编者按:如今,基础大模型正在诸多应用中发挥着日益重要的作用。大多数大语言模型的训练都是采取自回归的方式进行生成,虽然自回归模型生成的文本质量有所保证,但却导致了高昂的推理成本和长时间的延迟。由于大模型的参数量巨大、推理成本高,因此如何在大规模部署大模型的过程中降低成本、减小延迟是一个关键课题。针对此问题,微软亚洲研究院的研究员们提出了一种使用参考文本无损加速大语言模型推理的方法 LLM Accelerator,在大模型典型的应用场景中可以取得两到三倍的加速。
随着人工智能技术的快速发展,ChatGPT、New Bing、GPT-4 等新产品和新技术陆续发布,基础大模型在诸多应用中将发挥日益重要的作用。目前的大语言模型大多是自回归模型。自回归是指模型在输出时往往采用逐词输出的方式,即在输出每个词时,模型需要将之前输出的词作为输入。而这种自回归模式通常在输出时制约着并行加速器的充分利用。
在许多应用场景中,大模型的输出常常与一些参考文本有很大的相似性,例如在以下三个常见的场景中:
1. 检索增强的生成。New Bing 等检索应用在响应用户输入的内容时,会先返回一些与用户输入相关的信息,然后用语言模型总结检索出的信息,再回答用户输入的内容。在这种场景中,模型的输出往往包含大量检索结果中的文本片段。
2. 使用缓存的生成。大规模部署语言模型的过程中,历史的输入输出会被缓存。在处理新的输入时,检索应用会在缓存中寻找相似的输入。因此,模型的输出往往和缓存中对应的输出有很大的相似性。
3. 多轮对话中的生成。在使用 ChatGPT 等应用时,用户往往会根据模型的输出反复提出修改要求。在这种多轮对话的场景下,模型的多次输出往往只有少量的变化,重复度较高。
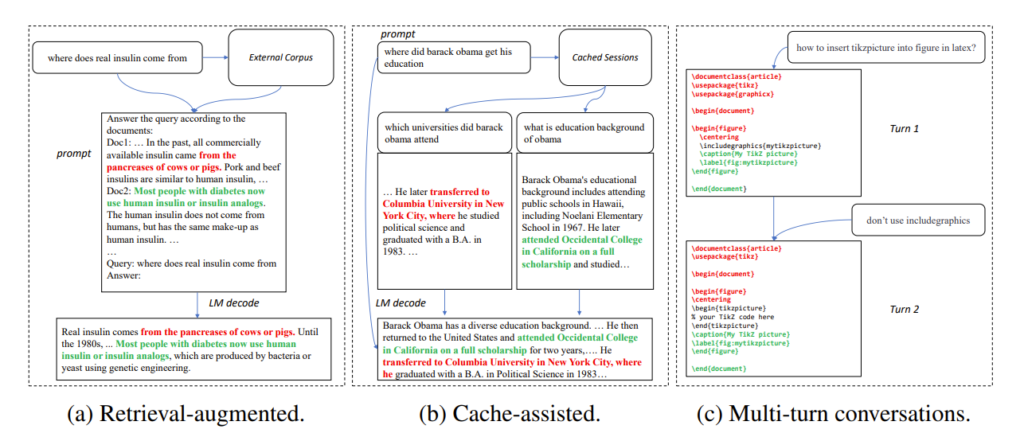
图1:大模型的输出与参考文本存在相似性的常见场景
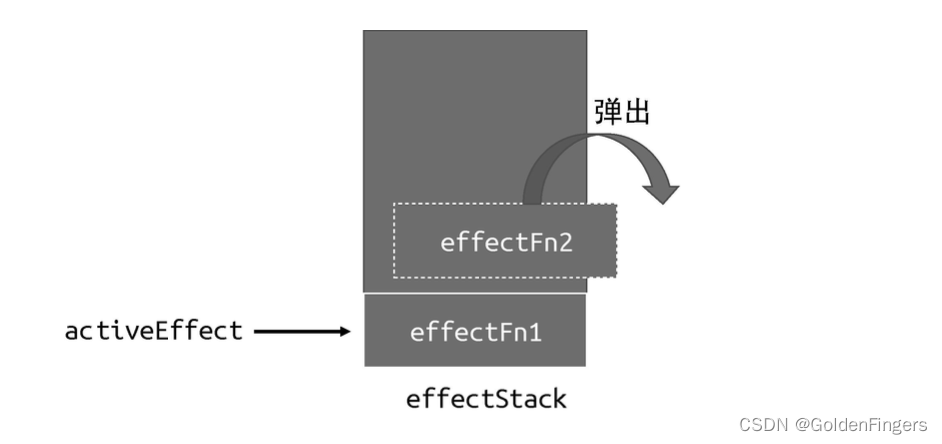
基于以上观察,研究员们以参考文本与模型输出的重复性作为突破自回归瓶颈的着力点,希望可以提高并行加速器利用率,加速大语言模型推理,进而提出了一种利用输出与参考文本的重复性来实现一步输出多个词的方法 LLM Accelerator。

