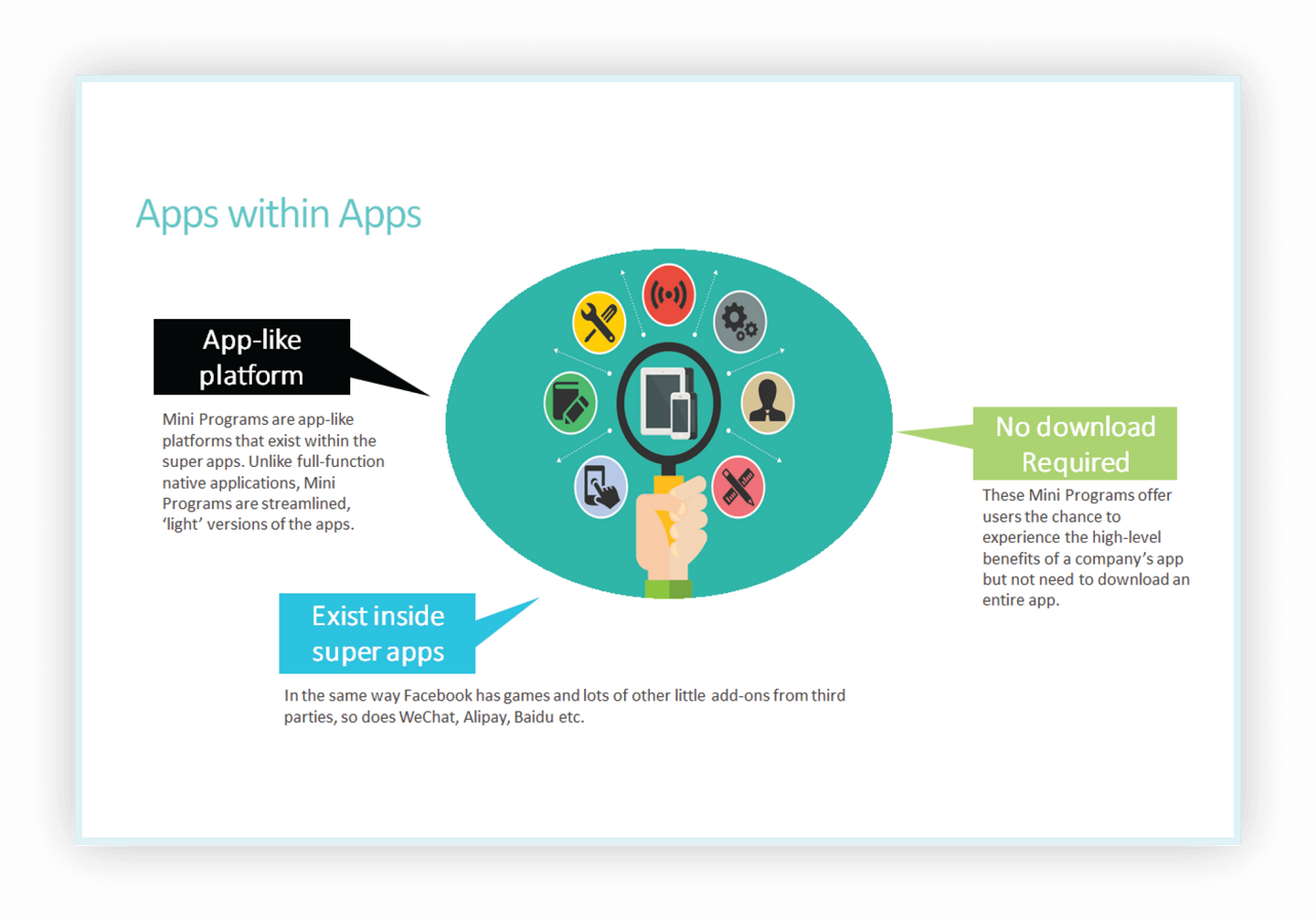
文件结构
config文件
在 config_base_ 文件夹下有 4 个基本组件类型,分别是:数据集(dataset),模型(model),训练策略(schedule)和运行时的默认设置(default runtime)。
命名风格
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
{xxx} 是被要求的文件 [yyy] 是可选的。
{model}: 模型种类,例如 faster_rcnn, mask_rcnn 等。
[model setting]: 特定的模型,例如 htc 中的without_semantic, reppoints 中的 moment 等。
{backbone}: 主干网络种类例如 r50 (ResNet-50), x101 (ResNeXt-101) 等。
{neck}: Neck 模型的种类包括 fpn, pafpn, nasfpn, c4 等。
[norm_setting]: 默认使用 bn (Batch Normalization),其他指定可以有 gn (Group Normalization), syncbn (Synchronized Batch Normalization) 等。 gn-head/gn-neck 表示 GN 仅应用于网络的 Head 或 Neck, gn-all 表示 GN 用于整个模型, 例如主干网络、Neck 和 Head。
[misc]: 模型中各式各样的设置/插件,例如 dconv、 gcb、 attention、albu、 mstrain 等。
[gpu x batch_per_gpu]:GPU 数量和每个 GPU 的样本数,默认使用 8x2。
{schedule}: 训练方案,选项是 1x、 2x、 20e 等。1x 和 2x 分别代表 12 epoch 和 24 epoch,20e 在级联模型中使用,表示 20 epoch。对于 1x/2x,初始学习率在第 8/16 和第 11/22 epoch 衰减 10 倍;对于 20e ,初始学习率在第 16 和第 19 epoch 衰减 10 倍。
{dataset}:数据集,例如 coco、 cityscapes、 voc_0712、 wider_face 等。
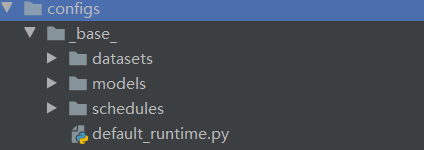
模型示例
config中的其他文件都是按照模型进行命名的,以DETR模型为例,其内包含4种模型配置:

以detr_r50_8xb2-150e_coco.py为例:
基础配置
首先是继承base中的部分文件,这里分别为数据集与基础配置
_base_ = [
'../_base_/datasets/coco_detection.py', '../_base_/default_runtime.py'
]
模型配置
检测模型为DETR,设置的超参数为num_query=100,具体设置可在mmdet/model/detector文件中找到:
type='DETR',
num_queries=100,
其内使用Transformer搭建的layer定义在layer/transformer文件夹中
数据加载配置
其中type为其加载方式
data_preprocessor=dict(
type='DetDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_size_divisor=1),
找到mmdet/model/data_preprocessor,其内data_preprocessor.py有其定义
