MySQL视图
VIEW(视图)
概念
可以被当作是虚拟表或存储查询
视图跟表格的不同是,表格中有实际储存资料,而视图是建立在表格之上的一个架构,它本身并不实际储存资料。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
创建、查看和删除视图
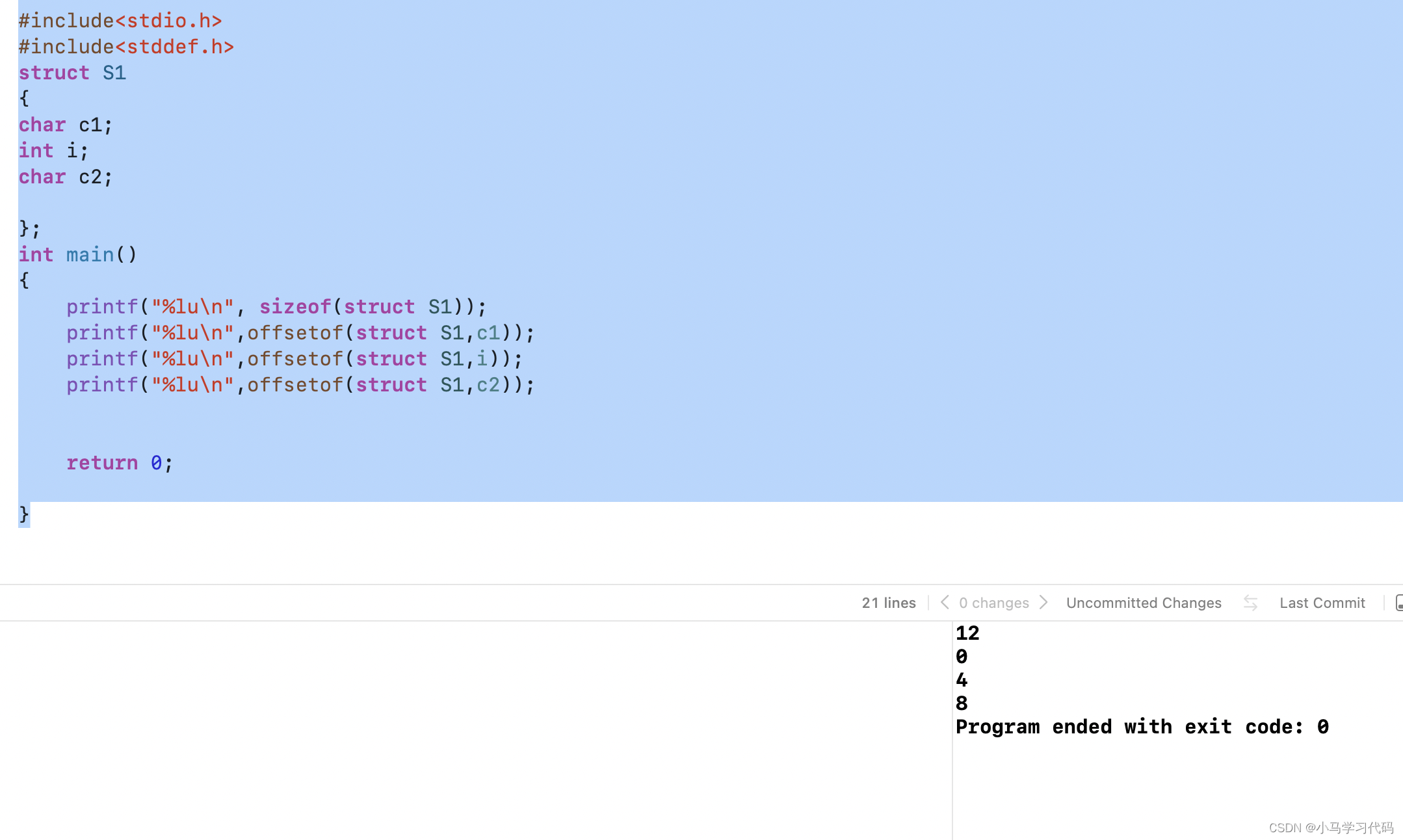
REATE VIEW "视图表名" AS "SELECT 语句"; #创建视图表
SELECT * FROM `V_NAME_VALUE`; #查看视图表
DROP VIEW V_NAME_VALUE; #删除视图表


修改update
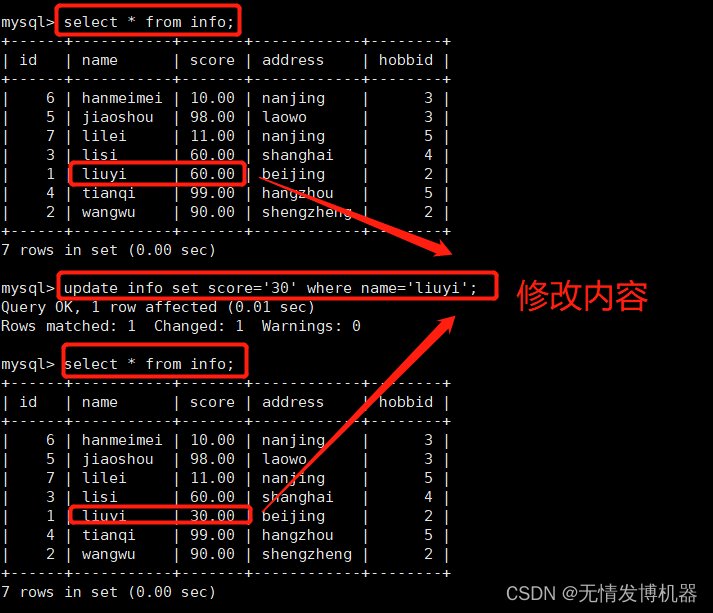
修改原表数据
update info set score='30' where name='liuyi';
# 将info表里的liuyi 分数修改为30
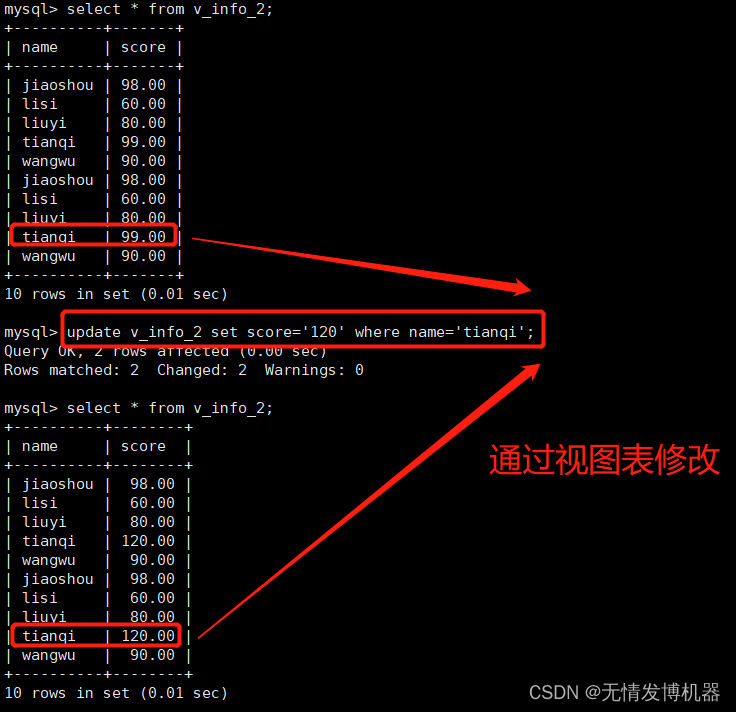
同时可以通过视图修改原表
update v_info_2 set score='120' where name='tianqi';
联集
将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的
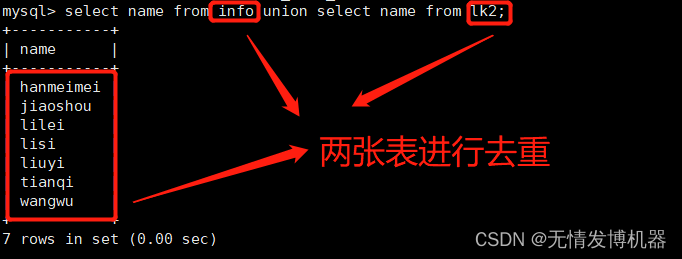
UNION
生成结果值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
select name from info union select name from lk2; # 去重
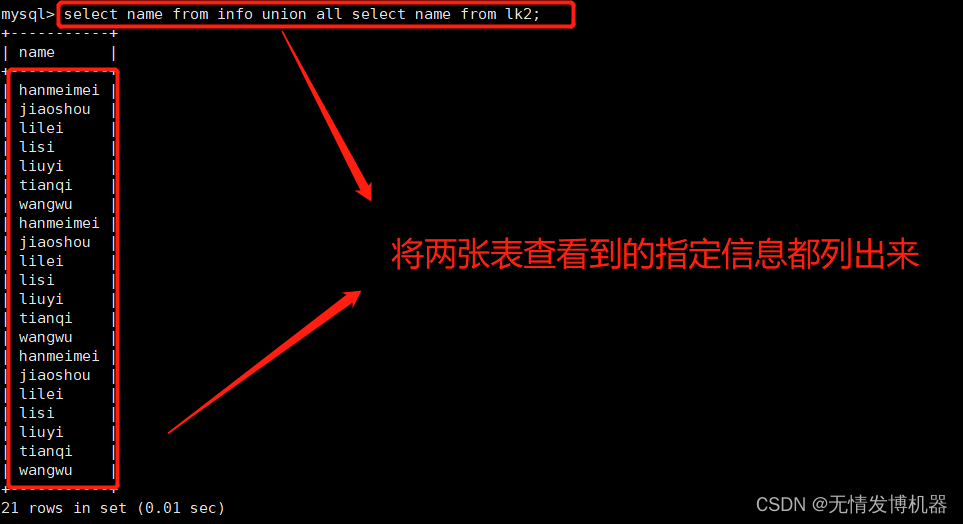
UNION ALL
将生成结果的值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
select name from info union all select name from lk2;
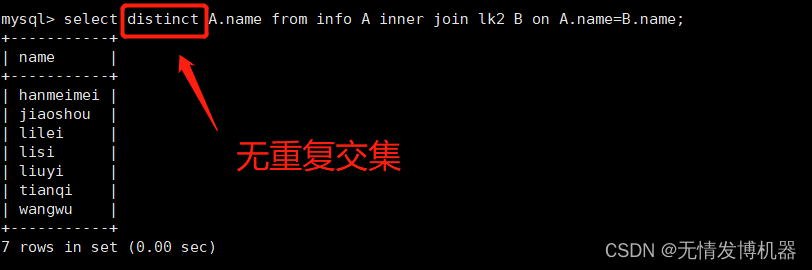
交集值
取两个SQL语句结果的交集
取交集值的方法1(2种简单方法,内连接+on/using,去重则加上distinct)
select A.name from info A inner join lk2 B on A.name=B.name;
select A.name from info A inner join lk2 B using(name);
select distinct A.name from info A inner join lk2 B on A.name=B.name;
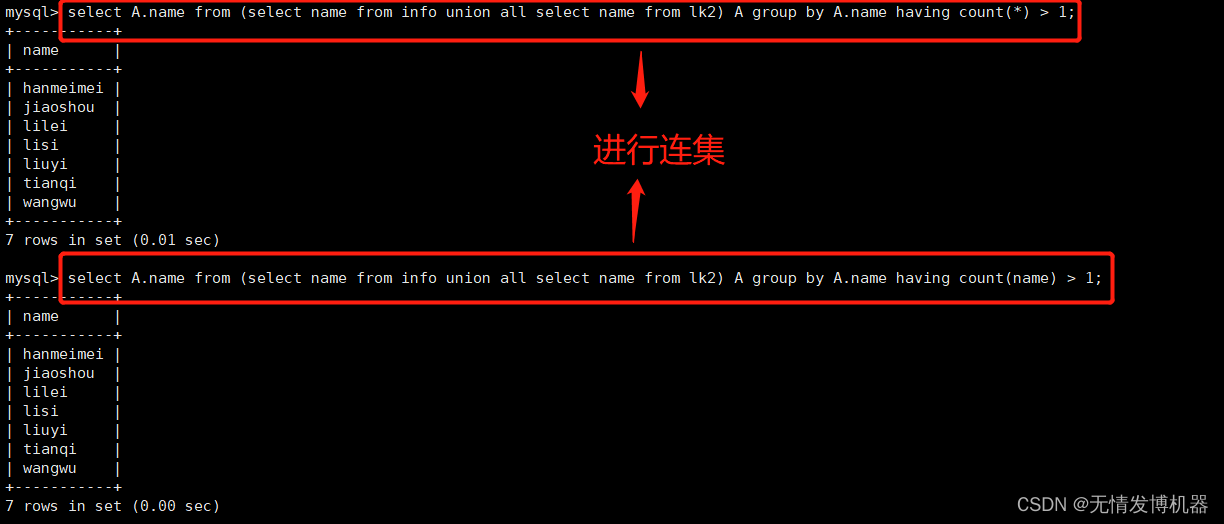
取交集方法2(1种,union all结合group by)
两表其中的一个表没有指定的行,而另一个表这个行有重复不可用,要求两个表确实有交集的时候用
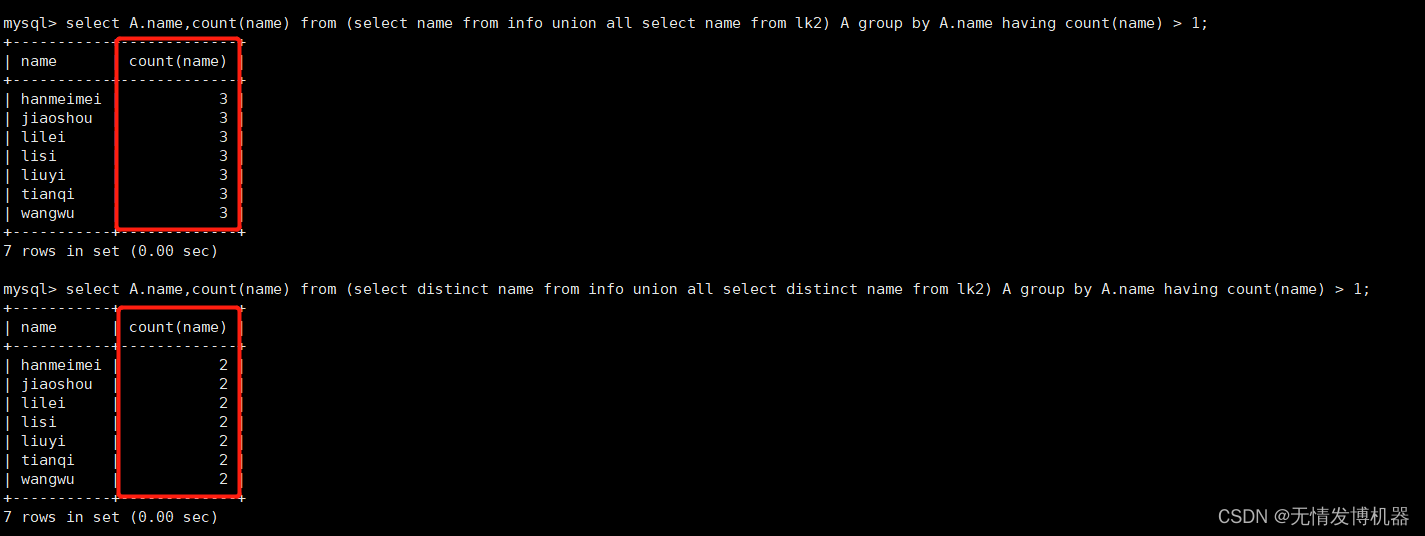
select A.name from (select name from info union all select name from lk2) A group by A.name having count(*) > 1;
