这里简单介绍一下面试回答、我之前有详细的去学习、但是一直都觉得太多内容了、太深入了
然后面试的时候不知道从哪里讲起、于是我写了这篇CSDN帮助大家面试回答、具体的深入解析下次再说
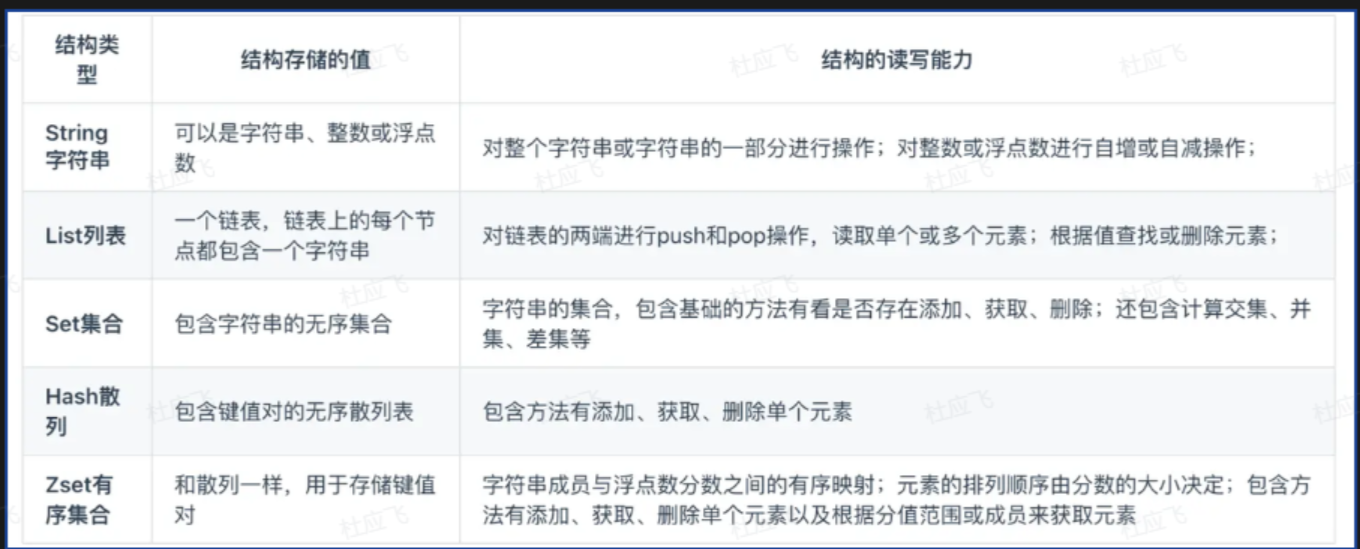
面试官你好 我来介绍一下Redis的五种基本数据类型
有String List Set ZSet Map 五种基本数据类型
1.首先介绍一下String类型
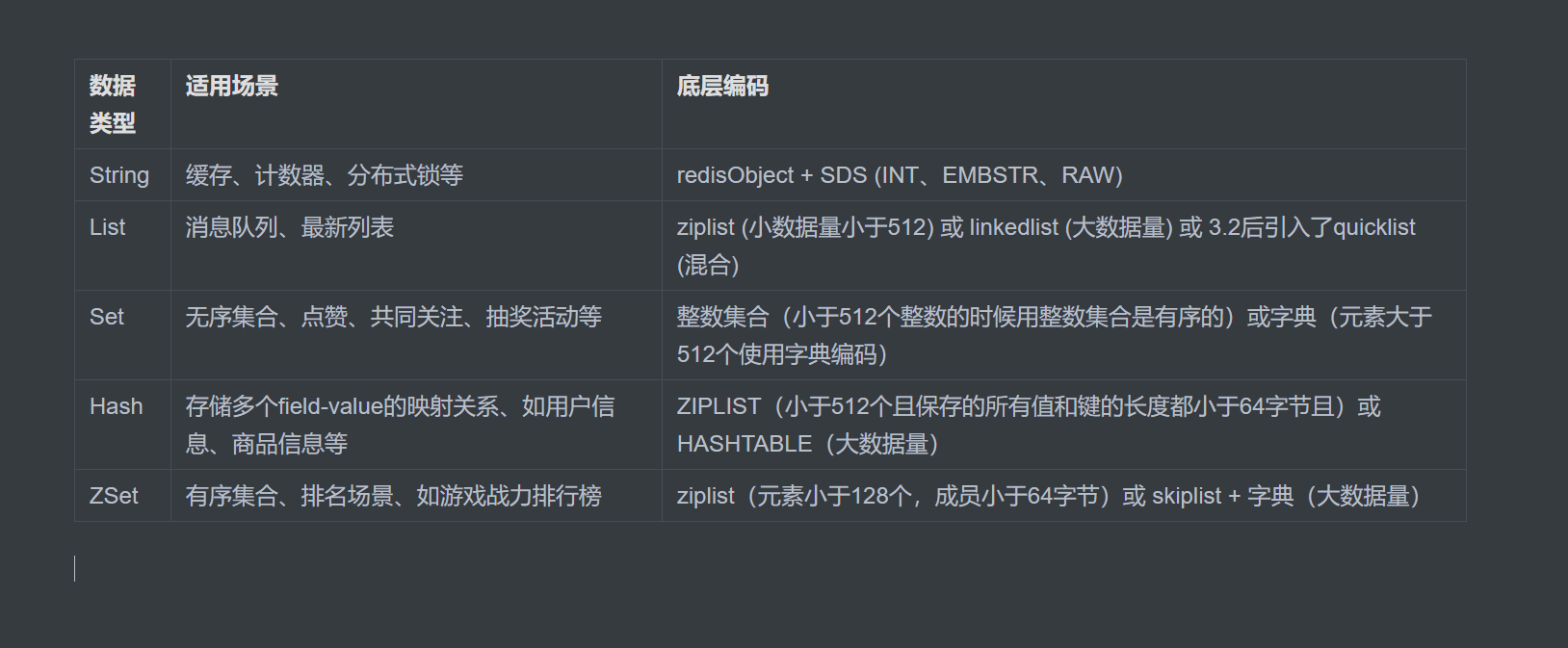
Redis的String类型是Redis中最基本的数据类型、最大可存储512MB数据、适用于存储文本、字节数据或序列化对象。常用于缓存、计数器和分布式锁等场景。
底层由redisObject和SDS组成、支持O(1)的长度获取和自动扩容。
String类型有三种编码方式:INT用于存整数、如果小于44字节时 将redisObject 和 SDS 连续存储 用EMBSTR编码 大于44字节时 将redisObject 和 SDS 分开存储用RAW 编码
2.然后介绍一下List类型
Redis的List类型是一个有序的字符串列表、支持在两端进行插入和删除操作、类似于双向链表。
元素是有序的且可以重复。
常见应用场景包括:
-
消息队列:通过
LPUSH和RPOP命令实现。 -
最新列表:用
LPUSH添加新元素,并通过LTRIM限制列表长度。
在Redis 3.2之前、List类型底层有两种实现:
-
ziplist:适用于元素较少且较短的情况、节省内存。
-
linkedlist:适用于元素较多或较长时、提供高效的插入删除操作。
