百分位数(percentile)计算
百分位数含义:统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列。如,处于p%位置的值称第p百分位数。能够表达p%的数据都是小于这个百分位数。
实现百分位数当前有很多种算法,下面使用一种比较容易理解的方法进行例子说明。
例子:
有下面几个学生分数数据。
Arr = [20,30,50,50,60,10]
将数据按从小到大排序后
Arr = [10,20,30,50,50,60]
percentile(50%) =下标为 3的值,即50。 【(Arr.size()-1)*0.5 = 2.5 四舍五入为 3】,
percentile(100%) = 下标为 5的值,即60。 【(Arr.size()-1)*1 = 5】,显然这个时候是等于Arr的最大值。
percentile(0%) = 下标为 0的值,即10。 【(Arr.size()-1)*0 = 0】,显然这个时候是等于Arr的最小值。
简单的python 代码实现的逻辑如下。
import numpy as np
def percentile(data, p):
sorted_data = np.sort(data)
k = round((len(data)-1) * p)
return sorted_data[k]
SQL实现如下:
--percentile(50%)
SELECT percentile(num, 0.5) as P50 FROM arr;
数据去重
已有表数据:
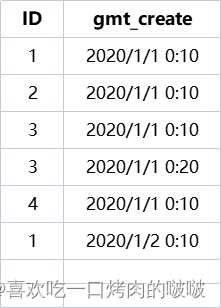
让ID不重复。
select id,gmt_create
from(
select id,gmt_create,row_number() over(partition by id order by gmt_create desc) tag
from table) t1
where tag=1;
以上SQL中row_number()为开窗函数,根据ID来分区,分区内部按时间来排序,然后再给分区里面的数据进行打标。
滚动指标计算
已有表数据:
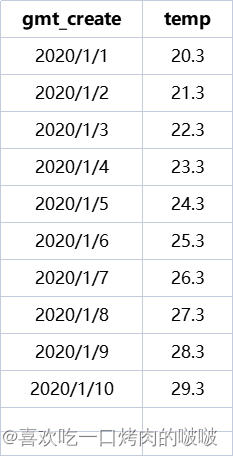
以上是每天的天气温度数据,如果需要输出一个趋势图,横坐表示日期,纵坐标表示当前日期的前7天温度的平均数,则怎么实现呢。
select gmt_create,SUM(num) num OVER(PARTITION BY gmt_create ORDER BY gmt_create ROWS BETWEEN 7 PRECEDING AND -1 FOLLOWING)
num from table;
累计指标计算
已有表数据。
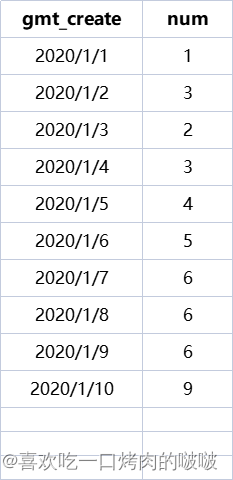
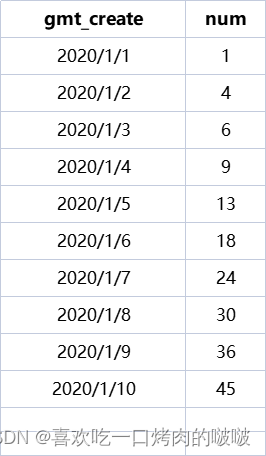
当天的日期的数据为之前所有日期累计的总和,如1月2日为1+3=4,1月3日为1+3+2=6,以此类推。
select gmt_create,SUM(num) num OVER(PARTITION BY gmt_create ORDER BY gmt_create) AS num from table;
等同于
select gmt_create,SUM(num) num OVER(PARTITION BY gmt_create ORDER BY gmt_create ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) num from table;
多维度聚合分析
有这种的场景,现需分析用户画像,需要统计3个不同维度的聚合,如地理IP、设备,性别。
需要分析不同地理IP、设备、性别分别多少人。
需要分析不同地理IP、设备分别多少人。
需要分析不同地理IP分别多少人。
需要总共有多少人。
传统的分析方法如下实现:
SELECT ip_city, device, sex, COUNT(*)
FROM users GROUP BY ip_city, device, sex
UNION ALL
SELECT ip_city, device, 'ALL' as sex, COUNT(*)
FROM users GROUP BY ip_city, device
UNION ALL
SELECT ip_city, 'ALL' as device, 'ALL' as sex, COUNT(*)
FROM users GROUP BY ip_city
UNION ALL
SELECT 'ALL' as ip_city, 'ALL' as device, 'ALL' as sex, COUNT(*)
FROM users
是不是代码很冗余?
如果使用Hive的多维度聚合分析函数grouping sets,则如下实现。
SELECT ip_city, device, sex ,COUNT(*)
FROM users
GROUP BY ip_city, device, sex GROUPING SETS((ip_city, device, sex), (ip_city, device), (ip_city),());
上面还是很要写很多字段信息,有没有更简单的?有的。
SELECT ip_city, device, sex ,COUNT(*)
FROM users
GROUP BY CUBE( ip_city, device, sex);
GROUP BY CUBE( ip_city, device, sex) 等价于
GROUPING SETS((ip_city,device,sex),(ip_city,device),(ip_city,sex),(device,sex),(ip_city),(device),(sex),())
一看起来比之前的需求多算了一些逻辑,因此计算量会更大,所以如果要做优化还是建议采用GROUPING SETS进行剪枝优化。
待续更新。


![[Kotlin] 玩Android代码学习之-模块化+Retrofit+协程+viewModel的数据层封装](https://img-blog.csdnimg.cn/108877e71a9d4cdfbc296c617976766c.png)