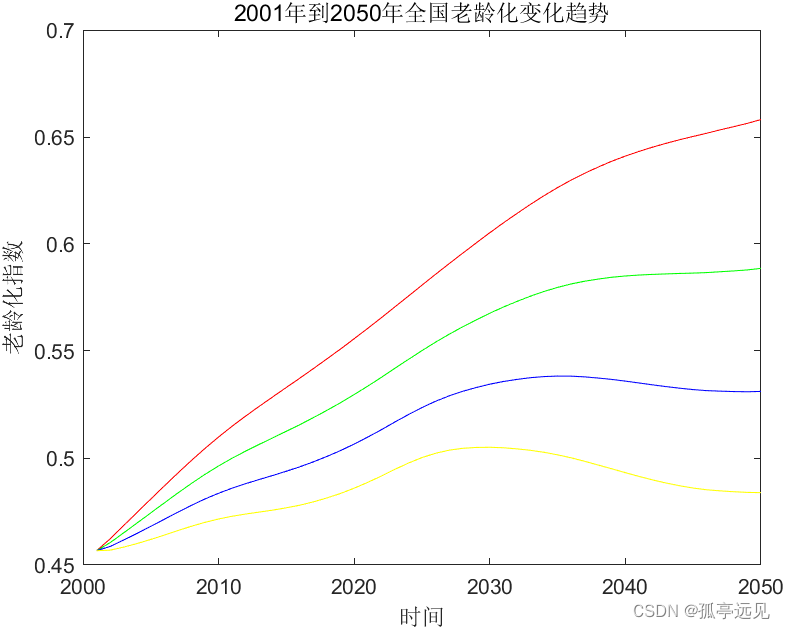
在此数据科学和机器学习教程中,获取有关如何从头到尾创建和运行分类模型的动手示例。本教程涵盖以下步骤:
- 数据探索
- 数据预处理
- 拆分数据以进行训练和测试
- 准备分类模型
- 使用管道组装所有步骤
- 训练模型
- 对模型运行预测
- 评估和可视化模型性能
建立
本教程包括一个用 Python 编写的 Jupyter Notebook。您可以使用具有 IBM Cloud 帐户的 Watson Studio 在 IBM Cloud 上运行笔记本。
-
注册或登录。
- 激活 Watson Studio,方法是从 Try IBM Cloud Pak for Data 页面登录您的 IBM Cloud 帐户。
- 访问 Watson Studio,方法是在 https://dataplatform.cloud.ibm.com 登录。
-
创建一个空项目。
- 单击“创建项目”或“新建项目”。
- 选择“创建空项目”。
- 为项目命名。
- 选择现有的对象存储服务实例或创建一个新的实例。
- 单击创建。
-
添加笔记本。
- 单击“+添加到项目”。
- 单击“笔记本”。
- 单击“从网址”。
- 提供名称。
- 在“选择运行时”下,选择“默认 Python 3.6 免费版”。
- 输入为笔记本 URL。
https://raw.githubusercontent.com/IBM/ml-learning-path-assets/master/notebooks/classification_start_to_end_with_scikit_learn.ipynb - 单击“创建笔记本”。
-
运行笔记本。
在打开的笔记本中,单击“运行”以一次运行一个单元格。本教程的其余部分遵循笔记本的顺序。
现在,您已经设置了笔记本,让我们继续开发分类模型,使用包含有关在线交易平台客户信息的数据集来预测客户是否会流失。
数据探索
在实际机器学习开始之前,必须执行几个步骤。首先,数据科学家必须分析将用于运行预测的数据的质量。数据的有偏差表示会导致模型偏斜。有几种方法可以分析数据。在本教程中,我们将进行最少的数据探索,刚好足以让您了解所执行的操作。然后,我们继续讨论本主题的核心主题。
关于数据集
在本教程中,我们使用包含在线交易平台客户信息的数据集来分类给定客户的流失概率是高、中还是低。这为了解如何从头到尾构建分类模型提供了一个很好的示例。预测将属于的三个类别是高、中和低。现在,让我们仔细看看数据集。
数据以.csv文件的形式提供给我们,并使用熊猫库导入。我们使用 numpy 和 matplotlib 来获取一些统计数据并可视化数据。
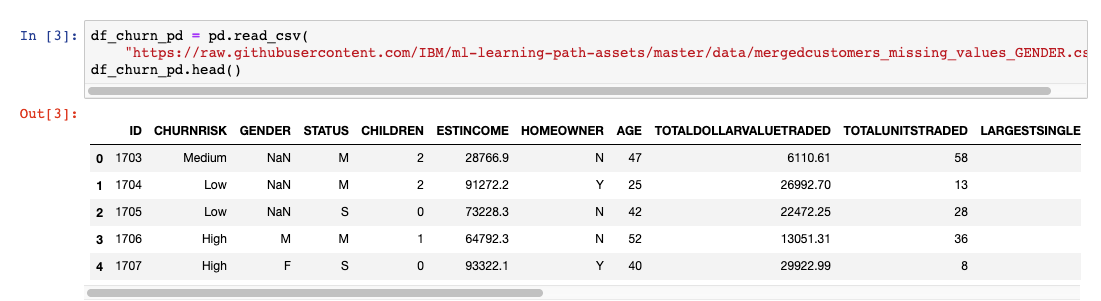
我们首先运行几行代码来了解每列的数据类型以及每列中的条目数。

