什么是多模态学习?
模态
- 模态是指一些表达或感知事物的方式,每一种信息的来源或者形式,都可以称为一种模态
- 视频
- 图像
- 文本
- 音频
多模态
- 多模态即是从多个模态表达或感知事物

多模态学习
- 从多种模态的数据中学习并且提升自身的算法
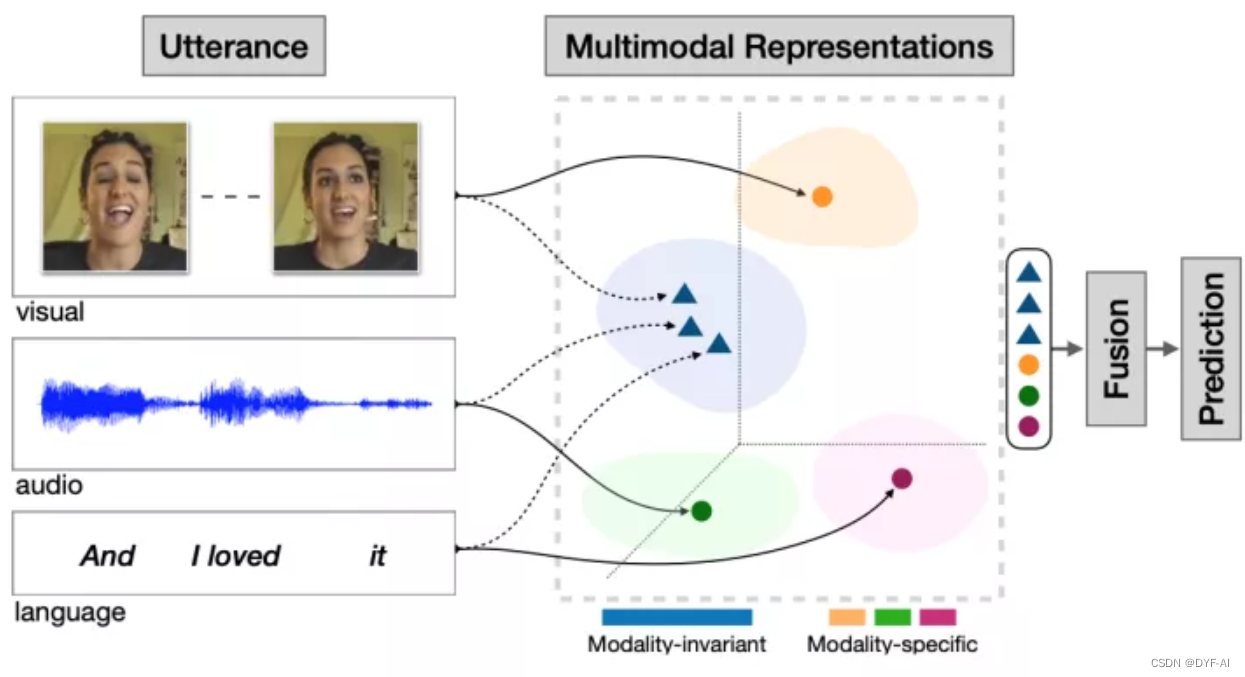
多模态学习的典型任务
- Language-Audio
- Text-to-Speech Synthesis
- 给定文本,生成一段对应的声音
- Audio Captioning
- 给定一段语音,生成一句话总结并描述主要内容(不是语音识别)
- Text-to-Speech Synthesis
- Vision-Audio
- Audio-Visual Speech Recognition
- 给定某人的视频及语音进行语音识别
- Video Sound Separation
- 给定视频和声音信号(包含多个声源),进行声源定位与分离
- Image Generation from Audio
- 给定声音,生成与其相关的图像
- Speech-conditioned Face generation
- 给定一段话,生成说话人的视频
- Audio-Driven 3D Facial Animation
- 给定一段话与3D人脸模版,生成说话的人脸3D动画
- Audio-Visual Speech Recognition
- Vision-Language
- Image/Video-Text Retrieval
- 图像/视频<–>文本的相互检索
- Image/Video Captioning
- 给定一个图像/视频,生成文本描述其主要内容
- Visual Question Answering
- 给定一个图像/视频与一个问题,预测答案
- Image/Video Generation from Text
- 给定文本,生成相应的图像或视频
- Multimodal Machine Translation
- 给定文本,生成相应的图像或视频
- Multimodal Dialog
- 给定图像,历史对话,以及与图像相关的问题,预测该问题的回答
- Image/Video-Text Retrieval
- 定位相关的任务
- Visual Grounding
