文章目录
- 前言
- 一、为什么HashMap是无序的
- 二、LinkedHashMap如何保证有序性
- 三、TreeMap的底层原理
- 四、LinkedHashMap和TreeMap比较
- 总结
前言
为什么HashMap是无序的?有序的Map集合有哪些?LinkedHashMap和TreeMap都是有序的Map集合,他们有什么区别,该如何选用?LinkedHashMap和TreeMap的底层原理是什么?
一、为什么HashMap是无序的
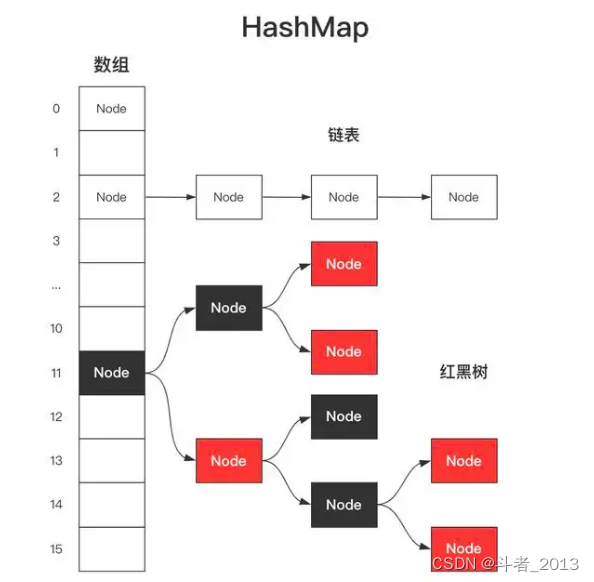
要搞清楚HashMap为什么是无序的,首先我们要搞清楚HashMap的底层数据结构。很多人可能会说简单,HashMap的底层不就是链表散列结构,那什么是链表散列结构呢?
用更直白的话说就是数组+链表+红黑树(java8)。
HashMap中存放的元素是根据key和hash(key)存放在数组、链表和红黑树中,而整个HashMap结构中并没有对每个元素的存放顺序做相关的记录,所以不能保证元素遍历顺序和存放顺序的一致性。
可能有人会说,无论是数组、链表和红黑树都是有序的结构,为什么遍历顺序就不能和存放顺序保持一致。
其核心点是:HashMap会根据hash(key)和数组长进行取模获取bucketIndex确定元素存放的槽位,而取模算法的除数table.length会随着HashMap中元素个数的变化而进行的扩容而产生变化,这就导致根据hash(key)取模分配得到的槽位并不是固定的,从而导致了HashMap是遍历顺序和存放顺序的不一致
注意⚠️:
HashMap虽然不能保证元素遍历的顺序和存放顺序的一致性,但是多次遍历HashMap ,顺序不变。
简单说下向HashMap中存放一个新元素的步骤:
1、首先对key值进行hash计算
2、对hash(key)和数组长进行取模运算,得到bucketIndex。即根据key的hash值取模确认数据存放在哪个数组位上。
3、判断对应的数组槽位上是否有数据,如果没有数据则直接存放新数据,如果有数据则判断已有数据和新加入数据的key值是否相等。
4、数组对应槽位上的数据key值相等的话,直接更新value值。
5、数组对应槽位上的数据key值不相等的话,槽位上的是树节点则向树结构中添加新节点,槽位上的是非树节点则向链表中添加新节点。
相关源码说明:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//1、通过位运算(n - 1) & hash取模,获取tab数值的index ,等价于hash%table.length
if ((p = tab[i = (n - 1) & hash]) == null)
//2、数组tab的index位为null,则直接存放新数据
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//3、数组tab的index位不为空,key值相等,则更新旧值的value值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//4、数组tab的index位元素的key值不相等,且元素为树节点,则在树结构中添加新节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//5、数组tab的index位元素的key值不相等,且元素非树节点,则在链表中添加新节点
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