图2:LLM Accelerator 解码算法
具体来说,在每一步解码时,让模型先匹配已有的输出结果与参考文本,如果发现某个参考文本与已有的输出相符,那么模型很可能顺延已有的参考文本继续输出。因此,研究员们将参考文本的后续词也作为输入加入到模型中,从而使得一个解码步骤可以输出多个词。
为了保证输入输出准确,研究员们进一步对比了模型输出的词与从参考文档输入的词。如果两者不一致,那么不正确的输入输出结果将被舍弃。以上方法能够保证解码结果与基准方法完全一致,并可以提高每个解码步骤的输出词数,从而实现大模型推理的无损加速。LLM Accelerator 无需额外辅助模型,简单易用,可以方便地部署到各种应用场景中。

论文链接:https://arxiv.org/pdf/2304.04487.pdf
项目链接:https://github.com/microsoft/LMOps
使用 LLM Accelerator,有两个超参数需要调整。一是触发匹配机制所需的输出与参考文本的匹配词数:匹配词数越长往往越准确,可以更好地保证从参考文本拷贝的词是正确的输出,减少不必要的触发和计算;更短的匹配,解码步骤更少,潜在加速更快。二是每次拷贝词的数量:拷贝词数越多,加速潜力越大,但也可能造成更多不正确的输出被舍弃,浪费计算资源。研究员们通过实验发现,更加激进的策略(匹配单个词触发,一次拷贝15到20个词)往往能够取得更好的加速比。
为了验证 LLM Accelerator 的有效性,研究员们在检索增强和缓存辅助生成方面进行了实验,利用 MS-MARCO 段落检索数据集构造了实验样本。在检索增强实验中,研究员们使用检索模型对每个查询返回10个最相关的文档,然后拼接到查询后作为模型输入,将这10个文档作为参考文本。在缓存辅助生成实验中,每个查询生成四个相似的查询,然后用模型输出对应的查询作为参考文本。
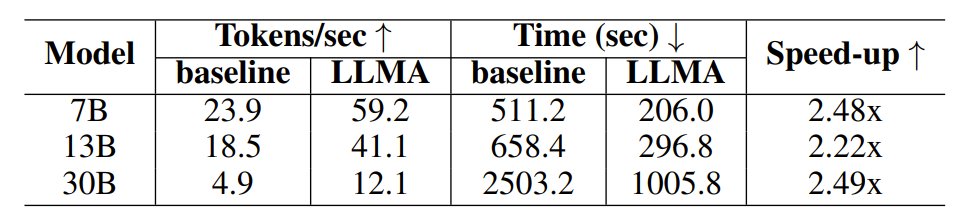
表1:检索增强的生成场景下的时间对比

表2:使用缓存的生成场景下的时间对比
