title: Flink系列
二、Flink State 设计详解
Flink 官网解释:Apache Flink® — Stateful Computations over Data Streams
前课中 WordCount 的例子,可以得知:其实我们会发现,单词出现的次数有累计的效果。如果没有状态的管理,是不会有累计的效果的,所以 Flink 里面有 state 的概念。
需求:统计路口每个小时里面的总车流量
| 路口编号 | 小时 | 总的车流量 |
|---|---|---|
| 路口01 | 0-1 | 2000 |
| 路口02 | 1-2 | 1800 |
| 路口03 | 2-3 | 1600 |
| 路口04 | 3-4 | 1500 |
| … | … | … |
State: 假设某个路口统计到 0:30 的时候,临时总车流量 就是当前这个 路口对应的 Task 的 状态
Window操作:每隔 10s 统计过去 20s 的总车流量
计算平均值:1 =>(1,1) ; 2 => (2,3) ; 3=>(3,6) ;…
通用的:n => (state.count +1 , state.sum + n) 最终输出的结果: state.sum / state.count
Flink 的一个重要特性就是有状态计算:Stateful Computations over Data Streams
State 简单说,就是 Flink Job 的 Task 在运行过程中,产生的一些状态数据。这些状态数据,会辅助 Task 执行某些有状态计算,同时也涉及到 Flink Job 的重启状态恢复。所以,保存和管理每个 Task 的状态是非常重要的一种机制。这也是 Flink 有别于其他分布式计算引擎的最重要的区别。
State 需要配合检查点 Checkpoint 机制来保证 Flink 作业失败后能正确地进行错误恢复。
Flink 中的状态分为两类,Keyed State 和 Operator State 。
- Keyed State 是和具体的 Key 相绑定的,只能在 KeyedStream 上的函数和算子中使用。
- Opeartor State 则是和 Operator 的一个特定的并行实例相绑定的,例如 Kafka Connector 中,每一个并行的 Kafka Consumer 都在 Operator State 中维护当前 Consumer 订阅的 partiton 和 offset。
由于 Flink 中的 keyBy 操作保证了每一个键相关联的所有消息都会送给下游算子的同一个并行实例处理,因此 Keyed State 也可以看作是 Operator State 的一种分区(partitioned)形式,每一个 key 都关联一个状态分区(state-partition)。
从另一个角度来看,无论 Operator State 还是 Keyed State,都有两种形式,Managed State 和 Raw State。 Managed State 的数据结构由 Flink 进行托管,而Raw State 的数据结构对 Flink 是透明的。 Flink 的建议是尽量使用 Managed State,这样 Flink 可以在并行度改变等情况下重新分布状态,并且可以更好地进行内存管理。
简单总结一下:
state:一般指一个具体的 task/operator 的状态。State 可以被记录,在失败的情况下数据还可以恢复。
Flink 中有两种基本类型的 State:Keyed State,Operator State,他们两种都可以以两种形式存在:原始状态(raw state) 和 托管状态(managed state)。
Keyed State:在做 keyBy 之后,每个 key 都会携带一个状态。这种状态,就是 key state
Operator State: 一个 Task 一个 State
1、托管状态:由 Flink 框架管理的状态,我们通常使用的就是这种。
2、原始状态:由用户自行管理状态具体的数据结构,框架在做 checkpoint 的时候,使用 byte[] 来读写状态内容,对其内部数据结构一无所知。通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的 operator 时,会使用到原始状态。但是我们工作中一般不常用,所以我们不考虑它。
ZooKeeper: ZNode 的分类:持久类型 + 临时类型, 这两个类型的 ZNode 又可以划分成另外两种类型:带顺序编号的,不带顺序的
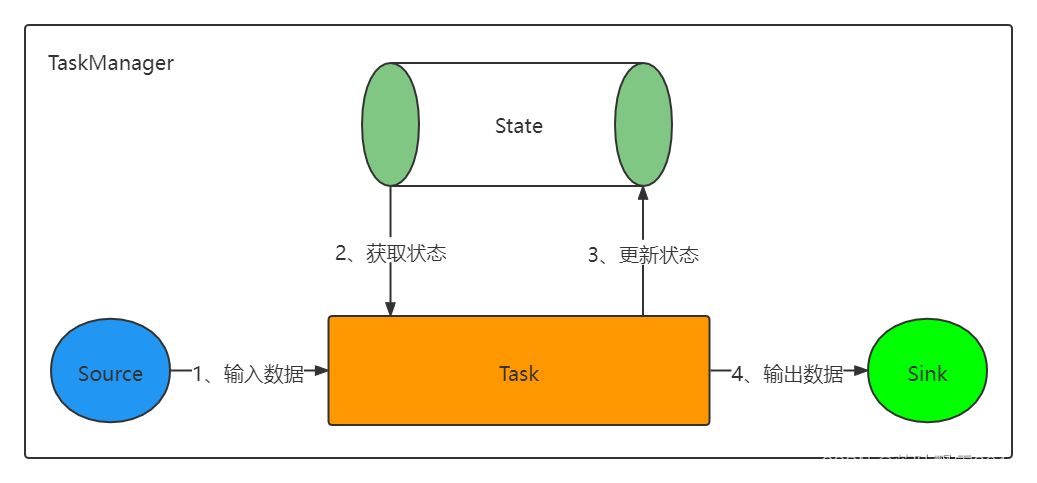
Flink 的 State 类型,通过一张图来理解
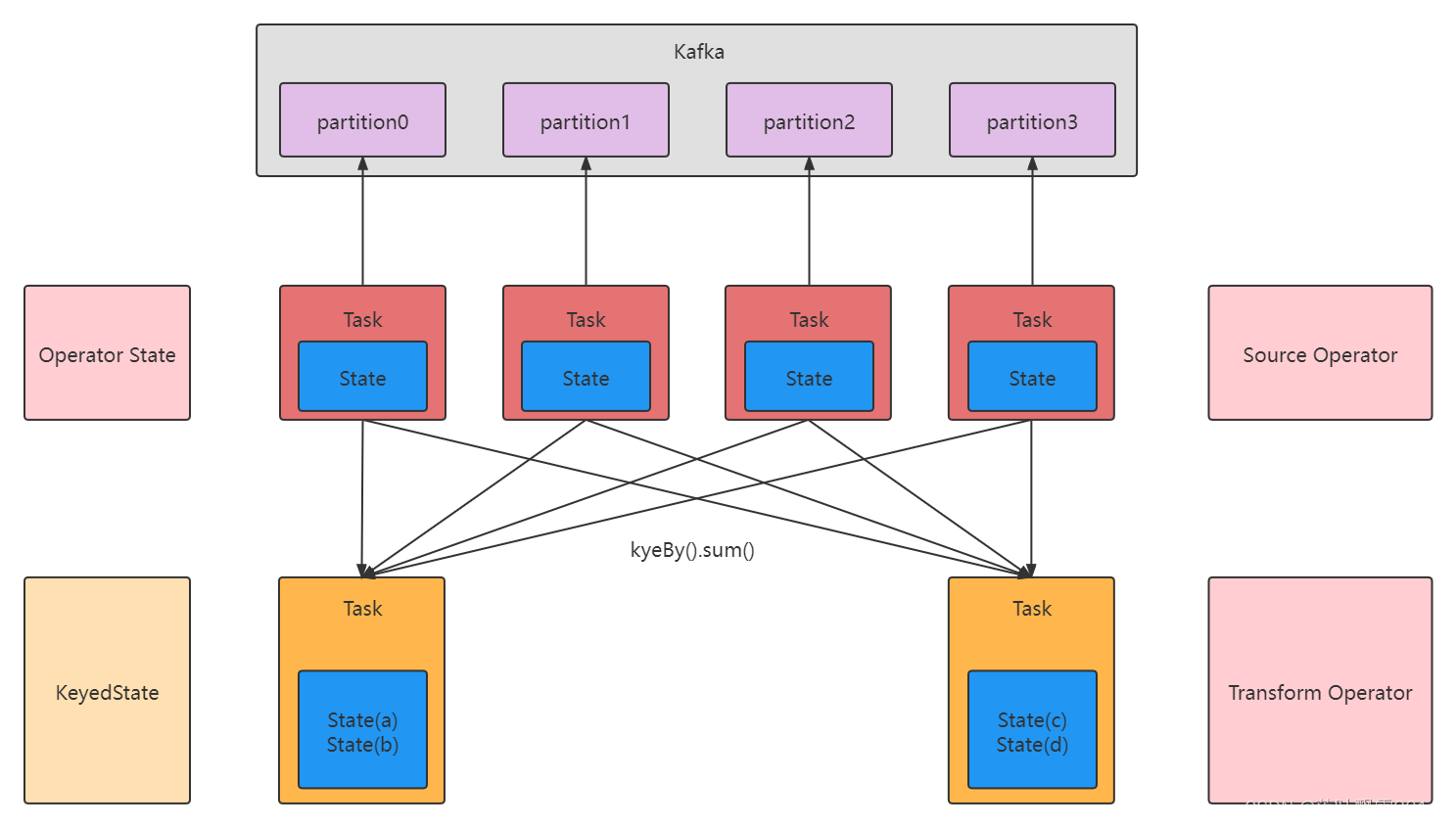
关于上图的理解补充:
1、假设 kafka 中有一个 Topic ,有 4 个分区
2、Flink Application 应用程序的 Source Operator 的并行度,一般就会必然设置成 4 ,一般不会设置多,也不会设置少
3、每个 Source Task 必然要去记录 当前这个 SourceTask 消费到 对应的那个 Topic Partition 的 offset
就是把所有的 Source Task 的状态 Operator State 进行持久化