- 给定一个图像与一段文本,定位到文本所描述的物体
- Temporal Language Localization
- 给定一个视频和一段文本,定位到文本所描述的动作(预测起止时间)
- Video Summarization from text query
- 给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,预测视频关键帧(或关键片段)组合为一个短的摘要视频
- Video Segmentation from Natural Language Query
- 给定一段话(query)与一个视频,分割得到query所指示的物体
- Video-Language Inference
- 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义
- Object Tracking from Natural Language Query
- 给定一段视频和一些文本,追踪视频中文本所描述的对象
- Language-guided Image/Video Editing
- 一句话自动修图。给定一段指令(文本),自动进行图像/视频的编辑
- Visual Grounding
Transformers:CV和NLP的大一统模型
-
ViT
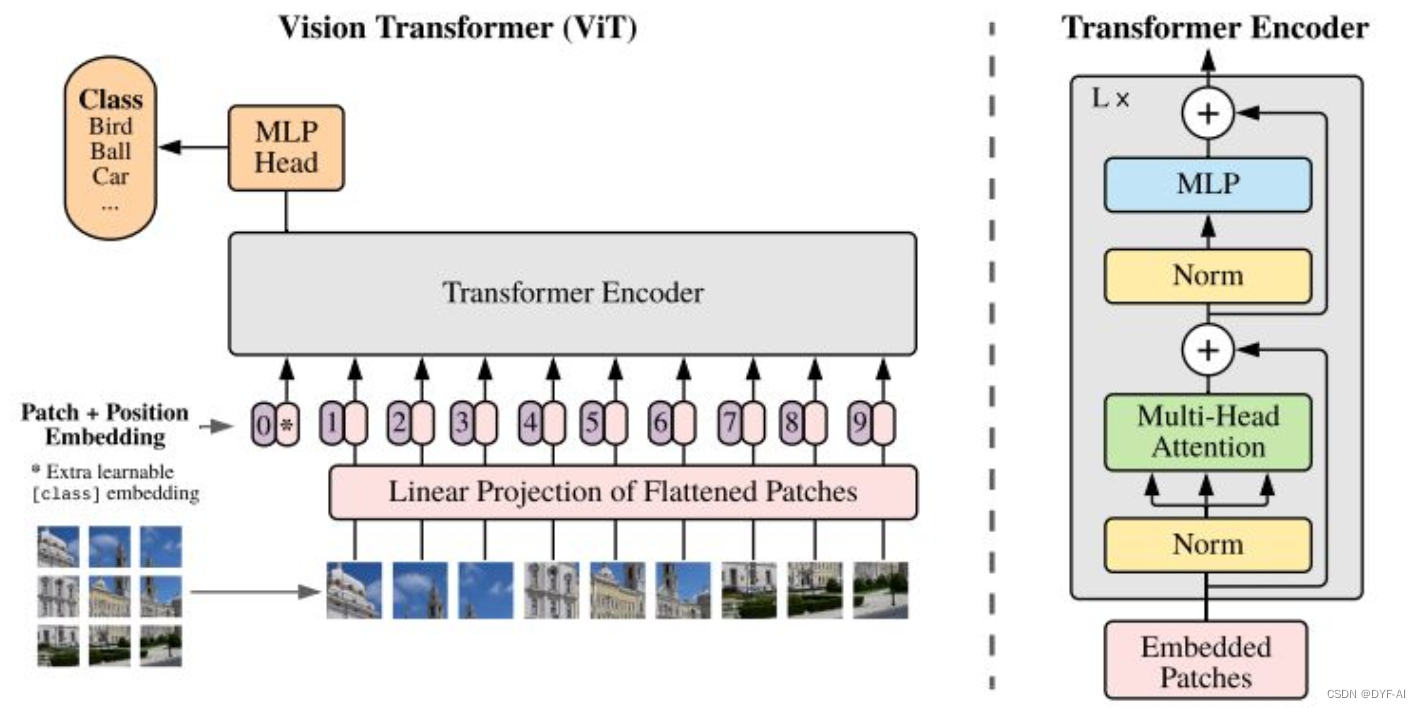
-
SwinT
多模态学习的模型
-
CLIP
-
简介
-
- CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型
-
- CLIP是一种基于对比学习的多模态模型,训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系
-
- CLIP包括两个模型:Text Encoder和Image Encoder
- 1)Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型
- 2)Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer
-
-
Contrastive Learning
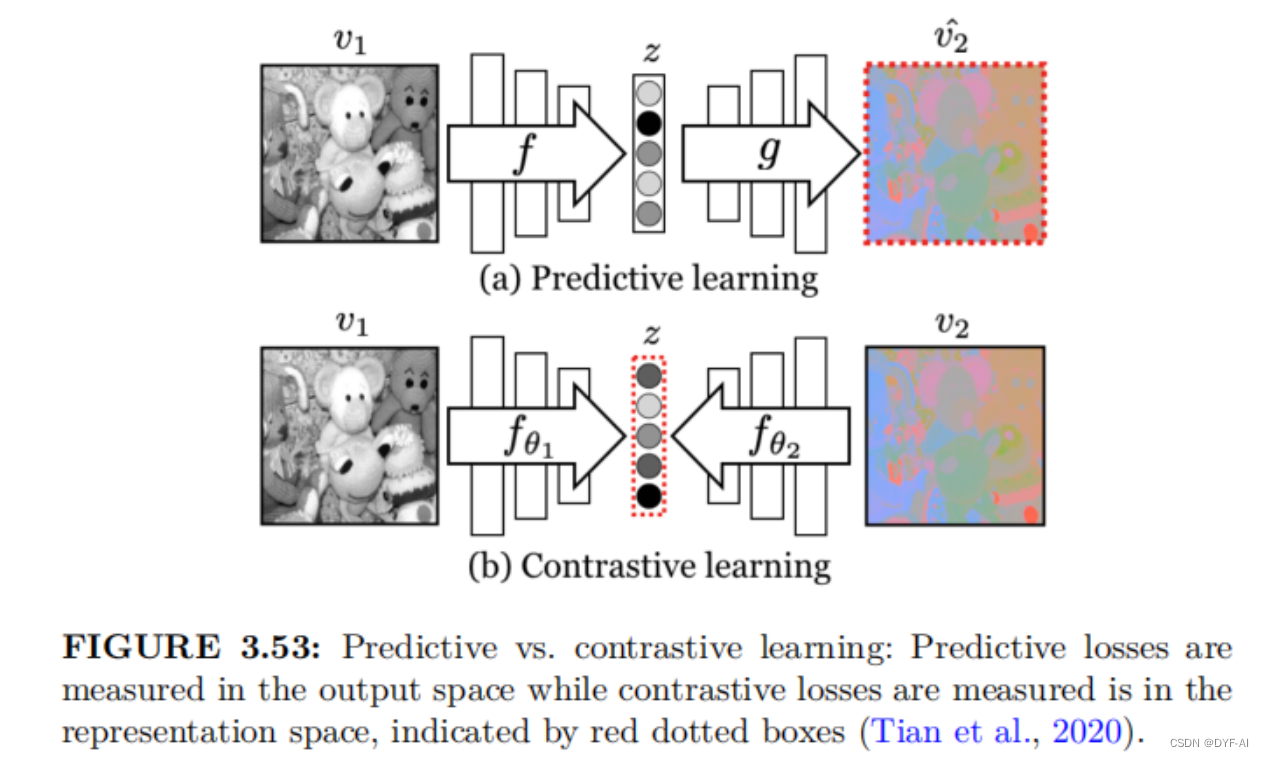
-
模型结构
