一. 简述
虽然Rust的类型系统为我们提供了相当多的安全保障,但是还是不足以防止所有的错误。因此,Rust在语言层面内置了编写测试代码、执行自动化测试任务的功能。
测试是一门复杂的技术,本章覆盖关于如何编写优秀测试的每一个细节,但是会讨论Rust测试工具的运行机制。我们会向你介绍编写测试时常用的标注和宏、运行测试的默认行为和选项参数,以及如何将测试用例组织为单元测试与集成测试。
二. 编写测试
Rust语言中的测试时一个函数,它被用于验证非测试代码是否按照期望的方式运行。测试函数的函数体中一般包含3个部分:
-
准备所需的数据或状态
-
调用需要测试的代码
-
断言运行结果与我们期望的一致
接下来,我们会一起学习用于编写测试代码的相关功能,它们包含test属性、一些测试宏及should_panic属性。此时我们将建一个库项目:cargo new adder —lib
此时adder库项目自动生成一个src/lib.rs文件,此时cargo会给我们创建一个简单的测试代码模块:
pub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test] // @1
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4); // @2
}
}
我们可以看到@1这一行的#[test]标注:它将当前的函数标记为一个测试,并使该函数可以在测试运行中被识别出来。要知道,即便是在tests模块中也可能会存在普通的非测试函数,它们通常被用来执行初始化操作或一些常用指令,所以我们必须要将测试函数标注为#[test]。函数体中@2使用了assert_eq!宏断言,这是一个典型的测试用例编写方式。这时我们执行命令:cargo test
xxxxx@xxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.05s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 1 test // 正在执行一个测试
test tests::it_works ... ok // 此时函数
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s // 测试摘要,表示该集合中的所有测试均成功通过,1 passed; 0 failed则统计了通过和失败的测试总数
Doc-tests adder // 文件测试的结果
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
此时我们删除初始化的代码,我们编写下面两个测试函数:
extern crate core;
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ok_test() {
assert_eq!(2 + 2, 4);
}
#[test]
fn fail_test() {
panic!("Make this test fail");
}
}
此时我们再次执行cargo test运行测试!可预见的ok_test肯定是OK的,fail_test我们在里面写了panic!测试失败!
xxxxxx@xxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.13s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 2 tests
test tests::ok_test ... ok
test tests::fail_test ... FAILED
failures:
---- tests::fail_test stdout ----
thread 'tests::fail_test' panicked at 'Make this test fail', src/lib.rs:11:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::fail_test
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
测试信息输出非常明显,测试失败的位置提示很明确。
三. 测试相关的宏和函数
下面我们介绍一些我们在编写测试时会使用到的相关宏和方法!
3.1. 使用assert!宏检查结果