select A.name from (select name from info union all select name from lk2) A group by A.name having count(name) > 1;
select name from info union all select name from lk2; #拆分上面的SQL语句
select A.name,count(name) from (select name from info union all select name from lk2) A group by A.name having count(name) > 1; #显示count值,便于理解
select A.name,count(name) from (select distinct name from info union all select distinct name from lk2) A group by A.name having count(name) > 1; #去重显示,在联集两个表之前先把表去重,以防一个表中本身就有重复值
取交集(去重)——4种方法
mysql> select A.name from (select B.name from info B inner join lk2 C on B.name=C.name) A group by A.name;
方法二:
select distinct A.name from info A inner join lk2 B using(name);
方法三:
select distinct name from info where name in (select name from lk2);
方法四:
select distinct A.name from info A left join lk2 B using(name) where B.name is NOT NULL;
方法一:内连接取交集结合group by去重
方法二:内连接取交集结合distinct去重
方法三:where+in遍历取交集并结合distinct去重
方法四:使用左连接(也可用右连接)+where 判断NOT NULL 取交集并结合distinct去重
NULL 值
在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失 的值,也就是在表中该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意 的是,NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有 值的。在 SQL 语句中,使用 IS NULL 可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL 值。
null值与空值的区别(空气与真空)
空值长度为0,不占空间,NULL值的长度为null,占用空间
is null无法判断空值
空值使用"=“或者”<>"来处理(!=)
count()计算时,NULL会忽略,空值会加入计算
插入一条记录,分数字段输入null,显示出来就是null
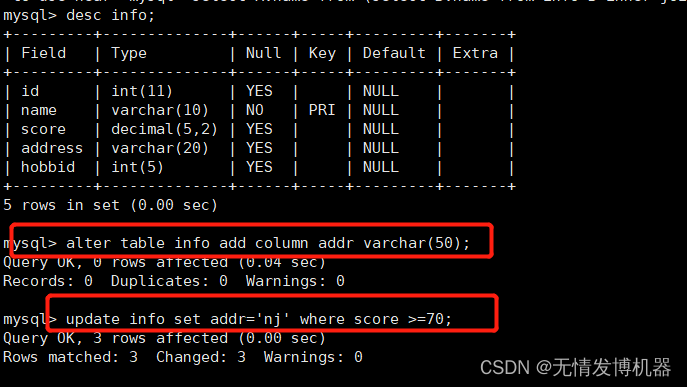
验证:
`alter table info add column addr varchar(50);