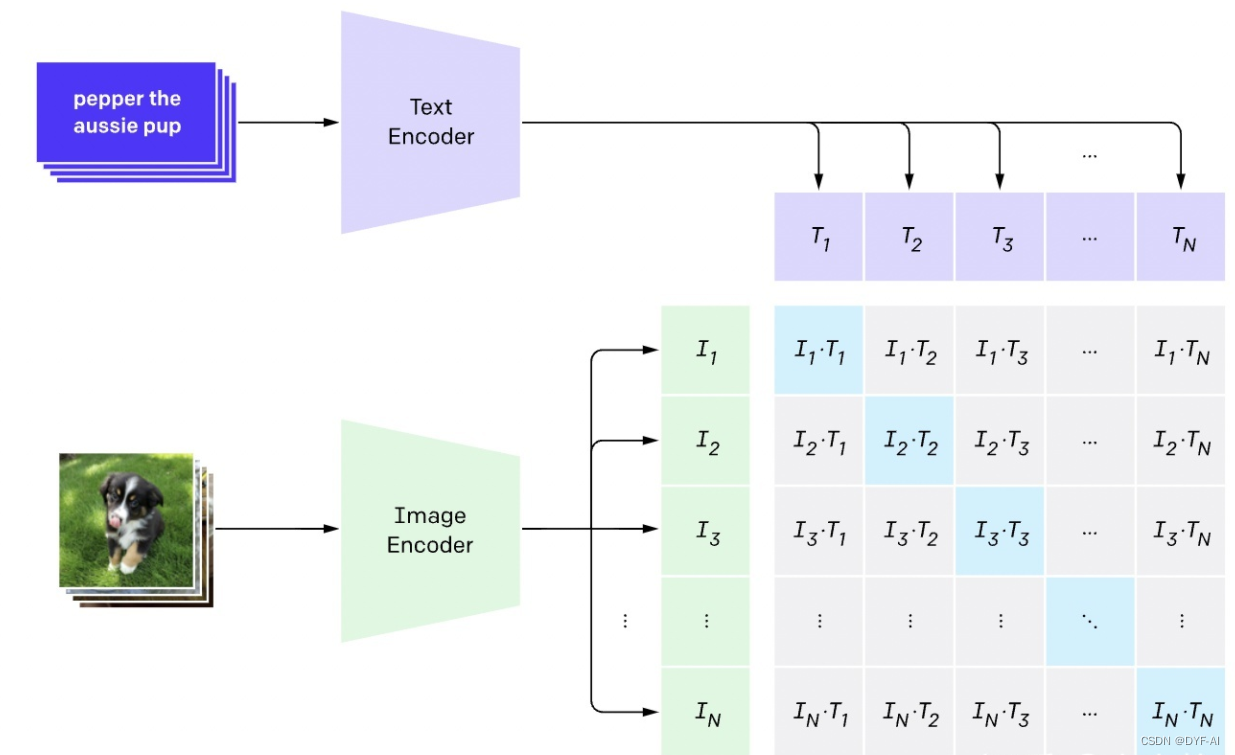
1. N个图片和N个文本的编码
2. 图片和文本进行对比学习(Contrastive Learning)
3. 正样本:匹配的图片和文本就是一对正样本(对角线上的),数量为N
4. 负样本:不匹配的图片和文本(对角线外的),数量为N^2-N
5. 训练目标:最大化正样本的余弦相似度,并最小化负样本的余弦相似度 -
训练数据
- WebImageText,共4个亿的文本-图像对的巨无霸数据集。
https://arxiv.org/pdf/2110.04222.pdf
- WebImageText,共4个亿的文本-图像对的巨无霸数据集。
-
zero-shot分类
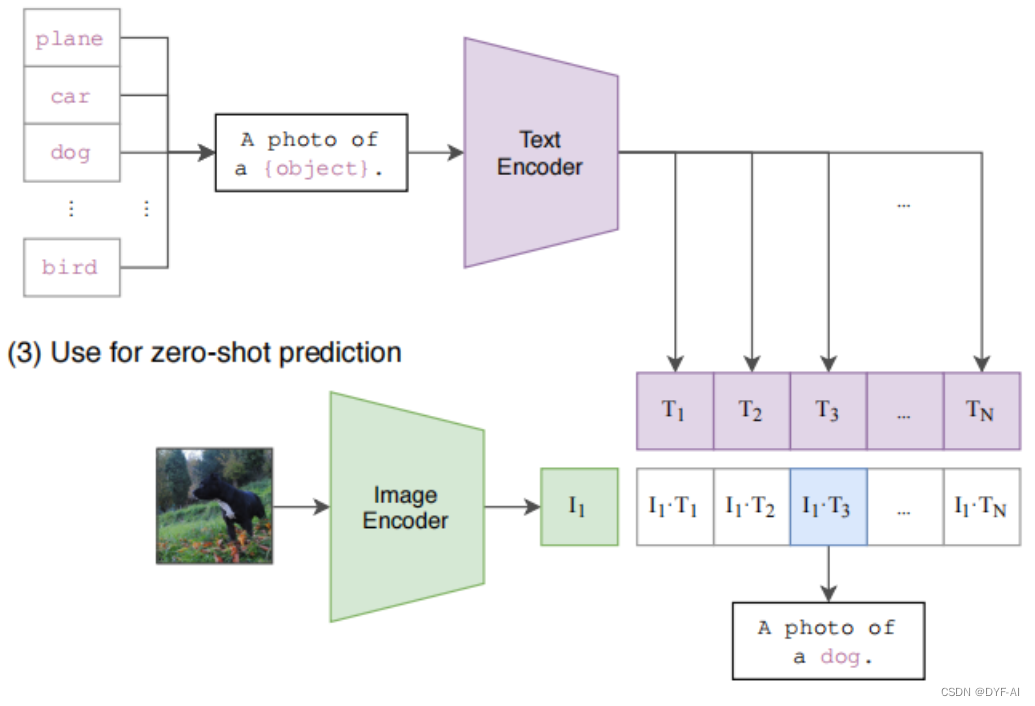
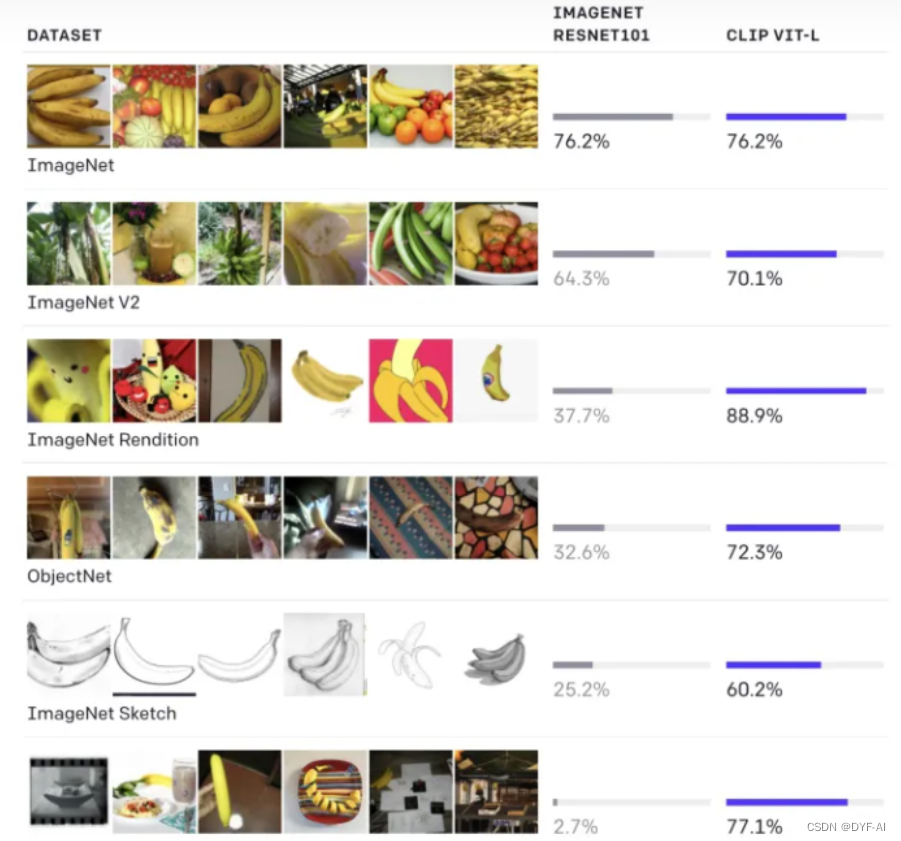
传统分类模型缺点:
1)训练类别个数固定,如训练1000个类别,预测就是这1000个类别的概率值,无法拓展
2)新增类别需要重新训练模型
CLIP分类:利用多模态特性为具体的任务构建了动态的分类器,可通过Text Encoder任意增加分类的标签 -
总结
- 优点
-
- 使用text encoder和image encoder进行相似度匹配,使得文本和图像模态得以融合
-
- 通过计算text encoder和image encoder的余弦相似度,可实现zero-shot的图片分类
-
- 不足
-
- zero-shot在某些数据集上表现较差,如细粒度分类,抽象任务等
-
- 在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题,即如果测试数据集的分布和训练集相差较大,CLIP会表现较差,如MNIST只有88%的准确率 (其实大部分模型都会存在)
-
- 没有解决深度学习的数据效率低下难题,训练CLIP需要大量的数据(4亿对图像-文本对)
-
- 优点
-
-
DALL-E
-
简介
- DALL-E是OpenAI推出的多模态预训练模型,该模型参数量120亿,在2.5亿对图像-文本对上进行训练
- DALL-E是一个两阶段模型
- Stage1:训练一个变分自编码器(Discrete Variance Auto-Encoder,dVAE),用于生成图像tokens(用embedding更合适?)