Redis 3.2引入了quicklist、它将多个ziplist链接在一起。
Redis 7.0之后、listpack取代了ziplist、进一步提高了性能。
3.然后介绍一下Set类型
Set适用于无序集合场景 将信息放进一个集合里
使用场景比如点赞、共同关注、抽奖活动等
Set的底层实现是整数集合或字典、前者是有序的、后者是无序的。
当元素数量小也就是个数小于512、并且全部是整数的时候、会使用整数集合编码、更加的节约内存。
元素数量大于512个的时候会使用字典编码、查找元素的速度会更快。
4.然后说一下Hash类型
-
Hash是字典、可以存储多个
field-value的映射关系、比如学生分数、(存储对象数据、如用户信息、商品信息等。
Hash的底层编码有ZIPLIST和HASHTABLE两种
也就是说
-
Hash底层有两种编码结构:
一个是压缩列表、一个是HASHTABLE。同时满足以下两个条件、用压缩列表:-
Hash对象保存的所有值和键的长度都小于64字节
-
Hash对象元素个数少于512个。
-
-
两个条件任何一条不满足、编码结构就用
HASHTABLE。
5.最后说一下Zset(重要)
-
ZSet就是有序集合、顾名思义用于保存、查询处理有序的集合、其范围查询、成员分值查询速度都非常快。
-
ZSet非常适用于排名场景、比如游戏战力排行榜。
ZSet对象的底层有两种编码方式:ziplist 或者 skiplist+字典。
-
如果一个
ZSet对象中的所有元素同时满足:元素数量小于128个 以及 所有元素成员的长度都小于64字节、那么会使用ziplist编码、否则使用skiplist+字典编码。