4、Flink + Kafka 的整合
(1)记录 当前应用程序消费 Topic 的 每个分区的 offset
(2)Flink 的 Applicatioin 的 Sink 操作必须输出的时候确保数据一致性(确保数据消费语义有且仅一次)
幂等输出
2PC 两阶段分布式事务提交
补充一个知识点:keyed state 记录的是每个 key 的状态
Keyed State 托管状态有五种类型:
1、ValueState 单个值(Integer, String, Tuple2, Student)
2、ListState 多个值的(List)
3、MapState key-value类型的值的
4、ReducingState 聚合逻辑
5、AggregatingState 聚合逻辑
并不是所有的计算,都是有状态的, 也有一些计算类型是,是无状态(KeyState)的: 比如大写 转 小写, 比如 ETL 。
三、Flink Keyed State 企业案例实战
Keyed State 主要有下面五种状态:
ValueState
ListState
MapState
ReducingState
AggregatingState
相关的实战案例课上直播编写代码。
3.1 FlinkState案例之ValueState
package com.aa.flinkjava.state;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.state
* 需求:每 N个相同的key输出的他们的平均值,例如 N=4。
*/
public class FlinkState_01_ValueState {
public static void main(String[] args) throws Exception {
//1、环境准备。获取编程入口对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//executionEnvironment.setParallelism(2);
//2、准备一些数据
DataStreamSource<Tuple2<Long, Long>> dataStreamSource = executionEnvironment.fromElements(
Tuple2.of(1L, 1L),
Tuple2.of(1L, 2L),
Tuple2.of(2L, 3L),
Tuple2.of(2L, 4L),
Tuple2.of(1L, 5L),
Tuple2.of(1L, 6L),
Tuple2.of(2L, 7L),
Tuple2.of(2L, 8L)
);
//3、状态编程
/**
* 三种 State 来计算
* 1、 ValueState 存储单一的值,一个 Key 对应一个 ValueState
* 2、 ListState 存储数据列表,一个 Key 对应一个 ListState
* 3、 MapState 存储数据集合,一个 Key 对应一个 MapState
*/
//状态编程
SingleOutputStreamOperator<Tuple2<Long, Float>> result = dataStreamSource.keyBy(0).flatMap(new MyAverageWithValueState());
//4、输出
result.print();
//5、提交执行
executionEnvironment.execute("FlinkState_01_ValueState");
}
/**
* RichFlatMapFunction<IN, OUT> 两个泛型,一个输入,一个输出
*/
private static class MyAverageWithValueState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Float>> {
//定义一个成员变量
private ValueState<Tuple2<Long, Long>> countAndSumState;
//初始化的一些方法在这个里面
@Override
public void open(Configuration parameters) throws Exception {
//下面其实就固定步骤: 先声明一个 XXStateDesc
ValueStateDescriptor<Tuple2<Long, Long>> countAndSumStateDsc = new ValueStateDescriptor<>("countAndSumState", Types.TUPLE(Types.LONG, Types.LONG));
countAndSumState = getRuntimeContext().getState(countAndSumStateDsc);
}
//这个里面实现具体的业务逻辑的。
@Override
public void flatMap(Tuple2<Long, Long> record, Collector<Tuple2<Long, Float>> collector) throws Exception {
//如果当前的这个key的ValueState不存在,则初始化一个。