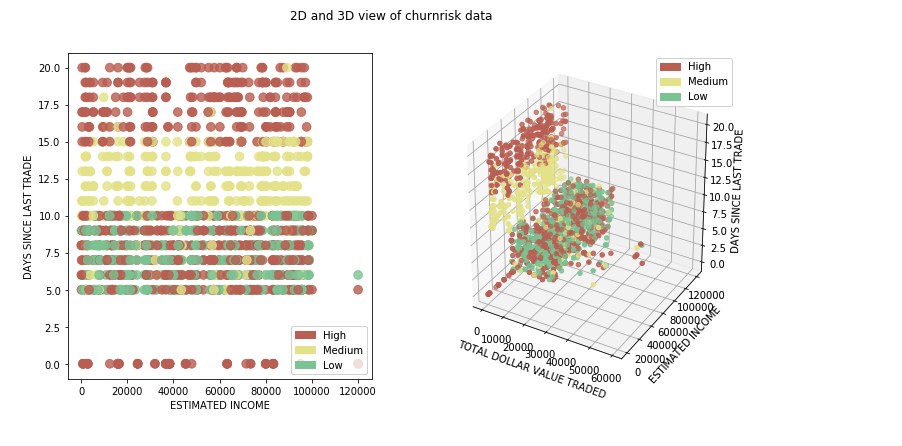
性别列中的计数不匹配(见下图)在数据预处理步骤中处理。
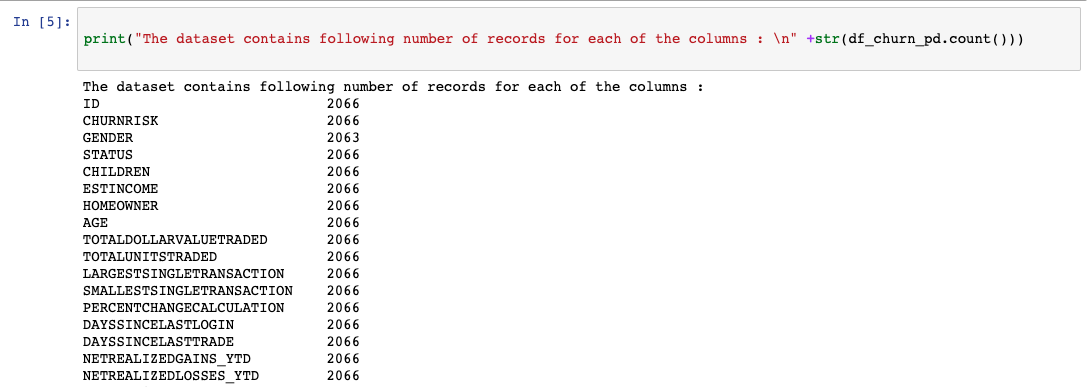
我们使用 matplotlib 绘制了一个基本的条形图,以了解数据如何在不同的输出类之间拆分。如果我们对代表性数据不满意,现在是时候获取更多数据用于训练和测试了。