骨干网络
骨干网络为ResNet,其深度为50,即ResNet50,stage为4,同时给出了加载权重文件
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(3, ),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
具体配置在mmdet/model/backbones中的resnet.py文件中
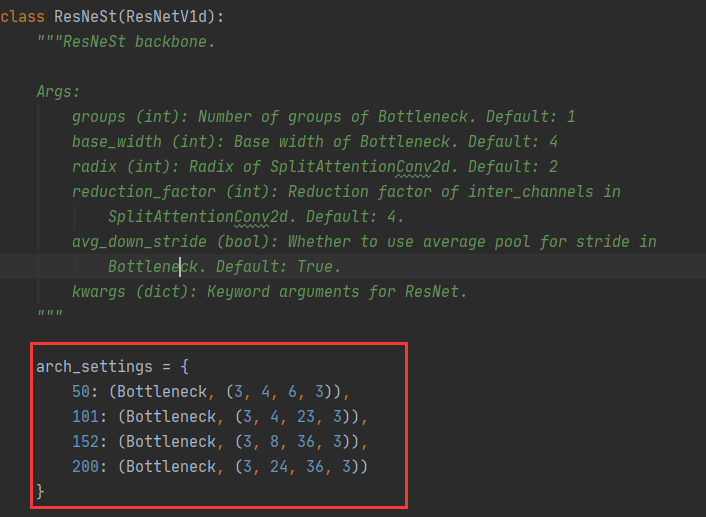
Neck特征融合模块
该模块实际上执行的是通道维度变换操作。
具体配置在mmdet/model/neck中的ChannelMapper.py文件中
neck=dict(
type='ChannelMapper',
in_channels=[2048],
kernel_size=1,
out_channels=256,
act_cfg=None,
norm_cfg=None,
num_outs=1),
其给出了示例,与先前所学习的DETR结构一致
>>> import torch
>>> in_channels = [2, 3, 5, 7]
>>> scales = [340, 170, 84, 43]
>>> inputs = [torch.rand(1, c, s, s)
... for c, s in zip(in_channels, scales)]
>>> self = ChannelMapper(in_channels, 11, 3).eval()
>>> outputs = self.forward(inputs)
>>> for i in range(len(outputs)):
... print(f'outputs[{i}].shape = {outputs[i].shape}')
outputs[0].shape = torch.Size([1, 11, 340, 340])
outputs[1].shape = torch.Size([1, 11, 170, 170])
outputs[2].shape = torch.Size([1, 11, 84, 84])
outputs[3].shape = torch.Size([1, 11, 43, 43])
Encoder配置
DETR由于是使用Transformer框架搭建,故其收录的模型较少
encoder=dict( # DetrTransformerEncoder
num_layers=6,
layer_cfg=dict( # DetrTransformerEncoderLayer
self_attn_cfg=dict( # MultiheadAttention
embed_dims=256,
num_heads=8,
dropout=0.1,
batch_first=True),
ffn_cfg=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
ffn_drop=0.1,
act_cfg=dict(type='ReLU', inplace=True)))),
Decoder配置
没有指定type就去detr文件中去找其实现方式,这说明这个模块比较偏,就没有划分一个类别。
decoder=dict( # DetrTransformerDecoder
num_layers=6,
layer_cfg=dict( # DetrTransformerDecoderLayer
self_attn_cfg=dict( # MultiheadAttention
embed_dims=256,
