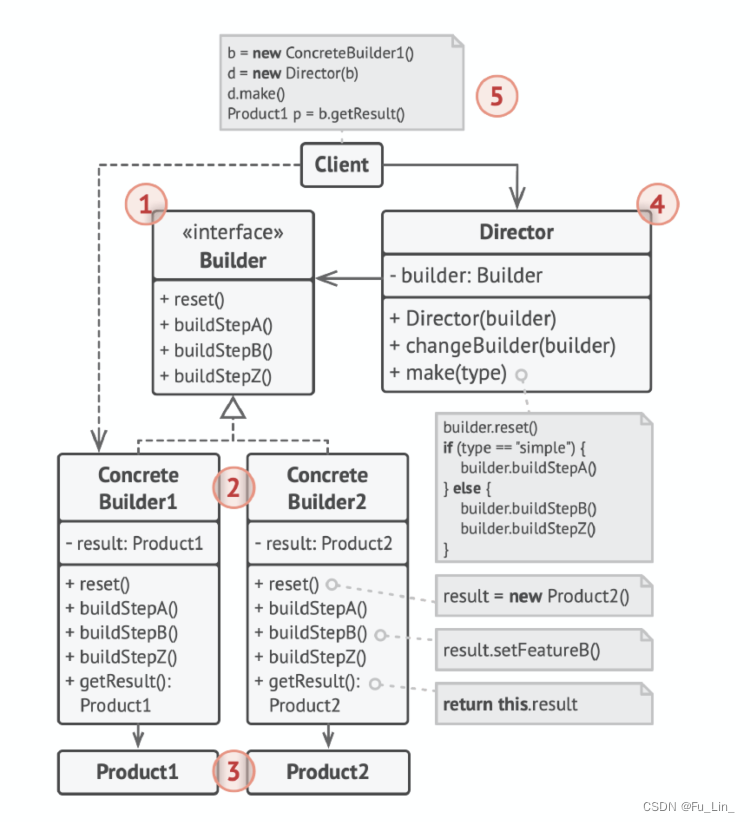
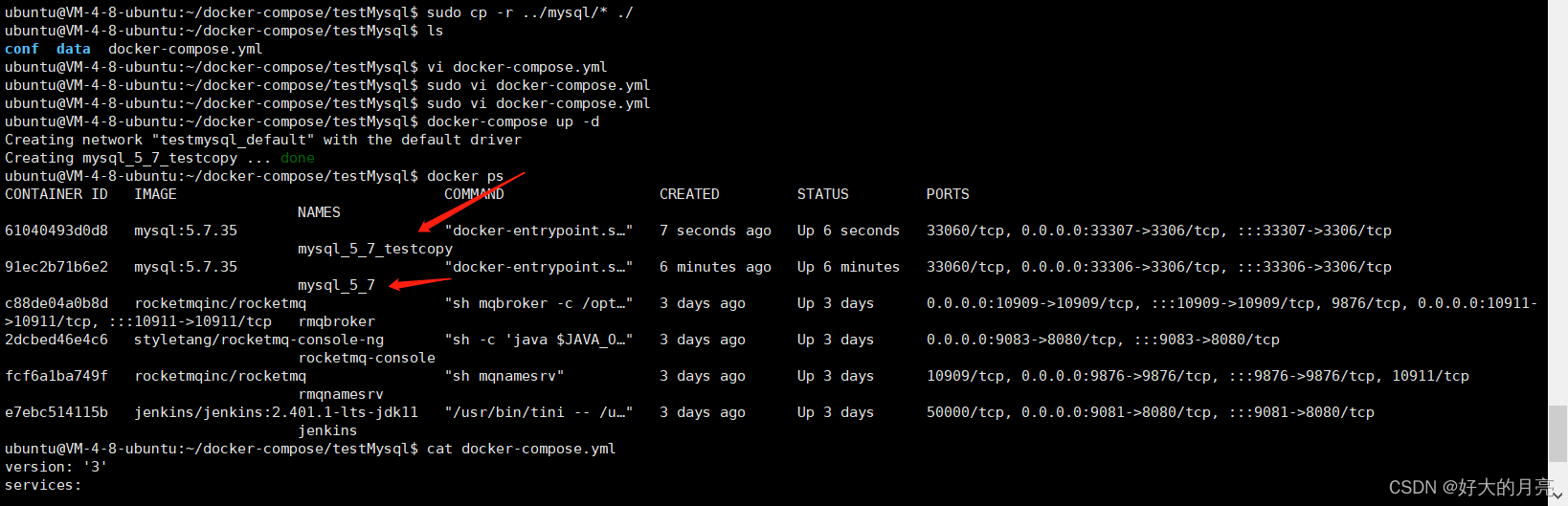
Python中的分词技术及其应用
什么是分词?