数据预处理
数据预处理是机器学习模型构建过程中的一个重要步骤,因为只有当训练的数据良好且准备充分时,模型才能表现良好。因此,在构建模型时,此步骤会消耗大量时间。
机器学习中有几个常见的数据预处理步骤,在本教程中,我们将介绍其中的一些步骤。scikit-learn提供的预处理选项的完整列表可以在scikit-learn数据预处理页。
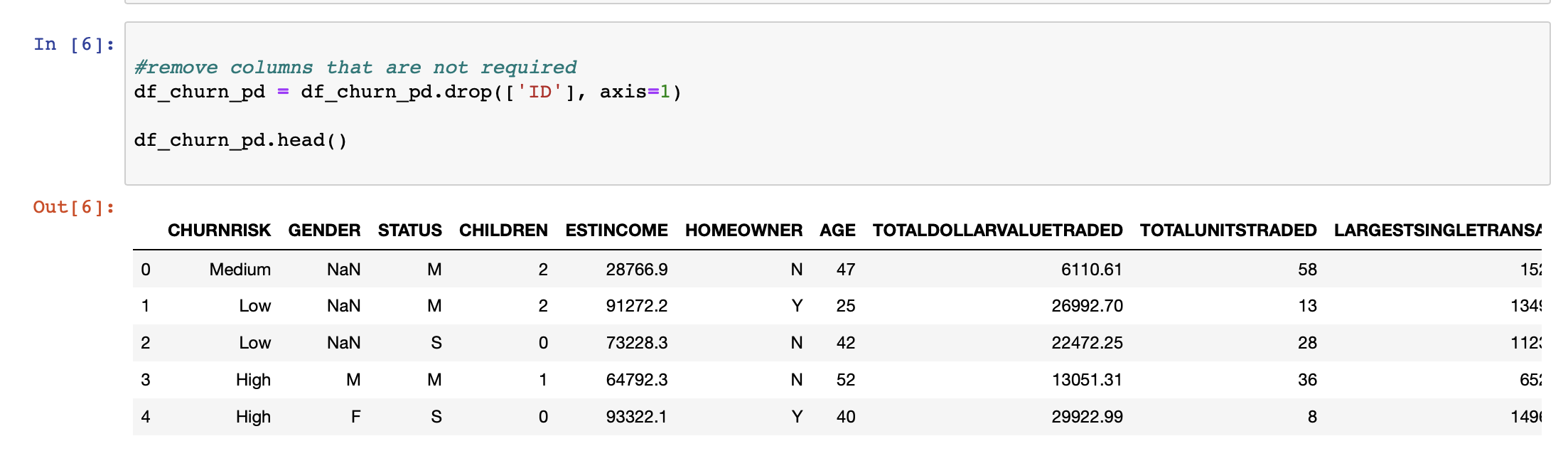
我们首先确定不会为预测输出增加任何价值的列。虽然其中一些列很容易识别,但通常会聘请主题专家来识别其中的大部分。删除此类列有助于降低模型的维数。
必须针对每个列自定义应用的预处理技术。Sklearn提供了一个名为ColumnTransformer的库,它允许使用管道将这些技术的序列应用于选择性列。
处理数据集时的一个常见问题是缺少值。scikit-learn提供了一种方法,可以用适用于其上下文的内容填充这些空值。我们使用了 Sklearn 提供的类,并用列中最常用的值填充缺失值。SimpleImputer
此外,由于机器学习算法在处理数字时比在字符串上表现得更好,因此我们希望识别具有类别的列并将其转换为数字。我们使用Sklearn提供的类。一个热编码器的想法是创建二进制变量,每个变量代表一个类别。通过这样做,我们删除了通过仅将数字分配给类别而可能发生的任何序数关系。基本上,我们从包含多个类号的单个列转到仅包含二进制类号的多个列。OneHotEncoder