update info set addr=‘nj’ where score >=70;`
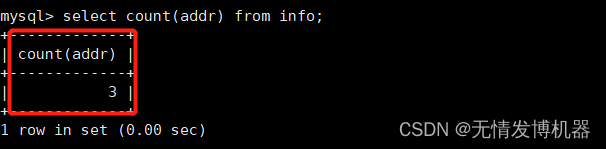
统计数量:检测null是否会加入统计中
select count(addr) from info;
将info表中其中一条数据修改为空值’’
update info set addr='' where name='wangwu';
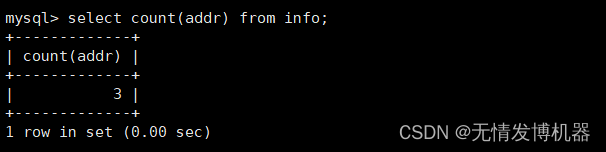
统计数量,检测空值是不会被添加到统计中
select count(addr) from info;
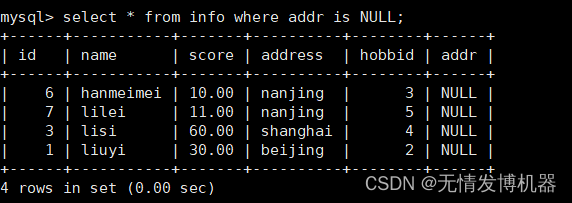
查询null值
select * from info where addr is NULL;
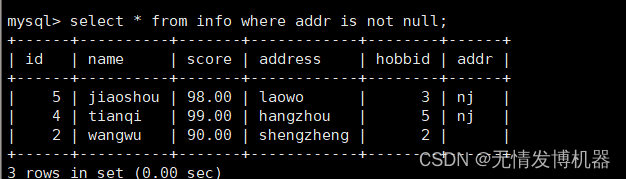
查询不为空的值
select * from info where addr is not null;
使用count统计行数(体现null与空值的区别)
count(*) 表示包括所有列的行数,不会忽略null值;空值正常统计
count(列名) 表示只包括这一列,统计时会忽略null值的行;空值正常统计
好文要顶 关注我 收藏该文
![[LeetCode解题报告] 1610. 可见点的最大数目](https://assets.leetcode-cn.com/aliyun-lc-upload/uploads/2020/10/04/5010bfd3-86e6-465f-ac64-e9df941d2e49.png)