- Stage2:训练一个文本和图像的自回归解码器,用于预测生成图片tokens
-
模型框架
- 训练阶段
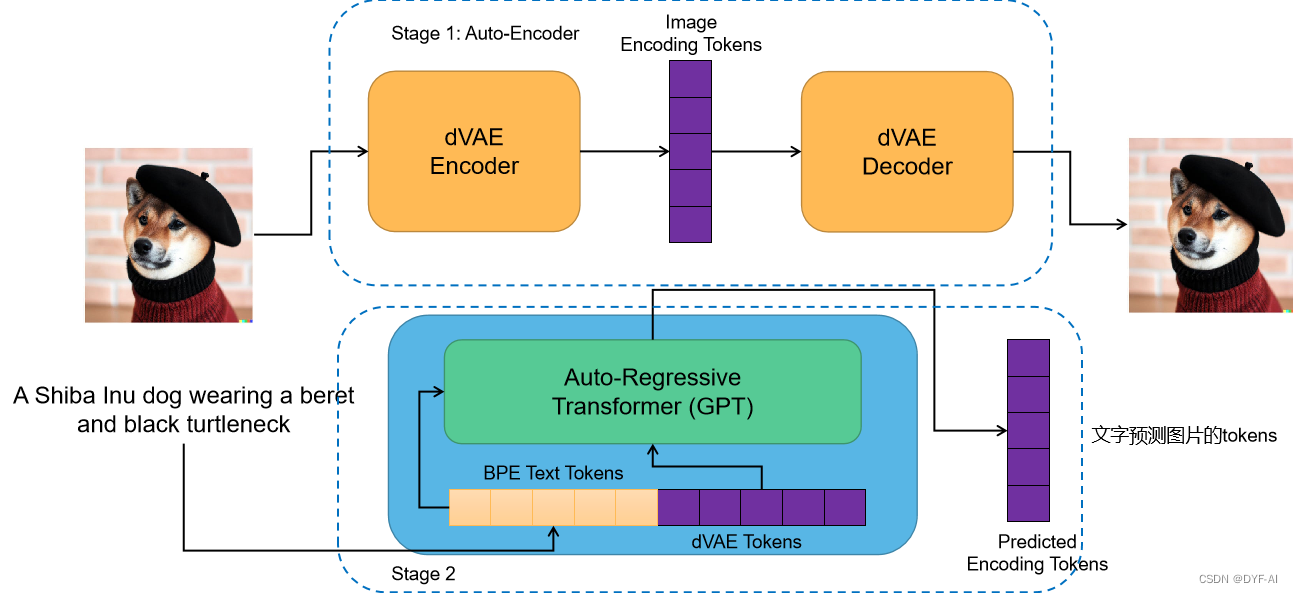
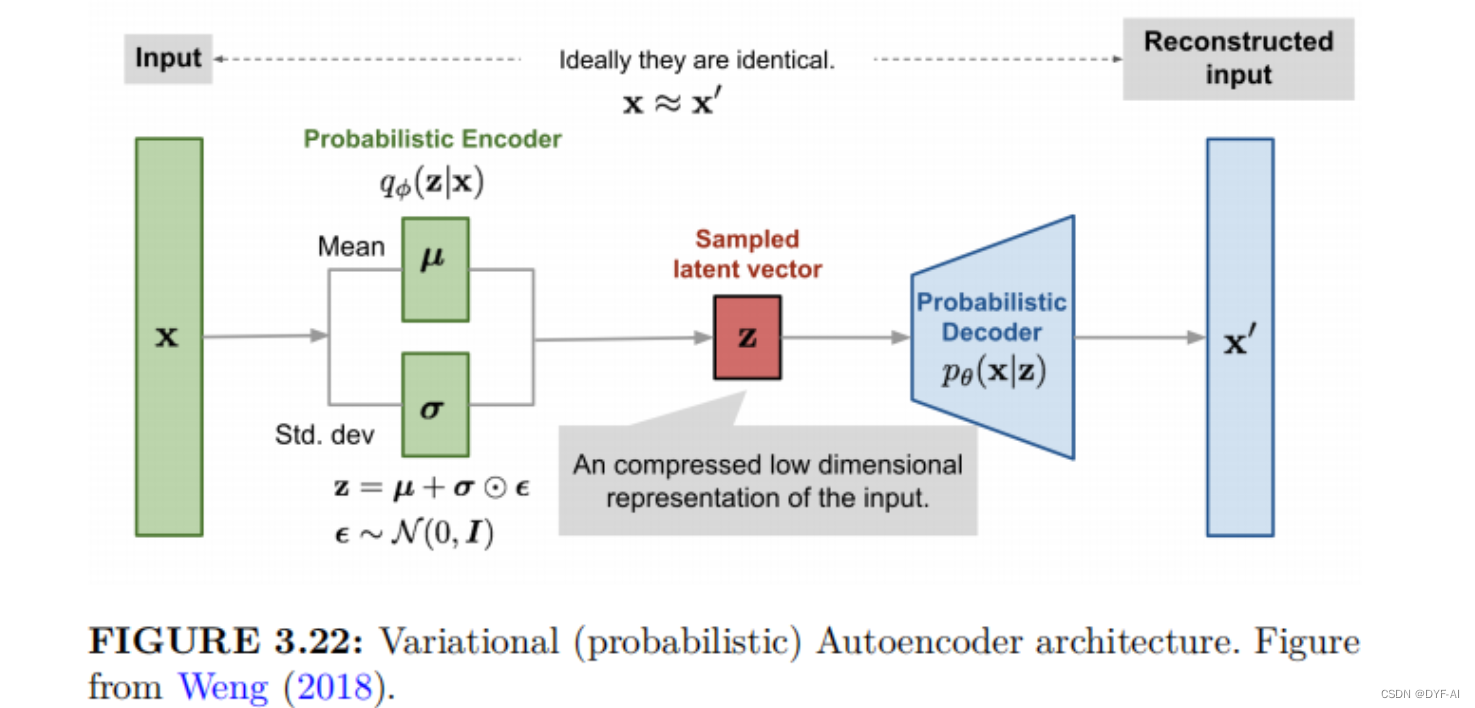
- Stage1 Loss Functiuon: loss=||x-x’||
- Stage1 Image Encoding Tokens代表图片被压缩的表示(Latent Representation)
- 训练阶段
-
推理阶段
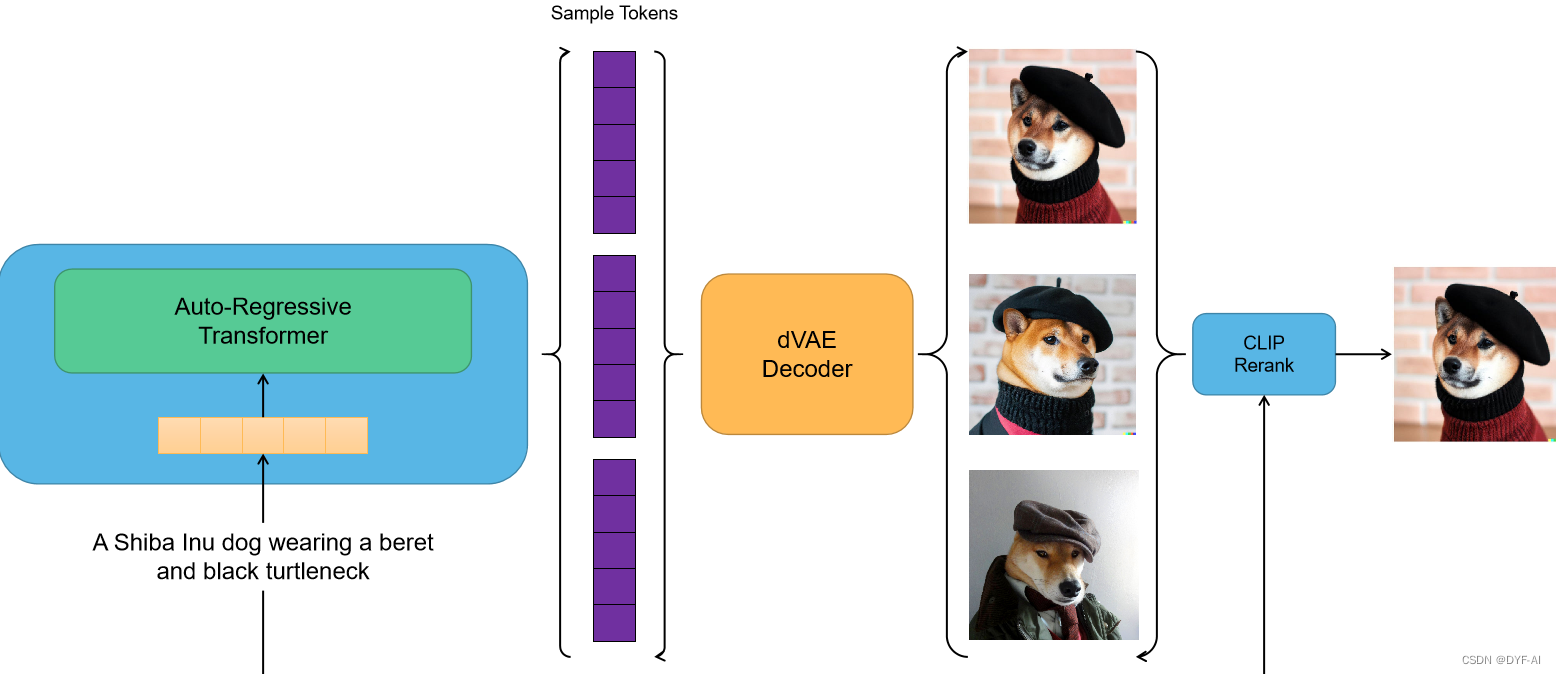
-
demo
- 文本提示

文本提示:一个专业高质量的颈鹿乌龟嵌合体插画。模仿乌龟的长颈鹿。乌龟做的长颈鹿 - 文本+图像提示

文本+图像提示:参照上面的猫在下面生成草图
- 文本提示
-
总结
- 优点:
-
- 多模态生成能力:DALL-E可以将文本描述转化为对应的图像,实现了文本到图像的多模态生成。它能够生成高质量、多样化且创意性的图像,甚至可以生成以前从未见过的新颖图像