assert!宏由标准库提供,它可以确保测试中某些条件的值是true。assert!宏可以接收一个能够被计算为布尔类型的值作为参数。当这个值为true时,assert!宏什么都不做并正常通过测试。而当值时false时,assert!宏就会调用panic!宏,进而导致测试失败。使用assert!宏可以检查代码是否按照我们预期的方式运行。
#[derive(Debug)]
pub struct Rectangle {
length: u32,
width: u32,
}
impl Rectangle {
pub fn can_hold(&self, other: &Rectangle) -> bool {
self.length > other.length && self.width > other.width
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle { length: 9, width: 7 };
let smaller = Rectangle { length: 5, width: 1 };
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle { length: 9, width: 7 };
let smaller = Rectangle { length: 5, width: 1 };
assert!(smaller.can_hold(&larger)); // fasle, 断言失败
}
}
此时执行cargo test测试代码:一个成功,一个失败。
xxxxx@xxxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.12s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... FAILED
failures:
---- tests::smaller_cannot_hold_larger stdout ----
thread 'tests::smaller_cannot_hold_larger' panicked at 'assertion failed: smaller.can_hold(&larger)', src/lib.rs:29:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::smaller_cannot_hold_larger
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
3.2. 使用assert_eq!宏和assert_ne!宏判断相等性
在对功能进行测试时,我们常常需要将被测试代码的结果与我们所期望的结果相比较,并检查它们是否相等。在标准库中提供了一对可以简化编程的宏:assert_eq!和assert_ne!。这两个宏分别用于比较并断言两个参数相等或不相等。在断言失败时,它们还可以自动打印出两个参数的值,从而方便我们观察测试失败的原因;相反,使用assert!宏则只能得知==判断表达式失败的事实,而无法知晓用于比较的值。
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ok_adds_two_eq() {
// 断言结果相同测试通过
assert_eq!(4, add_two(2));
}
#[test]
fn fail_adds_two_eq() {
// 断言结果不相同触发panic
assert_eq!(5, add_two(2));
}
#[test]
fn ok_adds_two_ne() {
// 断言结果不一致测试通过
assert_ne!(5, add_two(2));
}
#[test]
fn fail_adds_two_ne() {
// 断言结果相同触发panic
assert_ne!(4, add_two(2));
}
}
执行测试代码:
yuelong@yuelongdeMBP adder % cargo test
Compiling adder v0.1.0 (/Users/yuelong/CodeHome/TestProject/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.12s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 4 tests
test tests::ok_adds_two_ne ... ok
test tests::ok_adds_two_eq ... ok
test tests::fail_adds_two_eq ... FAILED
