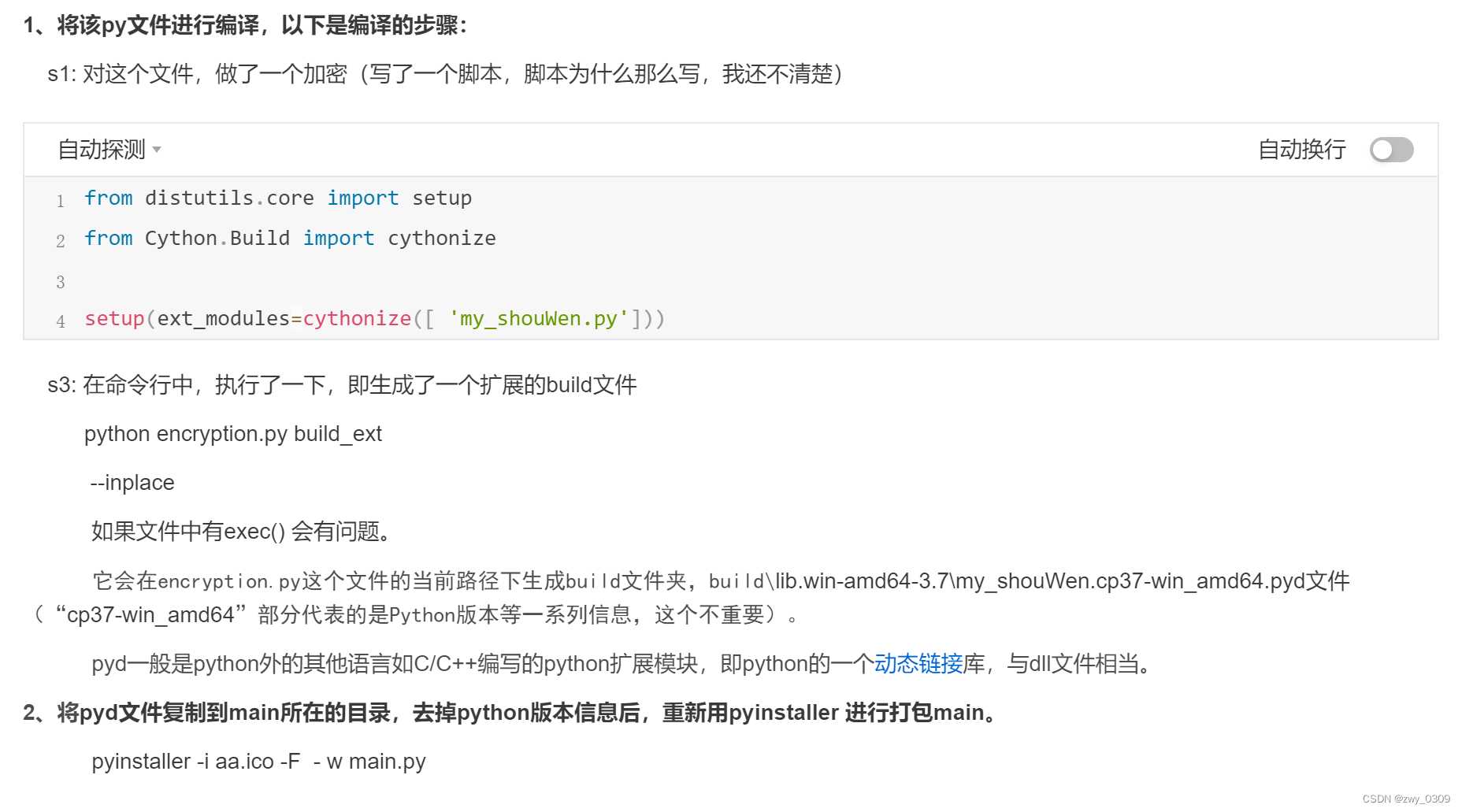
线程池
经历了Java内存模型、JUC基础之AQS、CAS、Lock、并发工具类、并发容器、阻塞队列、atomic类后,我们开始JUC的最后一部分:线程池。
线程池的优势
为什么多线程会带来性能问题
多线程的性能问题,分为两类,一类是线程本身的调度,另一类是线程之间的协作开销。
线程调度开销
上下文切换
在实际开发中,线程数往往是大于 CPU 核心数的,比如 CPU 核心数可能是 8 核、16 核,等等,但线程数可能达到成百上千个。
这种情况下,操作系统就会按照一定的调度算法,给每个线程分配时间片,让每个线程都有机会得到运行。而在进行调度时就会引起上下文切换,上下文切换会挂起当前正在执行的线程并保存当前的状态,然后寻找下一处即将恢复执行的代码,唤醒下一个线程,以此类推,反复执行。
但上下文切换带来的开销是比较大的,假设我们的任务内容非常短,比如只进行简单的计算,那么就有可能发生我们上下文切换带来的性能开销比执行线程本身内容带来的开销还要大的情况。
缓存失效
由于程序有很大概率会再次访问刚才访问过的数据,所以为了加速整个程序的运行,会使用缓存,这样我们在使用相同数据时就可以很快地获取数据。
可一旦进行了线程调度,切换到其他线程,CPU就会去执行不同的代码,原有的缓存就很可能失效了,需要重新缓存新的数据,这也会造成一定的开销。
所以线程调度器为了避免频繁地发生上下文切换,通常会给被调度到的线程设置最小的执行时间,也就是只有执行完这段时间之后,才可能进行下一次的调度,由此减少上下文切换的次数。
如果程序频繁地竞争锁,或者由于 IO 读写等原因导致频繁阻塞,那么这个程序就可能需要更多的上下文切换,这也就导致了更大的开销,我们应该尽量避免这种情况的发生。
协作开销
因为线程之间如果有共享数据,为了避免数据错乱,为了保证线程安全,就有可能禁止编译器和 CPU 对其进行重排序等优化。
也可能出于同步的目的,反复把线程工作内存的数据 flush 到主存中,然后再从主内存 refresh 到其他线程的工作内存中,等等。
这些问题在单线程中并不存在,但在多线程中为了确保数据的正确性,就不得不采取上述方法,因为线程安全的优先级要比性能优先级更高,这也间接降低了我们的性能。
线程池的诞生,是为了解决在大量线程下效率不见提升反而降低的情况。
如何提升运行效率
解决反复创建线程,性能开销大
使用固定的数量的线程一直保持工作状态,并返回执行任务
多线程占用内存资源
根据业务需要创建线程,控制线程总数量,避免占用过多内存资源
使用线程池的好处
可以解决线程生命周期的系统开销问题,同时还能够加快响应速度。
因为线程池中的线程是可以复用的,我们只需要少量的线程就可以执行大量的任务。
大大的减少了创建线程时候的资源消耗
可以统筹CPU和内存的使用,避免资源使用不当。
线程池能够根据配置灵活的控制线程数量,不够就创建,多了就回收,避免线程过多导致内存溢出,也避免了CPU资源的浪费
可以统一管理资源。
统一管理任务队列和线程,可以统一开始或结束任务,比单个线程处理任务要更方便
线程池的思想
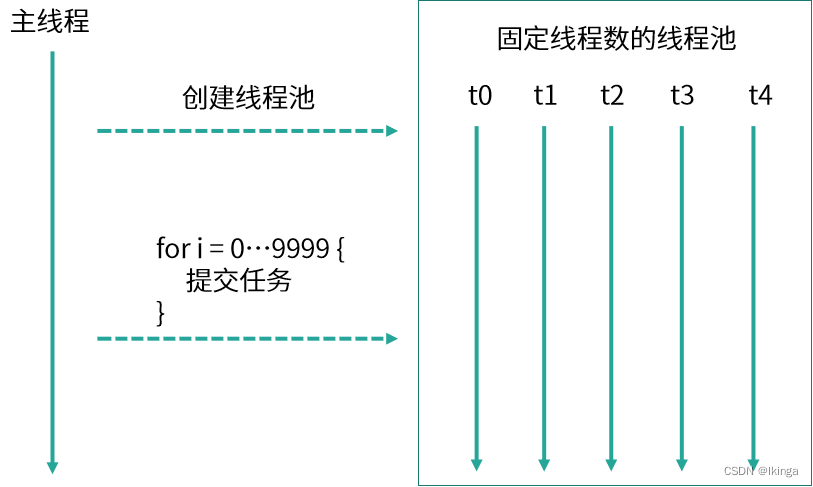
首先创建了一个线程池,线程池中有 5 个线程,然后线程池将 10000 个任务分配给这 5 个线程,这 5 个线程反复领取任务并执行,直到所有任务执行完毕,这就是线程池的思想。
创建线程池
在Java中创建线程都是通过一个ThreadPoolExecutor对象来进行创建的。
ThreadPoolExecutor类最多有5个构造函数,用于创建不同特性的线程池
参数列表
| 参数名 | 含义 |
|---|---|
| corePoolSize | 核心线程数 |
| maximumPoolSize | 最大线程数 |
| keepAliveTime | 空闲线程存活时长 |
| unit | 空闲线程存活时间单位 |
| workQueue | 用于存放任务的队列 |
| threadFactory | 线程工厂,用于来创建新线程 |
| handler | 处理被拒绝的任务 |
创建时机
线程池创建线程的时机
在最大线程创建出来之后,回去判断线程的存活时间,如果存活时间大于所设定的值,则会将这些创建出来的回收
线程工厂ThreadFactory
hreadFactory 实际上是一个线程工厂,它的作用是生产线程以便执行任务。我们可以选择使用默认的线程工厂,创建的线程都会在同一个线程组,并拥有一样的优先级,且都不是守护线程,我们也可以选择自己定制线程工厂,以方便给线程自定义命名,不同的线程池内的线程通常会根据具体业务来定制不同的线程名。
默认的线程工厂:
private static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
工作队列WorkQueue
用于存放任务的队列列表。
线程的不同的特性,就是通过这个存放任务的列表来实现的。
| 线程池 | 实现队列 | 特性 |
|---|---|---|
| FixedThreadPool | LinkedBlockingQueue | 没有额外线程,只存在核心线程,而且核心线程没有超时机制,而且任务队列没有长度的限制 |
| SingleThreadExecutor | LinkedBlockingQueue | 内部只有一个核心线程,它确保所有的任务都在同一个线程中按顺序执行。 |
| CachedThreadPool | SynchronousQueue | 只有非核心线程,并且其最大线程数为Integer.MAX_VALUE |
| ScheduledThreadPool SingleThreadScheduledExecutor | DelayedWorkQueue | 按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构 |
看下面ThreadPool的结构,workQueue就是用来存放添加的任务,然后交由给不同的线程去执行。
ThreadPool结构
拒绝策略Handler
用于处理核心线程满、队列满、最大线程满了之后,现在添加不进去之后的策略。
img
DiscardPolicy
当新任务提交之后会被直接丢弃,也不会有任何的通知,相对而言存在一定的风险,因为在提交的时候并不知道线程会被丢弃,会存在数据丢失的风险
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
DiscardOldestPolicy
丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与DiscardPolicy不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
CallerRunsPolicy
当触发拒绝策略时,只要线程池没有关闭,就由提交任务的当前线程处理。
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
AbortPolicy
当任务提交到这里,会抛出RejectedExecutionException异常
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
如何设置线程数
大多数文章都在扯要区分是计算密集型还是IO密集型,但是实际情况远比区分这两种复杂的多,一个线程数的设置会收到多个方面的影响。
在这个方面,美团给出了一个回答,动态设置 《Java线程池实现原理及其在美团业务中的实践》(opens new window) https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
线程池使用面临的核心的问题在于: 线程池的参数并不好配置 。
一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;
另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考。
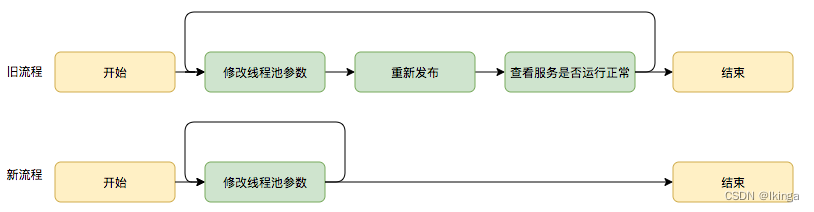
美团给出的方案是线程池参数动态化:
尽管经过谨慎的评估,仍然不能够保证一次计算出来合适的参数,那么我们是否可以将修改线程池参数的成本降下来,这样至少可以发生故障的时候可以快速调整从而缩短故障恢复的时间呢?
基于这个思考,我们是否可以将线程池的参数从代码中迁移到分布式配置中心上,实现线程池参数可动态配置和即时生效
现有的解决方案
目前市场上都是在区分IO密集型 还是计算密集型
在《Java并发编程实战》是这么描述的
-
假设机器有N个CPU,那么对于计算密集型的任务,应该设置线程数为N+1;
-
对于IO密集型的任务,应该设置线程数为2N;
-
对于同时有计算工作和IO工作的任务,应该考虑使用两个线程池,一个处理计算任务,一个处理IO任务,分别对两个线程池按照计算密集型和IO密集型来设置线程数。
这种方式有几个问题:
- 实际项目中,往往会有多个线程池对业务进行一个线程隔离,如果都是2*N的线程数量,肯定是不合理的
- 线程池承担的流量不可能是均衡的,每个时间点都会由于自身的业务特点,出现毛刺
- 线程池尝尝会被用于调用下游接口,线程池设置了2*N,直接把下游打挂了
所以,种种问题催生出了美团的动态化配置,动态化配置+线程池监控完美的解决的以上的问题。
动态更新的原理
JDK原生线程池ThreadPoolExecutor提供了如下几个public的setter方法,如下图所示:

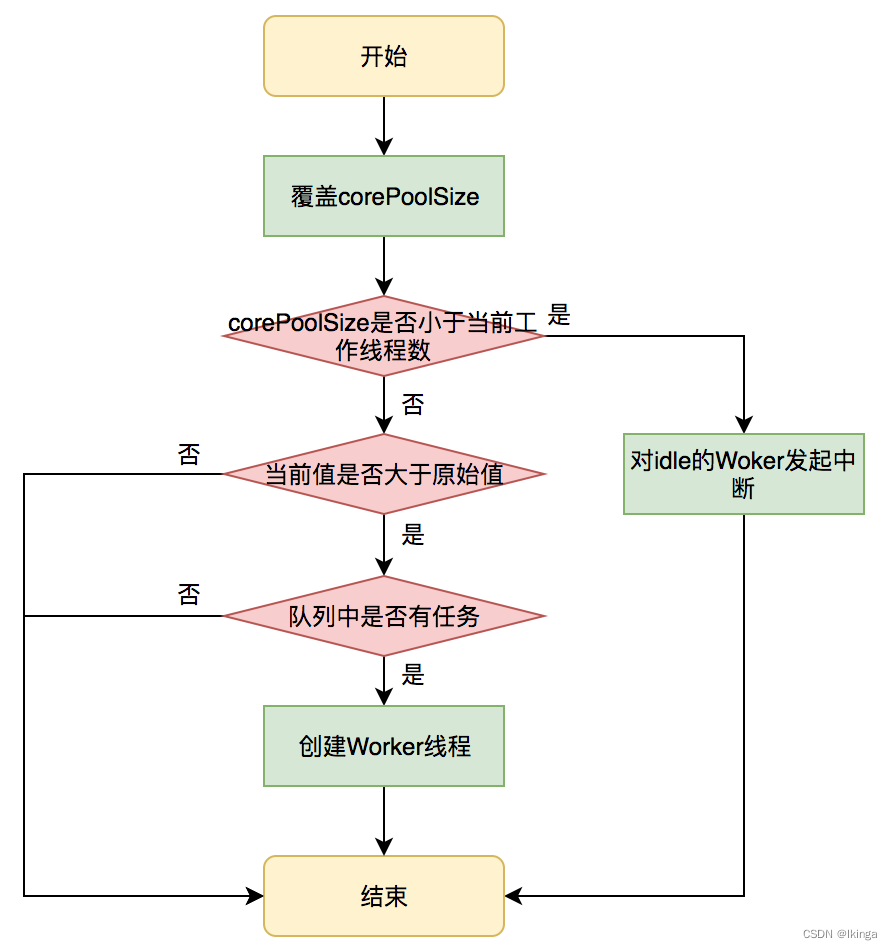
JDK允许线程池使用方通过ThreadPoolExecutor的实例来动态设置线程池的核心策略,以setCorePoolSize为方法例,在运行期线程池使用方调用此方法设置corePoolSize之后,线程池会直接覆盖原来的corePoolSize值,并且基于当前值和原始值的比较结果采取不同的处理策略。
对于当前值小于当前工作线程数的情况,说明有多余的worker线程,此时会向当前idle的worker线程发起中断请求以实现回收,多余的worker在下次idel的时候也会被回收;
对于当前值大于原始值且当前队列中有待执行任务,则线程池会创建新的worker线程来执行队列任务,setCorePoolSize具体流程如下:
面试考点
- 线程池被创建后里面有线程吗?如果没有的话,你知道有什么方法对线程池进行预热吗?
线程池被创建后如果没有任务过来,里面是不会有线程的。
可以通过prestartAllCoreThreads方法启动所有线程
或者通过prestartCoreThread预先启动一个线程
核心线程数会被回收吗?需要什么设置?