研究员们使用通过 OpenAI 接口得到的 Davinci-003 模型的输出结果作为目标输出,以获得高质量的输出。得到所需输入、输出和参考文本后,研究员们在开源的 LLaMA 语言模型上进行了实验。由于 LLaMA 模型的输出与 Davinci-003 输出不一致,所以研究员们采用了目标导向的解码方法来测试理想输出(Davinci-003 模型结果)结果下的加速比。研究员们利用算法2得到了贪婪解码时生成目标输出所需的解码步骤,并强制 LLaMA 模型按照得到的解码步骤进行解码。

图3:利用算法2得到了贪婪解码时生成目标输出所需的解码步骤
对于参数量为 7B 和 13B 的模型,研究员们在单个 32G NVIDIA V100 GPU 上进行实验;对于参数量为 30B 的模型,在四块同样的 GPU 上进行实验。所有的实验均采用了半精度浮点数,解码均为贪婪解码,且批量大小为1。实验结果表明,LLM Accelerator 在不同模型大小(7B,13B,30B)与不同的应用场景中(检索增强、缓存辅助)都取得了两到三倍的加速比。
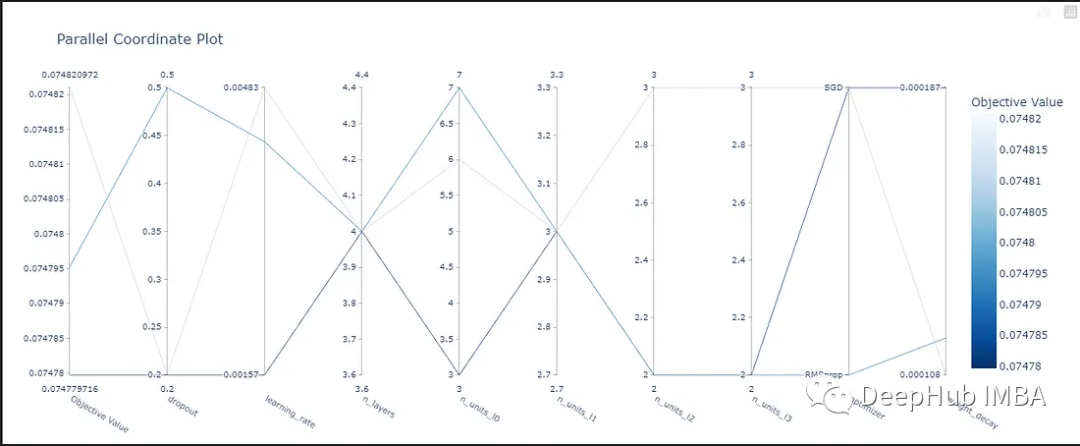
进一步实验分析发现,LLM Accelertator 能显著减少所需的解码步骤,并且加速比与解码步骤的减少比例呈正相关。更少的解码步骤一方面意味着每个解码步骤生成的输出词数更多,可以提高 GPU 计算的计算效率;另一方面,对于需要多卡并行的30B模型,这意味着更少的多卡同步,从而达到更快的速度提升。在消融实验中,在开发集上对 LLM Accelertator 的超参数进行分析的结果显示,匹配单个单词(即触发拷贝机制)时,一次拷贝15到20个单词时的加速比可达到最大 (图4所示)。在图5中我们可以看出,匹配词数为1能更多地触发拷贝机制,并且随着拷贝长度的增加,每个解码步骤接受的输出词增加,解码步骤减少,从而达到更高的加速比。
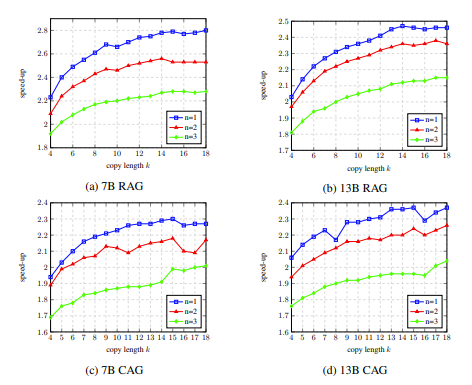
图4:消融实验中,在开发集上对 LLM Accelertator 的超参数的分析结果
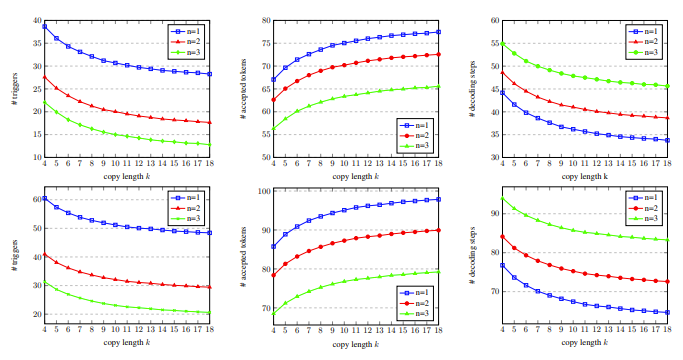
图5:在开发集上,具有不同匹配词数 n 和拷贝词数 k 的解码步骤统计数据
LLM Accelertator 是微软亚洲研究院自然语言计算组在大语言模型加速系列工作的一部分,未来,研究员们将持续对相关问题进行更加深入的探索。