题目
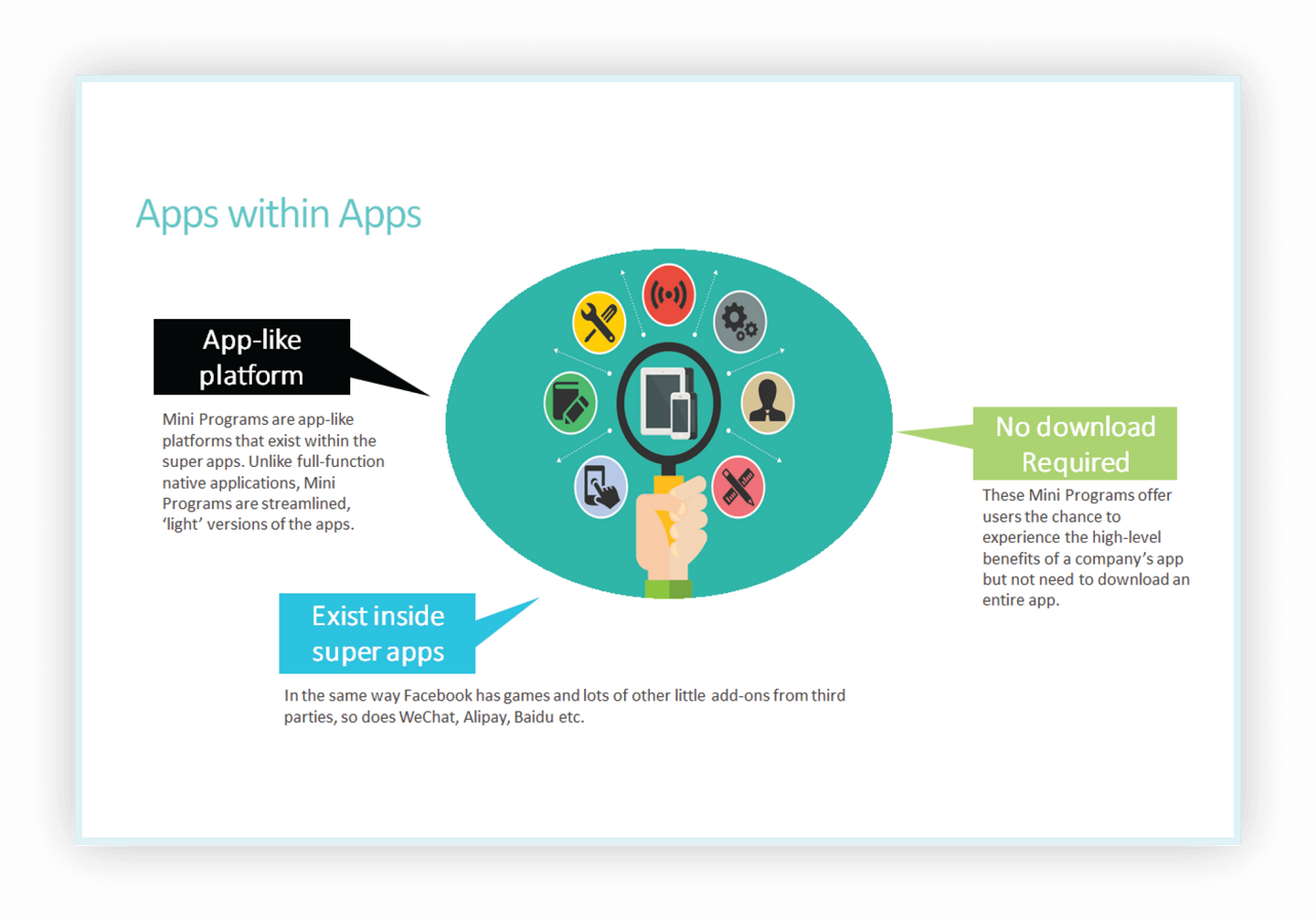
采用SVM方法实现鸢尾花(Iris)数据集分类
数据集
iris.name是关于数据集的属性说明;
iris.data是实际的数据集,它包含三类数据,每类数据有50条数据。

要求
训练集:选取Iris数据集中80%的数据,即120个数据,每类含有40个数据。
测试集:采用除训练集外的30个数据。
具体SVM方法:自由根据情况来选择。
评价指标:选取分类相关的评价指标来衡量分类结果。
# -*- coding: utf-8 -*- #
"""
@Project :NIR-Mathematical-Modeling-Tool
@File :main.py
@Author :ZAY
@Time :2023/6/4 15:44
@Annotation : " "
"""
import os
import torch
import sklearn
import numpy as np
from sklearn import svm
from sklearn.metrics import accuracy_score,auc,roc_curve,precision_recall_curve,f1_score, precision_score, recall_score
from Exp.Exp3.Plot import plotShow
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 将标签由文字映射为数字
def Iris_label(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
if __name__ == "__main__":
txt_path = './/Result//SVM.txt'
data = np.loadtxt("./Data/iris.data", dtype = float, delimiter = ',', converters = {4: Iris_label})
data_x, label_y = np.split(data, indices_or_sections = (4,), axis = 1) # x为数据,y为标签
data_x = data_x[:, 0:2]
train_data, test_data, train_label, test_label = sklearn.model_selection.train_test_split(data_x, label_y,
random_state = 1,
train_size = 0.8,
test_size = 0.2)
# 训练 SVM 分类器
classifier = svm.SVC(C = 2, kernel = 'rbf', gamma = 10, decision_function_shape = 'ovr')
classifier.fit(train_data, train_label.ravel())
train_label_pre = classifier.predict(train_data)
test_label_pre = classifier.predict(test_data)
print('训练集:', accuracy_score(train_label, train_label_pre))
print('测试集:', accuracy_score(test_label, test_label_pre))
# 查看内部决策函数(返回的是样本到超平面的距离)
train_decision_function = classifier.decision_function(train_data)
predict_result = classifier.predict(train_data)
print('train_decision_function:', classifier.decision_function(train_data))
print('predict_result:', classifier.predict(train_data))
plotShow(test_data, test_label, data_x, label_y, classifier)
plotShow.py
# -*- coding: utf-8 -*- #
"""
@Project :NIR-Mathematical-Modeling-Tool
@File :plot.py
@Author :ZAY
@Time :2023/6/5 21:41
@Annotation : " "
"""
# 确定坐标轴范围
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
def plotShow(test_data, test_label, data_x, label_y, classifier):
x1_min, x1_max = data_x[:, 0].min(), data_x[:, 0].max() # 第0维特征的范围
x2_min, x2_max = data_x[:, 1].min(), data_x[:, 1].max() # 第1维特征的范围
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j] # 生成网络采样点
grid_test = np.stack((x1.flat, x2.flat), axis = 1) # 测试点
# 指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
# 设置颜色
cm_light = matplotlib.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = matplotlib.colors.ListedColormap(['g', 'r', 'b'])
grid_hat = classifier.predict(grid_test) # 预测分类值
grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, grid_hat, cmap = cm_light) # 预测值的显示
plt.scatter(data_x[:, 0], data_x[:, 1], c = label_y[:, 0], s = 30, cmap = cm_dark) # 样本
plt.scatter(test_data[:, 0], test_data[:, 1], c = test_label[:, 0], s = 30, edgecolors = 'k', zorder = 2,
cmap = cm_dark) # 圈中测试集样本点
plt.xlabel('花萼长度', fontsize = 13)
plt.ylabel('花萼宽度', fontsize = 13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title('鸢尾花SVM二特征分类')
plt.savefig('./Result/iris-cla.png')
plt.show()