Tuple2<Long, Long> currentState = countAndSumState.value();
if (currentState == null){
currentState = Tuple2.of(0L,0L);
}
//进行状态的处理,key出现的次数加1,key的值进行了累加
currentState.f0 += 1;
currentState.f1 += record.f1;
//状态更新一下
countAndSumState.update(currentState);
//下面其实就是具体的业务逻辑了
if (currentState.f0 == 4){
//执行计算,求平均值
float avg = (float)currentState.f1 / currentState.f0;
//输出出去
collector.collect(Tuple2.of(record.f0,avg));
//清空状态
countAndSumState.clear();
}
}
}
}
3.2 FlinkState案例之ListState
package com.aa.flinkjava.state;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Collections;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.state
*/
public class FlinkState_02_ListState {
public static void main(String[] args) throws Exception {
//1、环境准备。获取编程入口对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//executionEnvironment.setParallelism(2);
//2、准备一些数据
DataStreamSource<Tuple2<Long, Long>> dataStreamSource = executionEnvironment.fromElements(
Tuple2.of(1L, 1L),
Tuple2.of(1L, 2L),
Tuple2.of(2L, 3L),
Tuple2.of(2L, 4L),
Tuple2.of(1L, 5L),
Tuple2.of(1L, 6L),
Tuple2.of(2L, 7L),
Tuple2.of(2L, 8L)
);
//3、状态编程
/**
* 三种 State 来计算
* 1、 ValueState 存储单一的值,一个 Key 对应一个 ValueState
* 2、 ListState 存储数据列表,一个 Key 对应一个 ListState
* 3、 MapState 存储数据集合,一个 Key 对应一个 MapState
*/
//状态编程
SingleOutputStreamOperator<Tuple2<Long, Float>> result = dataStreamSource.keyBy(0).flatMap(
new MyAverageWithListState());
//4、输出
result.print();
//5、提交执行
executionEnvironment.execute("FlinkState_02_ListState");
}
/**
* RichFlatMapFunction<IN, OUT> 两个泛型,一个输入,一个输出
*/
private static class MyAverageWithListState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Float>> {
//定义一个成员变量
private ListState<Tuple2<Long, Long>> listState;
//初始化的一些方法在这个里面
@Override
public void open(Configuration parameters) throws Exception {
//下面其实就固定步骤: 先声明一个 XXStateDescr
ListStateDescriptor<Tuple2<Long, Long>> listStateDsc = new ListStateDescriptor<>(
"list_State", Types.TUPLE(Types.LONG, Types.LONG));
listState = getRuntimeContext().getListState(listStateDsc);
}
//这个里面实现具体的业务逻辑的。
@Override
public void flatMap(Tuple2<Long, Long> record, Collector<Tuple2<Long, Float>> collector) throws Exception {
//如果当前的这个key的listState不存在,则初始化一个。
Iterable<Tuple2<Long, Long>> dataIterator = listState.get();
if (dataIterator == null){
listState.addAll(Collections.EMPTY_LIST);
}