分词是自然语言处理(Natural Language Processing,NLP)中的一个重要环节,指将一段文本切分成若干个单词或词组。在中文分词中,由于中文没有明显的词汇边界,而且一些词可能有多种不同的词义,因此中文分词具有一定的难度。Python中提供了多种中文分词工具,比如jieba、thulac等。
Python中的分词技术
jieba
jieba是一款高效灵活的中文分词工具,使用起来非常方便。它支持三种分词模式:精确模式(默认模式)、全模式和搜索引擎模式。其中,精确模式表示将文本按照最大概率分成最小的词语单元;全模式则表示将文本按照所有可能的词语单元分割,返回所有分词结果,搜索引擎模式类似于全模式,但是会对长词再次切分,提高召回率。
使用jieba分词非常简单,只需要先安装jieba包,然后调用分词函数即可。例如:
import jieba
text = "我来自中国北京"
seg_list = jieba.cut(text, cut_all=False)
print("|".join(seg_list))
输出结果是:我|来自|中国|北京
THULAC
THULAC是由清华大学自然语言处理与社会人文计算实验室开发的一款中文分词工具。与jieba相比,THULAC在分词准确率、处理速度等方面都有一定的优势。同时,THULAC还支持分词的粒度控制、词性标注等功能。
使用THULAC分词也非常简单,只需要先安装thulac包,然后调用分词函数即可。例如:
import thulac
thu1 = thulac.thulac(seg_only=True) # 只进行分词,不做词性标注
text = "我来自中国北京"
seg_list = thu1.cut(text, text=True).split()
print("|".join(seg_list))
输出结果也是:我|来自|中国|北京
分词技术的应用
中文分词技术在实际应用中有很多用途,例如:
文本处理与分析
在自然语言处理中,分词是非常基础的操作,通常是文本预处理的第一步。通过对文本进行分词,可以得到文本中的关键词,从而进行文本分类、聚类、情感分析等任务。同时,还可以通过统计词频、关键词提取等方式进一步挖掘文本的信息。
搜索与推荐
在搜索引擎和推荐系统中,分词技术也非常重要。通过对用户输入或商品描述等文本进行分词,可以得到词汇向量,进而进行文本相似性度量、相关性匹配等操作,从而提高搜索和推荐的准确度。
机器翻译与语音识别
中文分词技术在机器翻译和语音识别等领域也有很广泛的应用。通过对输入文本进行分词和词性标注,可以提高机器翻译和语音识别的准确度。
结论
中文分词是自然语言处理中的一个基础环节,Python中提供了多种中文分词工具,例如jieba和THULAC。通过对文本进行分词,并结合其他自然语言处理技术,可以实现文本处理与分析、搜索与推荐、机器翻译与语音识别等任务。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
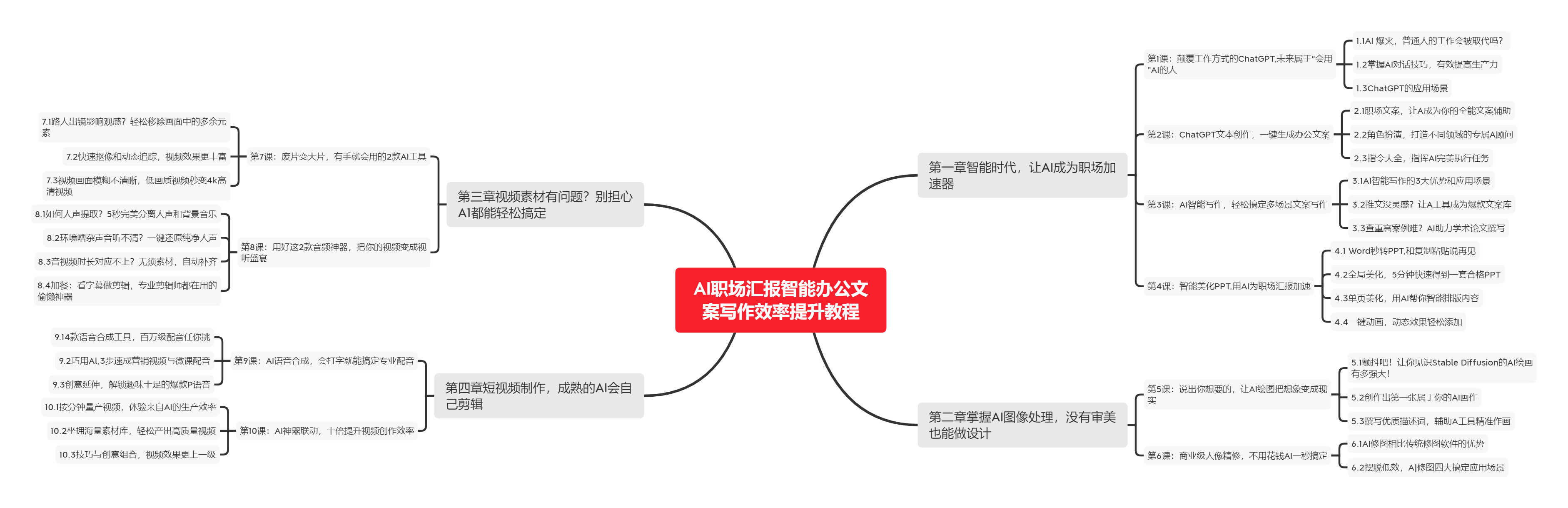

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |