计算机体系结构作业答案
第一二章作业
1.试述Flynn 分类的4 种计算机系统结构有何特点。
参考答案:
Flynn按照指令流和数据流两种不同的组合,把计算机系统的结构分为以下4 类:
(1)单指令流单数据流SISD(Single Instruction Stream Single Datastream),SISD 是传统的顺序处理计算机;
(2)单指令流多数据流SIMD(Single Instruction Stream Multiple Datastream),SIMD 以阵列处理机为代表;
(3)多指令流单数据流MISD(Multiple Instruction Stream Single Datastream),MISD 实际代表何种计算机,存在着不同的看法;
(4)多指令流多数据流MIMD(Multiple Instruction Stream Multiple Datastream),多处理机与多计算机系统属于MIMD 结构。
单指令流单数据流(SingleInstructionStreamSingleDataStream,SISD)
SISD其实就是传统的顺序执行的单处理器计算机,其指令部件每次只对一条指令进行译码,并只对一个操作部件分配数据。
单指令流多数据流(SingleInstructionStreamMultipleDataStream,SIMD)
SIMD以并行处理机为代表,结构如图,并行处理机包括多个重复的处理单元PU1~PUn,由单一指令部件控制,按照同一指令流的要求为它们分配各自所需的不同的数据。
多指令流单数据流(MultipleInstructionStreamSingleDataStream,MISD)
MISD的结构,它具有n个处理单元,按n条不同指令的要求对同一数据流及其中间结果进行不同的处理。一个处理单元的输出又作为另一个处理单元的输入。
多指令流多数据流(MultipleInstructionStreamMultipleDataStream,MIMD)
MIMD的结构,它是指能实现作业、任务、指令等各级全面并行的多机系统,多处理机就属于MIMD。
2.假设高速缓存Cache 工作速度为主存的5 倍,且Cache 被访问命中的概率为90%,
则采用Cache 后,能使整个存储系统获得多高的加速比?
参考答案:
加速比 = 1/(1-0.9 +0.9/5) = 25/7
3.某工作站采用时钟频率为15 MHz、处理速率为10 MIPS 的处理机来执行一个已知混合程序。假定每次存储器存取为1 个时钟周期延迟,试问:
(1)此计算机的有效CPI 是多少?CPI时间是多少?
(2)假定将处理机的时钟提高到30 MHz,但存储器子系统速率不变。这样,每次存储器
存取需要两个时钟周期。如果30%指令每条只需要一次存储存取,而另外5%每条需要两次存储存取,并假定已知混合程序的指令数不变,并与原工作站兼容,试求改进后计算机的CPI 是多少?CPI时间是多少?
参考答案:
(1)CPI = 一个程序的CPU 时钟周期数/ IC = 时钟频率/MIPS =15/10 = 1.5
CPI时间是1.5*(1/15)us = 0.1us
(2)由第一问可得原始CPI 为1.5 ,改进后一次访存操作需要2 个时钟周期,比改进前每次访存多了1 个时钟周期;
由于有30% 的指令由于需要1 次访存,所以它们的时钟周期数需要加1;
有5% 的指令由于需要2 次访存,所以它们的时钟周期数需要加2.
所以可得 CPI new = CPI original + 30%*1 + 5%*2 = 1.5 + 0.3 + 0.1 = 1.9
改进后CPI new的时间:1.9 *(1/30)us = 0.0627us
4.处理机的时钟30 MHz

(1)计算在单处理机上用上述跟踪数据运行程序的平均CPI。
(2)根据(1)所得CPI,计算相应的MIPS 速率。
参考答案:
- 平均CPI = 1*60% + 2*18% + 4*12 + 8*10% = 2.24
- MIPS = 时钟周期/CPI = 30M/2.24 = 13.4
5. 区分指令集系统结构分类(ISA分类)与通用寄存器结构分类。
参考答案:
答:ISA分类是根据CPU内部数据存储类型进行分类:堆栈型、累加器型、通用寄存器型(R-M,R-R)。
通用寄存器是ISA的一种类型,包括:寄存器-存储器型、寄存器-寄存器型。
6. 从ISA分类、指令长度、寻址方式、操作数类型、指令操作类型、指令操作码编码、转移控制类指令这几个方面说明CISC的8086指令系统与RISC 的MIPS指令系统的特点。
参考答案:
8086指令系统特点:属于R-M型ISA,指令长度是变长的,寻址方式有寻址字段(立即数、寄存器、直接寻址、寄存器间接寻址、基址寻址、变址寻址、基址变址寻址、串操作寻址、相对寻址、I/O寻址),操作数类型(定点数据类型有字节、16位字、双字、4字,字符串),指令操作类型(传送类、算术运算类、逻辑类、串操作类、程序转移类、处理器控制类),指令操作码编码(1-2个字节编码),转移控制流指令(无条件转移指令直接或间接寻址、条件转移指令和循环控制指令相对寻址、子程序调用与返回指令)。
- MIPS指令系统特点:属于R-R型ISA,指令长度是固定的,寻址方式无专门寻址字段(立即数、位移量寻址、相对寻址),操作数类型(定点数据类型有8位字节、16位半字、32位字和64位双字。浮点数有32位单精度和64位双精度浮点数),指令操作类型(LOAD/STORE类、ALU操作类、分支与跳转类、浮点运算类),指令操作码编码(6位操作码加辅助操作码),转移控制流指令(跳转指令拼接地址、分支指令相对寻址、跳转与链接、寄存器跳转与链接、等于零时转换)。
第三章作业
作业一
1.解释第三章PPT中图3-2.28中各控制信号的作用。
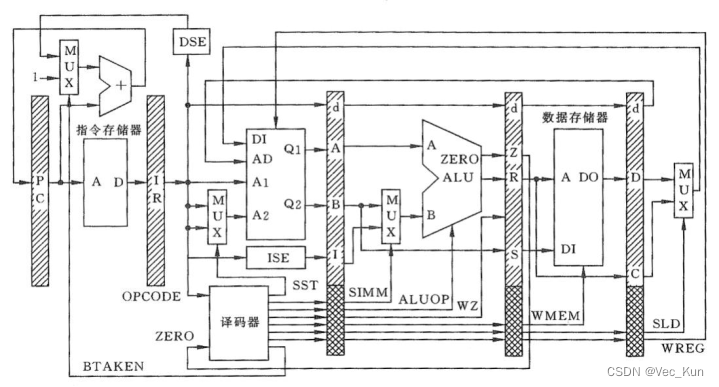
参考答案:
流水线各级控制信号的定义
| 流水线级 | 控制信号 | 注释 |
| IF级 | BTAKEN | 转移发生 |
| ID级 | SST | 选择store(rd) |
| EXE级 | SIMM | 选择立即数 |
| ALUOP | ALU操作码 | |
| WZ | 写Z标志 | |
| MEM级 | WMEM | 写存储器 |
| WB级 | SLD | 选择load |
| WREG | 写寄存器堆 |
2. 在第四个时钟周期结束时各个流水线寄存器和控制信号的值: 第一条指令进入MEM级,第二条指令进入EXE级,第三条指令进入ID级,第四条指令进入IF级。
参考答案:
第四个时钟周期结束,即刚进入第五个周期时,PC输出4,指向第五条指令;IR输出第四条指令add r7,r5,r6;A和B分别输出寄存器r5和r6的内容(第三条指令);R输出存储器地址(第二条指令);C输出第一条指令的加法结果。
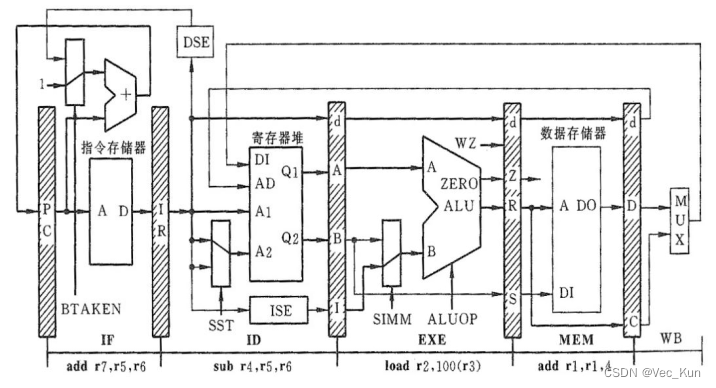
寄存器:
IF/ID: IR = add r7,r5,r6
ID/EXE: d=4, A=(r5), B=(r6), I=(null)
EXE/MEM: d=2, Z=0(不写Z标志), R=(r3)+100, S=(null)
MEM/WB: d =1, D=(null), C=4+(r1)
控制信号:
BTAKEN=0, SST=0, SIMM=1, ALUOP=(add), WZ=0, WMEM=0, SLD=0, WREG=0
3. 在第六个时钟周期结束时各个流水线寄存器和控制信号的值:
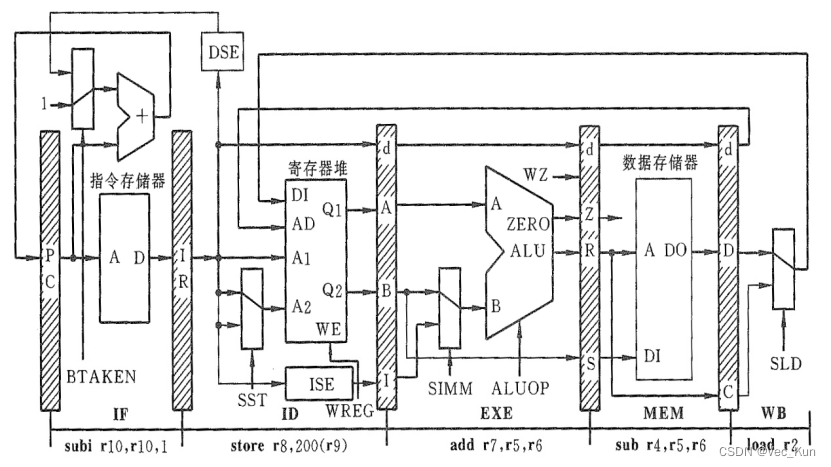
参考答案:
第六个时钟周期结束,即刚进入第七个周期时:PC输出6,指向第七条指令;IR输出第六条指令subi r10,r10,1;A和B分别输出寄存器r9和r8的内容,I送出32位的200(第五条指令);R输出加法结果(第四条指令);C输出第三条指令减法操作的结果。
寄存器:
IF/ID: IR = subi r10, r10, 1
ID/EXE: d=(null), A=(r9), B=(r8), I=200
EXE/MEM: d=7, Z=1(写Z标志), R=(r5)+(r6), S=(null)
MEM/WB: d =4, D=(null), C=(r5)-(r6)
控制信号:
BTAKEN=0, SST=1, SIMM=0, ALUOP=(add), WZ=1, WMEM=0, SLD=1, WREG=1
4.第五个时钟周期结束,即刚进入第六个周期时:PC输出5指向第六条指令;IR输出第五条指令store r8,200(r9);A和B分别输出r5和r6的内容(第四条指令);R输出减法结果(第三条指令);D输出第二条指令从存储器取来的数据。
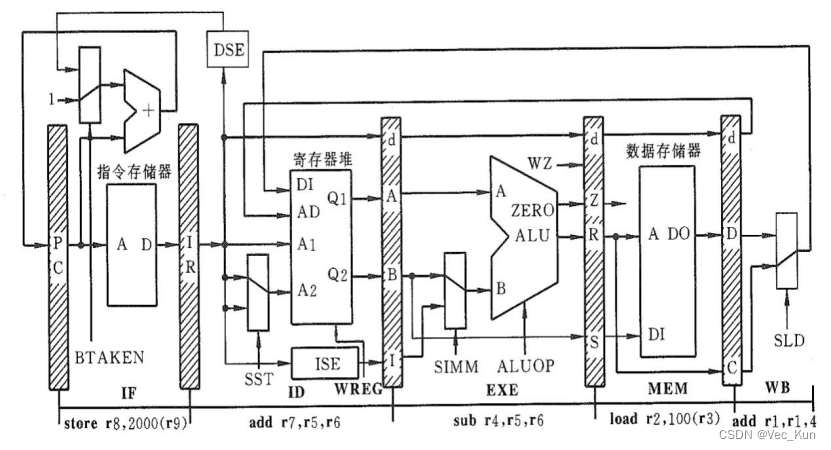
1)当第5个时钟周期结束时(即刚进入第6个时钟周期),给出以下流水线寄存器的内容
(1)IF级的PC内容 = ,IR的内容是 ;
(2)ID级的A寄存器内容来自寄存器 ,B寄存器内容来自寄存器 ,d寄存器内容= ;
(3)EXE与MEM级之间的R寄存器内容是 , S 寄存器内容= ;
(4)MEM与WB级之间的D寄存器内容是 , d 寄存器内容= ;
2)WB级上指令“add r1, r1, 4”这一级完成的操作和所需要的控制信号。
3)写出指令“and r1, r2, r3”, “load r1, 10( r2 )”,“store r3, 20( r4 )”, 所需要的控制信号。
参考答案:
(1) 5 store r8, 2000(r9)
(2)r5 r6 7
(3)(r5)-(r6) null
(4)(r3+100) 2
2)
SLD=0, WREG=1
3)
| SST | SIMM | ALUOP | WZ | WMEM | SLD | WREG | BTAKEN | |
| Add r1, r2, r3 | 0 | 0 | 10 | 1 | 0 | 0 | 1 | 0 |
| Load r1, 10(r2) | 0 | 1 | 10 | 0 | 0 | 1 | 1 | 0 |
| Store r3, 20(r4) | 1 | 1 | 10 | 0 | 1 | x | 0 | 0 |
| Branch lop | 0 | 0 | xx | 0 | 0 | 0 | 0 | 1 |
作业二
1.各流水级存放控制信号的流水线寄存器有何异同?
参考答案:
以PPT图1.28为例,
- ID级存控制信号的寄存器存放的是含EXE、MEM、WB级所需的控制信号;
- EXE级存控制信号的寄存器存放的是含MEM、WB级所需的控制信号;
- MEM级存控制信号的寄存器存放的是含WB级所需的控制信号。
相同之处:都存有WB级控制信号。
不同之处:前面级的流水线控制信号寄存器包含后面级的控制信号,而后面级的则无前级信号。
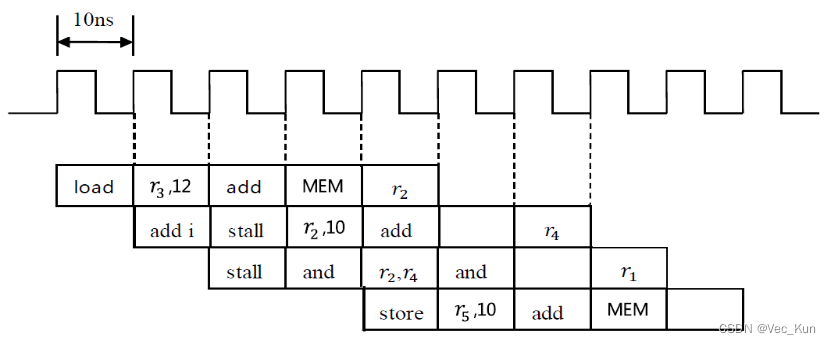
2.设流水线模型机采用load前推和数据前推,按时钟周期画出以下指令序列的时序图,标示出前推示意。
load r2, 12(r3)
addi r4, r2, 10
and r1, r2, r4
store r1, 10(r5)
参考答案:
假设store也采用前推技术:
3、给出第三章PPT中图3-3.39的BDEPEN控制信号的真值表。
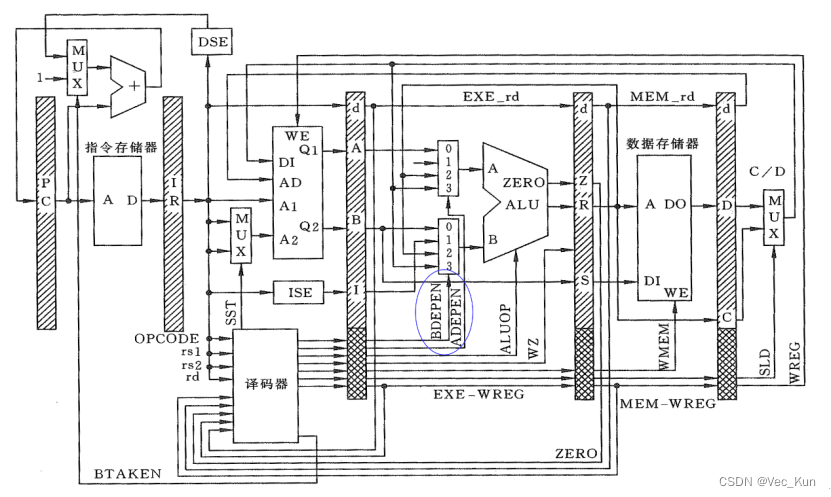
BDEPEN1= (ID_rs2= =EXE_rd)(EXE_WREG= =1)(ID_rs2IsReg) + ……
参考答案:
| 输入 | 输出 | ||||||
| ID_rs2 IsReg | EXE_WREG | ID_rs2 ==EXE_rd | MEM_WREG | ID-rs2 = =MEM_rd | BDEPEN1 | BDEPEN0 | 输入选择 |
| 0 | X | X | X | X | 0 | 1 | 立即数 |
| 1 | 0 | X | 0 | X | 0 | 0 | B |
| 1 | 1 | 0 | 0 | X | 0 | 0 | B |
| 1 | 1 | 1 | 0 | X | 1 | 0 | MEM_R |
| 1 | 0 | X | 1 | 0 | 0 | 0 | B |
| 1 | 0 | X | 1 | 1 | 1 | 1 | WB_C |
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | B |
| 1 | 1 | 1 | 1 | 0 | 1 | 0 | MEM_R |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | WB_C |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | MEM_R |
第五章作业:
1.某个计算机系统有128字节的高速缓存。它采用每块有8个字节的4路组相联映射。物理地址大小是32位,最小可寻址单位是1个字节。(1)画图说明高速缓存的组织并指明物理地址与高速缓存地址的关系;(2)可以将地址000010AFH分配给高速缓存的哪一组?(3)假如地址000010AFH和FFFF7AxyH可以同时分配给同一个高速缓存组,地址中的x与y的值为多少?
参考答案:
(1)
(2)考虑低八位:
(AF)16 = (10101111)2,所以应为01
(3)同理可得,x = (***0)2,y=(1***)2
2.假设对指令Cache的访问占全部访问的75%,而对数据Cache的访问占全部访问的25%。Cache的命中时间为1个时钟周期,失效开销为50个时钟周期,在混合Cache中一次LOAD或STORE操作访问Cache的命中时间都要增加一个时钟周期,32KB的指令Cache的失效率为0.39%,32 KB的数据Cache的失效率为4.82%,64 KB的混合Cache的失效率为1.35%。又假设采用写直达策略,且有一个写缓冲器,并且忽略写缓冲器引起的等待。试问指令Cache和数据Cache容量均为32 KB的分离Cache和容量为64 KB的混合Cache相比,哪种Cache的失效率更低?两种情况下平均访存时间各是多少?
参考答案:
(1)分离的失效率=75%*0.39%+25%*4.82%=1.5%
混合的失效率=1.35%,混合更低。
(2)分离的平均访存时间=75%*(1+0.39%*50)+25%*(1+4.82%*50)=1.75
混合的平均访存时间=75%*(1+1.35%*50)+25%*(1+1+1.35%*50)=1.925
3.给定以下的假设,试计算直接映象Cache和两路组相联Cache的平均访问时间以及CPU的性能。由计算结果能得出什么结论?
(1)理想Cache情况下的CPI为2.0,时钟周期为2 ns,平均每条指令访存1.2次。
(2)两者Cache容量均为64KB,块大小都是32B。
(3)组相联Cache中的多路选择器使CPU的时钟周期增加了10%。
(4)这两种Cache的失效开销都是80 ns。
(5)命中时间为1个时钟周期。
(6)64 KB直接映象Cache的失效率为1.4%,64 KB两路组相联Cache的失效率为1.0%。
参考答案:

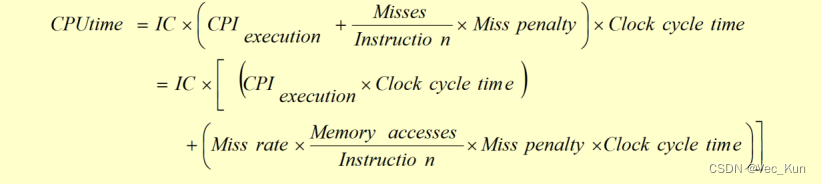
(1)
直接映象的平均访存时间=1*2+1.4%*80=3.12
二路组相连的平均访存时间=1*2+1.0%*80=3
(2)
直接映象的CPU时间= IC*(2.0*2 + 1.2*1.4%*80)=5.34IC
二路组相连的CPU时间 = IC*(2.0*2.2 + 1.2*1.0%*80)=5.36IC
- 虚拟存储器与cache综合分析题
如果Cache采用虚拟索引物理标识,假定页式虚拟地址42位,物理地址34位,每页为8KB,块大小64B,Cache大小同一页大小,TLB全相联,Cache直接映像。
试计算TLB中的标识位数和物理地址位数;以及Cache的索引、块偏移、标识的位数。
答案:Cache索引7位:8kB/64=(23*210)/26 =27
块偏移6位: 每块64B, 26
标识: 34-7-6 = 21位
一页地址位数:13位(因为每页8KB),所以页内偏移位:13位
TLB标识位:42-13=29位(虚拟页号),所以物理页号:34-13=21位
补充:如果Cache采用虚拟索引物理标识,假定页式虚拟地址42位,物理地址34位,每页为4KB,块大小64B,Cache大小同一页大小,TLB全相联,Cache直接映像。
问:计算TLB中的标识位数;以及Cache的索引、块偏移、标识的位数。
答:Cache大小与页大小相同,4KB,每块64B,共64块,则:
Cache索引6位: 4KB/64B=(22*210)/26 =26
块偏移6位: 每块64B, 26
标识: 34-6-6 = 22位
一页地址位数:12位(因为每页4KB),所以页内偏移位:12位
TLB标识位:42-12=30位(虚拟页号),所以物理页号:34-12=22位
另外注意:
如果给一个虚拟地址,根据上述TLB中的位数,可以推出对应的虚拟页号;查表,可以得到物理页号;将物理页号+页内偏移=物理地址;最后对应Cache的索引、块偏移及标识进行分析。