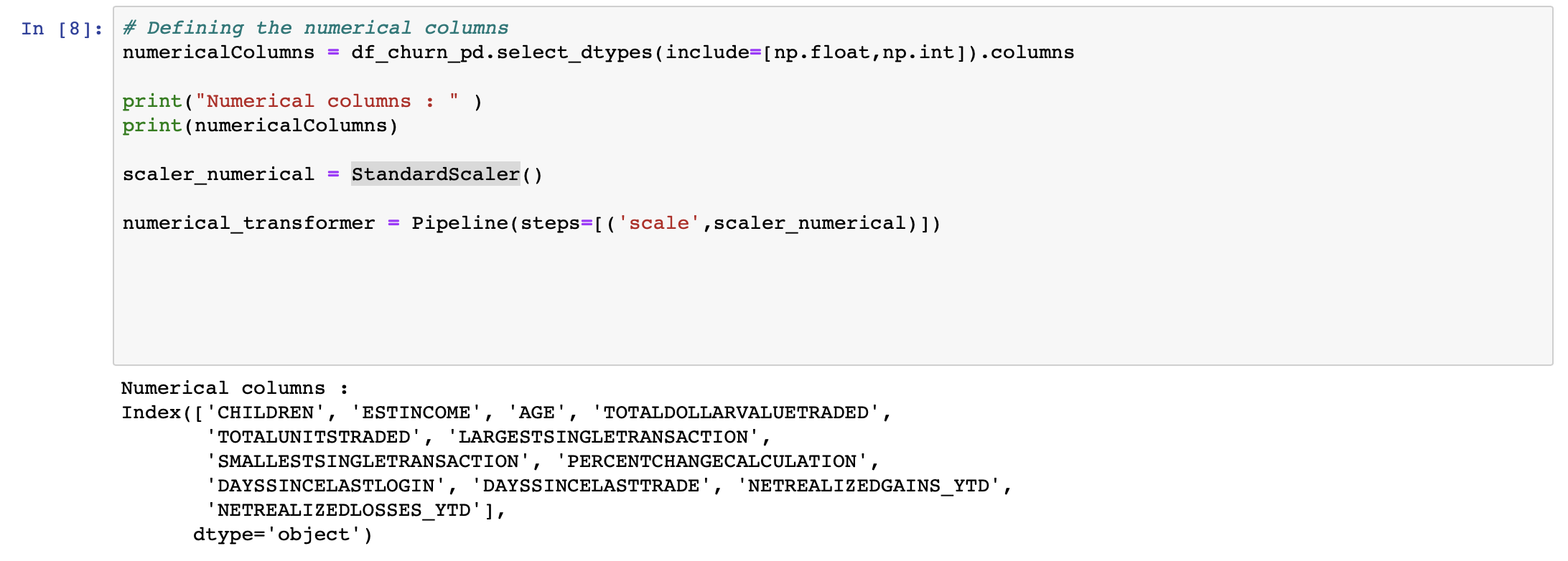
将标识数据集中的数字列,并将其应用于每个列。这样,每个值都用其列的平均值减去,然后除以其标准差。StandardScaler
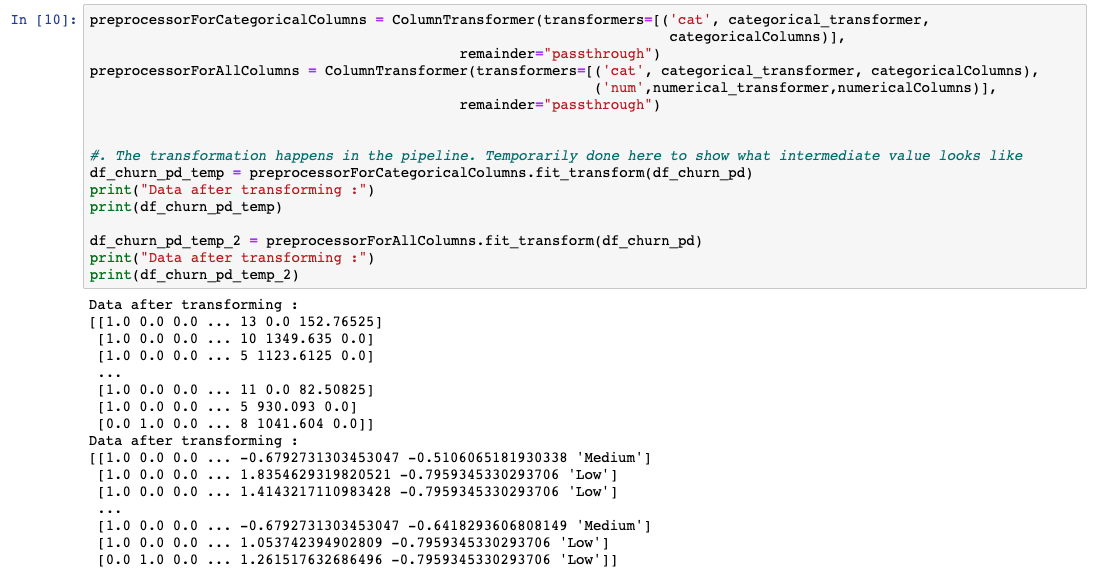
如前所述,每种技术都按需要应用的列进行分组,并使用 .理想情况下,这在训练模型之前在管道中运行。但是,为了了解数据的外观,我们将数据转换为临时变量。ColumnTransformer
机器学习算法不能使用简单文本。我们必须将数据从文本转换为数字。因此,对于每个作为类的字符串,我们分配一个数字标签。例如,在客户流失数据集中,流失风险输出标签分类为高、中或低,并分配标签 0、1 或 2。为此,我们使用Sklearn提供的类。LabelEncoder