- 核心线程数默认是不会被回收的,如果需要回收核心线程数,需要调用allowCoreThreadTimeOut 该值默认为 false
线程池线程复用原理
线程池最大的优势就在于可以复用线程,以减少创建和销毁时带来的消耗。线程池运行一堆固定数量的任务,需要的线程数远小于任务的数量,精髓就在于线程复用,让同一个线程去执行不同的任务。
线程池创建线程的时机
依旧是这张图,我们能从中可以看到,有三个关键的地方
- 当前线程数小于核心线程数创建线程
- 核心线程数已满,就往任务队列里面塞
- 任务队列和核心线程都满了,就创建非核心线程用于分摊压力
- 当前三个都无法塞入的时候,拒绝执行
具体执行的代码在 ThreadPoolExecutor的execute中
实现方式
来看看是怎么实现的。(最核心的代码)
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// ctl属性的高3位,提供了线程池的运行状态,包含线程池主要生命周期。
// 剩余位记录线程池线程个数
int c = ctl.get();
// 如果工作线程的数量小于核心线程数 (步骤1)
if (workerCountOf(c) < corePoolSize) {
// 如果核心线程没有满,创建核心线程执行任务,如果返回false说明在创建核心线程的时候线程数已经满了
if (addWorker(command, true))
return;
c = ctl.get();
}
// 当前线程池的状态是正在运行,就把任务放入到队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 重新检查一番,如果这个时候线程池被关闭了,则从队列中移除这个任务,并执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
// 如果检查下来运行的线程数量为0,就调用addWorker创建新的线程
addWorker(null, false);
}
// 线程池关闭,或者队列已经满了,就去判断最大线程数是否满了,步骤3
else if (!addWorker(command, false))
// 最大线程数满了,执行拒绝策略
reject(command);
}
线程复用的秘密就是在这个addWorker里面。
private boolean addWorker(Runnable firstTask, boolean core) {
/**
* 跳过上面一大段检查队列的直接看启动
*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
.....
if (t != null) {
// 加锁
if (workerAdded) {
// 启动,
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
}
通过内置的Worker对象,把自己的firstTask作为任务封装进去,重写了run方法,所以在调用start方法的时候会调用的worker的run方法
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 加个死循环,不断的从队列中获取任务,并执行----这里的task才是我们要执行的业务代码
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
try {
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
总结
复用的本质,就是将我们的Runable给封装起来,封装成一个个task,塞入到队列中。
然后使用worker线程,不断的轮训这个任务队列,直接执行,采用了代理模式,增强了原本runable的执行逻辑。
Executor
我们先看线程池的基础架构图:
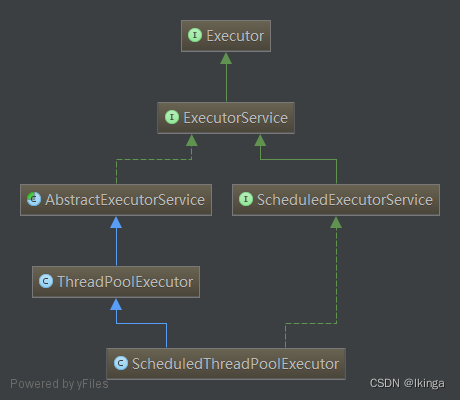
Executor,任务的执行者,线程池框架中几乎所有类都直接或者间接实现Executor接口,它是线程池框架的基础。Executor提供了一种将“任务提交”与“任务执行”分离开来的机制,它仅提供了一个Execute()方法用来执行已经提交的Runnable任务。
public interface Executor {
void execute(Runnable command);
}
ExcutorService
继承Executor,它是“执行者服务”接口,它是为"执行者接口Executor"服务而存在的。准确的地说,ExecutorService提供了"将任务提交给执行者的接口(submit方法)","让执行者执行任务(invokeAll, invokeAny方法)"的接口等等。
public interface ExecutorService extends Executor {
/**
* 启动一次顺序关闭,执行以前提交的任务,但不接受新任务
*/
void shutdown();
/**
* 试图停止所有正在执行的活动任务,暂停处理正在等待的任务,并返回等待执行的任务列表
*/
List<Runnable> shutdownNow();
/**
* 如果此执行程序已关闭,则返回 true。
*/
boolean isShutdown();
/**
* 如果关闭后所有任务都已完成,则返回 true
*/
boolean isTerminated();
/**
* 请求关闭、发生超时或者当前线程中断,无论哪一个首先发生之后,都将导致阻塞,直到所有任务完成执行
*/
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
/**
* 提交一个返回值的任务用于执行,返回一个表示任务的未决结果的 Future
*/
<T> Future<T> submit(Callable<T> task);
/**
* 提交一个 Runnable 任务用于执行,并返回一个表示该任务的 Future
*/
<T> Future<T> submit(Runnable task, T result);
/**
* 提交一个 Runnable 任务用于执行,并返回一个表示该任务的 Future
*/
Future<?> submit(Runnable task);
/**
* 执行给定的任务,当所有任务完成时,返回保持任务状态和结果的 Future 列表
*/
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
/**
* 执行给定的任务,当所有任务完成或超时期满时(无论哪个首先发生),返回保持任务状态和结果的 Future 列表
*/
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
/**
* 执行给定的任务,如果某个任务已成功完成(也就是未抛出异常),则返回其结果
*/
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
/**
* 执行给定的任务,如果在给定的超时期满前某个任务已成功完成(也就是未抛出异常),则返回其结果
*/
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
AbstractExecutorService
抽象类,实现ExecutorService接口,为其提供默认实现。AbstractExecutorService除了实现ExecutorService接口外,还提供了newTaskFor()方法返回一个RunnableFuture,在运行的时候,它将调用底层可调用任务,作为 Future 任务,它将生成可调用的结果作为其结果,并为底层任务提供取消操作。
ScheduledExecutorService
继承ExcutorService,为一个“延迟”和“定期执行”的ExecutorService。他提供了一些如下几个方法安排任务在给定的延时执行或者周期性执行。
// 创建并执行在给定延迟后启用的 ScheduledFuture。
<V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit)
// 创建并执行在给定延迟后启用的一次性操作。
ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit)
// 创建并执行一个在给定初始延迟后首次启用的定期操作,后续操作具有给定的周期;
//也就是将在 initialDelay 后开始执行,然后在 initialDelay+period 后执行,接着在 initialDelay + 2 * period 后执行,依此类推。
ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)
// 创建并执行一个在给定初始延迟后首次启用的定期操作,随后,在每一次执行终止和下一次执行开始之间都存在给定的延迟。
ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)
ThreadPoolExecutor
大名鼎鼎的“线程池”,后续做详细介绍。
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承ThreadPoolExecutor并且实现ScheduledExecutorService接口,是两者的集大成者,相当于提供了“延迟”和“周期执行”功能的ThreadPoolExecutor。
Executors
Executors

静态工厂类,提供了Executor、ExecutorService、ScheduledExecutorService、ThreadFactory 、Callable 等类的静态工厂方法,通过这些工厂方法我们可以得到相对应的对象。
- 创建并返回设置有常用配置字符串的 ExecutorService 的方法。
- 创建并返回设置有常用配置字符串的 ScheduledExecutorService 的方法。
- 创建并返回“包装的”ExecutorService 方法,它通过使特定于实现的方法不可访问来禁用重新配置。
- 创建并返回 ThreadFactory 的方法,它可将新创建的线程设置为已知的状态。
- 创建并返回非闭包形式的 Callable 的方法,这样可将其用于需要 Callable 的执行方法中。
Future
Future接口和实现Future接口的FutureTask代表了线程池的异步计算结果。
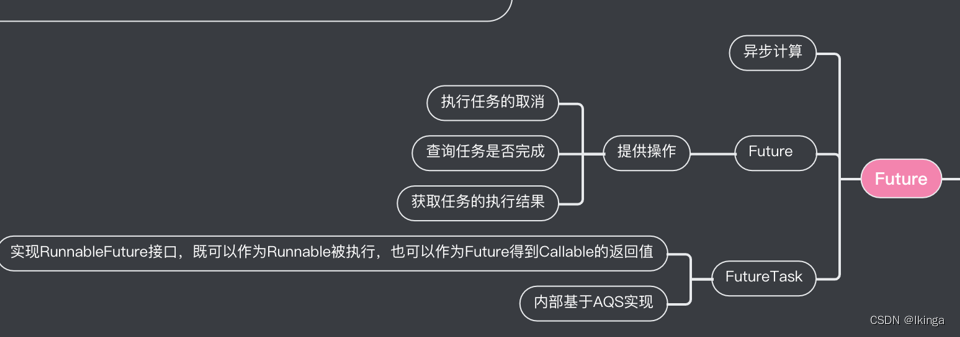
AbstractExecutorService提供了newTaskFor()方法返回一个RunnableFuture,除此之外当我们把一个Runnable或者Callable提交给(submit())ThreadPoolExecutor或者ScheduledThreadPoolExecutor时,他们则会向我们返回一个FutureTask对象。如下:
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
<T> Future<T> submit(Callable<T> task)
<T> Future<T> submit(Runnable task, T result)
Future<> submit(Runnable task)
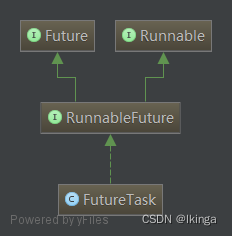
作为异步计算的顶层接口,Future对具体的Runnable或者Callable任务提供了三种操作:执行任务的取消、查询任务是否完成、获取任务的执行结果。其接口定义如下:
public interface Future<V> {
/**
* 试图取消对此任务的执行
* 如果任务已完成、或已取消,或者由于某些其他原因而无法取消,则此尝试将失败。
* 当调用 cancel 时,如果调用成功,而此任务尚未启动,则此任务将永不运行。
* 如果任务已经启动,则 mayInterruptIfRunning 参数确定是否应该以试图停止任务的方式来中断执行此任务的线程
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
* 如果在任务正常完成前将其取消,则返回 true
*/
boolean isCancelled();
/**
* 如果任务已完成,则返回 true
*/
boolean isDone();
/**
* 如有必要,等待计算完成,然后获取其结果
*/
V get() throws InterruptedException, ExecutionException;
/**
* 如有必要,最多等待为使计算完成所给定的时间之后,获取其结果(如果结果可用)
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
RunnableFuture
继承Future、Runnable两个接口,为两者的合体,即所谓的Runnable的Future。提供了一个run()方法可以完成Future并允许访问其结果。
public interface RunnableFuture<V> extends Runnable, Future<V> {
//在未被取消的情况下,将此 Future 设置为计算的结果
void run();
}
FutureTask
实现RunnableFuture接口,既可以作为Runnable被执行,也可以作为Future得到Callable的返回值。
ThreadPoolExecutor
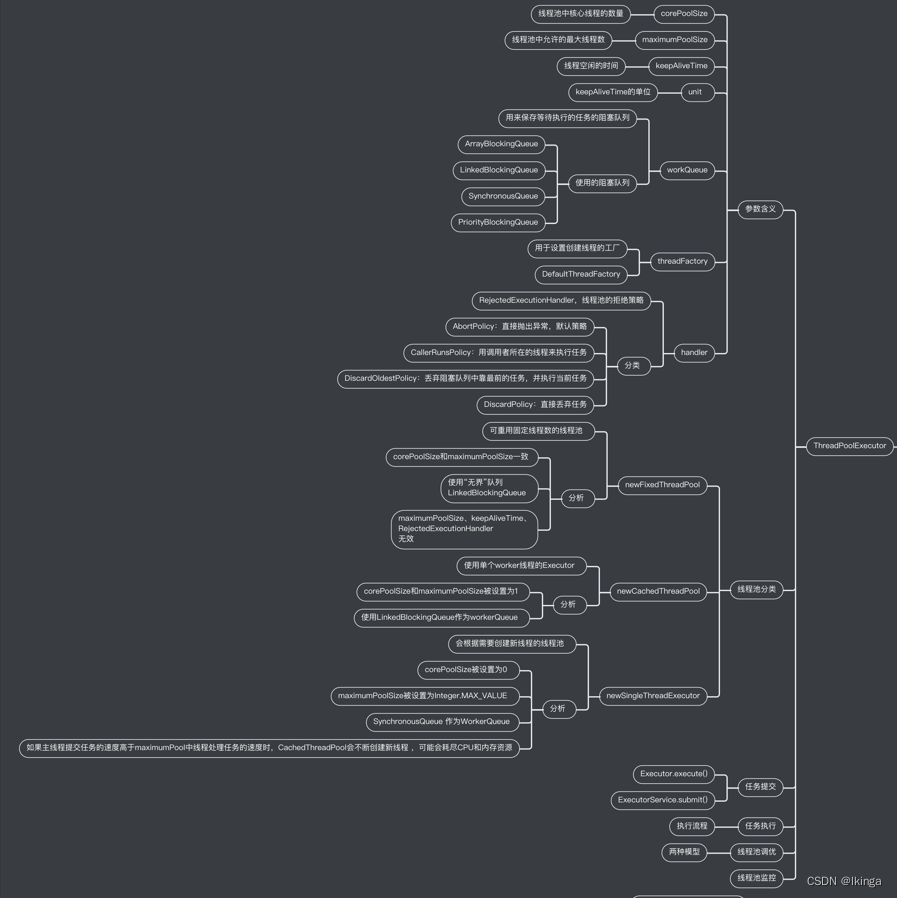
作为Executor框架中最核心的类,ThreadPoolExecutor代表着鼎鼎大名的线程池,它给了我们足够的理由来弄清楚它。
下面我们就通过源码来一步一步弄清楚它。
内部状态
线程有五种状态:新建,就绪,运行,阻塞,死亡,线程池同样有五种状态:Running, SHUTDOWN, STOP, TIDYING, TERMINATED。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
变量 ctl 定义为AtomicInteger ,其功能非常强大,记录了“线程池中的任务数量”和“线程池的状态”两个信息。共32位,其中高3位表示"线程池状态",低29位表示"线程池中的任务数量"。
RUNNING -- 对应的高3位值是111。
SHUTDOWN -- 对应的高3位值是000。
STOP -- 对应的高3位值是001。
TIDYING -- 对应的高3位值是010。
TERMINATED -- 对应的高3位值是011。
RUNNING :处于RUNNING状态的线程池能够接受新任务,以及对新添加的任务进行处理。
SHUTDOWN :处于SHUTDOWN状态的线程池不可以接受新任务,但是可以对已添加的任务进行处理。
STOP :处于STOP状态的线程池不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
TIDYING :当所有的任务已终止,ctl记录的"任务数量"为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
TERMINATED :线程池彻底终止的状态。
各个状态的转换如下:

创建线程池
我们可以通过ThreadPoolExecutor构造函数来创建一个线程池:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
共有七个参数,每个参数含义如下:
corePoolSize
线程池中核心线程的数量。当提交一个任务时,线程池会新建一个线程来执行任务,直到当前线程数等于corePoolSize。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
maximumPoolSize
线程池中允许的最大线程数。线程池的阻塞队列满了之后,如果还有任务提交,如果当前的线程数小于maximumPoolSize,则会新建线程来执行任务。注意,如果使用的是无界队列,该参数也就没有什么效果了。
keepAliveTime
线程空闲的时间。线程的创建和销毁是需要代价的。线程执行完任务后不会立即销毁,而是继续存活一段时间:keepAliveTime。默认情况下,该参数只有在线程数大于corePoolSize时才会生效。
unit
keepAliveTime的单位。TimeUnit
workQueue
用来保存等待执行的任务的阻塞队列,等待的任务必须实现Runnable接口。我们可以选择如下几种:
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO。
- LinkedBlockingQueue:基于链表结构的有界阻塞队列,FIFO。
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作,反之亦然。
- PriorityBlockingQueue:具有优先界别的阻塞队列。
threadFactory
用于设置创建线程的工厂。该对象可以通过Executors.defaultThreadFactory(),如下:
public static ThreadFactory defaultThreadFactory() {
return new DefaultThreadFactory();
}
返回的是DefaultThreadFactory对象,源码如下:
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
ThreadFactory的左右就是提供创建线程的功能的线程工厂。他是通过newThread()方法提供创建线程的功能,newThread()方法创建的线程都是“非守护线程”而且“线程优先级都是Thread.NORM_PRIORITY”。
handler
RejectedExecutionHandler,线程池的拒绝策略。所谓拒绝策略,是指将任务添加到线程池中时,线程池拒绝该任务所采取的相应策略。当向线程池中提交任务时,如果此时线程池中的线程已经饱和了,而且阻塞队列也已经满了,则线程池会选择一种拒绝策略来处理该任务。
线程池提供了四种拒绝策略:
- AbortPolicy:直接抛出异常,默认策略;
- CallerRunsPolicy:用调用者所在的线程来执行任务;
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy:直接丢弃任务;
当然我们也可以实现自己的拒绝策略,例如记录日志等等,实现RejectedExecutionHandler接口即可。
线程池
Executor框架提供了三种线程池,他们都可以通过工具类Executors来创建。
FixedThreadPool
FixedThreadPool,可重用固定线程数的线程池,其定义如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
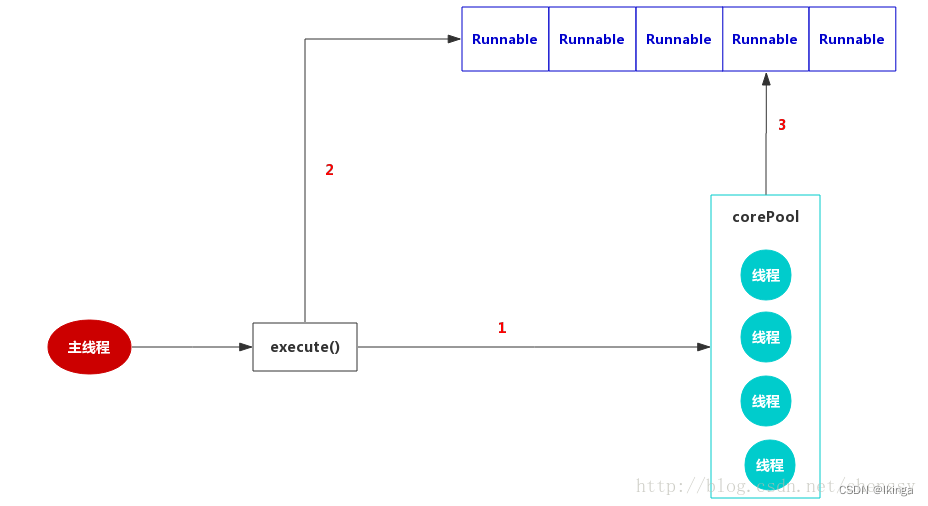
corePoolSize 和 maximumPoolSize都设置为创建FixedThreadPool时指定的参数nThreads,意味着当线程池满时且阻塞队列也已经满时,如果继续提交任务,则会直接走拒绝策略,该线程池不会再新建线程来执行任务,而是直接走拒绝策略。FixedThreadPool使用的是默认的拒绝策略,即AbortPolicy,则直接抛出异常。
keepAliveTime设置为0L,表示空闲的线程会立刻终止。
workQueue则是使用LinkedBlockingQueue,但是没有设置范围,那么则是最大值(Integer.MAX_VALUE),这基本就相当于一个无界队列了。使用该“无界队列”则会带来哪些影响呢?当线程池中的线程数量等于corePoolSize 时,如果继续提交任务,该任务会被添加到阻塞队列workQueue中,当阻塞队列也满了之后,则线程池会新建线程执行任务直到maximumPoolSize。由于FixedThreadPool使用的是“无界队列”LinkedBlockingQueue,那么maximumPoolSize参数无效,同时指定的拒绝策略AbortPolicy也将无效。而且该线程池也不会拒绝提交的任务,如果客户端提交任务的速度快于任务的执行,那么keepAliveTime也是一个无效参数。
其运行图如下(参考《Java并发编程的艺术》):
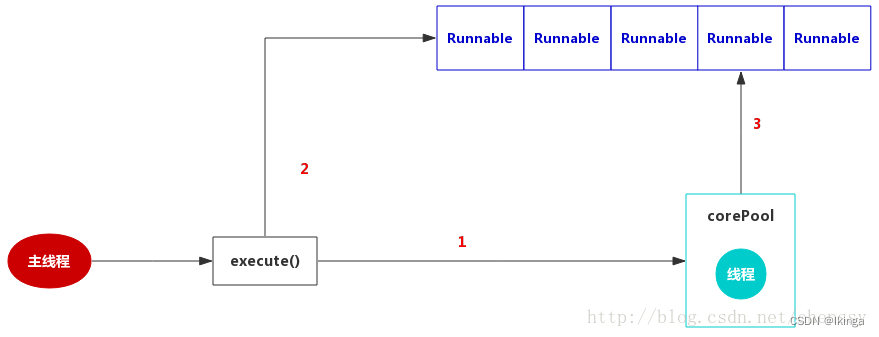
SingleThreadExecutor
SingleThreadExecutor是使用单个worker线程的Executor,定义如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