//将接受到数据放到listState中,然后再去做判断。
listState.add(record);
//获取数据集的状态
ArrayList<Tuple2<Long, Long>> dataList = Lists.newArrayList(listState.get());
//下面其实就是具体的业务逻辑了,也就是判断是否达到统计的条件
if (dataList.size() == 4){
//执行计算,求平均值
//先统计一个和
long total = 0;
for (Tuple2<Long, Long> data : dataList) {
total += data.f1;
}
float avg = (float) total / 4 ;
//输出出去
collector.collect(Tuple2.of(record.f0,avg));
//清空状态
listState.clear();
}
}
}
}
3.3 FlinkState案例之MapState
package com.aa.flinkjava.state;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.UUID;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.state
* MapState 案例
*/
public class FlinkState_03_MapState {
public static void main(String[] args) throws Exception {
//1、环境准备。获取编程入口对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//executionEnvironment.setParallelism(2);
//2、准备一些数据
DataStreamSource<Tuple2<Long, Long>> dataStreamSource = executionEnvironment.fromElements(
Tuple2.of(1L, 1L),
Tuple2.of(1L, 2L),
Tuple2.of(2L, 3L),
Tuple2.of(2L, 4L),
Tuple2.of(1L, 5L),
Tuple2.of(1L, 6L),
Tuple2.of(2L, 7L),
Tuple2.of(2L, 8L)
);
//3、状态编程
/**
* 三种 State 来计算
* 1、 ValueState 存储单一的值,一个 Key 对应一个 ValueState
* 2、 ListState 存储数据列表,一个 Key 对应一个 ListState
* 3、 MapState 存储数据集合,一个 Key 对应一个 MapState
*/
//状态编程
SingleOutputStreamOperator<Tuple2<Long, Float>> result = dataStreamSource.keyBy(0).flatMap(
new MyAverageWithMapState()
);
//4、输出
result.print();
//5、提交执行
executionEnvironment.execute("FlinkState_03_MapState");
}
/**
* RichFlatMapFunction<IN, OUT> 两个泛型,一个输入,一个输出
*/
private static class MyAverageWithMapState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Float>> {
//定义一个成员变量
private MapState<String, Long> mapState;
//初始化的一些方法在这个里面
@Override
public void open(Configuration parameters) throws Exception {
//下面其实就固定步骤: 先声明一个 XXStateDescr
MapStateDescriptor<String, Long> mapStateDse = new MapStateDescriptor<>("map_State", String.class, Long.class);
mapState = getRuntimeContext().getMapState(mapStateDse);
}
//这个里面实现具体的业务逻辑的。
@Override
public void flatMap(Tuple2<Long, Long> record, Collector<Tuple2<Long, Float>> collector) throws Exception {
//记录状态数据。
mapState.put(UUID.randomUUID().toString(), record.f1);
//执行判断逻辑
Iterable<Long> values = mapState.values();
ArrayList<Long> arrayList = Lists.newArrayList(values);
//下面其实就是具体的业务逻辑了
if (arrayList.size() == 4){
//执行计算,求平均值