test tests::fail_adds_two_ne ... FAILED
failures:
---- tests::fail_adds_two_eq stdout ----
thread 'tests::fail_adds_two_eq' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `4`', src/lib.rs:16:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
---- tests::fail_adds_two_ne stdout ----
thread 'tests::fail_adds_two_ne' panicked at 'assertion failed: `(left != right)`
left: `4`,
right: `4`', src/lib.rs:26:9
failures:
tests::fail_adds_two_eq
tests::fail_adds_two_ne
test result: FAILED. 2 passed; 2 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
测试顺利通过检查。
3.3. 添加自定义的错误提示信息
我们也可以添加自定义的错误提示信息,将其作为可选的参数传入assert!、assert_eq!和assert_ne!宏。实际上面任何在assert!、assert_eq!和assert_ne!的必要参数之后出现的参数都会一起被传递给format!宏。因此,你甚至可以将一个包含{}占位符的格式化字符串及相对应的填充值作为参数一起传递给这个宏。自定义的错误提示信息可以很方便地记录当前断言的含义;这样在测试失败时,我们就可以更容易的知道代码到底出了什么问题。
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_test() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{}`", result
)
}
}
当测试失败之后:
running 1 test
test tests::greeting_test ... FAILED
failures:
---- tests::greeting_test stdout ----
thread 'tests::greeting_test' panicked at 'Greeting did not contain name, value was `Hello!`', src/lib.rs:16:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_test
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
这次的测试输出中包含了实际的值,他能帮助我们观察程序真正发生的行为,并迅速定位与预期产生差异的地方。
3.4. 使用should_panic检查paninc
除了检查代码是否返回了正确的结果,确认代码能否按照预期处理错误状态同样重要。
pub struct Guess {
value: u32,
}
impl Guess {
pub fn new(value: u32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
pub fn new_plus(value: u32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn new_test() {
// 此时肯定会发生错误, 但是因为加了should_panic宏,所有测试通过
Guess::new(200);
}
#[test]
#[should_panic]
fn new_plus_test() {
// 此时不会发生错误, 但是因为加了should_panic宏,所有测试无法通过
Guess::new(200);
}
}
执行cargo test并不会失败:
running 2 tests
test tests::new_plus_test - should panic ... FAILED
test tests::new_test - should panic ... ok
failures:
---- tests::new_plus_test stdout ----
note: test did not panic as expected
failures:
tests::new_plus_test
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
使用should_panic进行的测试可能会有些模糊不清,因为他们仅仅能够说明被检查的代码会发生panic。即便函数发生panic的原因和我们预期的不同,使用should_panic进行测试也会顺利通过。为了让should_panic测试更加精确一些,我们可以在should_panic属性中添加可选参数expected。它会检查panic发生时输出的错误提示信息是否包含了指定的文字。例子:
pub struct Guess {
value: u32,
}
impl Guess {
pub fn new(value: u32) -> Guess {
if value < 1 {
panic!("Guess value must be greater than or equal to 1, got {}.", value);
} else if value > 100 {
panic!("Guess value must be less than or equal to 100, got {}.", value);
} else {
Guess { value }
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "Guess value must be less than or equal to 100")]
fn new_test() {
// 此时肯定会发生错误
Guess::new(0);
}
}
此时再次执行测试:
running 1 test
test tests::new_test - should panic ... FAILED
failures:
---- tests::new_test stdout ----
thread 'tests::new_test' panicked at 'Guess value must be greater than or equal to 1, got 0.', src/lib.rs:8:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 0."`,
expected substring: `"Guess value must be less than or equal to 100"`
failures:
tests::new_test
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
3.5. 使用Result<T, E>编写测试
到目前为止,我们编写的测试都会在运行失败时触发panic。不过我们也可以用Result<T, E>来编写测试!例子:
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}
在函数体中,我们不再调用assert_eq!宏,而是在测试的时候通过时返回Ok(()),在失败时返回一个带有String的Err值。
不要在使用Reuslt<T, E>编写的测试上标注#[should_panic]。在测试失败时,我们应该直接返回一个Err值。
四. 控制测试的运行方式
如同cargo run会编译代码并运行生成的二进制文件一样,cargo test同样会在测试环境下编译代码,并运行生成的测试二进制文件。你可以通过指定命令行参数来改变cargo test的默认行为。
cargo test --help // 查看cargo test的可用参数
cargo test -- --help // 显示出所有可用在 -- 之后的参数
4.1. 并行或串行的进行测试
当我们尝试运行多个测试,Rust会默认使用多线程来执行它们。这样可以让测试更快地运行完毕。从来尽早得到代码是否可以正常工作的反馈。但是由于测试是同时进行的,所以开发者必须保证测试之间不会互相依赖,或者依赖到同一个共享的状态或环境上,例如当前工作目录、环境变量等。
如果你不想必行运行测试,或者希望精确的控制测试时所启动的线程数量,那么可以通过给测试二进制文件传入 —test-threads标记及期望的具体线程数量来控制这一行为。
cargo test -- --test-threads=1 // 将线程数量控制为1,这也意味着程序不会使用任何并行操作,使用单线程执行测试会比并行话费更多的时间,但是顺序执行不会再因为共享状态而出现可能的干扰情形了
4.2. 显示函数输出