作为单一worker线程的线程池,SingleThreadExecutor把corePool和maximumPoolSize均被设置为1,和FixedThreadPool一样使用的是无界队列LinkedBlockingQueue,所以带来的影响和FixedThreadPool一样。
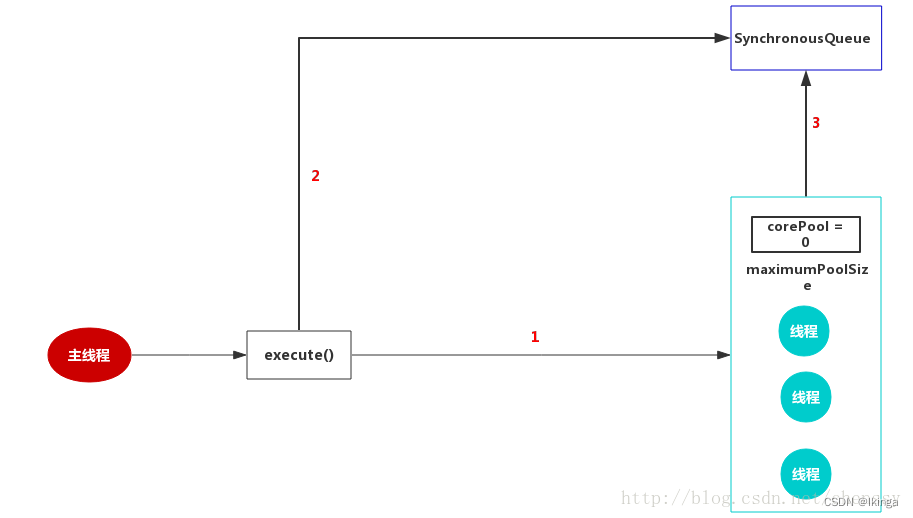
CachedThreadPool
CachedThreadPool是一个会根据需要创建新线程的线程池 ,他定义如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
CachedThreadPool的corePool为0,maximumPoolSize为Integer.MAX_VALUE,这就意味着所有的任务一提交就会加入到阻塞队列中。keepAliveTime这是为60L,unit设置为TimeUnit.SECONDS,意味着空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。阻塞队列采用的SynchronousQueue,J.U.C之阻塞队列:SynchronousQueue 中了解到SynchronousQueue是一个没有元素的阻塞队列,加上corePool = 0 ,maximumPoolSize = Integer.MAX_VALUE,这样就会存在一个问题,如果主线程提交任务的速度远远大于CachedThreadPool的处理速度,则CachedThreadPool会不断地创建新线程来执行任务,这样有可能会导致系统耗尽CPU和内存资源,所以在 使用该线程池是,一定要注意控制并发的任务数,否则创建大量的线程可能导致严重的性能问题 。
任务提交
线程池根据业务不同的需求提供了两种方式提交任务:Executor.execute()、ExecutorService.submit()。其中ExecutorService.submit()可以获取该任务执行的Future。 我们以Executor.execute()为例,来看看线程池的任务提交经历了那些过程。
定义:
public interface Executor {
void execute(Runnable command);
}
ThreadPoolExecutor提供实现:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
执行流程如下:
- 如果线程池当前线程数小于corePoolSize,则调用addWorker创建新线程执行任务,成功返回true,失败执行步骤2。
- 如果线程池处于RUNNING状态,则尝试加入阻塞队列,如果加入阻塞队列成功,则尝试进行Double Check,如果加入失败,则执行步骤3。
- 如果线程池不是RUNNING状态或者加入阻塞队列失败,则尝试创建新线程直到maxPoolSize,如果失败,则调用reject()方法运行相应的拒绝策略。
在步骤2中如果加入阻塞队列成功了,则会进行一个Double Check的过程。Double Check过程的主要目的是判断加入到阻塞队里中的线程是否可以被执行。如果线程池不是RUNNING状态,则调用remove()方法从阻塞队列中删除该任务,然后调用reject()方法处理任务。否则需要确保还有线程执行。
addWorker 当线程中的当前线程数小于corePoolSize,则调用addWorker()创建新线程执行任务,当前线程数则是根据 ctl 变量来获取的,调用workerCountOf(ctl)获取低29位即可:
private static int workerCountOf(int c) { return c & CAPACITY; }
addWorker(Runnable firstTask, boolean core)方法用于创建线程执行任务,源码如下:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
// 获取当前线程状态
int rs = runStateOf(c);
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 内层循环,worker + 1
for (;;) {
// 线程数量
int wc = workerCountOf(c);
// 如果当前线程数大于线程最大上限CAPACITY return false
// 若core == true,则与corePoolSize 比较,否则与maximumPoolSize ,大于 return false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// worker + 1,成功跳出retry循环
if (compareAndIncrementWorkerCount(c))
break retry;
// CAS add worker 失败,再次读取ctl
c = ctl.get();
// 如果状态不等于之前获取的state,跳出内层循环,继续去外层循环判断
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 新建线程:Worker
w = new Worker(firstTask);
// 当前线程
final Thread t = w.thread;
if (t != null) {
// 获取主锁:mainLock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 线程状态
int rs = runStateOf(ctl.get());
// rs < SHUTDOWN ==> 线程处于RUNNING状态
// 或者线程处于SHUTDOWN状态,且firstTask == null(可能是workQueue中仍有未执行完成的任务,创建没有初始任务的worker线程执行)
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 当前线程已经启动,抛出异常
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// workers是一个HashSet<Worker>
workers.add(w);
// 设置最大的池大小largestPoolSize,workerAdded设置为true
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
// 释放锁
mainLock.unlock();
}
// 启动线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 线程启动失败
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
- 判断当前线程是否可以添加任务,如果可以则进行下一步,否则return false;
- rs >= SHUTDOWN ,表示当前线程处于SHUTDOWN ,STOP、TIDYING、TERMINATED状态
- rs == SHUTDOWN , firstTask != null时不允许添加线程,因为线程处于SHUTDOWN 状态,不允许添加任务
- rs == SHUTDOWN , firstTask == null,但workQueue.isEmpty() == true,不允许添加线程,因为firstTask == null是为了添加一个没有任务的线程然后再从workQueue中获取任务的,如果workQueue == null,则说明添加的任务没有任何意义。
-
内嵌循环,通过CAS worker + 1
-
获取主锁mailLock,如果线程池处于RUNNING状态获取处于SHUTDOWN状态且 firstTask == null,则将任务添加到workers Queue中,然后释放主锁mainLock,然后启动线程,然后return true,如果中途失败导致workerStarted= false,则调用addWorkerFailed()方法进行处理。
在这里需要好好理论addWorker中的参数,在execute()方法中,有三处调用了该方法:
- 第一次:workerCountOf© < corePoolSize ==> addWorker(command, true),这个很好理解,当然线程池的线程数量小于 corePoolSize ,则新建线程执行任务即可,在执行过程core == true,内部与corePoolSize比较即可。
- 第二次:加入阻塞队列进行Double Check时,else if (workerCountOf(recheck) == 0) >addWorker(null, false)。如果线程池中的线程0,按照道理应该该任务应该新建线程执行任务,但是由于已经该任务已经添加到了阻塞队列,那么就在线程池中新建一个空线程,然后从阻塞队列中取线程即可。
- 第三次:线程池不是RUNNING状态或者加入阻塞队列失败:else if (!addWorker(command, false)),这里core == fase,则意味着是与maximumPoolSize比较。
在新建线程执行任务时,将讲Runnable包装成一个Worker,Woker为ThreadPoolExecutor的内部类
Woker内部类
Woker的源码如下:
private final class Worker extends AbstractQueuedSynchronizer
implements Runnable {
private static final long serialVersionUID = 6138294804551838833L;
// task 的thread
final Thread thread;
// 运行的任务task
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
//设置AQS的同步状态private volatile int state,是一个计数器,大于0代表锁已经被获取
setState(-1);
this.firstTask = firstTask;
// 利用ThreadFactory和 Worker这个Runnable创建的线程对象
this.thread = getThreadFactory().newThread(this);
}
// 任务执行
public void run() {
runWorker(this);
}
}
从Worker的源码中我们可以看到Woker继承AQS,实现Runnable接口,所以可以认为Worker既是一个可以执行的任务,也可以达到获取锁释放锁的效果。这里继承AQS主要是为了方便线程的中断处理。这里注意两个地方:构造函数、run()。构造函数主要是做三件事:1.设置同步状态state为-1,同步状态大于0表示就已经获取了锁,2.设置将当前任务task设置为firstTask,3.利用Worker本身对象this和ThreadFactory创建线程对象。
当线程thread启动(调用start()方法)时,其实就是执行Worker的run()方法,内部调用runWorker()。
runWorker
final void runWorker(Worker w) {
// 当前线程
Thread wt = Thread.currentThread();
// 要执行的任务
Runnable task = w.firstTask;
w.firstTask = null;
// 释放锁,运行中断
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
// worker 获取锁
w.lock();
// 确保只有当线程是stoping时,才会被设置为中断,否则清楚中断标示
// 如果线程池状态 >= STOP ,且当前线程没有设置中断状态,则wt.interrupt()
// 如果线程池状态 < STOP,但是线程已经中断了,再次判断线程池是否 >= STOP,如果是 wt.interrupt()
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 自定义方法
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
// 完成任务数 + 1
w.completedTasks++;
// 释放锁
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
运行流程
- 根据worker获取要执行的任务task,然后调用unlock()方法释放锁,这里释放锁的主要目的在于中断,因为在new Worker时,设置的state为-1,调用unlock()方法可以将state设置为0,这里主要原因就在于interruptWorkers()方法只有在state >= 0时才会执行;
- 通过getTask()获取执行的任务,调用task.run()执行,当然在执行之前会调用worker.lock()上锁,执行之后调用worker.unlock()放锁;
- 在任务执行前后,可以根据业务场景自定义beforeExecute() 和 afterExecute()方法,则两个方法在ThreadPoolExecutor中是空实现;
- 如果线程执行完成,则会调用getTask()方法从阻塞队列中获取新任务,如果阻塞队列为空,则根据是否超时来判断是否需要阻塞;
- task == null或者抛出异常(beforeExecute()、task.run()、afterExecute()均有可能)导致worker线程终止,则调用processWorkerExit()方法处理worker退出流程。
getTask()
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
// 线程池状态
int c = ctl.get();
int rs = runStateOf(c);
// 线程池中状态 >= STOP 或者 线程池状态 == SHUTDOWN且阻塞队列为空,则worker - 1,return null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 判断是否需要超时控制
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 从阻塞队列中获取task
// 如果需要超时控制,则调用poll(),否则调用take()
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
timed == true,调用poll()方法,如果在keepAliveTime时间内还没有获取task的话,则返回null,继续循环。timed == false,则调用take()方法,该方法为一个阻塞方法,没有任务时会一直阻塞挂起,直到有任务加入时对该线程唤醒,返回任务。
在runWorker()方法中,无论最终结果如何,都会执行processWorkerExit()方法对worker进行退出处理。
processWorkerExit()
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// true:用户线程运行异常,需要扣减
// false:getTask方法中扣减线程数量
if (completedAbruptly)
decrementWorkerCount();
// 获取主锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
// 从HashSet中移出worker
workers.remove(w);
} finally {
mainLock.unlock();
}
// 有worker线程移除,可能是最后一个线程退出需要尝试终止线程池
tryTerminate();
int c = ctl.get();
// 如果线程为running或shutdown状态,即tryTerminate()没有成功终止线程池,则判断是否有必要一个worker
if (runStateLessThan(c, STOP)) {
// 正常退出,计算min:需要维护的最小线程数量
if (!completedAbruptly) {
// allowCoreThreadTimeOut 默认false:是否需要维持核心线程的数量
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果min ==0 或者workerQueue为空,min = 1
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// 如果线程数量大于最少数量min,直接返回,不需要新增线程
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 添加一个没有firstTask的worker
addWorker(null, false);
}
}
首先completedAbruptly的值来判断是否需要对线程数-1处理,如果completedAbruptly == true,说明在任务运行过程中出现了异常,那么需要进行减1处理,否则不需要,因为减1处理在getTask()方法中处理了。然后从HashSet中移出该worker,过程需要获取mainlock。然后调用tryTerminate()方法处理,该方法是对最后一个线程退出做终止线程池动作。如果线程池没有终止,那么线程池需要保持一定数量的线程,则通过addWorker(null,false)新增一个空的线程。
addWorkerFailed()
在addWorker()方法中,如果线程t==null,或者在add过程出现异常,会导致workerStarted == false,那么在最后会调用addWorkerFailed()方法:
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 从HashSet中移除该worker
if (w != null)
workers.remove(w);
// 线程数 - 1
decrementWorkerCount();
// 尝试终止线程
tryTerminate();
} finally {
mainLock.unlock();
}
}
整个逻辑显得比较简单。
tryTerminate()
当线程池涉及到要移除worker时候都会调用tryTerminate(),该方法主要用于判断线程池中的线程是否已经全部移除了,如果是的话则关闭线程池。
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 线程池处于Running状态
// 线程池已经终止了
// 线程池处于ShutDown状态,但是阻塞队列不为空
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
// 执行到这里,就意味着线程池要么处于STOP状态,要么处于SHUTDOWN且阻塞队列为空
// 这时如果线程池中还存在线程,则会尝试中断线程
if (workerCountOf(c) != 0) {
// /线程池还有线程,但是队列没有任务了,需要中断唤醒等待任务的线程
// (runwoker的时候首先就通过w.unlock设置线程可中断,getTask最后面的catch处理中断)
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 尝试终止线程池
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
// 线程池状态转为TERMINATED
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
}
}
在关闭线程池的过程中,如果线程池处于STOP状态或者处于SHUDOWN状态且阻塞队列为null,则线程池会调用interruptIdleWorkers()方法中断所有线程,注意ONLY_ONE== true,表示仅中断一个线程。
interruptIdleWorkers
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
onlyOne==true仅终止一个线程,否则终止所有线程。
线程终止
线程池ThreadPoolExecutor提供了shutdown()和shutDownNow()用于关闭线程池。
-
shutdown():按过去执行已提交任务的顺序发起一个有序的关闭,但是不接受新任务。
-
shutdownNow() :尝试停止所有的活动执行任务、暂停等待任务的处理,并返回等待执行的任务列表。
shutdown
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 推进线程状态
advanceRunState(SHUTDOWN);