//先统计一个和
long total = 0;
for (Long data : arrayList) {
total += data;
}
float avg = (float) total / 4 ;
//输出出去
collector.collect(Tuple2.of(record.f0,avg));
//清空状态
arrayList.clear();
}
}
}
}
3.4 FlinkState案例之ReducingState
package com.aa.flinkjava.state;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.state
* ReducingState 案例
* 自定义累加求和
*/
public class FlinkState_04_ReducingState {
public static void main(String[] args) throws Exception {
//1、环境准备。获取编程入口对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//executionEnvironment.setParallelism(1);
//2、准备一些数据
DataStreamSource<Tuple2<Long, Long>> dataStreamSource = executionEnvironment.fromElements(
Tuple2.of(1L, 1L),
Tuple2.of(1L, 2L),
Tuple2.of(2L, 3L),
Tuple2.of(2L, 4L),
Tuple2.of(1L, 5L),
Tuple2.of(1L, 6L),
Tuple2.of(2L, 7L),
Tuple2.of(2L, 8L)
);
//3、状态编程
SingleOutputStreamOperator<Tuple2<Long, Long>> result = dataStreamSource.keyBy(0).flatMap(
new MySumByReducingStateFunction()
);
//4、输出
result.print();
//5、提交执行
executionEnvironment.execute("FlinkState_04_ReducingState");
}
/**
* RichFlatMapFunction<IN, OUT> 两个泛型,一个输入,一个输出
*/
private static class MySumByReducingStateFunction extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
//定义一个成员变量
private ReducingState<Long> reducingState;
//初始化的一些方法在这个里面
@Override
public void open(Configuration parameters) throws Exception {
ReducingStateDescriptor<Long> reducingStateDse = new ReducingStateDescriptor<Long>("reduce_state",
new ReduceFunction<Long>() {
//初始化ReducingState的时候,定义了一个聚合函数
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
},Long.class
);
reducingState = getRuntimeContext().getReducingState(reducingStateDse);
}
//这个里面实现具体的业务逻辑的。
@Override
public void flatMap(Tuple2<Long, Long> record, Collector<Tuple2<Long, Long>> collector) throws Exception {
//将输入合并到 ReducingState 当中
reducingState.add(record.f1);
//输出
collector.collect(Tuple2.of(record.f0,reducingState.get()));
}
}
}
3.5 FlinkState案例之AggregatingState
package com.aa.flinkjava.state;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.state
* AggregatingState案例
* 输出每个key对应的value列表
*/
public class FlinkState_05_AggregatingState {
public static void main(String[] args) throws Exception {
//1、环境准备。获取编程入口对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//executionEnvironment.setParallelism(1);
//2、准备一些数据