num_heads=8,
dropout=0.1,
batch_first=True),
cross_attn_cfg=dict( # MultiheadAttention
embed_dims=256,
num_heads=8,
dropout=0.1,
batch_first=True),
ffn_cfg=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
ffn_drop=0.1,
act_cfg=dict(type='ReLU', inplace=True))),
return_intermediate=True),
位置编码模块
这种没有指定type的就去detector中找其具体定义:
self.positional_encoding = SinePositionalEncoding(
**self.positional_encoding)
positional_encoding=dict(num_feats=128, normalize=True),
检测头配置
检测头输出为80个类别,维度为256。
bbox_head=dict(
type='DETRHead',
num_classes=80,
embed_dims=256,
loss_cls=dict(
type='CrossEntropyLoss',
bg_cls_weight=0.1,
use_sigmoid=False,
loss_weight=1.0,
class_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=5.0),
loss_iou=dict(type='GIoULoss', loss_weight=2.0)),
训练配置
这里定义了使用匈牙利匹配来进行标签与预测框的匹配过程。
train_cfg=dict(
assigner=dict(
type='HungarianAssigner',
match_costs=[
dict(type='ClassificationCost', weight=1.),
dict(type='BBoxL1Cost', weight=5.0, box_format='xywh'),
dict(type='IoUCost', iou_mode='giou', weight=2.0)
])),
test_cfg=dict(max_per_img=100))
优化器配置
# optimizer
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(type='AdamW', lr=0.0001, weight_decay=0.0001),
clip_grad=dict(max_norm=0.1, norm_type=2),
paramwise_cfg=dict(
custom_keys={'backbone': dict(lr_mult=0.1, decay_mult=1.0)}))
其他配置
# learning policy
max_epochs = 150
train_cfg = dict(
type='EpochBasedTrainLoop', max_epochs=max_epochs, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
param_scheduler = [
dict(
type='MultiStepLR',
begin=0,
end=max_epochs,
by_epoch=True,
milestones=[100],
gamma=0.1)
]
# NOTE: `auto_scale_lr` is for automatically scaling LR,
# USER SHOULD NOT CHANGE ITS VALUES.
# base_batch_size = (8 GPUs) x (2 samples per GPU)
auto_scale_lr = dict(base_batch_size=16)
配置文件基本结构
model = dict(
type=...,
...
train_cfg=dict(...),
test_cfg=dict(...),
)
示例
以Mask R-CNN 配置文件为例
model = dict(
type='MaskRCNN', # 检测器(detector)名称
backbone=dict( # 主干网络的配置文件
type='ResNet', # 主干网络的类别,可用选项请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/backbones/resnet.py#L308
depth=50, # 主干网络的深度,对于 ResNet 和 ResNext 通常设置为 50 或 101。
num_stages=4, # 主干网络状态(stages)的数目,这些状态产生的特征图作为后续的 head 的输入。
out_indices=(0, 1, 2, 3), # 每个状态产生的特征图输出的索引。
frozen_stages=1, # 第一个状态的权重被冻结
norm_cfg=dict( # 归一化层(norm layer)的配置项。
type='BN', # 归一化层的类别,通常是 BN 或 GN。
requires_grad=True), # 是否训练归一化里的 gamma 和 beta。
norm_eval=True, # 是否冻结 BN 里的统计项。
style='pytorch', # 主干网络的风格,'pytorch' 意思是步长为2的层为 3x3 卷积, 'caffe' 意思是步长为2的层为 1x1 卷积。
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')), # 加载通过 ImageNet 与训练的模型
neck=dict(
type='FPN', # 检测器的 neck 是 FPN,我们同样支持 'NASFPN', 'PAFPN' 等,更多细节可以参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/necks/fpn.py#L10。
in_channels=[256, 512, 1024, 2048], # 输入通道数,这与主干网络的输出通道一致
out_channels=256, # 金字塔特征图每一层的输出通道
num_outs=5), # 输出的范围(scales)
rpn_head=dict(
type='RPNHead', # RPN_head 的类型是 'RPNHead', 我们也支持 'GARPNHead' 等,更多细节可以参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/dense_heads/rpn_head.py#L12。
in_channels=256, # 每个输入特征图的输入通道,这与 neck 的输出通道一致。
feat_channels=256, # head 卷积层的特征通道。
anchor_generator=dict( # 锚点(Anchor)生成器的配置。
type='AnchorGenerator', # 大多是方法使用 AnchorGenerator 作为锚点生成器, SSD 检测器使用 `SSDAnchorGenerator`。更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/anchor/anchor_generator.py#L10。
scales=[8], # 锚点的基本比例,特征图某一位置的锚点面积为 scale * base_sizes
ratios=[0.5, 1.0, 2.0], # 高度和宽度之间的比率。
strides=[4, 8, 16, 32, 64]), # 锚生成器的步幅。这与 FPN 特征步幅一致。 如果未设置 base_sizes,则当前步幅值将被视为 base_sizes。
bbox_coder=dict( # 在训练和测试期间对框进行编码和解码。
type='DeltaXYWHBBoxCoder', # 框编码器的类别,'DeltaXYWHBBoxCoder' 是最常用的,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/bbox/coder/delta_xywh_bbox_coder.py#L9。
target_means=[0.0, 0.0, 0.0, 0.0], # 用于编码和解码框的目标均值
target_stds=[1.0, 1.0, 1.0, 1.0]), # 用于编码和解码框的标准方差
loss_cls=dict( # 分类分支的损失函数配置
type='CrossEntropyLoss', # 分类分支的损失类型,我们也支持 FocalLoss 等。
use_sigmoid=True, # RPN通常进行二分类,所以通常使用sigmoid函数。
los_weight=1.0), # 分类分支的损失权重。
loss_bbox=dict( # 回归分支的损失函数配置。
type='L1Loss', # 损失类型,我们还支持许多 IoU Losses 和 Smooth L1-loss 等,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/losses/smooth_l1_loss.py#L56。
loss_weight=1.0)), # 回归分支的损失权重。
roi_head=dict( # RoIHead 封装了两步(two-stage)/级联(cascade)检测器的第二步。
type='StandardRoIHead', # RoI head 的类型,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/roi_heads/standard_roi_head.py#L10。
bbox_roi_extractor=dict( # 用于 bbox 回归的 RoI 特征提取器。
type='SingleRoIExtractor', # RoI 特征提取器的类型,大多数方法使用 SingleRoIExtractor,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/roi_heads/roi_extractors/single_level.py#L10。
roi_layer=dict( # RoI 层的配置
type='RoIAlign', # RoI 层的类别, 也支持 DeformRoIPoolingPack 和 ModulatedDeformRoIPoolingPack,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/ops/roi_align/roi_align.py#L79。
output_size=7, # 特征图的输出大小。
sampling_ratio=0), # 提取 RoI 特征时的采样率。0 表示自适应比率。
out_channels=256, # 提取特征的输出通道。
featmap_strides=[4, 8, 16, 32]), # 多尺度特征图的步幅,应该与主干的架构保持一致。
bbox_head=dict( # RoIHead 中 box head 的配置.
type='Shared2FCBBoxHead', # bbox head 的类别,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/roi_heads/bbox_heads/convfc_bbox_head.py#L177。
in_channels=256, # bbox head 的输入通道。 这与 roi_extractor 中的 out_channels 一致。
fc_out_channels=1024, # FC 层的输出特征通道。
roi_feat_size=7, # 候选区域(Region of Interest)特征的大小。
num_classes=80, # 分类的类别数量。
bbox_coder=dict( # 第二阶段使用的框编码器。
type='DeltaXYWHBBoxCoder', # 框编码器的类别,大多数情况使用 'DeltaXYWHBBoxCoder'。
target_means=[0.0, 0.0, 0.0, 0.0], # 用于编码和解码框的均值
target_stds=[0.1, 0.1, 0.2, 0.2]), # 编码和解码的标准方差。因为框更准确,所以值更小,常规设置时 [0.1, 0.1, 0.2, 0.2]。
reg_class_agnostic=False, # 回归是否与类别无关。
loss_cls=dict( # 分类分支的损失函数配置
type='CrossEntropyLoss', # 分类分支的损失类型,我们也支持 FocalLoss 等。
use_sigmoid=False, # 是否使用 sigmoid。
loss_weight=1.0), # 分类分支的损失权重。
loss_bbox=dict( # 回归分支的损失函数配置。
type='L1Loss', # 损失类型,我们还支持许多 IoU Losses 和 Smooth L1-loss 等。
loss_weight=1.0)), # 回归分支的损失权重。
mask_roi_extractor=dict( # 用于 mask 生成的 RoI 特征提取器。
type='SingleRoIExtractor', # RoI 特征提取器的类型,大多数方法使用 SingleRoIExtractor。
roi_layer=dict( # 提取实例分割特征的 RoI 层配置
type='RoIAlign', # RoI 层的类型,也支持 DeformRoIPoolingPack 和 ModulatedDeformRoIPoolingPack。
output_size=14, # 特征图的输出大小。
sampling_ratio=0), # 提取 RoI 特征时的采样率。
out_channels=256, # 提取特征的输出通道。
featmap_strides=[4, 8, 16, 32]), # 多尺度特征图的步幅。
mask_head=dict( # mask 预测 head 模型
type='FCNMaskHead', # mask head 的类型,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/roi_heads/mask_heads/fcn_mask_head.py#L21。
num_convs=4, # mask head 中的卷积层数
in_channels=256, # 输入通道,应与 mask roi extractor 的输出通道一致。
conv_out_channels=256, # 卷积层的输出通道。
num_classes=80, # 要分割的类别数。
loss_mask=dict( # mask 分支的损失函数配置。
type='CrossEntropyLoss', # 用于分割的损失类型。
use_mask=True, # 是否只在正确的类中训练 mask。
loss_weight=1.0)))) # mask 分支的损失权重.
train_cfg = dict( # rpn 和 rcnn 训练超参数的配置
rpn=dict( # rpn 的训练配置
assigner=dict( # 分配器(assigner)的配置
type='MaxIoUAssigner', # 分配器的类型,MaxIoUAssigner 用于许多常见的检测器,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/bbox/assigners/max_iou_assigner.py#L10。
pos_iou_thr=0.7, # IoU >= 0.7(阈值) 被视为正样本。
neg_iou_thr=0.3, # IoU < 0.3(阈值) 被视为负样本。
min_pos_iou=0.3, # 将框作为正样本的最小 IoU 阈值。
match_low_quality=True, # 是否匹配低质量的框(更多细节见 API 文档).
ignore_iof_thr=-1), # 忽略 bbox 的 IoF 阈值。
sampler=dict( # 正/负采样器(sampler)的配置
type='RandomSampler', # 采样器类型,还支持 PseudoSampler 和其他采样器,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/bbox/samplers/random_sampler.py#L8。
num=256, # 样本数量。
pos_fraction=0.5, # 正样本占总样本的比例。
neg_pos_ub=-1, # 基于正样本数量的负样本上限。
add_gt_as_proposals=False), # 采样后是否添加 GT 作为 proposal。
allowed_border=-1, # 填充有效锚点后允许的边框。
pos_weight=-1, # 训练期间正样本的权重。
debug=False), # 是否设置调试(debug)模式
rpn_proposal=dict( # 在训练期间生成 proposals 的配置
nms_across_levels=False, # 是否对跨层的 box 做 NMS。仅适用于 `GARPNHead` ,naive rpn 不支持 nms cross levels。
nms_pre=2000, # NMS 前的 box 数
nms_post=1000, # NMS 要保留的 box 的数量,只在 GARPNHHead 中起作用。
max_per_img=1000, # NMS 后要保留的 box 数量。
nms=dict( # NMS 的配置
type='nms', # NMS 的类别
iou_threshold=0.7 # NMS 的阈值
),
min_bbox_size=0), # 允许的最小 box 尺寸
rcnn=dict( # roi head 的配置。
assigner=dict( # 第二阶段分配器的配置,这与 rpn 中的不同
type='MaxIoUAssigner', # 分配器的类型,MaxIoUAssigner 目前用于所有 roi_heads。更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/bbox/assigners/max_iou_assigner.py#L10。
pos_iou_thr=0.5, # IoU >= 0.5(阈值)被认为是正样本。
neg_iou_thr=0.5, # IoU < 0.5(阈值)被认为是负样本。
min_pos_iou=0.5, # 将 box 作为正样本的最小 IoU 阈值
match_low_quality=False, # 是否匹配低质量下的 box(有关更多详细信息,请参阅 API 文档)。
ignore_iof_thr=-1), # 忽略 bbox 的 IoF 阈值
sampler=dict(
type='RandomSampler', #采样器的类型,还支持 PseudoSampler 和其他采样器,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/bbox/samplers/random_sampler.py#L8。
num=512, # 样本数量
pos_fraction=0.25, # 正样本占总样本的比例。.
neg_pos_ub=-1, # 基于正样本数量的负样本上限。.
add_gt_as_proposals=True
), # 采样后是否添加 GT 作为 proposal。
mask_size=28, # mask 的大小
pos_weight=-1, # 训练期间正样本的权重。
debug=False)) # 是否设置调试模式。
test_cfg = dict( # 用于测试 rnn 和 rnn 超参数的配置
rpn=dict( # 测试阶段生成 proposals 的配置
nms_across_levels=False, # 是否对跨层的 box 做 NMS。仅适用于`GARPNHead`,naive rpn 不支持做 NMS cross levels。
nms_pre=1000, # NMS 前的 box 数
nms_post=1000, # NMS 要保留的 box 的数量,只在`GARPNHHead`中起作用。
max_per_img=1000, # NMS 后要保留的 box 数量
nms=dict( # NMS 的配置
type='nms', # NMS 的类型
iou_threshold=0.7 # NMS 阈值
),
min_bbox_size=0), # box 允许的最小尺寸
rcnn=dict( # roi heads 的配置
score_thr=0.05, # bbox 的分数阈值
nms=dict( # 第二步的 NMS 配置
type='nms', # NMS 的类型
iou_thr=0.5), # NMS 的阈值
max_per_img=100, # 每张图像的最大检测次数
mask_thr_binary=0.5)) # mask 预处的阈值
dataset_type = 'CocoDataset' # 数据集类型,这将被用来定义数据集。
data_root = 'data/coco/' # 数据的根路径。
img_norm_cfg = dict( #图像归一化配置,用来归一化输入的图像。
mean=[123.675, 116.28, 103.53], # 预训练里用于预训练主干网络模型的平均值。
std=[58.395, 57.12, 57.375], # 预训练里用于预训练主干网络模型的标准差。
to_rgb=True
) # 预训练里用于预训练主干网络的图像的通道顺序。
train_pipeline = [ # 训练流程
dict(type='LoadImageFromFile'), # 第 1 个流程,从文件路径里加载图像。
dict(
type='LoadAnnotations', # 第 2 个流程,对于当前图像,加载它的注释信息。
with_bbox=True, # 是否使用标注框(bounding box), 目标检测需要设置为 True。
with_mask=True, # 是否使用 instance mask,实例分割需要设置为 True。
poly2mask=False), # 是否将 polygon mask 转化为 instance mask, 设置为 False 以加速和节省内存。
dict(
type='Resize', # 变化图像和其注释大小的数据增广的流程。
img_scale=(1333, 800), # 图像的最大规模。
keep_ratio=True
), # 是否保持图像的长宽比。
dict(
type='RandomFlip', # 翻转图像和其注释大小的数据增广的流程。
flip_ratio=0.5), # 翻转图像的概率。
dict(
type='Normalize', # 归一化当前图像的数据增广的流程。
mean=[123.675, 116.28, 103.53], # 这些键与 img_norm_cfg 一致,因为 img_norm_cfg 被
std=[58.395, 57.12, 57.375], # 用作参数。
to_rgb=True),
dict(
type='Pad', # 填充当前图像到指定大小的数据增广的流程。
size_divisor=32), # 填充图像可以被当前值整除。
dict(type='DefaultFormatBundle'), # 流程里收集数据的默认格式捆。
dict(
type='Collect', # 决定数据中哪些键应该传递给检测器的流程
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]
test_pipeline = [
dict(type='LoadImageFromFile'), # 第 1 个流程,从文件路径里加载图像。
dict(
type='MultiScaleFlipAug', # 封装测试时数据增广(test time augmentations)。
img_scale=(1333, 800), # 决定测试时可改变图像的最大规模。用于改变图像大小的流程。
flip=False, # 测试时是否翻转图像。
transforms=[
dict(type='Resize', # 使用改变图像大小的数据增广。
keep_ratio=True), # 是否保持宽和高的比例,这里的图像比例设置将覆盖上面的图像规模大小的设置。
dict(type='RandomFlip'), # 考虑到 RandomFlip 已经被添加到流程里,当 flip=False 时它将不被使用。
dict(
type='Normalize', # 归一化配置项,值来自 img_norm_cfg。
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(
type='Pad', # 将配置传递给可被 32 整除的图像。
size_divisor=32),
dict(
type='ImageToTensor', # 将图像转为张量
keys=['img']),
dict(
type='Collect', # 收集测试时必须的键的收集流程。
keys=['img'])
])
]
data = dict(
samples_per_gpu=2, # 单个 GPU 的 Batch size
workers_per_gpu=2, # 单个 GPU 分配的数据加载线程数
train=dict( # 训练数据集配置