// 中断空闲的线程
interruptIdleWorkers();
// 交给子类实现
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}
shutdownNow
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
// 中断所有线程
interruptWorkers();
// 返回等待执行的任务列表
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
与shutdown不同,shutdownNow会调用interruptWorkers()方法中断所有线程。
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
同时会调用drainQueue()方法返回等待执行到任务列表。
private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<Runnable>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
SchesuledThreadPoolExecutor

已经介绍了线程池中最核心的类 ThreadPoolExecutor ,这篇就来看看另一个核心类 ScheduledThreadPoolExecutor 的实现。
ScheduledThreadPoolExecutor解析
我们知道Timer与TimerTask虽然可以实现线程的周期和延迟调度,但是Timer与TimerTask存在一些缺陷,所以对于这种定期、周期执行任务的调度策略,我们一般都是推荐ScheduledThreadPoolExecutor来实现。下面就深入分析ScheduledThreadPoolExecutor是如何来实现线程的周期、延迟调度的。 ScheduledThreadPoolExecutor,继承ThreadPoolExecutor且实现了ScheduledExecutorService接口,它就相当于提供了“延迟”和“周期执行”功能的ThreadPoolExecutor。在JDK API中是这样定义它的:ThreadPoolExecutor,它可另行安排在给定的延迟后运行命令,或者定期执行命令。需要多个辅助线程时,或者要求 ThreadPoolExecutor 具有额外的灵活性或功能时,此类要优于 Timer。 一旦启用已延迟的任务就执行它,但是有关何时启用,启用后何时执行则没有任何实时保证。按照提交的先进先出 (FIFO) 顺序来启用那些被安排在同一执行时间的任务。 它提供了四个构造方法:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
当然我们一般都不会直接通过其构造函数来生成一个ScheduledThreadPoolExecutor对象(例如new ScheduledThreadPoolExecutor(10)之类的),而是通过Executors类(例如Executors.newScheduledThreadPool(int);) 在ScheduledThreadPoolExecutor的构造函数中,我们发现它都是利用ThreadLocalExecutor来构造的,唯一变动的地方就在于它所使用的阻塞队列变成了DelayedWorkQueue,而不是ThreadLocalhExecutor的LinkedBlockingQueue(通过Executors产生ThreadLocalhExecutor对象)。DelayedWorkQueue为ScheduledThreadPoolExecutor中的内部类,它其实和阻塞队列DelayQueue有点儿类似。DelayQueue是可以提供延迟的阻塞队列,它只有在延迟期满时才能从中提取元素,其列头是延迟期满后保存时间最长的Delayed元素。如果延迟都还没有期满,则队列没有头部,并且 poll 将返回 null。有关于DelayQueue的更多介绍请参J.U.C之阻塞队列:DelayQueue。所以DelayedWorkQueue中的任务必然是按照延迟时间从短到长来进行排序的。下面我们再深入分析DelayedWorkQueue,这里留一个引子。 ScheduledThreadPoolExecutor提供了如下四个方法,也就是四个调度器:
- schedule(Callable callable, long delay, TimeUnit unit) :创建并执行在给定延迟后启用的 ScheduledFuture。
- schedule(Runnable command, long delay, TimeUnit unit) :创建并执行在给定延迟后启用的一次性操作。
- scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) :创建并执行一个在给定初始延迟后首次启用的定期操作,后续操作具有给定的周期;也就是将在 initialDelay 后开始执行,然后在 initialDelay+period 后执行,接着在 initialDelay + 2 * period 后执行,依此类推。
- scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) :创建并执行一个在给定初始延迟后首次启用的定期操作,随后,在每一次执行终止和下一次执行开始之间都存在给定的延迟。
第一、二个方法差不多,都是一次性操作,只不过参数一个是Callable,一个是Runnable。稍微分析下第三(scheduleAtFixedRate)、四个(scheduleWithFixedDelay)方法,加入initialDelay = 5,period/delay = 3,unit为秒。如果每个线程都是都运行非常良好不存在延迟的问题,那么这两个方法线程运行周期是5、8、11、14、17…,但是如果存在延迟呢?比如第三个线程用了5秒钟,那么这两个方法的处理策略是怎样的?第三个方法(scheduleAtFixedRate)是周期固定,也就说它是不会受到这个延迟的影响的,每个线程的调度周期在初始化时就已经绝对了,是什么时候调度就是什么时候调度,它不会因为上一个线程的调度失效延迟而受到影响。但是第四个方法(scheduleWithFixedDelay),则不一样,它是每个线程的调度间隔固定,也就是说第一个线程与第二线程之间间隔delay,第二个与第三个间隔delay,以此类推。如果第二线程推迟了那么后面所有的线程调度都会推迟,例如,上面第二线程推迟了2秒,那么第三个就不再是11秒执行了,而是13秒执行。 查看着四个方法的源码,会发现其实他们的处理逻辑都差不多,所以我们就挑scheduleWithFixedDelay方法来分析,如下:
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(-delay));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
scheduleWithFixedDelay方法处理的逻辑如下:
- 校验,如果参数不合法则抛出异常
- 构造一个task,该task为ScheduledFutureTask
- 调用delayedExecute()方法做后续相关处理
这段代码涉及两个类ScheduledFutureTask和RunnableScheduledFuture,其中RunnableScheduledFuture不用多说,他继承RunnableFuture和ScheduledFuture两个接口,除了具备RunnableFuture和ScheduledFuture两类特性外,它还定义了一个方法isPeriodic() ,该方法用于判断执行的任务是否为定期任务,如果是则返回true。而ScheduledFutureTask作为ScheduledThreadPoolExecutor的内部类,它扮演着极其重要的作用,因为它的作用则是负责ScheduledThreadPoolExecutor中任务的调度。 ScheduledFutureTask内部继承FutureTask,实现RunnableScheduledFuture接口,它内部定义了三个比较重要的变量
/** 任务被添加到ScheduledThreadPoolExecutor中的序号 */
private final long sequenceNumber;
/** 任务要执行的具体时间 */
private long time;
/** 任务的间隔周期 */
private final long period;
这三个变量与任务的执行有着非常密切的关系,什么关系?先看ScheduledFutureTask的几个构造函数和核心方法:
ScheduledFutureTask(Runnable r, V result, long ns) {
super(r, result);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask(Callable<V> callable, long ns) {
super(callable);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask(Callable<V> callable, long ns) {
super(callable);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask 提供了四个构造方法,这些构造方法与上面三个参数是不是一一对应了?这些参数有什么用,如何用,则要看ScheduledFutureTask在那些方法使用了该方法,在ScheduledFutureTask中有一个compareTo()方法:
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
相信各位都知道该方法是干嘛用的,提供一个排序算法,该算法规则是:首先按照time排序,time小的排在前面,大的排在后面,如果time相同,则使用sequenceNumber排序,小的排在前面,大的排在后面。那么为什么在这个类里面提供compareTo()方法呢?在前面就介绍过ScheduledThreadPoolExecutor在构造方法中提供的是DelayedWorkQueue()队列中,也就是说ScheduledThreadPoolExecutor是把任务添加到DelayedWorkQueue中的,而DelayedWorkQueue则是类似于DelayQueue,内部维护着一个以时间为先后顺序的队列,所以compareTo()方法使用与DelayedWorkQueue队列对其元素ScheduledThreadPoolExecutor task进行排序的算法。 排序已经解决了,那么ScheduledThreadPoolExecutor 是如何对task任务进行调度和延迟的呢?任何线程的执行,都是通过run()方法执行,ScheduledThreadPoolExecutor 的run()方法如下:
public void run() {
boolean periodic = isPeriodic();
if (!canRunInCurrentRunState(periodic))
cancel(false);
else if (!periodic)
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}
调用isPeriodic()获取该线程是否为周期性任务标志,然后调用canRunInCurrentRunState()方法判断该线程是否可以执行,如果不可以执行则调用cancel()取消任务。
如果当线程已经到达了执行点,则调用run()方法执行task,该run()方法是在FutureTask中定义的。
否则调用runAndReset()方法运行并充值,调用setNextRunTime()方法计算任务下次的执行时间,重新把任务添加到队列中,让该任务可以重复执行。
isPeriodic() 该方法用于判断指定的任务是否为定期任务。
public boolean isPeriodic() {
return period != 0;
}
canRunInCurrentRunState()判断任务是否可以取消,cancel()取消任务,这两个方法比较简单,而run()执行任务,runAndReset()运行并重置状态,牵涉比较广,我们放在FutureTask后面介绍。所以重点介绍setNextRunTime()和reExecutePeriodic()这两个涉及到延迟的方法。 setNextRunTime() setNextRunTime()方法用于重新计算任务的下次执行时间。如下:
private void setNextRunTime() {
long p = period;
if (p > 0)
time += p;
else
time = triggerTime(-p);
}
该方法定义很简单,p > 0 ,time += p ,否则调用triggerTime()方法重新计算time:
long triggerTime(long delay) {
return now() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
reExecutePeriodic
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {
super.getQueue().add(task);
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
reExecutePeriodic重要的是调用super.getQueue().add(task);将任务task加入的队列DelayedWorkQueue中。ensurePrestart()在【死磕Java并发】-----J.U.C之线程池:ThreadPoolExecutor已经做了详细介绍。 到这里ScheduledFutureTask已经介绍完了,ScheduledFutureTask在ScheduledThreadPoolExecutor扮演作用的重要性不言而喻。其实ScheduledThreadPoolExecutor的实现不是很复杂,因为有FutureTask和ThreadPoolExecutor的支撑,其实现就显得不是那么难了。
ThreadLocal
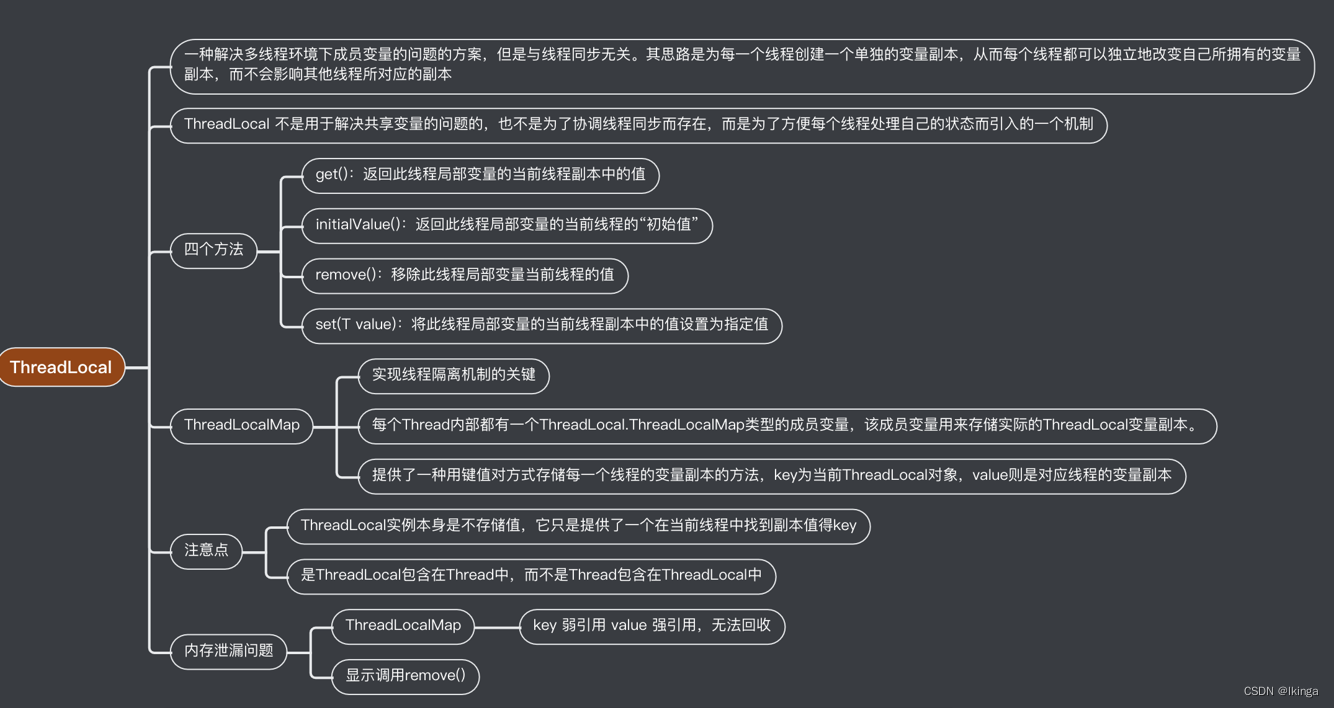
ThreadLocal 提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。
所以ThreadLocal与线程同步机制不同,线程同步机制是多个线程共享同一个变量,而ThreadLocal是为每一个线程创建一个单独的变量副本,故而每个线程都可以独立地改变自己所拥有的变量副本,而不会影响其他线程所对应的副本。可以说ThreadLocal为多线程环境下变量问题提供了另外一种解决思路。
ThreadLocal是啥?以前面试别人时就喜欢问这个,有些伙伴喜欢把它和线程同步机制混为一谈,事实上ThreadLocal与线程同步无关。
ThreadLocal虽然提供了一种解决多线程环境下成员变量的问题,但是它并不是解决多线程共享变量的问题。
那么ThreadLocal到底是什么呢? API是这样介绍它的: This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own, independently initialized copy of the variable. {@code ThreadLocal} instances are typically private static fields in classes that wish to associate state with a thread (e.g.,a user ID or Transaction ID).
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。
所以ThreadLocal与线程同步机制不同,线程同步机制是多个线程共享同一个变量,而ThreadLocal是为每一个线程创建一个单独的变量副本,故而每个线程都可以独立地改变自己所拥有的变量副本,而不会影响其他线程所对应的副本。可以说ThreadLocal为多线程环境下变量问题提供了另外一种解决思路。 ThreadLocal定义了四个方法:
- get():返回此线程局部变量的当前线程副本中的值。
- initialValue():返回此线程局部变量的当前线程的“初始值”。
- remove():移除此线程局部变量当前线程的值。
- set(T value):将此线程局部变量的当前线程副本中的值设置为指定值。
除了这四个方法,ThreadLocal内部还有一个静态内部类ThreadLocalMap,该内部类才是实现线程隔离机制的关键,get()、set()、remove()都是基于该内部类操作。ThreadLocalMap提供了一种用键值对方式存储每一个线程的变量副本的方法,key为当前ThreadLocal对象,value则是对应线程的变量副本。 对于ThreadLocal需要注意的有两点:
ThreadLocal实例本身是不存储值,它只是提供了一个在当前线程中找到副本值得key。
是ThreadLocal包含在Thread中,而不是Thread包含在ThreadLocal中,有些小伙伴会弄错他们的关系。
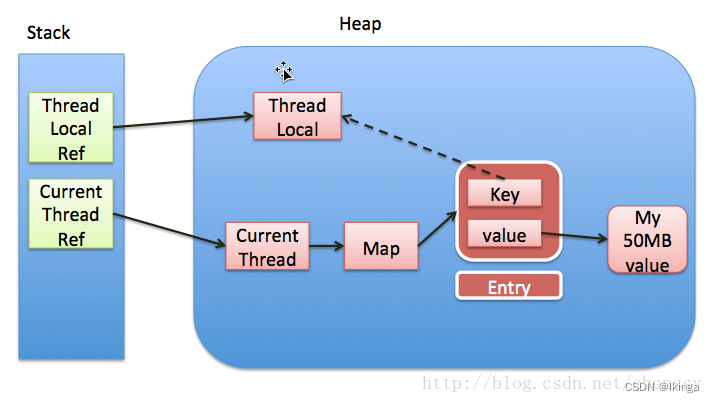
下图是Thread、ThreadLocal、ThreadLocalMap的关系(http://blog.xiaohansong.com/2016/08/06/ThreadLocal-memory-leak/)
ThreadLocal使用场景
在业务开发中有两种典型的使用场景。
- 保存线程不安全的对象。
- 传递全局变量
保存线程不安全的工具类
典型的类: SimpleDateFormat
如果有多个线程同时调用下面这个方法,由于dateFormat是局部变量,不会有线程安全问题;但是会创建出大量的SimpleDateFormat对象,造成频繁的GC。
public String date() {
SimpleDateFormat dateFormat = new SimpleDateFormat("mm:ss");
return dateFormat.format(new Date());
}
如果我们声明成全局变量呢?
static SimpleDateFormat dateFormat = new SimpleDateFormat("mm:ss");
public String date(){
return dateFormat.format(new Date());
}
在多个线程访问下,不同的线程都是指向同一个对象,会有线程安全的问题、
用传统的解决方法: 加锁
static SimpleDateFormat dateFormat = new SimpleDateFormat("mm:ss");
public synchronized String date(){
return dateFormat.format(new Date());
}
加锁的方式的确能够解决线程不安全的问题,但是也带来了性能低下。
正确的方式是采用ThreadLocal来创建对象
public synchronized String date(){
SimpleDateFormat dateFormat = ThreadSafeFormatter.dateFormatThreadLocal.get();
return dateFormat.format(new Date());
}
class ThreadSafeFormatter {
public static ThreadLocal<SimpleDateFormat> dateFormatThreadLocal = new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("mm:ss");
}
};
}
这种创建的方式,最多创建的对象只和线程数相同。这样既高效的使用了内存,也保证了线程安全。
传递全局变量
每个线程内需要保存类似于全局变量的信息,可以让不同方法直接使用,避免参数传递的麻烦却不想被多线程共享。
例如,用 ThreadLocal 保存一些业务内容,这些信息在同一个线程内相同,但是不同的线程使用的业务内容是不相同的。
在线程生命周期内,都通过这个静态 ThreadLocal 实例的 get() 方法取得自己 set 过的那个对象,避免了将这个对象作为参数传递的麻烦。
案例:
- 在分布式链路追踪中,log4j的MDC对象
- 业务系统中,使用ThreadLocal传递用户信息
面试题: ThreadLocal是用来解决共享资源的多线程访问吗?