这些是应用于数据集的一些常用预处理步骤。您可以在数据预处理中获取详细信息。
拆分数据以进行训练和测试
预处理数据后,下一步是将数据拆分为多个部分,用于创建和训练模型以及测试和评估生成的模型。在训练和测试之间应该分配多少百分比的数据背后有几种理论。在本教程中,我们使用 98% 的数据进行训练,使用 2% 的数据进行测试。

准备分类模型
有几种流行的分类模型,并且已被证明具有很高的准确性。在本教程中,我们通过初始化 Sklearn 提供的库来应用随机森林分类器。作为此学习路径的一部分,我们使用 Python 和 scikit-learn 对 Learn 分类算法中的各种分类模型进行了详细的描述和比较。现在,我们将跳过随机森林如何工作的细节,并继续创建我们的第一个机器学习模型。

使用管道组装步骤
在此学习路径中,我们使用管道。管道是在机器学习流中设计数据处理的便捷方法。使用管道背后的想法在使用 Python 和 scikit-learn 的 Learn 分类算法中有详细说明。下面的代码示例演示如何使用 sklearn 设置管道。

训练模型
创建模型的最后一步称为建模,您基本上可以训练机器学习算法。在拆分数据步骤中拆分的 98% 的数据用于训练在上一步中初始化的模型。
对模型运行预测
训练模型后,即可进行一些分析。在此步骤中,为测试模型保留的 2% 的数据用于运行预测。数据被蒙住,没有任何输出,并如下图所示进行传递。收集预测输出以根据实际结果进行评估,这就是我们在下一步中要做的事情。

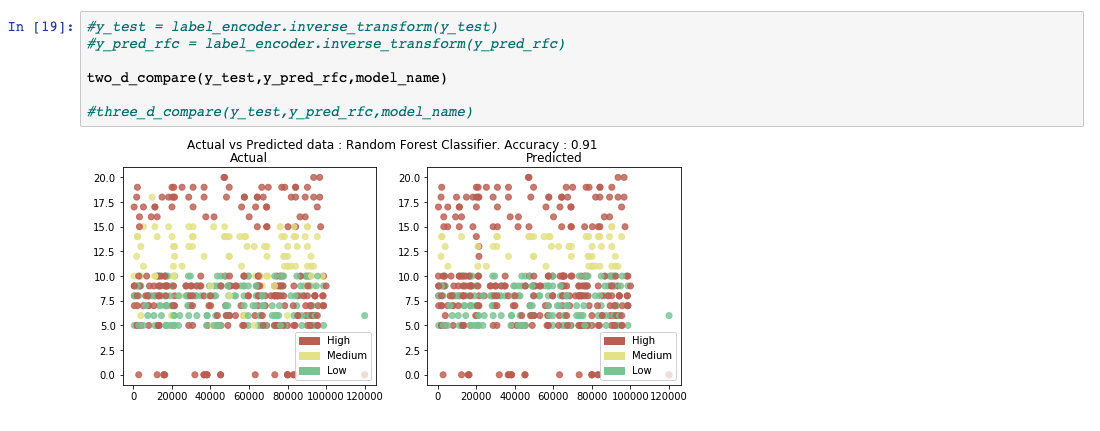
评估和可视化模型性能
使用实际结果进行比较上一步中获取的预测结果。生成多个评估指标来计算模型的性能。
总结
在评估提供令人满意的分数之前,您将通过调整所谓的超参数来通过评估步骤重复数据预处理。

在本教程中,你将获得一个动手示例,说明如何从头到尾开发基本的机器学习分类模型。