DataStreamSource<Tuple2<Long, Long>> dataStreamSource = executionEnvironment.fromElements(
Tuple2.of(1L, 1L),
Tuple2.of(1L, 2L),
Tuple2.of(2L, 3L),
Tuple2.of(2L, 4L),
Tuple2.of(1L, 5L),
Tuple2.of(1L, 6L),
Tuple2.of(2L, 7L),
Tuple2.of(2L, 8L)
);
//3、状态编程
SingleOutputStreamOperator<Tuple2<Long, String>> result = dataStreamSource.keyBy(0).flatMap(
new MySumByAggregatingStateFunction()
);
//4、输出
result.print();
//5、提交执行
executionEnvironment.execute("FlinkState_05_AggregatingState");
}
/**
* RichFlatMapFunction<IN, OUT> 两个泛型,一个输入,一个输出
*/
private static class MySumByAggregatingStateFunction extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, String>> {
//定义一个成员变量
private AggregatingState<Long,String> aggregatingState;
//初始化的一些方法在这个里面
@Override
public void open(Configuration parameters) throws Exception {
AggregatingStateDescriptor<Long, String, String> aggregatingStateDse = new AggregatingStateDescriptor<>("agg_state",
new AggregateFunction<Long, String, String>() {
//创建一个初始变量
@Override
public String createAccumulator() {
return "valueList:";
}
/**
* 进行 value的累加
* 例如传输过来的数据是 1 2 3
* 那么 结果的
* valueList: 1
* valueList: 1 2
* valueList: 1 2 3
* @param value 传递过来的值
* @param accumulator 字符串拼接结果
* @return
*/
@Override
public String add(Long value, String accumulator) {
if (accumulator.equals("valueList:")) {
return accumulator + value;
} else {
return accumulator + "," + value;
}
}
/**
* 获取最终的结果
* @param accumulator
* @return
*/
@Override
public String getResult(String accumulator) {
return accumulator;
}
/**
* 分区合并
* @param a
* @param b
* @return
*/
@Override
public String merge(String a, String b) {
return a + "," + b;
}
}, String.class
);
aggregatingState = getRuntimeContext().getAggregatingState(aggregatingStateDse);
}
//这个里面实现具体的业务逻辑的。
@Override
public void flatMap(Tuple2<Long, Long> record, Collector<Tuple2<Long, String>> collector) throws Exception {
//将输入合并到 ReducingState 当中
aggregatingState.add(record.f1);
//输出
collector.collect(Tuple2.of(record.f0,aggregatingState.get()));
}
}
}
四、Flink Operator State 企业案例实战
4.1 OperatorState自定义输出案例
package com.aa.flinkjava.state;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.util.ArrayList;
import java.util.List;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.state
*
* OperatorState 案例
* 自定义输出
*/
public class FlinkState_01_OperatorState {