这道题的答案很明确——不是。
ThreadLocal不是用来解决共享资源问题的。虽然ThreadLocal可以用于解决多线程情况下的线程安全问题,但是资源不是共享的,而是每个线程独享过的。
面试官在忽悠你,独享资源何来的多线程访问呢?
ThreadLocal解决线程安全问题的时候,相比于使用“锁”而言,避免了竞争,采用了线程独享来进行操作。
具体而言,它可以在 initialValue 中 new 出自己线程独享的资源,而多个线程之间,它们所访问的对象本身是不共享的,自然就不存在任何并发问题。这是 ThreadLocal 解决并发问题的最主要思路。
如果变量变成了共享,则依然是线程不安全的:
public synchronized String date(){
SimpleDateFormat dateFormat = ThreadSafeFormatter.dateFormatThreadLocal.get();
return dateFormat.format(new Date());
}
class ThreadSafeFormatter {
static SimpleDateFormat format = new SimpleDateFormat();
public static ThreadLocal<SimpleDateFormat> dateFormatThreadLocal = new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
return ThreadSafeFormatter.format;
}
};
}
ThreadLocal 和 synchronized 是什么关系
当 ThreadLocal 用于解决线程安全问题的时候,也就是把一个对象给每个线程都生成一份独享的副本的,在这种场景下,ThreadLocal 和 synchronized 都可以理解为是用来保证线程安全的手段。
但是效果和实现原理不同:
ThreadLocal 是通过让每个线程独享自己的副本,避免了资源的竞争。
synchronized 主要用于临界资源的分配,在同一时刻限制最多只有一个线程能访问该资源。
ThreadLocal使用示例
示例如下:
public class SeqCount {
private static ThreadLocal<Integer> seqCount = new ThreadLocal<Integer>(){
// 实现initialValue()
public Integer initialValue() {
return 0;
}
};
public int nextSeq(){
seqCount.set(seqCount.get() + 1);
return seqCount.get();
}
public static void main(String[] args){
SeqCount seqCount = new SeqCount();
SeqThread thread1 = new SeqThread(seqCount);
SeqThread thread2 = new SeqThread(seqCount);
SeqThread thread3 = new SeqThread(seqCount);
SeqThread thread4 = new SeqThread(seqCount);
thread1.start();
thread2.start();
thread3.start();
thread4.start();
}
private static class SeqThread extends Thread{
private SeqCount seqCount;
SeqThread(SeqCount seqCount){
this.seqCount = seqCount;
}
public void run() {
for(int i = 0 ; i < 3 ; i++){
System.out.println(Thread.currentThread().getName() + " seqCount :" + seqCount.nextSeq());
}
}
}
}
运行结果:
Thread-2 seqCount :1
Thread-3 seqCount :1
Thread-2 seqCount :2
Thread-3 seqCount :2
Thread-2 seqCount :3
Thread-3 seqCount :3
Thread-1 seqCount :1
Thread-1 seqCount :2
Thread-1 seqCount :3
Thread-0 seqCount :1
Thread-0 seqCount :2
Thread-0 seqCount :3
从运行结果可以看出,ThreadLocal确实是可以达到线程隔离机制,确保变量的安全性。这里我们想一个问题,在上面的代码中ThreadLocal的initialValue()方法返回的是0,加入该方法返回得是一个对象呢,会产生什么后果呢?例如:
A a = new A();
private static ThreadLocal<A> seqCount = new ThreadLocal<A>(){
// 实现initialValue()
public A initialValue() {
return a;
}
};
class A{
// ....
}
具体过程请参考:对ThreadLocal实现原理的一点思考
http://www.jianshu.com/p/ee8c9dccc953
ThreadLocal源码解析
ThreadLocal虽然解决了这个多线程变量的复杂问题,但是它的源码实现却是比较简单的。ThreadLocalMap是实现ThreadLocal的关键,我们先从它入手。
ThreadLocalMap
ThreadLocalMap其内部利用Entry来实现key-value的存储,如下:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
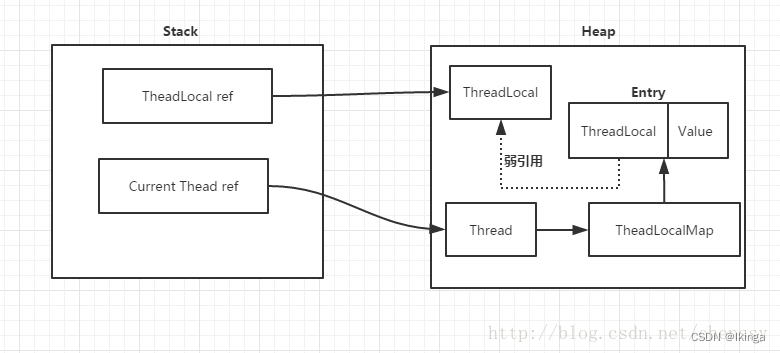
从上面代码中可以看出Entry的key就是ThreadLocal,而value就是值。同时,Entry也继承WeakReference,所以说Entry所对应key(ThreadLocal实例)的引用为一个弱引用(关于弱引用这里就不多说了,感兴趣的可以关注这篇博客:Java 理论与实践: 用弱引用堵住内存泄漏 https://www.ibm.com/developerworks/cn/java/j-jtp11225/)
ThreadLocalMap的源码稍微多了点,我们就看两个最核心的方法getEntry()、set(ThreadLocal key, Object value)方法。 set(ThreadLocal key, Object value)
private void set(ThreadLocal<?> key, Object value) {
ThreadLocal.ThreadLocalMap.Entry[] tab = table;
int len = tab.length;
// 根据 ThreadLocal 的散列值,查找对应元素在数组中的位置
int i = key.threadLocalHashCode & (len-1);
// 采用“线性探测法”,寻找合适位置
for (ThreadLocal.ThreadLocalMap.Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// key 存在,直接覆盖
if (k == key) {
e.value = value;
return;
}
// key == null,但是存在值(因为此处的e != null),说明之前的ThreadLocal对象已经被回收了
if (k == null) {
// 用新元素替换陈旧的元素
replaceStaleEntry(key, value, i);
return;
}
}
// ThreadLocal对应的key实例不存在也没有陈旧元素,new 一个
tab[i] = new ThreadLocal.ThreadLocalMap.Entry(key, value);
int sz = ++size;
// cleanSomeSlots 清楚陈旧的Entry(key == null)
// 如果没有清理陈旧的 Entry 并且数组中的元素大于了阈值,则进行 rehash
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
这个set()操作和我们在集合了解的put()方式有点儿不一样,虽然他们都是key-value结构,不同在于他们解决散列冲突的方式不同。集合Map的put()采用的是拉链法,而ThreadLocalMap的set()则是采用开放定址法(具体请参考散列冲突处理系列博客 http://www.nowamagic.net/academy/detail/3008015)。掌握了开放地址法该方法就一目了然了。 set()操作除了存储元素外,还有一个很重要的作用,就是replaceStaleEntry()和cleanSomeSlots(),这两个方法可以清除掉key == null 的实例,防止内存泄漏。在set()方法中还有一个变量很重要:threadLocalHashCode,定义如下:
private final int threadLocalHashCode = nextHashCode();
从名字上面我们可以看出threadLocalHashCode应该是ThreadLocal的散列值,定义为final,表示ThreadLocal一旦创建其散列值就已经确定了,生成过程则是调用nextHashCode():
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
nextHashCode表示分配下一个ThreadLocal实例的threadLocalHashCode的值,HASH_INCREMENT则表示分配两个ThradLocal实例的threadLocalHashCode的增量,从nextHashCode就可以看出他们的定义。 getEntry()
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
由于采用了开放定址法,所以当前key的散列值和元素在数组的索引并不是完全对应的,首先取一个探测数(key的散列值),如果所对应的key就是我们所要找的元素,则返回,否则调用getEntryAfterMiss(),如下:
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
这里有一个重要的地方,当key == null时,调用了expungeStaleEntry()方法,该方法用于处理key == null,有利于GC回收,能够有效地避免内存泄漏。
get()
返回当前线程所对应的线程变量
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的成员变量 threadLocal
ThreadLocalMap map = getMap(t);
if (map != null) {
// 从当前线程的ThreadLocalMap获取相对应的Entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
// 获取目标值
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
首先通过当前线程获取所对应的成员变量ThreadLocalMap,然后通过ThreadLocalMap获取当前ThreadLocal的Entry,最后通过所获取的Entry获取目标值result。 getMap()方法可以获取当前线程所对应的ThreadLocalMap,如下:
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
set(T value)
设置当前线程的线程局部变量的值。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
获取当前线程所对应的ThreadLocalMap,如果不为空,则调用ThreadLocalMap的set()方法,key就是当前ThreadLocal,如果不存在,则调用createMap()方法新建一个,如下:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
initialValue()
返回该线程局部变量的初始值。
protected T initialValue() {
return null;
}
该方法定义为protected级别且返回为null,很明显是要子类实现它的,所以我们在使用ThreadLocal的时候一般都应该覆盖该方法。该方法不能显示调用,只有在第一次调用get()或者set()方法时才会被执行,并且仅执行1次。
remove()
将当前线程局部变量的值删除。
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
该方法的目的是减少内存的占用。当然,我们不需要显示调用该方法,因为一个线程结束后,它所对应的局部变量就会被垃圾回收。
ThreadLocal为什么会内存泄漏
前面提到每个Thread都有一个ThreadLocal.ThreadLocalMap的map,该map的key为ThreadLocal实例,它为一个弱引用,我们知道弱引用有利于GC回收。当ThreadLocal的key == null时,GC就会回收这部分空间,但是value却不一定能够被回收,因为他还与Current Thread存在一个强引用关系,如下(图片来自http://www.jianshu.com/p/ee8c9dccc953):
由于存在这个强引用关系,会导致value无法回收。如果这个线程对象不会销毁那么这个强引用关系则会一直存在,就会出现内存泄漏情况。所以说只要这个线程对象能够及时被GC回收,就不会出现内存泄漏。如果碰到线程池,那就更坑了。 那么要怎么避免这个问题呢? 在前面提过,在ThreadLocalMap中的setEntry()、getEntry(),如果遇到key == null的情况,会对value设置为null。当然我们也可以显示调用ThreadLocal的remove()方法进行处理。
内存泄漏的案例
通过线程池去持有ThreadLocal对象,由于线程池的特性,线程被用完之后不会被释放。
因此,总是存在<ThreadLocal,LocalVariable>的强引用,file static修饰的变量不会被释放,所以即使TreadLocalMap的key是弱引用,但由于强引用的存在,弱引用一直会有值,不会被GC回收。
内存泄漏的大小 = 核心线程数 * LocalVariable
public class ThreadLocalDemo {
static class LocalVariable {
private Long[] a = new Long[1024 * 1024];
}
// (1)
final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>());
// (2)
final static ThreadLocal<LocalVariable> localVariable = new ThreadLocal<LocalVariable>();
public static void main(String[] args) throws InterruptedException {
// (3)
Thread.sleep(5000 * 4);
for (int i = 0; i < 50; ++i) {
poolExecutor.execute(new Runnable() {
public void run() {
// (4)
localVariable.set(new LocalVariable());
// (5)
System.out.println("use local varaible" + localVariable.get());
localVariable.remove();
}
});
}
// (6)
System.out.println("pool execute over");
}
}
所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
找到Key对应的Entry, 并且清除Entry的Key(ThreadLocal)置空, 随后清除过期的Entry即可避免内存泄露。
总结
下面再对ThreadLocal进行简单的总结:
- ThreadLocal 不是用于解决共享变量的问题的,也不是为了协调线程同步而存在,而是为了方便每个线程处理自己的状态而引入的一个机制。这点至关重要。
- 每个Thread内部都有一个ThreadLocal.ThreadLocalMap类型的成员变量,该成员变量用来存储实际的ThreadLocal变量副本。
- ThreadLocal并不是为线程保存对象的副本,它仅仅只起到一个索引的作用。它的主要木得视为每一个线程隔离一个类的实例,这个实例的作用范围仅限于线程内部。
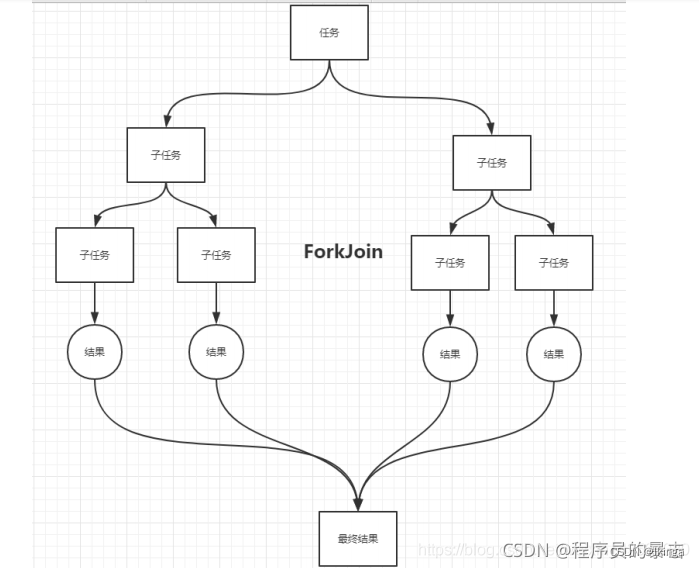
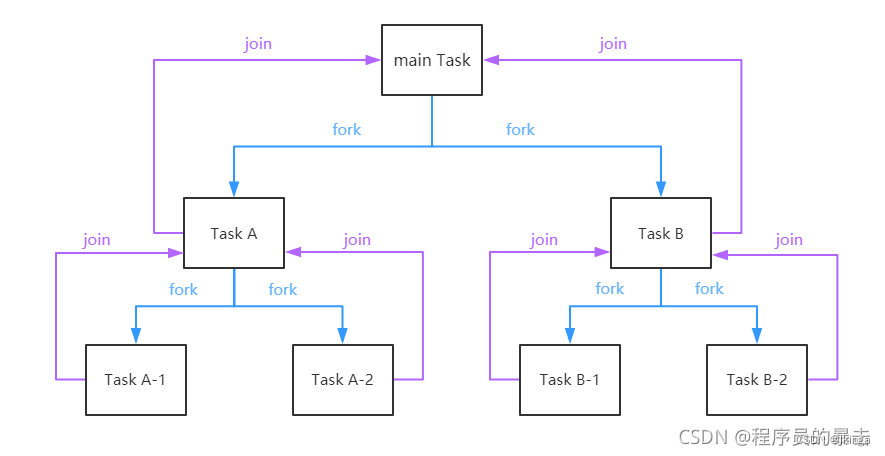
Fork/Join

Fork/Join 在 JDK 1.7 , 并行执行任务!提高效率。大数据量!Fork/Join是基于分治算法的并行实现。
它是一个可以让使用者简单方便的使用并行,来对数据进行处理,极大限度的利用多处理器来提高应用的性能。
大数据:Map Reduce (把大任务拆分为小任务)
Fork/Join框架的使用需要根据实际情况划分子任务的大小
案例
累加数字
public static void main(String[] args) throws InterruptedException, ExecutionException {
long start = 1;
long end = 1000000000;
sum(start, end);
}
public static void sum(long start, long end) {
int result = 0;
long startTime = System.currentTimeMillis();
for (long i = start; i <= end; i++) {
result += i;
}
long endTime = System.currentTimeMillis();
System.out.println("sum: " + result + " in " + (endTime - startTime) + " ms.");
}
我们可以将累加数字改写成下面的这种写法,使用forkJoin线程池进行运算。
public static void main(String[] args) throws InterruptedException, ExecutionException {
long startTime = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> task = new SumTask(start, end);
pool.submit(task);
long result = task.get();
long endTime = System.currentTimeMillis();
System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms.");
}
static final class SumTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
final long start; //开始计算的数
final long end; //最后计算的数
SumTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//如果计算量小于1000,那么分配一个线程执行if中的代码块,并返回执行结果
if (end - start < 10000) {
int sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}
//如果计算量大于1000,那么拆分为两个任务
SumTask task1 = new SumTask(start, (start + end) / 2);
SumTask task2 = new SumTask((start + end) / 2 + 1, end);
//执行任务
task1.fork();
task2.fork();
//获取任务执行的结果
return task1.join() + task2.join();
}
}
运行结果:
sum: -243309312 in 624 ms.