二、LinkedHashMap如何保证有序性
通过上面的分析我们知道HashMap为什么不能保证遍历顺序和存放顺序的一致性。核心原因是HashMap底层是通过数组+链表+红黑树的混合结构来保存元素,并没有引入额外的属性保证元素的存放顺序。
那么,我们是否可以引入一些有序的数据结构来保存HashMap元素的存放顺序呢?答案是可以的。
LinkedHashMap正是通过引入了链表结构来保存元素的存放顺序。
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处 : 迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
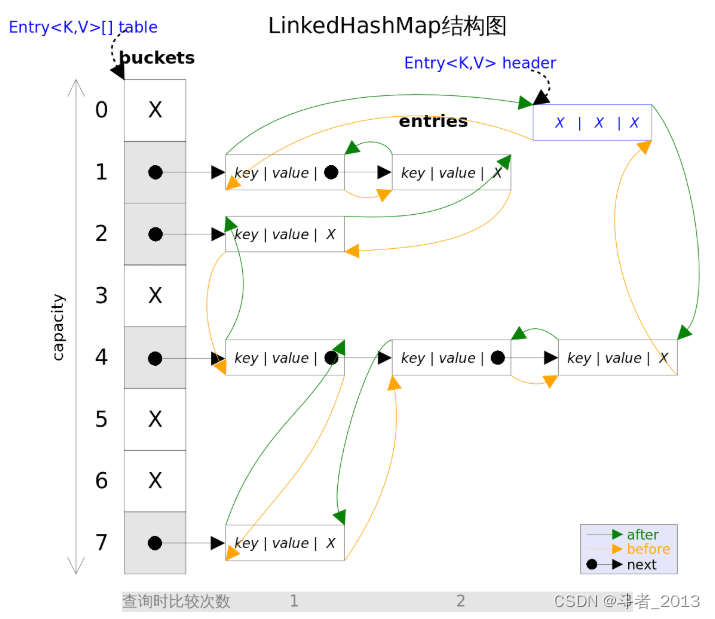
LinkedHashMap中的节点说明:
//继承了HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
//当前节点的前一个节点before、后一个节点after
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
……
}
三、TreeMap的底层原理
很多人喜欢将TreeMap和LinkedHashMap放在一起比较,误认为两种都能保证数据的有序性,这其实是错误的。
LinkedHashMap可以保证遍历顺序和存放顺序的一致性。
TreeMap由于元素插入的时候会根据key进行排序,所以并不能保证遍历顺序和存放顺序的一致性。
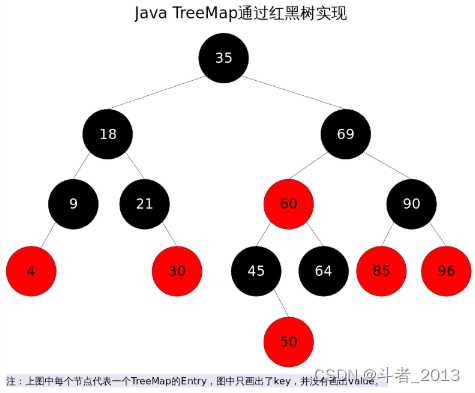
Java TreeMap实现了SortedMap接口,也就是说会按照key的大小顺序对Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。
TreeMap底层通过红黑树(Red-Black tree)实现,也就意味着containsKey(), get(), put(), remove()都有着log(n)的时间复杂度。其具体算法实现参照了《算法导论》。
四、LinkedHashMap和TreeMap比较
- 底层结构:LinkedHashMap底层还是沿用了HashMap的存储结构,核心区别在于节点属性中通过额外添加前后元素的属性,采用链表方式保存了元素存放的顺序。而TreeMap底层采用的是红黑树结构,存放的元素会根据key的大小顺序。
- 有序性:LinkedHashMap能够保证遍历顺序和存放顺序的一致性,而TreeMap由于在存放元素的时候会根据Key值进行排序,所以不能保证遍历顺序和存放顺序的一致性。但两者都能保证多次遍历的顺序一致性。
- 性能比较:LinkedHashMap无论是在新增、修改、删除还是根据根据Key值进行等值查找时,都有比TreeMap更好的性能,但是在根据Key值进行区间检索、范围查询时TreeMap更有优势。
- 使用场景:HashMap是Key-Value数据结构的首选类型,性能最高,能满足绝大部分的场景,如果还需要保证集合的遍历和存放顺序的一致性可以采用LinkedHashMap,如果需要根据Key值顺序对集合内存放的元素进行排序则推荐采用TreeMap。
总结
本文主要是结合HashMap、LinkedHashMap和TreeMap的底层原理对3者的有序性进行了说明,并比较了3者在使用上的差异,大家可以根据项目中的实际业务场景来灵活选用。