-
- 创造力和想象力:DALL-E模型展现了惊人的创造力和想象力。它可以将抽象的文本描述转化为具体的图像,同时保持图像的相关性和连贯性。这使得它在创意设计、虚拟场景生成等领域具有广泛的应用潜力
-
- 不足
- 训练数据的限制:DALL-E的训练过程依赖于大规模的图像和文本数据集
- 语义理解的限制:尽管DALL-E能够生成与文本描述相匹配的图像,但它对于理解文本的深层语义仍然存在限制。在某些复杂的场景或抽象概念的描述中,模型可能会产生与预期不一致的结果
- 优点:
-
-
BLIP2
-
简介
- BLIP2是一个图像到文本的模型
-
模型框架
- Stage1
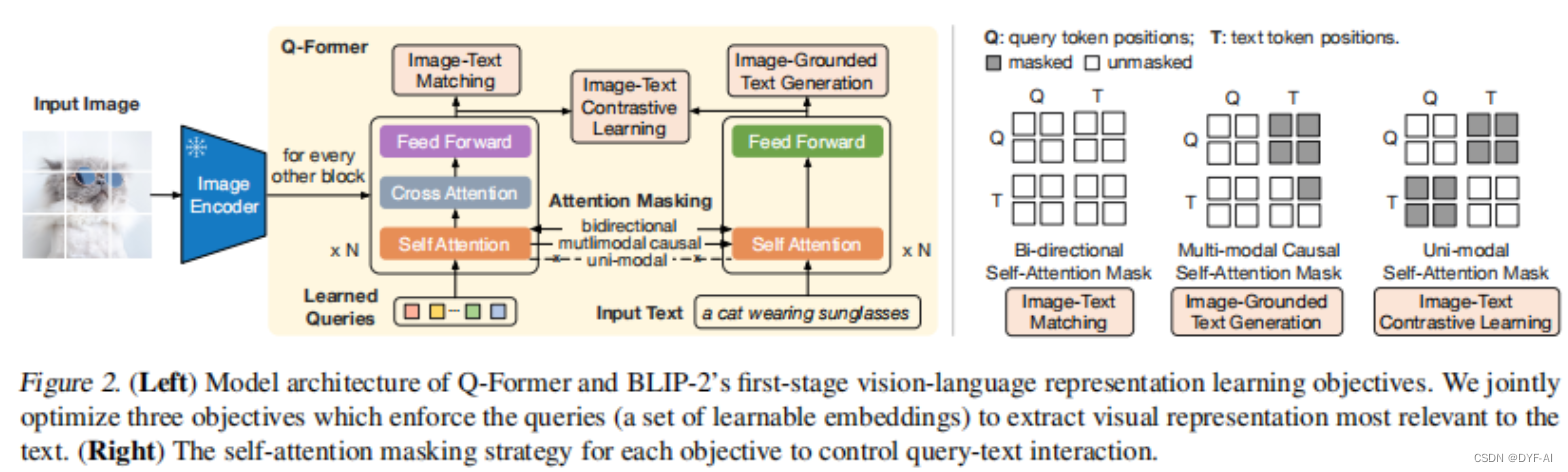
- 第一阶段从冻结图像编码器引导视觉语言表示学习,即让Q-Former学习和文本更相关的视觉特征(视觉-文本特征对齐)
- 固定视觉预训练模型,通过三个任务来训练一个 Q-Former 将图像输入中的语义编码到一个和文本特征空间相似的特征空间中。具体来讲,模型基于 K 个可学习的 query 嵌入和 cross-attention 机制从图像中获取特征,三个任务包括:
-
- 图文匹配:对输入的(图像,文本)二元组分类,判断其是否相关
-
- 基于图像的文本生成:给定图像输入,生成对应的文本描述
-
- 图文对比学习:拉近图像特征和对应文本特征的距离,增大其和无关文本特征的距离
-
- Stage2:
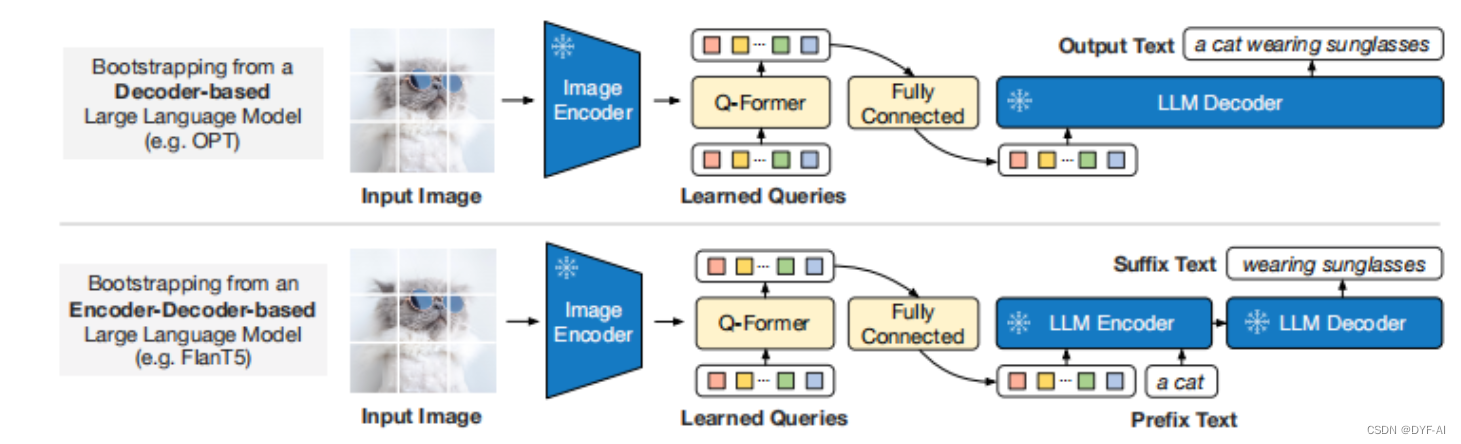
- 第二阶段将视觉从冻结的语言模型引导到语言生成学习,即使用LLM来解析Q-Former输出的视觉特征
- 针对两类不同的LLM设计了不同的任务:
-
- Decoder类型的LLM(如OPT):以Query做输入,文本做目标
-
- Encoder-Decoder类型的LLM(如FlanT5):以Query和一句话的前半段做输入,以后半段做目标
-
- Stage1
-
demo

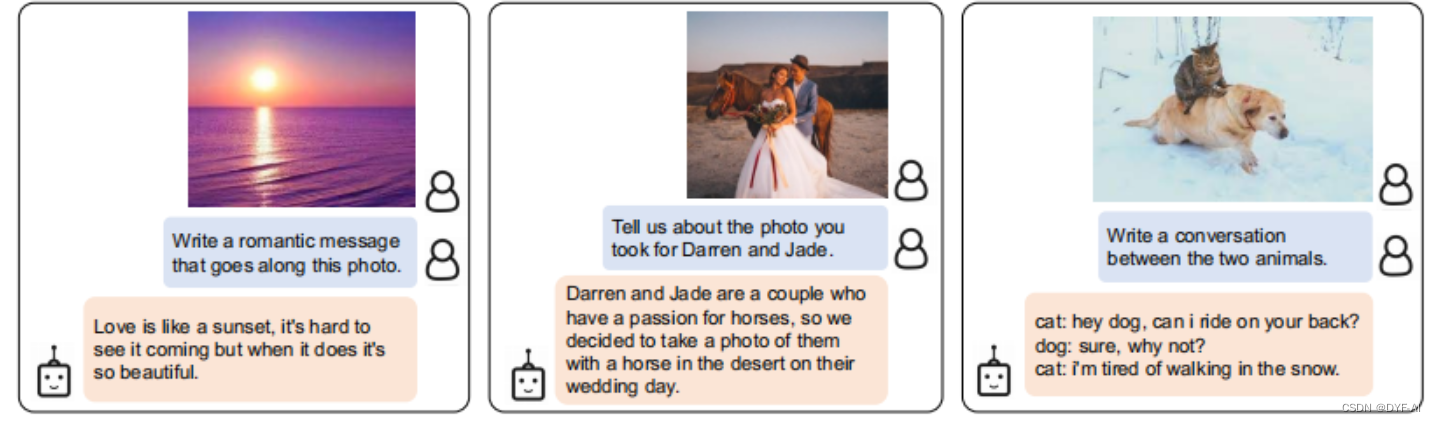
-
总结
- 优点
-