默认情况下,Rust的测试库会在测试通过时捕获所有被打印至标准输出中的消息。当我们测试通过,它所打印的内容就无法显示在终端上;我们只能看到一条用于指明测试通过的消息。只有在测试失败时,我么你才能在错误提示信息的上方观察到打印至标准输出中的内容。例子:
pub fn add(x: i32, y: i32) -> i32 {
println!("x => {}, y => {}", x, y); // @1
x + y
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test() {
assert_eq!(4, add(2, 2))
}
}
我们希望在测试通过时也将值打印出来,那么可以传入—nocapture标记来禁用输出截获功能,执行下面的命令比较输出结果:
cargo test -- --nocapture // 会将@1也输出显示
cargo test // 没有输出@1
4.3. 只运行部分特定名称的测试
执行全部的测试用例有时会花费很长时间。而在编写某个特定部分的代码时,你也许只需要运行和代码相对应地那部分测试。我们可以通过cargo test中传递测试名称来指定需要运行的测试。例子:
pub fn add(x: i32, y: i32) -> i32 {
println!("x => {}, y => {}", x, y);
x + y
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test() {
assert_eq!(4, add(2, 2))
}
#[test]
fn new_test_1() {
assert_eq!(5, add(2, 2))
}
#[test]
fn test_1() {
assert_eq!(6, add(2, 2))
}
}
这时我们可以指定测试名称进行单独测试:
cargo test new_test_1
另外我们可以使用名称过滤运行多个测试:
cargo test new // 此时就会匹配到 new_test 和 new_test_1这两个测试
4.4. 通过显示指定来忽略某些测试
有时,一些特定的测试执行起来会非常耗时,所有你可能会想要在大部分的cargo test命令中忽略它们。除了手动将想要运行的测试列举出来,我们也可以使用ignore属性来标记这些耗时的测试,将这些测试排除在正常的测试运行之外。
pub fn add(x: i32, y: i32) -> i32 {
println!("x => {}, y => {}", x, y);
x + y
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn new_test_1() {
assert_eq!(5, add(2, 2))
}
#[test]
#[ignore]
fn test_1() {
assert_eq!(6, add(2, 2))
}
}
此时我们执行cargo test时就可以很明显的看到ignored的标识:
xxxxxx@xxxxxxx adder % cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 3 tests
test tests::test_1 ... ignored
test tests::new_test ... ok
test tests::new_test_1 ... FAILED
此时我们也可以使用cargo test —- —-ignored来单独运行这些被忽略的测试。
xxxxx@xxxxxx adder % cargo test -- --ignored
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 1 test
test tests::test_1 ... FAILED
failures:
---- tests::test_1 stdout ----
五. 测试的组织结构
Rust社区主要从以下两个分类来讨论测试:单元测试(unit test)和集成测试(integration test)。单元测试小而专注,每次只单独测试一个模块或私有接口。而集成测试完全位于代码库之外,和正常从外部调用代码一样使用外部代码,只能访问公共接口,而且再一次测试中可能会联用多个模块。
5.1. 单元测试
单元测试的目的在于将一小段代码单独隔离出来,从而迅速确定这段代码的功能是否符合预期。我们一般将单元测试与需要测试的代码存放在src目录下的同一文件中。同时也约定俗称地在每个源代码文件中都新建一个tests模块来存放测试函数,并使用cfg(test)对该模块进行标注。
