一、NLP
(一)bert中一些标记
1、[SEP]
用于断句,其真实效果,有待考究,因为有segment embedding
2、[CLS]
生成一个向量,用来进行文本分类
(二)AutoTokenizer
关于tokenizer更加详细内容,可参考:https://zhuanlan.zhihu.com/p/390821442
这个是Transformer中的一个类,可以使用from_pretrained方法,进行实例化

(三)tokenizer
参考:https://zhuanlan.zhihu.com/p/121787628
1、Encoding
(1)tokenize
(2)convert to ids
--------------Roberta---------------------------------------
from transformers import RobertaTokenizer
sequence1 = "media_common.cataloged_instance award.winning_work"
sequence2 = "media _ common . cataloged _ instance award . winning _ work"
tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
tokens1 = tokenizer.tokenize(sequence1)
ids1 = tokenizer.convert_tokens_to_ids(tokens1)
tokens2 = tokenizer.tokenize(sequence2)
ids2 = tokenizer.convert_tokens_to_ids(tokens2)
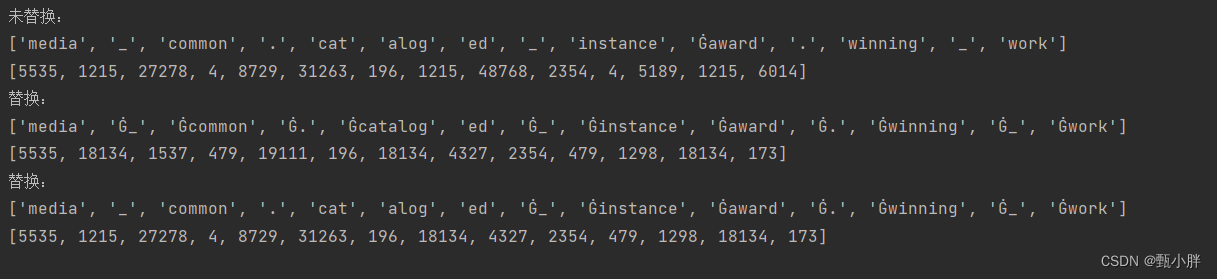
print('未替换:')
print(tokens1)
print(ids1)
print('替换:')
print(tokens2)
print(ids2)
运行结果是不一样的~

--------------------------deberta-------------------------------
from transformers import AutoModel, AutoModelForSequenceClassification, AutoTokenizer, AutoConfig, DataCollatorWithPadding
from transformers import DebertaTokenizer
sequence1 = "media_common.cataloged_instance award.winning_work"
sequence2 = "media _ common . cataloged _ instance award . winning _ work"
sequence3 = "media_common.cataloged _ instance award . winning _ work"
tokenizer = DebertaTokenizer.from_pretrained("microsoft/deberta-base")
tokens1 = tokenizer.tokenize(sequence1)
ids1 = tokenizer.convert_tokens_to_ids(tokens1)
tokens2 = tokenizer.tokenize(sequence2)
ids2 = tokenizer.convert_tokens_to_ids(tokens2)
tokens3 = tokenizer.tokenize(sequence3)
ids3 = tokenizer.convert_tokens_to_ids(tokens3)
print('未替换:')
print(tokens1)
print(ids1)
print('替换:')
print(tokens2)
print(ids2)
print('替换:')
print(tokens3)
print(ids3)
好玩欸,deberta 的tokenize也变成这样了~加了空格之后,'_‘和’.'会被重新解读
2、decode
就是反向查看
3、padding
为了做matrix处理,加入pad,可以指定pad的id
4、mask
可以用mask mask掉上面的pad,这样使运算结果不受影响。
(四)动态masking的好处
每个epoch的训练内容不同,增加了训练的多样性
https://adaning.github.io/posts/24649.html
纯静态Mask: 就是BERT中使用的Mask, 在数据预处理阶段就进行, 每个Epoch所Mask同一句中的Token位置都是相同的.
改进一点的静态Mask: 将每个Sentence都重复N次, 这样可能在预处理阶段能得到N种不同的Mask.
因为扩大了每个Epoch的数据量, 训练的Epoch要是原来的1/N倍. 动态Mask: 每个Sentence给BERT之前动态Mask,
即生成一种新的Mask方式. 这样每个Epoch拿到的Mask基本上是不同的. 从Mask的方法上来看,
动态Mask并没有引入太多的计算花费, 但是却大大提升了训练时句子的多样性. 为了证明其有效性,
(五)BPE
参考:https://zhuanlan.zhihu.com/p/424631681
Byte-Pair Encoding
这是一种数据压缩的方式,主要压缩词表,把慈悲压缩为sub-word的形式。
之所以叫byte-pair是因为该算法以byte为编码,作为subword聚合的基本单位——先将单词拆为byte,统计频率;然后不断结合。
参考:https://zhuanlan.zhihu.com/p/170656789
使用bytes-based BPE不会引入位置字符;
原BERT对应vocab大小,3万;
现在:5万
Radford在GPT2[2]里提出了一种更巧妙的BPE实现版本,该方法使用bytes(字节)作为基础的子词单元,这样便把词汇表的大小控制到了5w。它可以在不需要引入任何未知字符前提下对任意文本进行编码。
BERT原始版本使用一个字级(character-level)的BPE词汇表,大小是3w,是用启发式分词规则对输入进行预处理学习得到的。
(六)MASK
具体mask是如何作用的呢?源代码中是不去计算了嘛
DP
(一)交叠子问题是什么
很多子问题被一次次求解


![[附源码]计算机毕业设计校园便携系统Springboot程序](https://img-blog.csdnimg.cn/b15cc6bc878543f19c38bf3e26552d53.png)

![[附源码]计算机毕业设计网上电影购票系统Springboot程序](https://img-blog.csdnimg.cn/2c1fbba2771d4ba3b949d6385bd10eaa.png)



![[附源码]计算机毕业设计JAVA医院门诊信息管理系统](https://img-blog.csdnimg.cn/65e4336648804aed8122d7f01173bc46.png)
![[LeetCode解题报告] 1610. 可见点的最大数目](https://assets.leetcode-cn.com/aliyun-lc-upload/uploads/2020/10/04/5010bfd3-86e6-465f-ac64-e9df941d2e49.png)