- 将 Q-Former 的输出通过一个全联接网络输入给固定的大语言模型,通过【基于图像的文本生成】任务将与文本特征进行了初步对齐的视觉特征进一步编码为大语言模型可以理解的输入
-
- 通过固定大语言模型的参数,BLIP-2 保留了大语言模型的 Instruction Following 能力
-
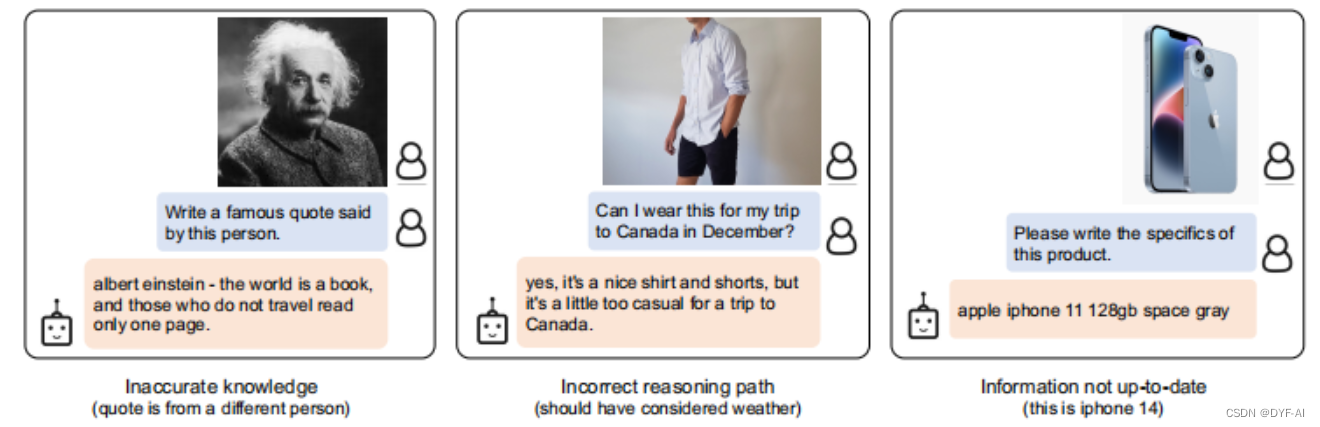
- 不足:
- 模型缺乏多模态的 In-Context-Learning 能力

- 例子:给出一张树的照片,并告诉模型有两个树,给出一盘橙子,告诉模型有三个橙子,再给出一张小鸟的图片,问图片中小鸟的数量?
- 原因:训练数据只是一些简单(图像,文本)对
- 模型缺乏多模态的 In-Context-Learning 能力
- 没修改大语言模型权重,保留了大语言模型的一些缺点,比如可能输出不准确的信息
- 优点
-
多模态学习面临的难点和挑战
- 数据获取和标注
- 获取多模态数据集并进行准确的标注是一个挑战。不同模态的数据可能具有不同的特点和表示方式,需要耗费大量的时间和人力进行数据采集和标注
- 特征表示学习