Fork/join sum: -243309312 in 168 ms.
使用fork/Join的归并排序
public class ThreadMergeSort extends RecursiveAction {
public static void main(String[] args) {
int[] arr = new int[8000];
for (int i = 0; i <8000; i++) {
arr[i]= (int) (Math.random() * 8000);
}
long start=System.currentTimeMillis();
System.out.println(Arrays.toString(threadMergeSort(arr)));
long end= System.currentTimeMillis();
System.out.println("多线程归并排序消耗时间:"+(end-start));
}
@Serial
private static final long serialVersionUID = -4369231251235987766L;
private final int[] meargeArr;
public ThreadMergeSort(int[] meargeArr) {
this.meargeArr = meargeArr;
}
@Override
protected void compute() {
if (meargeArr.length<=2){
if (meargeArr.length==2&&meargeArr[0]>meargeArr[1]){
meargeArr[0] = meargeArr[0]^meargeArr[1];
meargeArr[1] = meargeArr[0]^meargeArr[1];
meargeArr[0] = meargeArr[0]^meargeArr[1];
}
return ;
}
int middle=meargeArr.length>>1;
int[] leftArray= Arrays.copyOfRange(meargeArr, 0, middle);
int[] rightArray= Arrays.copyOfRange(meargeArr, middle, meargeArr.length);
invokeAll(new ThreadMergeSort(leftArray), new ThreadMergeSort(rightArray));
merge(leftArray, rightArray,meargeArr);
}
public static int[] threadMergeSort(int[] arr){
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(new ThreadMergeSort(arr));
return arr;
}
//将两个有序数组合并,合并后数组仍然有序
private static void merge(int[] left, int[] right,int[] temp){
int i = 0;
int tem=0;
int j=0;
while (i< left.length &&j< right.length ) {
if (left[i]<= right[j]){//比较left元素与right元素大小
temp[tem++] = left[i++];
}
else {
temp[tem++] = right[j++];
}
}
if(i== left.length){//说明left已经放完,right存在没有放完的元素
System.arraycopy(right,j,temp,tem,right.length-j);
}
if(j== right.length){//说明right已经放完,left存在没有放完的元素
System.arraycopy(left,i,temp,tem,left.length-i);
}
}
}
任务调度流程
Fork/Join 特点:工作窃取
由于线程处理不同任务的速度不同,这样就可能存在某个线程先执行完了自己队列中的任务的情况,这时为了提升效率,我们可以让该线程去“窃取”其它任务队列中的任务,这就是所谓的工作窃取算法。
工作窃取说白了就是,比较闲的线程到比较忙的线程那边把任务给拿过来执行,分摊压力。
每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列LinkedBlockingDeque。
队列支持三个功能push、pop、poll
add/remove源自集合,所以添加到队尾,从队头删除;
offer/poll源自队列(先进先出 => 尾进头出),所以添加到队尾,从队头删除;
push/pop源自栈(先进后出 => 头进头出),所以添加到队头,从队头删除;
offerFirst/offerLast/pollFirst/pollLast源自双端队列(两端都可以进也都可以出),根据字面意思,offerFirst添加到队头,offerLast添加到队尾,pollFirst从队头删除,pollLast从队尾删除。
总结:
add/offer/offerLast添加队尾,三个方法等价;
push/offerFirst添加队头,两个方法等价。
remove/pop/poll/pollFirst删除队头,四个方法等价;
pollLast删除队尾
push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
划分的子任务调用fork时,都会被push到自己的队列中。
默认情况下,工作线程从自己的双端队列获出任务并执行。
当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务。
工作线程worker1、worker2以及worker3都从taskQueue的尾部popping获取task,而任务也从尾部Pushing,当worker3队列中没有任务的时候,就会从其他线程的队列中取stealing,这样就使得worker3不会由于没有任务而空闲
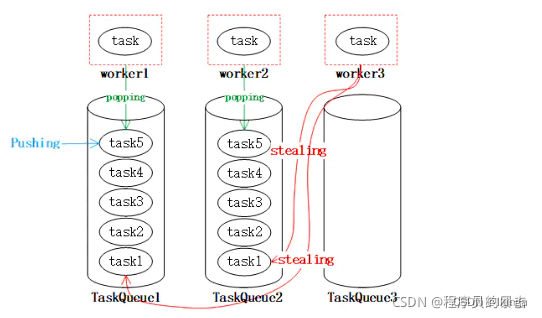
入队元素都是在“队尾”,出队元素在“队首”,要满足“工作窃取”的需求,任务队列应该支持从队尾出队元素 。所以这里面维护的都是双端队列LinkedBlockingDeque.
Fork/Join体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运
算效率
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
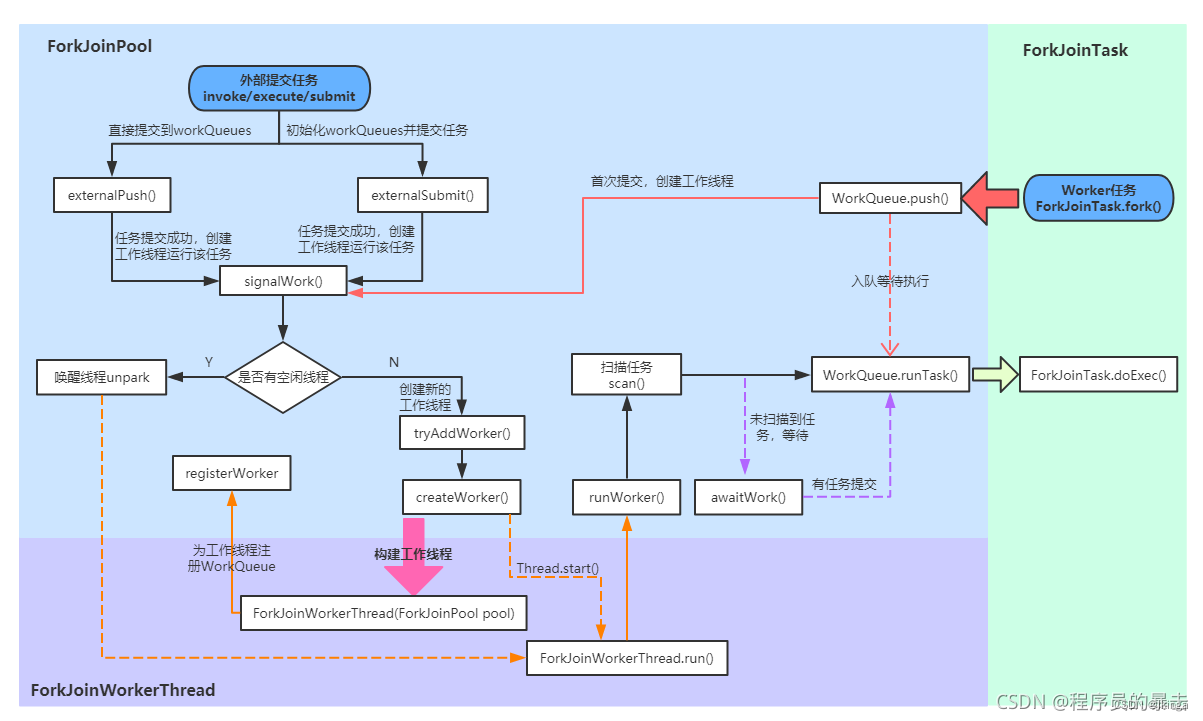
Fork/Join内部大量运用了位操作和无锁算法。该框架主要涉及三大核心组件:ForkJoinPool(线程池)、ForkJoinTask(任务)、ForkJoinWorkerThread(工作线程),外加WorkQueue(任务队列):
- ForkJoinPool:ExecutorService的实现类,负责工作线程的管理、任务队列的维护,以及控制整个任务调度流程;
- ForkJoinTask:Future接口的实现类,fork是其核心方法,用于分解任务并异步执行;而join方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果;
- ForkJoinWorkerThread:Thread的子类,作为线程池中的工作线程(Worker)执行任务;
- WorkQueue:任务队列,用于保存任务
执行流程
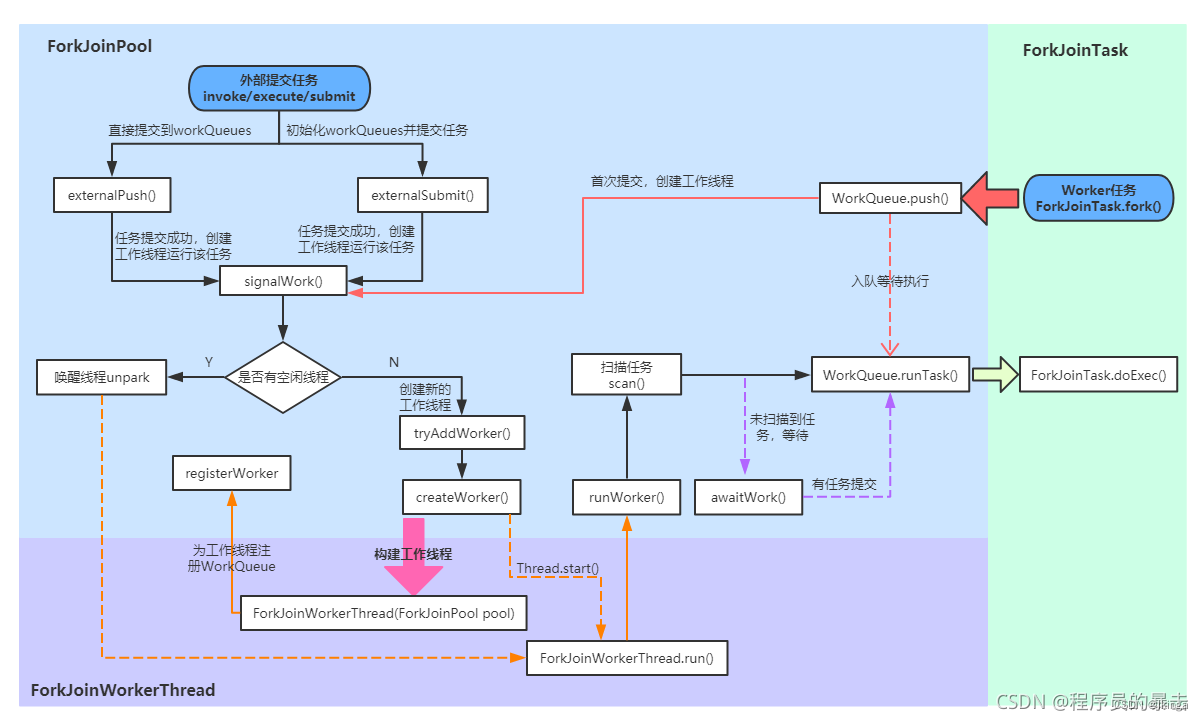
ForkJoinPool
ForkJoinPool的主要工作如下:
- 接受外部任务的提交(外部调用ForkJoinPool的invoke/execute/submit方法提交任务);
- 接受ForkJoinTask自身fork()出的子任务的提交;
- 任务队列数组(WorkQueue[])的初始化和管理;
- 工作线程(Worker)的创建/管理。
ForkJoinPool对象的构建有两种方式:
- 通过3种构造器的任意一种进行构造;
- 通过ForkJoinPool.commonPool()静态方法构造
JDK8以后,ForkJoinPool又提供了一个静态方法commonPool(),这个方法返回一个ForkJoinPool内部声明的静态ForkJoinPool实例,主要是为了简化线程池的构建,这个ForkJoinPool实例可以满足大多数的使用场景
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}
全部参数的构造器
**
* @param parallelism 并行级别, 默认为CPU核心数
* @param factory 工作线程工厂
* @param handler 异常处理器
* @param mode 调度模式: true表示FIFO_QUEUE; false表示LIFO_QUEUE
* @param workerNamePrefix 工作线程的名称前缀
*/
private ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler,
int mode, String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long) (-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
- parallelism:默认值为CPU核心数,ForkJoinPool里工作线程数量与该参数有关,但它不表示最大线程数;
- factory:工作线程工厂,默认是DefaultForkJoinWorkerThreadFactory,其实就是用来创建工作线程对象——ForkJoinWorkerThread;
- handler:异常处理器;
- config:保存parallelism和mode信息,供后续读取;
- ctl:线程池的核心控制字段
核心参数
ForkJoinPool 与 内部类 WorkQueue 共享的一些常量
// Constants shared across ForkJoinPool and WorkQueue
// 限定参数
static final int SMASK = 0xffff; // 低位掩码,也是最大索引位
static final int MAX_CAP = 0x7fff; // 工作线程最大容量
static final int EVENMASK = 0xfffe; // 偶数低位掩码
static final int SQMASK = 0x007e; // workQueues 数组最多64个槽位
// ctl 子域和 WorkQueue.scanState 的掩码和标志位
static final int SCANNING = 1; // 标记是否正在运行任务
static final int INACTIVE = 1 << 31; // 失活状态 负数
static final int SS_SEQ = 1 << 16; // 版本戳,防止ABA问题
// ForkJoinPool.config 和 WorkQueue.config 的配置信息标记
static final int MODE_MASK = 0xffff << 16; // 模式掩码
static final int LIFO_QUEUE = 0; //LIFO队列
static final int FIFO_QUEUE = 1 << 16;//FIFO队列
static final int SHARED_QUEUE = 1 << 31; // 共享模式队列,负数
相关常量和实例字段
// 低位和高位掩码
private static final long SP_MASK = 0xffffffffL;
private static final long UC_MASK = ~SP_MASK;
// 活跃线程数
private static final int AC_SHIFT = 48;
private static final long AC_UNIT = 0x0001L << AC_SHIFT; //活跃线程数增量
private static final long AC_MASK = 0xffffL << AC_SHIFT; //活跃线程数掩码
// 工作线程数
private static final int TC_SHIFT = 32;
private static final long TC_UNIT = 0x0001L << TC_SHIFT; //工作线程数增量
private static final long TC_MASK = 0xffffL << TC_SHIFT; //掩码
private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // 创建工作线程标志
// 池状态
private static final int RSLOCK = 1;
private static final int RSIGNAL = 1 << 1;
private static final int STARTED = 1 << 2;
private static final int STOP = 1 << 29;
private static final int TERMINATED = 1 << 30;
private static final int SHUTDOWN = 1 << 31;
// 实例字段
volatile long ctl; // 主控制参数
volatile int runState; // 运行状态锁
final int config; // 并行度|模式
int indexSeed; // 用于生成工作线程索引
volatile WorkQueue[] workQueues; // 主对象注册信息,workQueue
final ForkJoinWorkerThreadFactory factory;// 线程工厂
final UncaughtExceptionHandler ueh; // 每个工作线程的异常信息
final String workerNamePrefix; // 用于创建工作线程的名称
volatile AtomicLong stealCounter; // 偷取任务总数,也可作为同步监视器
/** 静态初始化字段 */
//线程工厂
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
//启动或杀死线程的方法调用者的权限
private static final RuntimePermission modifyThreadPermission;
// 公共静态pool
static final ForkJoinPool common;
//并行度,对应内部common池
static final int commonParallelism;
//备用线程数,在tryCompensate中使用
private static int commonMaxSpares;
//创建workerNamePrefix(工作线程名称前缀)时的序号
private static int poolNumberSequence;
//线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒
private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec
//空闲超时时间,防止timer未命中
private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms
//默认备用线程数
private static final int DEFAULT_COMMON_MAX_SPARES = 256;
//阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中
private static final int SPINS = 0;
//indexSeed的增量
private static final int SEED_INCREMENT = 0x9e3779b9;
ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成:
- AC: 正在运行工作线程数减去目标并行度,高16位
- TC: 总工作线程数减去目标并行度,中高16位
- SS: 栈顶等待线程的版本计数和状态,中低16位
- ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
ForkJoinTask
属性
/** 任务运行状态 */
volatile int status; // 任务运行状态
static final int DONE_MASK = 0xf0000000; // 任务完成状态标志位
static final int NORMAL = 0xf0000000; // must be negative
static final int CANCELLED = 0xc0000000; // must be < NORMAL
static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
static final int SIGNAL = 0x00010000; // must be >= 1 << 16 等待信号
static final int SMASK = 0x0000ffff; // 低位掩码
ForkJoinTask实现了Future接口,是一个异步任务,我们在使用Fork/Join框架时,一般需要使用线程池来调度任务,线程池内部调度的其实都是ForkJoinTask任务(即使提交的是一个Runnable或Callable任务,也会被适配成ForkJoinTask)。
除了ForkJoinTask,Fork/Join框架还提供了两个它的抽象实现,我们在自定义ForkJoin任务时,一般继承这两个类:
- RecursiveAction:表示具有返回结果的ForkJoin任务
- RecursiveTask:表示没有返回结果的ForkJoin任务

ForkJoinWorkerThread
fork/Join框架中,每个工作线程(Worker)都有一个自己的任务队列(WorkerQueue), 所以需要对一般的Thread做些特性化处理,J.U.C提供了ForkJoinWorkerThread类作为ForkJoinPool中的工作线程:
public class ForkJoinWorkerThread extends Thread {
final ForkJoinPool pool; // 该工作线程归属的线程池
final ForkJoinPool.WorkQueue workQueue; // 对应的任务队列
protected ForkJoinWorkerThread(ForkJoinPool pool) {
super("aForkJoinWorkerThread"); // 指定工作线程名称
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
// ...