在tests模块上标注#[cfg(test)]可以让Rust只在执行cargo test命令时编译和运行该部分测试代码,而在执行cargo build时剔除它们。这样就可以在正常编译时不包含测试代码,从而节省编译时间和产出物所占用的空间。我们不需要对集成测试标注#[cfg(test)],因此集成测试本省就放置在独立的目录中。但是,由于本身测试是和业务代码并列放置在同一文件中,所有我们必须使用#[cfg(test)]进行标注才能将单元测试的代码排除在编译产出物之外。Rust是允许测试私有函数,例子:
// 共有函数
pub fn add(x: i32, y: i32) -> i32 { x + y }
// 私有函数
fn sub(x: i32, y: i32) -> i32 { x - y }
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_test() {
assert_eq!(4, add(2, 2))
}
#[test]
fn sub_test() {
assert_eq!(0, sub(2, 2))
}
}
5.2. 集成测试
在Rust中,集成测试是完全位于代码库之外的。集成个测试调用库的方式和其他的代码调用方式没有任何不同,这也意味着你只能调用对外公开提供的那部分接口。集成测试的目的在于验证库的不同部分能否协同起来工作。能够独立对外公开提供的那部分接口。集成测试的目的在于验证库的不同部分能否协同起来正常工作。能够独立正常工作的单元代码的集成运行时也会发生各种问题,所有集成测试的覆盖同样是非常重要的。
为了创建集成测试,我们需要首先建立一个tests目录。tests是文件夹和src文件夹并列。Cargo会自动在这个目录下寻找集成测试文件。在这个目录下创建任意多个测试文件,Cargo在编译时会将每个文件都处理为一个独立的包。
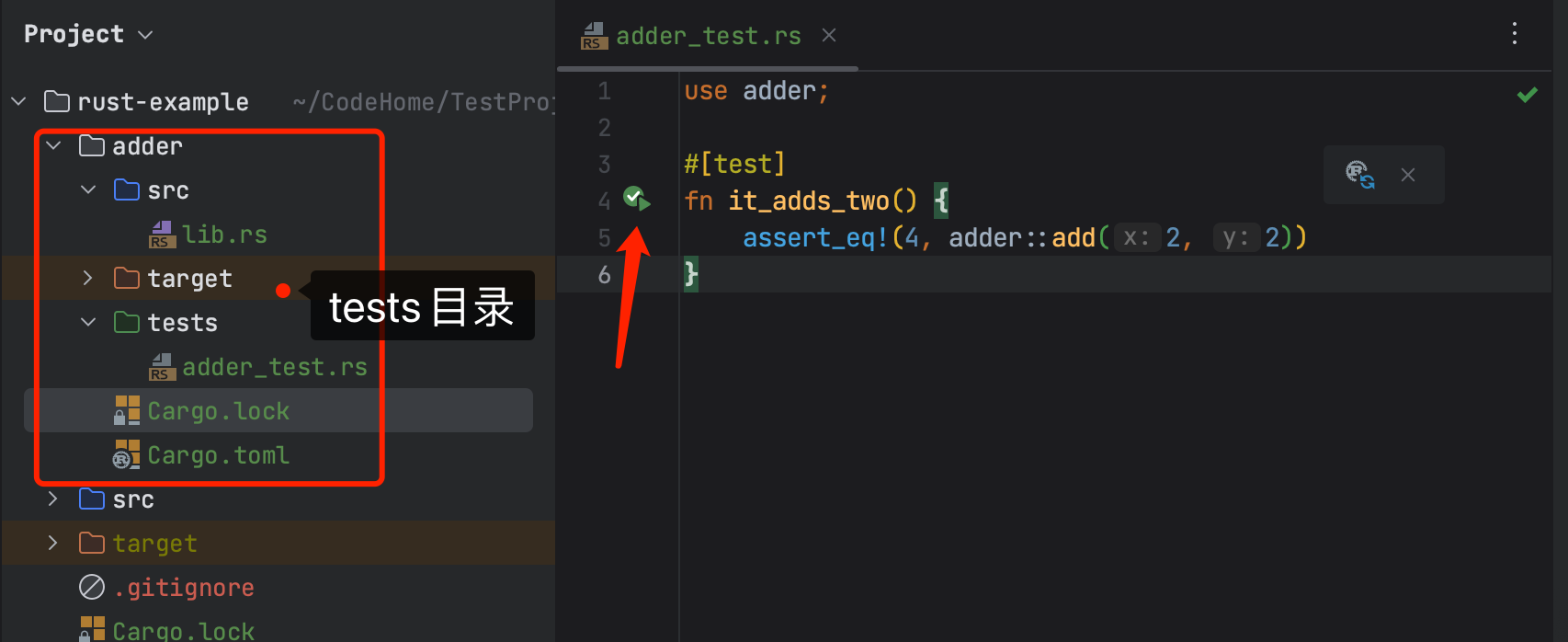
我们在执行cargo test
xxxxxx@xxxxxxx adder % cargo test
Compiling adder v0.1.0 (/rust-example/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.15s
Running unittests src/lib.rs (target/debug/deps/adder-96bda0c2404f749c)
running 1 test
test tests::add_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/adder_test.rs (target/debug/deps/adder_test-4bc3058753e422c8). // 执行集成测试
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
如果此时有多个测试函数,我们可以指定函数名,单独运行特定的集成测试函数:
cargo test --test add_test
随着集成测试增加,我们可以把tests目录下的代码分离到多个文件中。将每个集成测试的文件编译成独立的包有助于隔离作用域,并使集成测试环境更加贴近于用户的使用场景。
但是在tests目录中添加模块并不是简单的添加一个文件,如图:
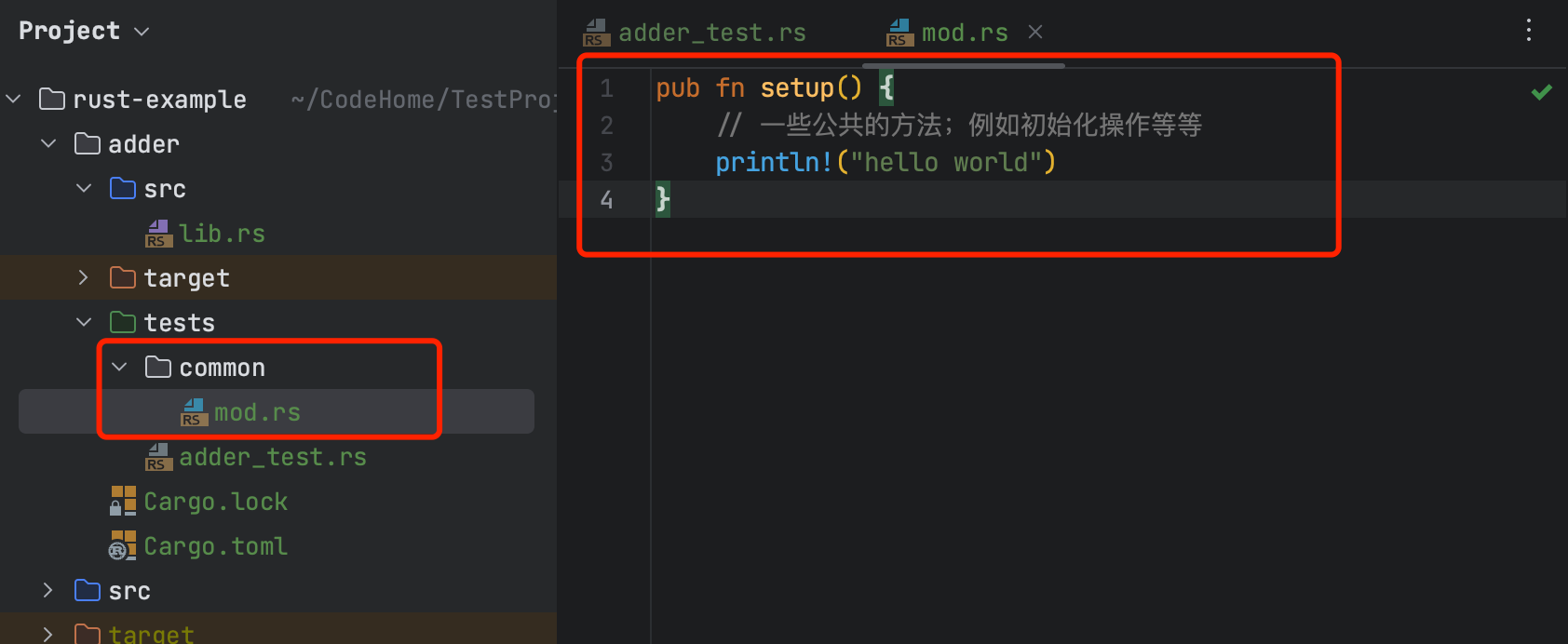
接着我们就可以在测试函数中引用了
mod common; // 引入模块
use adder;
#[test]
fn it_adds_two() {
common::setup(); // 调用
assert_eq!(4, adder::add(2, 2))
}
最后需要注意一点,如果我们的项目是一个只有src/main.rs文件而没有src/lib.rs文件的二进制包,那么我们就无法在tests目录中创建集成测试,也无法使用过use将src/main.rs中定义的函数导入作用域。只有代码包(library crate)才可以将函数暴露给其他包调用,而二进制包只被用于独立执行。
![[LeetCode周赛复盘] 第 322 场周赛20221204](https://img-blog.csdnimg.cn/13704aaa394e4710b5355955dff685a5.png)


![[附源码]Python计算机毕业设计Django汽车美容店管理系统](https://img-blog.csdnimg.cn/07ab0e30abf14c7496e562d0ca8a2715.png)