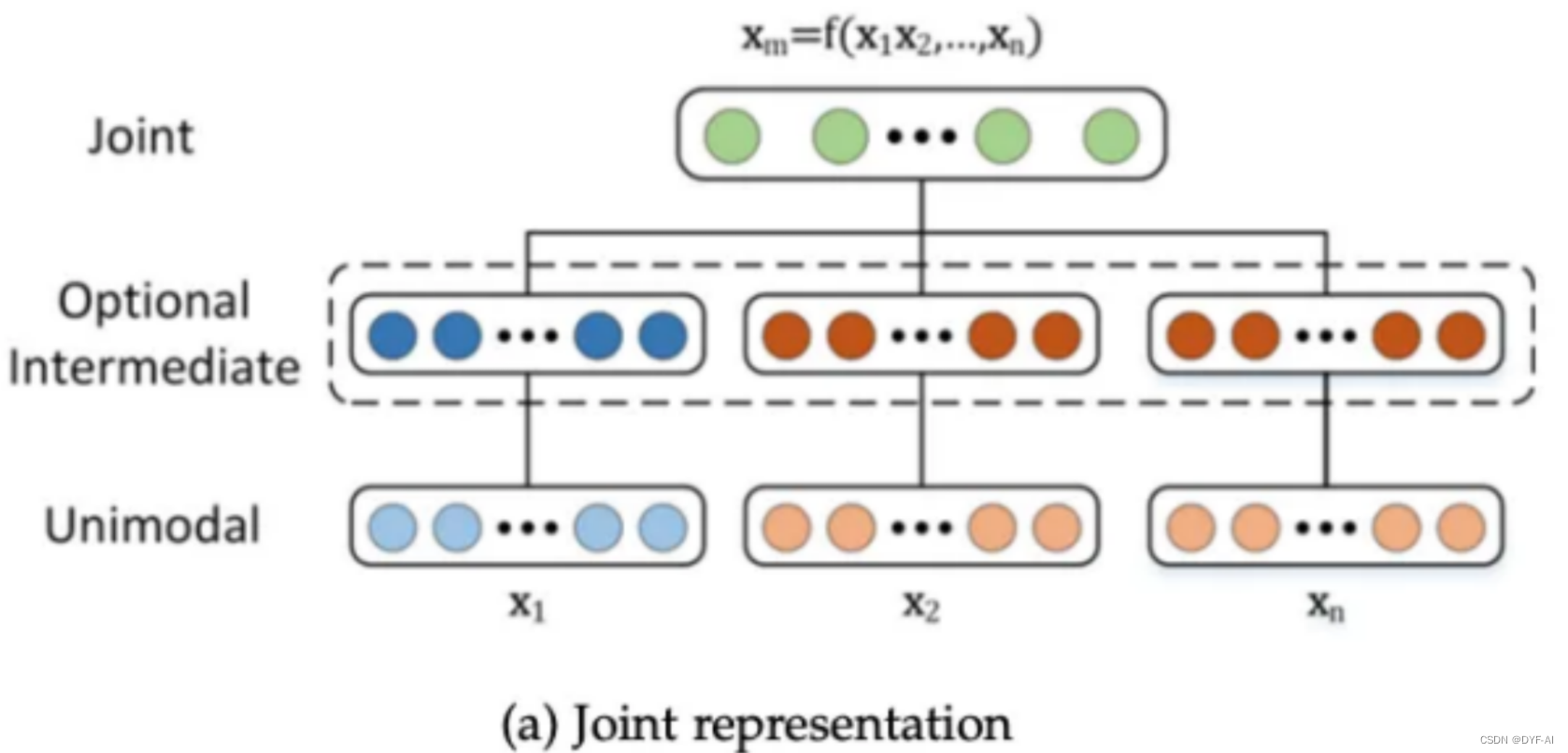
- 如何以利用多种模态的互补性和冗余性的方式表示和总结多模态数据
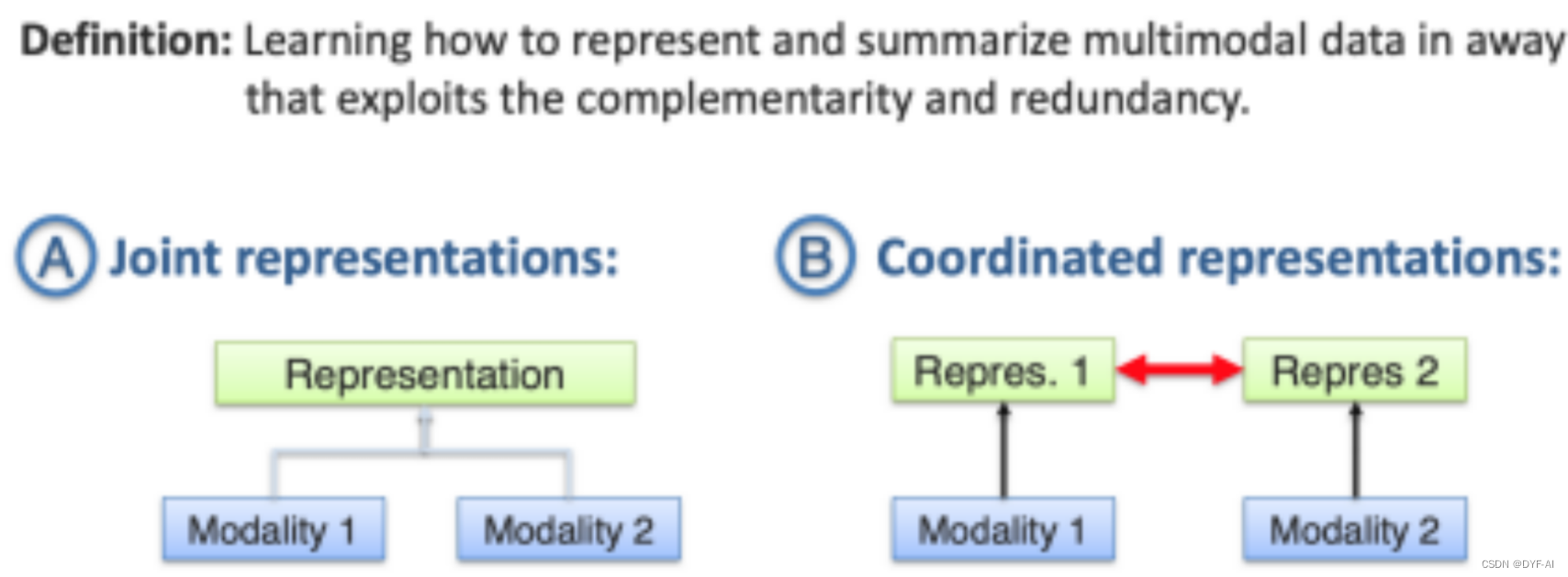
- 如何以利用多种模态的互补性和冗余性的方式表示和总结多模态数据
- 联合表征
- 如何有效地融合不同模态的信息是一个关键问题。模态之间的关联性和权重分配需要仔细设计和建模
- 如何有效地融合不同模态的信息是一个关键问题。模态之间的关联性和权重分配需要仔细设计和建模
- 模态间的对齐和匹配
- 多模态学习需要处理不同模态之间的对齐和匹配问题,以便进行有效的信息融合和联合学习。模态之间的对齐可以是空间上的对齐(如图像和文本的对齐)或语义上的对齐(如情感的对齐) -

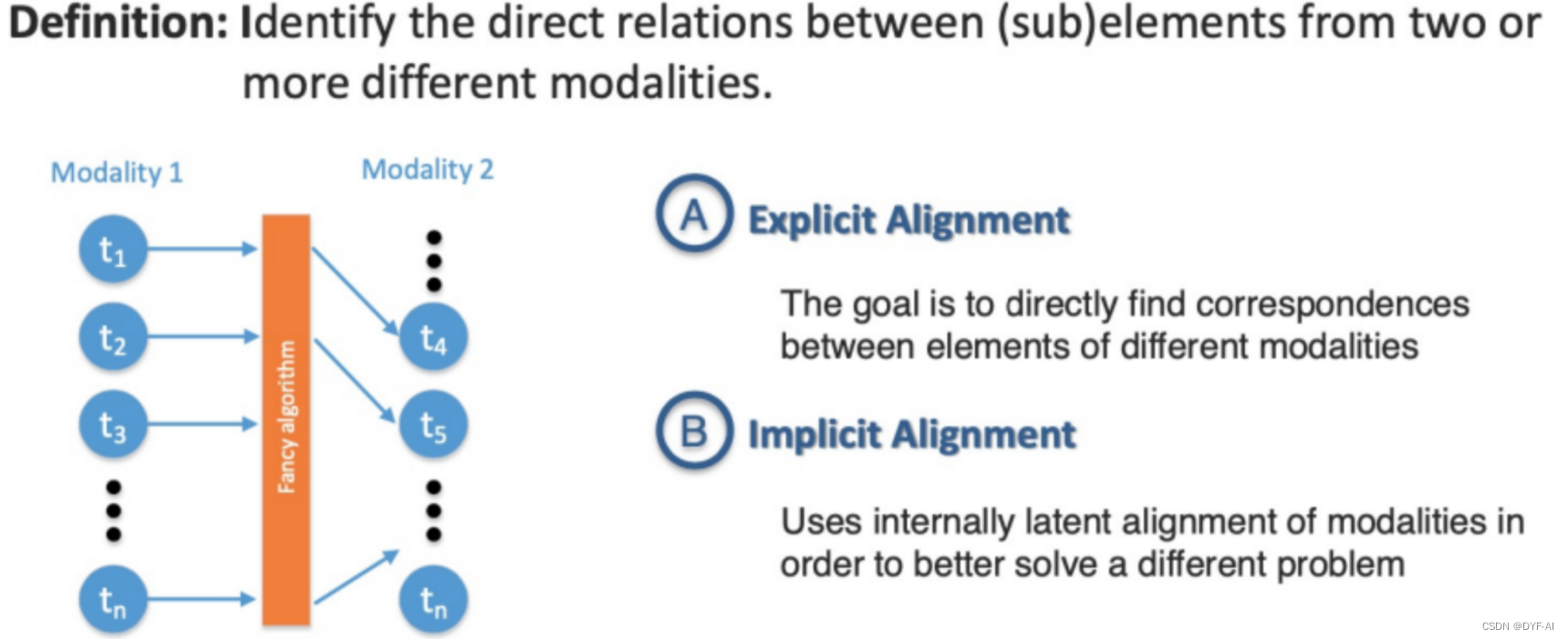
- 多模态学习需要处理不同模态之间的对齐和匹配问题,以便进行有效的信息融合和联合学习。模态之间的对齐可以是空间上的对齐(如图像和文本的对齐)或语义上的对齐(如情感的对齐) -