}
ForkJoinWorkerThread 在构造过程中,会保存所属线程池信息和与自己绑定的任务队列信息。同时,它会通过ForkJoinPool的registerWorker方法将自己注册到线程池中。
线程池中的每个工作线程(ForkJoinWorkerThread)都有一个自己的任务队列(WorkQueue),工作线程优先处理自身队列中的任务(LIFO或FIFO顺序,由线程池构造时的参数 mode 决定),自身队列为空时,以FIFO的顺序随机窃取其它队列中的任务
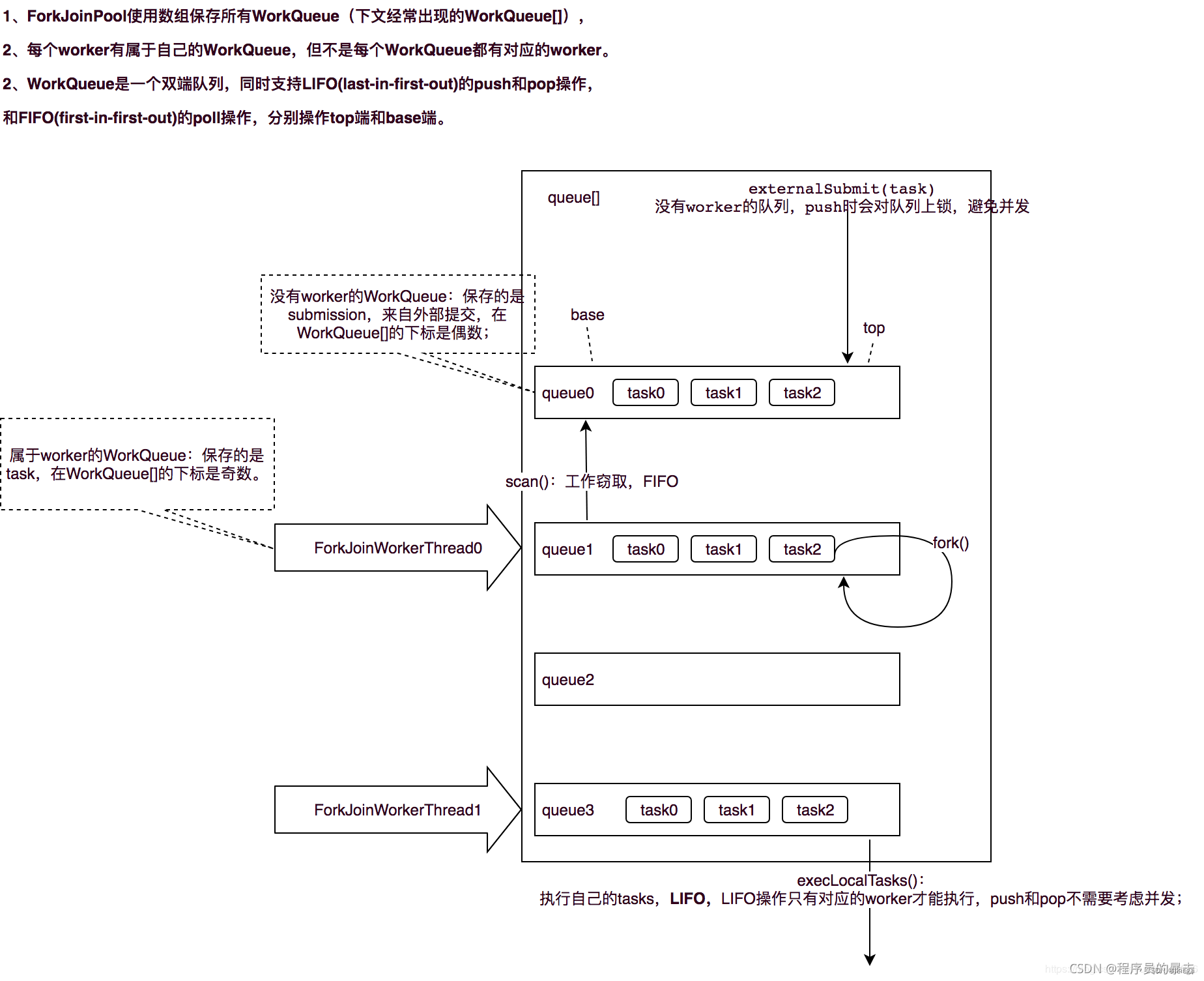
WorkQueue
任务队列(WorkQueue)是ForkJoinPool与其它线程池区别最大的地方,在ForkJoinPool内部,维护着一个WorkQueue[]数组,它会在外部首次提交任务)时进行初始化
WorkQueue作为ForkJoinPool的内部类,表示一个双端队列。双端队列既可以作为栈使用(LIFO),也可以作为队列使用(FIFO)。ForkJoinPool的“工作窃取”正是利用了这个特点,当工作线程从自己的队列中获取任务时,默认总是以栈操作(LIFO)的方式从栈顶取任务;当工作线程尝试窃取其它任务队列中的任务时,则是FIFO的方式。
可以指定线程池的同步/异步模式(mode参数),其作用就在于此。同步模式就是“栈操作”,异步模式就是“队列操作”,影响的就是工作线程从自己队列中取任务的方式
属性
//初始队列容量,2的幂
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
//最大队列容量
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
// 实例字段
volatile int scanState; // Woker状态, <0: inactive; odd:scanning
int stackPred; // 记录前一个栈顶的ctl
int nsteals; // 偷取任务数
int hint; // 记录偷取者索引,初始为随机索引
int config; // 池索引和模式
volatile int qlock; // 1: locked, < 0: terminate; else 0
volatile int base; //下一个poll操作的索引(栈底/队列头)
int top; // 下一个push操作的索引(栈顶/队列尾)
ForkJoinTask<?>[] array; // 任务数组
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // 当前工作队列的工作线程,共享模式下为null
volatile Thread parker; // 调用park阻塞期间为owner,其他情况为null
volatile ForkJoinTask<?> currentJoin; // 记录被join过来的任务
volatile ForkJoinTask<?> currentSteal; // 记录从其他工作队列偷取过来的任务
ForkJoinPool中的工作队列可以分为两类:
- 有工作线程(Worker)绑定的任务队列:数组下标始终是奇数,称为task queue,该队列中的任务均由工作线程调用产生(工作线程调用FutureTask.fork方法);
- 没有工作线程(Worker)绑定的任务队列:数组下标始终是偶数,称为submissions queue,该队列中的任务全部由其它线程提交(也就是非工作线程调用execute/submit/invoke或者FutureTask.fork方法)
任务提交
外部提交任务
所谓外部提交任务,是指通过ForkJoinPool的execute/submit/invoke方法提交的任务,或者非工作线程(ForkJoinWorkerThread)直接调用ForkJoinTask的fork/invoke方法提交的任务:

public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task;
}
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws;
WorkQueue q;
int m;
int r = ThreadLocalRandom.getProbe();
int rs = runState;
// m & r & SQMASK必为偶数,所以通过externalPush方法提交的任务都添加到了偶数索引的任务队列中(没有绑定的工作线程)
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&//获取随机偶数槽位的workQueue
U.compareAndSwapInt(q, QLOCK, 0, 1)) {//锁定workQueue
ForkJoinTask<?>[] a;
int am, n, s;
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;//计算任务索引位置
U.putOrderedObject(a, j, task);//任务入列
U.putOrderedInt(q, QTOP, s + 1);//更新push slot
U.putIntVolatile(q, QLOCK, 0);//解除锁定
if (n <= 1) // 队列里只有一个任务
signalWork(ws, q); // 创建或激活一个工作线程
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);//解除锁定
}
// 未命中任务队列时(WorkQueue == null 或 WorkQueue[i] == null),会进入该方法
externalSubmit(task);
}
externalPush方法包含两部分:
- 根据线程随机变量、任务队列数组信息,计算命中槽(即本次提交的任务应该添加到任务队列数组中的哪个队列),如果命中且队列中任务数<1,则创建或激活一个工作线程;
- 否则,调用externalSubmit初始化队列,并入队
private void externalSubmit(ForkJoinTask<?> task) {
int r; // 线程相关的随机数
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (; ; ) {
WorkQueue[] ws;
WorkQueue q;
int rs, m, k;
boolean move = false;
// CASE1: 线程池已关闭
if ((rs = runState) < 0) {
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
// CASE2: 初始化线程池
else if ((rs & STARTED) == 0 || // initialize
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
rs = lockRunState();
try {
if ((rs & STARTED) == 0) {
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
// 初始化工作队列数组, 数组大小必须为2的幂次
int p = config & SMASK;
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n = (n + 1) << 1;
workQueues = new WorkQueue[n];
ns = STARTED; // 线程池状态转化为STARTED
}
} finally {
unlockRunState(rs, (rs & ~RSLOCK) | ns);//解锁并更新runState
}
}
// CASE3: 入队任务
else if ((q = ws[k = r & m & SQMASK]) != null) {//获取随机偶数槽位的workQueue
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask<?>[] a = q.array;//当前workQueue的全部任务
int s = q.top;
boolean submitted = false; // initial submission or resizing
try { // locked version of push
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {//扩容
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);//放入给定任务
U.putOrderedInt(q, QTOP, s + 1);
submitted = true;
}
} finally {
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
if (submitted) {
signalWork(ws, q);
return;
}
}
move = true; // move on failure
}
// CASE4: 创建一个任务队列
else if (((rs = runState) & RSLOCK) == 0) {
q = new WorkQueue(this, null);
q.hint = r;
q.config = k | SHARED_QUEUE; // k为任务队列在队列数组中的索引: k == r & m & SQMASK, 在CASE3的IF判断中赋值
q.scanState = INACTIVE; // 任务队列状态为INACTIVE
rs = lockRunState();
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
ws[k] = q; // 更新索引k位值的workQueue
unlockRunState(rs, rs & ~RSLOCK);
} else
move = true; // move if busy
if (move)
r = ThreadLocalRandom.advanceProbe(r);//重新获取线程探针值
}
}
- CASE1:线程池已经关闭,则执行终止操作,并拒绝该任务的提交;
- CASE2:线程池未初始化,则进行初始化,主要就是初始化任务队列数组;
- CASE3:命中了任务队列,则将任务入队,并尝试创建/唤醒一个工作线程(Worker);
- CASE4:未命中任务队列,则在偶数索引处创建一个任务队列
工作线程fork任务
所谓工作线程fork任务,是指由ForkJoinPool所维护的工作线程(ForkJoinWorkerThread)从自身任务队列中获取任务(或从其它任务队列窃取),然后执行任务。
工作线程fork任务的特点就是调用线程是工作线程
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) // 如果调用线程为【工作线程】
((ForkJoinWorkerThread) t).workQueue.push(this); // 直接添加到线程的自身队列中
else
ForkJoinPool.common.externalPush(this); // 外部(其它线程)提交的任务
return this;
}
WorkQueue.push方法,任务存入自身队列的栈顶(top)
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a;
ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1); // 任务存入栈顶(top+1)
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this); // 唤醒或创建一个工作线程
} else if (n >= m)
growArray(); // 扩容
}
}
创建工作线程
任务提交完成后,ForkJoinPool会根据情况创建或唤醒工作线程,以便执行任务。
ForkJoinPool并不会为每个任务都创建工作线程,而是根据实际情况(构造线程池时的参数)确定是唤醒已有空闲工作线程,还是新建工作线程。这个过程还是涉及任务队列的绑定、工作线程的注销等过程
任务提交后,会调用signalWork方法创建或唤醒一个工作线程,该方法的核心其实就两个分支:
- 工作线程数不足:创建一个工作线程;
- 工作线程数足够:唤醒一个空闲(阻塞)的工作线程。
/**
* 尝试创建或唤醒一个工作线程.
