输出算子(Sink)
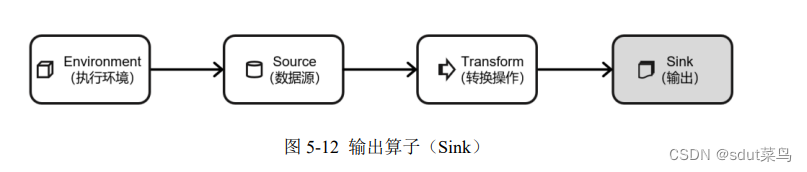
Flink作为数据处理框架,最终还是需要把计算处理的结果写入到外部存储,为外部应用提供支持。Flink提供了很多方式输出到外部系统。
1. 连接外部系统
在Flink中我们可以在各种Fuction中处理输出到外部系统,但是Flink作为一个快速的分布式实时流处理系统,对稳定性和容错性要求极高。一旦出现故障,我们应该有能力恢复之前的状态,保障处理结果的正确性。这种性质一般被称为"状态一致性"。Flink内部提供了一致性检查点checkpoint来保障我们可以回滚到正确的状态,但是我们在处理过程中任意读写外部系统,发生故障后就很难回退到从前了。
所以Flink的DataStream API提供了专门向外部写入数据的方法,通过addSink实现,与addSource类似,addSink方法对应着一个Sink算子,主要就是来实现与外部系统连接,并将数据提交写入;Flink程序中所有对外的输出操作一般都是利用Sink算子完成的。比如我们经常使用的print 方法返回的就是一个 DataStreamSink。
Sink算子的创建主要是通过DataSream的.addSink()实现的,并且需要重写default void invoke(IN value, Context context) throws Exception 方法
Flink提供的连接器,这个是1.17版本的,比1.13版本的多很多

除了官方的,Flink也可以使用Apache Bahir的扩展连接器

2. 输出到文件
输出文件Flink有writeAsText()、writeAsCsv()可以直接输出到文件,但是这种不支持同时写一份文件,必须设定为并行度为1,所以Flink又提供了一个专门的流式文件系统的连接器StreamingFileSink。
SreamingFileSink继承自抽象类RichSinkFunction,而且集成Flink的检查点机制(checkpoint)用来保证精确一次的一致性语义。 StreamingFileSInk主要操作是将数据写入桶,每个桶中的数据都可以分割成一个个大小有限的分区文件,并且也可以通过各种配置来控制分桶的操作;默认的分桶方式是基于时间的。
StreamingFileSink(Row-encoded)支持行编码和批量编码(Bulk-encoded,比如 Parquet)格式,这两种不同的方式都有各自的构建器:
- 行编码:
StreamingFileSink.forRowFormat(basePath,rowEncoder) - 批量编码:
StreamingFileSink.forBulkFormat(basePath,bulkWriterFactory)
代码实例:
public static void main(String[] args) throws Exception {
// 1. 直接调用getExecutionEnvironment 方法,底层源码可以自由判断是本地执行环境还是集群的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 2. 从集合中读取数据
ArrayList<Event> list = new ArrayList<>();
list.add(new Event("ming","www.baidu1.com",1200L));
list.add(new Event("xiaohu","www.baidu2.com",1200L));
list.add(new Event("xiaohu","www.baidu5.com",1267L));
list.add(new Event("gala","www.baidu6.com",1200L));
list.add(new Event("ming","www.baidu7.com",4200L));
list.add(new Event("xiaohu","www.baidu8.com",5500L));
// 3. 读取数据
DataStreamSource<Event> eventDataStreamSource = env.fromCollection(list, BasicTypeInfo.of(Event.class));
// 4. 构建File Sink
StreamingFileSink<String> streamingFileSink = StreamingFileSink.<String>forRowFormat(new Path("./out"), new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withMaxPartSize(1024 * 1024 * 1024)
.build()
).build();
eventDataStreamSource.map(Event::toString).addSink(streamingFileSink);
// 5. 执行程序
env.execute();
}
这里设置了并行度是2,所以是两个桶文件。通过.withRollingPolicy()方法指定滚动策略,策略配置说明:
withInactivityInterval: 最近 5 分钟没有收到新的数据withRolloverInterval: 至少包含 15 分钟的数据withMaxPartSize: 文件大小已达到 1 GB

3. 输出到Kafka
Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。
代码实例:
public static void main(String[] args) throws Exception {
// 1. 直接调用getExecutionEnvironment 方法,底层源码可以自由判断是本地执行环境还是集群的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 设置属性
Properties properties = new Properties();
properties.put("bootstrap.servers","hadoop102:9092");
// 3. 读取数据
DataStreamSource<String> stringDataStreamSource = env.readTextFile("input/clicks.csv");
// 4. 构建File Sink
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>("clicks", new SimpleStringSchema(), properties);
// 5. addSink
stringDataStreamSource.addSink(kafkaProducer);
// 6. 执行程序
env.execute();
}
addSink 传入的参数是一个 FlinkKafkaProducer。FlinkKafkaProducer继承了抽象类TwoPhaseCommitSinkFunction,这是一个实现了两阶段提交的RichSinkFuction,两阶段提交提供了Flink向Kafka写入数据的事务性保证,能够真正做到精确一次的状态一致性。
4. 自定义Sink输出
如果Flink提供的Sink不满足自己的要求,也可以通过自定义Sink来满足自己的要求,通过Flink提供的SinkFuction接口和对应的RichSinkFuction抽象类重写invoke()就可以自定义Sink。
这里以Hbase为例,使用RichSinkFuction,创建Hbase的连接以及关闭Hbase的连接分别放到open和close方法中。
代码实例:
public static void main(String[] args) throws Exception {
// 1. 直接调用getExecutionEnvironment 方法,底层源码可以自由判断是本地执行环境还是集群的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 设置属性
Properties properties = new Properties();
properties.put("bootstrap.servers","hadoop102:9092");
// 3. 读取数据
DataStreamSource<String> stringDataStreamSource = env.readTextFile("input/clicks.csv");
// 4. 构建File Sink
stringDataStreamSource.addSink(new RichSinkFunction<String>() {
public Configuration configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径
public Connection connection; // 管理 Hbase 连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop102:2181");
connection = ConnectionFactory.createConnection(configuration);
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
@Override
public void invoke(String value, Context context) throws Exception {
Table table = connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
});
// 6. 执行程序
env.execute();
}