public static void main(String[] args) throws Exception {
//1、环境准备。获取编程入口对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//executionEnvironment.setParallelism(2);
//2、准备一些数据
DataStreamSource<Tuple2<String, Integer>> dataStreamSource = executionEnvironment.fromElements(
Tuple2.of("zhangsan", 3),
Tuple2.of("lisi", 4),
Tuple2.of("wangwu", 5),
Tuple2.of("zhaoliu", 6),
Tuple2.of("sunqi", 7),
Tuple2.of("zhouba", 8),
Tuple2.of("wujiu", 9),
Tuple2.of("zhengshi", 10)
);
//4、输出
dataStreamSource.addSink(new MyPrintSink(2)).setParallelism(1);
//5、提交执行
executionEnvironment.execute("FlinkState_01_OperatorState");
}
private static class MyPrintSink implements SinkFunction<Tuple2<String,Integer>>, CheckpointedFunction{
private int recordNumber;
private List<Tuple2<String,Integer>> bufferElements;
private ListState<Tuple2<String,Integer>> listState;
public MyPrintSink(int recordNumber) {
this.recordNumber = recordNumber;
this.bufferElements = new ArrayList<>();
}
/**
* 对于数据的结合,拍摄state的快照
* @param functionSnapshotContext
* @throws Exception
*/
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
listState.clear();
for (Tuple2<String, Integer> element : bufferElements) {
listState.add(element);
}
}
/**
* 初始化 state
* @param context
* @throws Exception
*/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> listStateDescriptor = new ListStateDescriptor<>("MyPrintSink",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
})
);
//初始化 listState
ListState<Tuple2<String, Integer>> listState = context.getOperatorStateStore().getListState(listStateDescriptor);
//状态恢复
if (context.isRestored()){
for (Tuple2<String, Integer> element : listState.get()) {
bufferElements.add(element);
}
}
}
/**
* 帮数据给添加到 bufferElements 的数据集合中
* @param value
* @throws Exception
*/
@Override
public void invoke(Tuple2<String, Integer> value) throws Exception {
bufferElements.add(value);
if (bufferElements.size() == recordNumber){
System.out.println("输出格式为: " + bufferElements);
bufferElements.clear();
}
}
}
}
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接


![[附源码]计算机毕业设计JAVA医院门诊信息管理系统](https://img-blog.csdnimg.cn/65e4336648804aed8122d7f01173bc46.png)
![[LeetCode解题报告] 1610. 可见点的最大数目](https://assets.leetcode-cn.com/aliyun-lc-upload/uploads/2020/10/04/5010bfd3-86e6-465f-ac64-e9df941d2e49.png)