type='CocoDataset', # 数据集的类别, 更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/datasets/coco.py#L19。
ann_file='data/coco/annotations/instances_train2017.json', # 注释文件路径
img_prefix='data/coco/train2017/', # 图片路径前缀
pipeline=[ # 流程, 这是由之前创建的 train_pipeline 传递的。
dict(type='LoadImageFromFile'),
dict(
type='LoadAnnotations',
with_bbox=True,
with_mask=True,
poly2mask=False),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]),
val=dict( # 验证数据集的配置
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[ # 由之前创建的 test_pipeline 传递的流程。
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict( # 测试数据集配置,修改测试开发/测试(test-dev/test)提交的 ann_file
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[ # 由之前创建的 test_pipeline 传递的流程。
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
],
samples_per_gpu=2 # 单个 GPU 测试时的 Batch size
))
evaluation = dict( # evaluation hook 的配置,更多细节请参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/evaluation/eval_hooks.py#L7。
interval=1, # 验证的间隔。
metric=['bbox', 'segm']) # 验证期间使用的指标。
optimizer = dict( # 用于构建优化器的配置文件。支持 PyTorch 中的所有优化器,同时它们的参数与 PyTorch 里的优化器参数一致。
type='SGD', # 优化器种类,更多细节可参考 https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/optimizer/default_constructor.py#L13。
lr=0.02, # 优化器的学习率,参数的使用细节请参照对应的 PyTorch 文档。
momentum=0.9, # 动量(Momentum)
weight_decay=0.0001) # SGD 的衰减权重(weight decay)。
optimizer_config = dict( # optimizer hook 的配置文件,执行细节请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8。
grad_clip=None) # 大多数方法不使用梯度限制(grad_clip)。
lr_config = dict( # 学习率调整配置,用于注册 LrUpdater hook。
policy='step', # 调度流程(scheduler)的策略,也支持 CosineAnnealing, Cyclic, 等。请从 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9 参考 LrUpdater 的细节。
warmup='linear', # 预热(warmup)策略,也支持 `exp` 和 `constant`。
warmup_iters=500, # 预热的迭代次数
warmup_ratio=
0.001, # 用于热身的起始学习率的比率
step=[8, 11]) # 衰减学习率的起止回合数
runner = dict(
type='EpochBasedRunner', # 将使用的 runner 的类别 (例如 IterBasedRunner 或 EpochBasedRunner)。
max_epochs=12) # runner 总回合数, 对于 IterBasedRunner 使用 `max_iters`
checkpoint_config = dict( # Checkpoint hook 的配置文件。执行时请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py。
interval=1) # 保存的间隔是 1。
log_config = dict( # register logger hook 的配置文件。
interval=50, # 打印日志的间隔
hooks=[
# dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志
dict(type='TextLoggerHook')
]) # 用于记录训练过程的记录器(logger)。
dist_params = dict(backend='nccl') # 用于设置分布式训练的参数,端口也同样可被设置。
log_level = 'INFO' # 日志的级别。
load_from = None # 从一个给定路径里加载模型作为预训练模型,它并不会消耗训练时间。
resume_from = None # 从给定路径里恢复检查点(checkpoints),训练模式将从检查点保存的轮次开始恢复训练。
workflow = [('train', 1)] # runner 的工作流程,[('train', 1)] 表示只有一个工作流且工作流仅执行一次。根据 total_epochs 工作流训练 12个回合。
work_dir = 'work_dir' # 用于保存当前实验的模型检查点和日志的目录文件地址。