*
* @param ws 任务队列数组
* @param q 当前操作的任务队列WorkQueue
*/
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c;
int sp, i;
WorkQueue v;
Thread p;
while ((c = ctl) < 0L) { // too few active
// CASE1: 工作线程数不足
if ((sp = (int) c) == 0) {
if ((c & ADD_WORKER) != 0L)
tryAddWorker(c); // 增加工作线程
break;
}
// CASE2: 存在空闲工作线程,则唤醒
if (ws == null) // unstarted/terminated
break;
if (ws.length <= (i = sp & SMASK)) // terminated
break;
if ((v = ws[i]) == null) // terminating
break;
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
int d = sp - v.scanState; // screen CAS
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // activate v
if ((p = v.parker) != null)
U.unpark(p);
break;
}
if (q != null && q.base == q.top) // no more work
break;
}
}
先来看创建工作线程的方法tryAddWorker,其实就是设置下字段值(活跃/总工作线程池数),然后调用createWorker真正创建一个工作线程
private void tryAddWorker(long c) {
boolean add = false;
do {
// 设置活跃工作线程数、总工作线程池数
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
if (ctl == c) {
int rs, stop; // check if terminating
if ((stop = (rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);
unlockRunState(rs, rs & ~RSLOCK);
if (stop != 0)
break;
// 创建工作线程
if (add) {
createWorker();
break;
}
}
} while (((c = ctl) & ADD_WORKER) != 0L && (int) c == 0);
}
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
// 使用线程池工厂创建线程
if (fac != null && (wt = fac.newThread(this)) != null) {
wt.start(); // 启动线程
return true;
}
} catch (Throwable rex) {
ex = rex;
}
// 创建出现异常,则注销该工作线程
deregisterWorker(wt, ex);
return false;
}
如果创建过程中出现异常,则调用deregisterWorker注销线程:
final void deregisterWorker(ForkJoinWorkerThread wt, Throwable ex) {
WorkQueue w = null;
// 1.移除workQueue
if (wt != null && (w = wt.workQueue) != null) { // 获取ForkJoinWorkerThread的等待队列
WorkQueue[] ws;
int idx = w.config & SMASK; // 计算workQueue索引
int rs = lockRunState(); // 获取runState锁和当前池运行状态
if ((ws = workQueues) != null && ws.length > idx && ws[idx] == w)
ws[idx] = null; // 移除workQueue
unlockRunState(rs, rs & ~RSLOCK); // 解除runState锁
}
// 2.减少CTL数
long c; // decrement counts
do {
} while (!U.compareAndSwapLong
(this, CTL, c = ctl, ((AC_MASK & (c - AC_UNIT)) |
(TC_MASK & (c - TC_UNIT)) |
(SP_MASK & c))));
// 3.处理被移除workQueue内部相关参数
if (w != null) {
w.qlock = -1; // ensure set
w.transferStealCount(this);
w.cancelAll(); // cancel remaining tasks
}
// 4.如果线程未终止,替换被移除的workQueue并唤醒内部线程
for (; ; ) { // possibly replace
WorkQueue[] ws;
int m, sp;
// 尝试终止线程池
if (tryTerminate(false, false) || w == null || w.array == null ||
(runState & STOP) != 0 || (ws = workQueues) == null ||
(m = ws.length - 1) < 0) // already terminating
break;
// 唤醒被替换的线程,依赖于下一步
if ((sp = (int) (c = ctl)) != 0) { // wake up replacement
if (tryRelease(c, ws[sp & m], AC_UNIT))
break;
}
// 创建工作线程替换
else if (ex != null && (c & ADD_WORKER) != 0L) {
tryAddWorker(c); // create replacement
break;
} else // don't need replacement
break;
}
// 5.处理异常
if (ex == null) // help clean on way out
ForkJoinTask.helpExpungeStaleExceptions();
else // rethrow
ForkJoinTask.rethrow(ex);
}
deregisterWorker方法用于工作线程运行完毕之后终止线程或处理工作线程异常,主要就是清除已关闭的工作线程或回滚创建线程之前的操作,并把传入的异常抛给 ForkJoinTask 来处理。
工作线程在构造的过程中,会保存线程池信息和与自己绑定的任务队列信息。它通过ForkJoinPool.registerWorker方法将自己注册到线程池中:
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
// 创建一个工作队列, 并于该工作线程绑定
WorkQueue w = new WorkQueue(this, wt);
int i = 0; // 记录队列在任务队列数组中的索引, 始终为奇数
int mode = config & MODE_MASK;
int rs = lockRunState();
try {
WorkQueue[] ws;
int n;
if ((ws = workQueues) != null && (n = ws.length) > 0) {
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
int m = n - 1;
i = ((s << 1) | 1) & m; // 经计算后, i为奇数
if (ws[i] != null) { // 槽冲突, 即WorkQueue[i]位置已经有了任务队列
// 重新计算索引i
int probes = 0; // step by approx half n
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
while (ws[i = (i + step) & m] != null) {
if (++probes >= n) {
workQueues = ws = Arrays.copyOf(ws, n <<= 1);
m = n - 1;
probes = 0;
}
}
}
// 设置队列状态为SCANNING
w.hint = s; // use as random seed
w.config = i | mode;
w.scanState = i; // publication fence
ws[i] = w;
}
} finally {
unlockRunState(rs, rs & ~RSLOCK);
}
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
任务执行
任务入队后,由工作线程开始执行,这个过程涉及任务窃取、工作线程等待等过程
会执行它的run方法,该方法内部调用了ForkJoinPool.runWorker方法来执行任务
public void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart(); // 钩子方法
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);
}
}
}
}
runWorker方法的核心流程如下:
- scan:尝试获取一个任务;
- runTask:执行取得的任务;
- awaitWork:没有任务则阻塞
final void runWorker(WorkQueue w) {
w.growArray(); // 初始化任务队列
int seed = w.hint; // initially holds randomization hint
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
for (ForkJoinTask<?> t; ; ) {
// CASE1: 尝试获取一个任务
if ((t = scan(w, r)) != null)
w.runTask(t); // 获取成功, 执行任务
// CASE2: 获取失败, 阻塞等待任务入队
else if (!awaitWork(w, r)) // 等待失败, 跳出该方法后, 工作线程会被注销
break;
r ^= r << 13;
r ^= r >>> 17;
r ^= r << 5; // xorshift
}
}
如果awaitWork返回false,等不到任务,则跳出runWorker的循环,回到run中执行finally,最后调用deregisterWorker注销工作线程。
任务窃取——scan
private ForkJoinTask<?> scan(WorkQueue w, int r) {
WorkQueue[] ws;
int m;
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
int ss = w.scanState; // initially non-negative
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0; ; ) {
WorkQueue q;
ForkJoinTask<?>[] a;
ForkJoinTask<?> t;
int b, n;
long c;
// 根据随机数r定位一个任务队列
if ((q = ws[k]) != null) { // 获取workQueue
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) { // non-empty
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
if ((t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i))) != null && // 取base位置任务
q.base == b) {
// 成功获取到任务
if (ss >= 0) {
if (U.compareAndSwapObject(a, i, t, null)) {
q.base = b + 1; // 更新base位
if (n < -1)
signalWork(ws, q); // 创建或唤醒工作线程来运行任务
return t;
}
} else if (oldSum == 0 && // try to activate
w.scanState < 0)
tryRelease(c = ctl, ws[m & (int) c], AC_UNIT); // 唤醒栈顶工作线程
}
// base位置任务为空或base位置偏移,随机移位重新扫描
if (ss < 0) // refresh
ss = w.scanState;
r ^= r << 1;
r ^= r >>> 3;
r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;
}
if ((k = (k + 1) & m) == origin) { // continue until stable
// 运行到这里说明已经扫描了全部的 workQueues,但并未扫描到任务
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
oldSum == (oldSum = checkSum)) {
if (ss < 0 || w.qlock < 0) // already inactive
break;
// 对当前WorkQueue进行灭活操作
int ns = ss | INACTIVE; // try to inactivate
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));
w.stackPred = (int) c; // hold prev stack top
U.putInt(w, QSCANSTATE, ns);
if (U.compareAndSwapLong(this, CTL, c, nc))
ss = ns;
else
w.scanState = ss; // back out
}
checkSum = 0;
}
}
}
return null;
}
机选择一个WorkQueue,获取base位的 ForkJoinTask,成功取到后更新base位并返回任务;如果取到的 WorkQueue 中任务数大于1,则调用signalWork创建或唤醒其他工作线程。
阻塞等待——awaitWork
如果scan方法未扫描到任务,会调用awaitWork等待获取任务:
private boolean awaitWork(WorkQueue w, int r) {
if (w == null || w.qlock < 0) // w is terminating
return false;
for (int pred = w.stackPred, spins = SPINS, ss; ; ) {
if ((ss = w.scanState) >= 0) // 正在扫描,跳出循环
break;
else if (spins > 0) {
r ^= r << 6;
r ^= r >>> 21;
r ^= r << 7;
if (r >= 0 && --spins == 0) { // randomize spins
WorkQueue v;
WorkQueue[] ws;
int s, j;
AtomicLong sc;
if (pred != 0 && (ws = workQueues) != null &&
(j = pred & SMASK) < ws.length &&
(v = ws[j]) != null && // see if pred parking
(v.parker == null || v.scanState >= 0))
spins = SPINS; // continue spinning
}
} else if (w.qlock < 0) // 当前workQueue已经终止,返回false recheck after spins
return false;
else if (!Thread.interrupted()) { // 判断线程是否被中断,并清除中断状态
long c, prevctl, parkTime, deadline;
int ac = (int) ((c = ctl) >> AC_SHIFT) + (config & SMASK); // 活跃线程数
if ((ac <= 0 && tryTerminate(false, false)) || // 无active线程,尝试终止
(runState & STOP) != 0) // pool terminating
return false;
if (ac <= 0 && ss == (int) c) { // is last waiter
// 计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
prevctl = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & pred);
int t = (short) (c >>> TC_SHIFT); // shrink excess spares
if (t > 2 && U.compareAndSwapLong(this, CTL, c, prevctl))//总线程过量
return false; // else use timed wait
// 计算空闲超时时间
parkTime = IDLE_TIMEOUT * ((t >= 0) ? 1 : 1 - t);
deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP;
} else
prevctl = parkTime = deadline = 0L;
Thread wt = Thread.currentThread();
U.putObject(wt, PARKBLOCKER, this); // emulate LockSupport
w.parker = wt; // 设置parker,准备阻塞
if (w.scanState < 0 && ctl == c) // recheck before park
U.park(false, parkTime); // 阻塞指定的时间
U.putOrderedObject(w, QPARKER, null);
U.putObject(wt, PARKBLOCKER, null);
if (w.scanState >= 0) // 正在扫描,说明等到任务,跳出循环
break;
if (parkTime != 0L && ctl == c &&
deadline - System.nanoTime() <= 0L &&
U.compareAndSwapLong(this, CTL, c, prevctl)) // 未等到任务,更新ctl,返回false
return false; // shrink pool
}
}
return true;
}
任务执行——runTask
窃取到任务后,调用WorkQueue.runTask方法执行任务:
final void runTask(ForkJoinTask<?> task) {
if (task != null) {
scanState &= ~SCANNING; // mark as busy
(currentSteal = task).doExec(); // 更新currentSteal并执行任务
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks(); // 依次执行本地任务
ForkJoinWorkerThread thread = owner;
if (++nsteals < 0) // collect on overflow
transferStealCount(pool); // 增加偷取任务数
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec(); // 执行钩子函数
}
}
1.首先调用FutureTask.deExec()执行任务,其内部会调用FutureTask.exec()方法,该方法为抽象方法,由子类实现。
子类实现该方法时,一般会进行fork,导致生成子任务,并最终添加到调用线程自身地任务队列中
final int doExec() {
int s;
boolean completed;
if ((s = status) >= 0) {
try {
completed = exec(); // exec为抽象方法, 由子类实现
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
s = setCompletion(NORMAL);
}
return s;
}
2.除了执行窃取到的任务,工作线程还会执行自己队列中的任务,即WorkQueue.execLocalTasks方法
final void execLocalTasks() {
int b = base, m, s;
ForkJoinTask<?>[] a = array;
if (b - (s = top - 1) <= 0 && a != null &&
(m = a.length - 1) >= 0) {
if ((config & FIFO_QUEUE) == 0) { // LIFO, 从top -> base 遍历执行任务
for (ForkJoinTask<?> t; ; ) {
if ((t = (ForkJoinTask<?>) U.getAndSetObject
(a, ((m & s) << ASHIFT) + ABASE, null)) == null)
break;
U.putOrderedInt(this, QTOP, s);
t.doExec();
if (base - (s = top - 1) > 0)
break;
}
} else // FIFO, 从base -> top 遍历执行任务
pollAndExecAll();
}
}
构建线程池时的asyncMode参数,决定了工作线程执行自身队列中的任务的方式。如果 asyncMode == true,则以FIFO的方式执行任务;否则,以LIFO的方式执行任务
任务结果获取
任务结果一般通过ForkJoinTask的join方法获得,其主要流程如下图
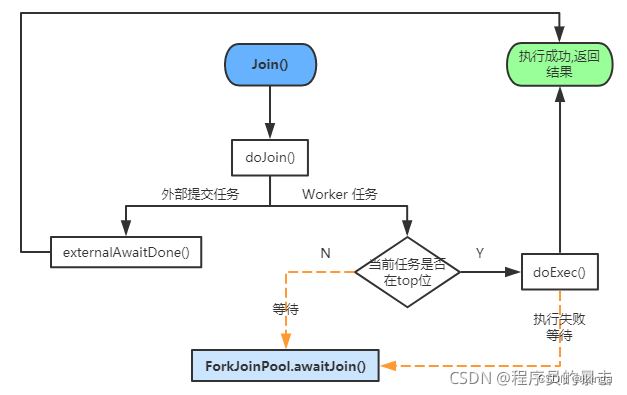
核心涉及两点:
互助窃取:ForkJoinPool.helpStealer
算力补偿:ForkJoinPool.tryCompensate
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
可以看到,内部先调用doJoin方法
private int doJoin() {
int s;
Thread t;
ForkJoinWorkerThread wt;
ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread) t).workQueue).tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
doJoin方法会判断调用线程是否是工作线程:
-
如果是非工作线程调用的join,则最终调用
externalAwaitDone()阻塞等待任务的完成。 -
如果是工作线程调用的join,则存在以下情况:
- 如果需要join的任务已经完成,直接返回运行结果;
- 如果需要join的任务刚刚好是当前线程所拥有的队列的top位置,则立即执行它。
- 如果该任务不在top位置,则调用awaitJoin方法等待
final int awaitJoin(WorkQueue w, ForkJoinTask<?> task, long deadline) {
int s = 0;
if (task != null && w != null) {
ForkJoinTask<?> prevJoin = w.currentJoin; // 获取给定Worker的join任务
U.putOrderedObject(w, QCURRENTJOIN, task); // 把currentJoin替换为给定任务
// 判断是否为CountedCompleter类型的任务
CountedCompleter<?> cc = (task instanceof CountedCompleter) ?
(CountedCompleter<?>) task : null;
for (; ; ) {
if ((s = task.status) < 0) // 已经完成|取消|异常 跳出循环
break;
if (cc != null) // CountedCompleter任务由helpComplete来完成join
helpComplete(w, cc, 0);
else if (w.base == w.top || w.tryRemoveAndExec(task)) //尝试执行
helpStealer(w, task); // 队列为空或执行失败,任务可能被偷,帮助偷取者执行该任务
if ((s = task.status) < 0) // 已经完成|取消|异常,跳出循环
break;
// 计算任务等待时间
long ms, ns;
if (deadline == 0L)
ms = 0L;
else if ((ns = deadline - System.nanoTime()) <= 0L)
break;
else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L)
ms = 1L;
if (tryCompensate(w)) { // 执行补偿操作
task.internalWait(ms); // 补偿执行成功,任务等待指定时间
U.getAndAddLong(this, CTL, AC_UNIT); // 更新活跃线程数
}
}
U.putOrderedObject(w, QCURRENTJOIN, prevJoin); // 循环结束,替换为原来的join任务
}
return s;
}
ForkJoinPool.awaitJoin`方法中有三个重要方法:
- tryRemoveAndExec
- helpStealer
- tryCompensate
这里说下这三个方法的主要作用,不贴代码了:
tryRemoveAndExec:
当工作线程正在等待join的任务时,它会从top位开始自旋向下查找该任务:
如果找到则移除并执行它;
如果找不到,说明说明任务可能被偷,则调用helpStealer方法反过来帮助偷取者执行它自己的任务。
helpStealer:
先定位的偷取者的任务队列;
从偷取者的base索引开始,每次偷取一个任务执行。
tryCompensate:
tryCompensate主要用来补偿工作线程因为阻塞而导致的算力损失,当工作线程自身的队列不为空,且还有其它空闲工作线程时,如果自己阻塞了,则在此之前会唤醒一个工作线程.
CompletableFuture
public class CompletableFutureDemo {
public static void main(String[] args)
throws Exception {
CompletableFutureDemo completableFutureDemo = new CompletableFutureDemo();
System.out.println(completableFutureDemo.getPrices());
}
private Set<Integer> getPrices() {
Set<Integer> prices = Collections.synchronizedSet(new HashSet<Integer>());
CompletableFuture<Void> task1 = CompletableFuture.runAsync(new Task(123, prices));
CompletableFuture<Void> task2 = CompletableFuture.runAsync(new Task(456, prices));
CompletableFuture<Void> task3 = CompletableFuture.runAsync(new Task(789, prices));
CompletableFuture<Void> allTasks = CompletableFuture.allOf(task1, task2, task3);
try {
allTasks.get(3, TimeUnit.SECONDS);
} catch (InterruptedException e) {
} catch (ExecutionException e) {
} catch (TimeoutException e) {
}
return prices;
}
private class Task implements Runnable {
Integer productId;
Set<Integer> prices;
public Task(Integer productId, Set<Integer> prices) {
this.productId = productId;
this.prices = prices;
}
@Override
public void run() {
int price = 0;
try {
Thread.sleep((long) (Math.random() * 4000));
price = (int) (Math.random() * 4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
prices.add(price);
}
}
}
我们看到 getPrices 方法,在这个方法中,我们用了 CompletableFuture 的 runAsync 方法,这个方法会异步的去执行任务
我们有三个任务,并且在执行这个代码之后会分别返回一个 CompletableFuture 对象,我们把它们命名为 task 1、task 2、task 3,然后执行 CompletableFuture 的 allOf 方法,并且把 task 1、task 2、task 3 传入。这个方法的作用是把多个 task 汇总,然后可以根据需要去获取到传入参数的这些 task 的返回结果,或者等待它们都执行完毕等。我们就把这个返回值叫作 allTasks,并且在下面调用它的带超时时间的 get 方法,同时传入 3 秒钟的超时参数
这样一来它的效果就是,如果在 3 秒钟之内这 3 个任务都可以顺利返回,也就是这个任务包括的那三个任务,每一个都执行完毕的话,则这个 get 方法就可以及时正常返回,并且往下执行,相当于执行到 return prices。在下面的这个 Task 的 run 方法中,该方法如果执行完毕的话,对于 CompletableFuture 而言就意味着这个任务结束,它是以这个作为标记来判断任务是不是执行完毕的。但是如果有某一个任务没能来得及在 3 秒钟之内返回,那么这个带超时参数的 get 方法便会抛出 TimeoutException 异常,同样会被我们给 catch 住。这样一来它就实现了这样的效果:会尝试等待所有的任务完成,但是最多只会等 3 秒钟,在此之间,如及时完成则及时返回。那么所以我们利用 CompletableFuture,同样也可以解决旅游平台的问题。它的运行结果也和之前是一样的,有多种可能性
如何利用 CompletableFuture 实现“旅游平台”问题?






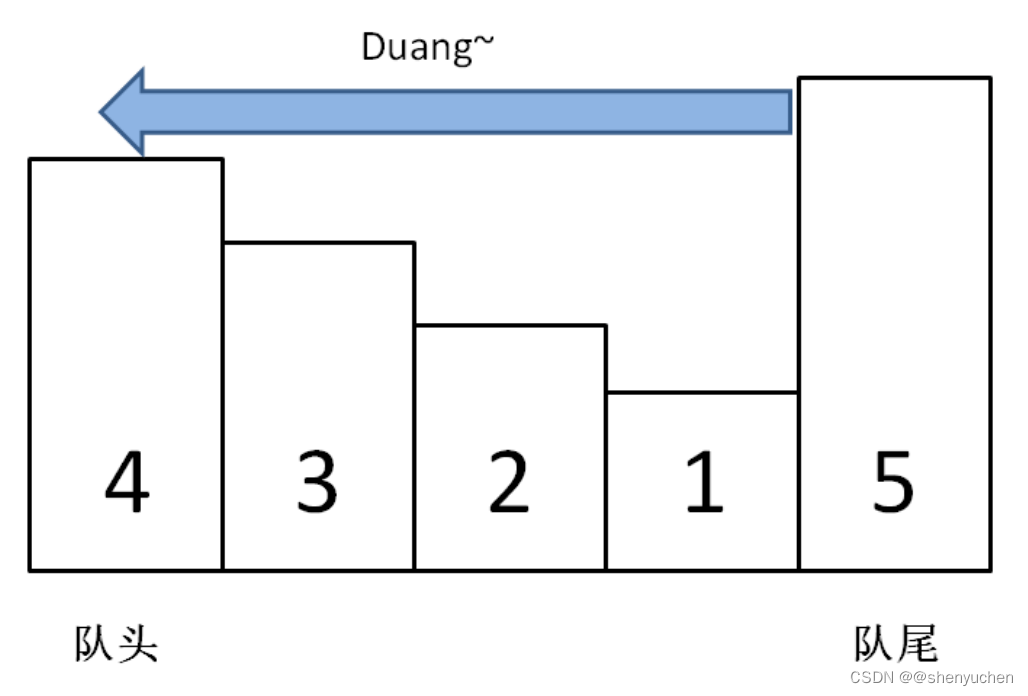



![[附源码]Python计算机毕业设计Django咖啡销售平台](https://img-blog.csdnimg.cn/7648c325f84b41438e218d7d03bdbcde.png)