先上官方架构图:

论文地址:https://arxiv.org/pdf/2203.03605.pdf
代码地址:GitHub - IDEA-Research/DINO: [ICLR 2023] Official implementation of the paper "DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection"
DINO通过使用对比式的去噪训练、混合查询选择方法进行锚点初始化以及look forward twice方案进行边界框预测,从而在性能和效率上改进了先前的DETR-like模型。
一、backbone
DINO的backbone有两类,分别是基于swin transformer和resnet两类,其中resnet有4 scale 和5 scale 的设置。特征提取部分和Deformable-DETR相似,进行了一些改动,结果上基本一样。这里以resnet50 4scale为例,代码中通过return_interm_indices来控制返回的feature map层数
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_indices: list):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
return_layers = {}
for idx, layer_index in enumerate(return_interm_indices):
return_layers.update({"layer{}".format(5 - len(return_interm_indices) + idx): "{}".format(layer_index)})
# if len:
# if use_stage1_feature:
# return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
# else:
# return_layers = {"layer2": "0", "layer3": "1", "layer4": "2"}
# else:
# return_layers = {'layer4': "0"}
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
dilation: bool,
return_interm_indices:list,
batch_norm=FrozenBatchNorm2d,
):
if name in ['resnet18', 'resnet34', 'resnet50', 'resnet101']:
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=batch_norm)
else:
raise NotImplementedError("Why you can get here with name {}".format(name))
# num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
assert name not in ('resnet18', 'resnet34'), "Only resnet50 and resnet101 are available."
assert return_interm_indices in [[0,1,2,3], [1,2,3], [3]]
num_channels_all = [256, 512, 1024, 2048]
num_channels = num_channels_all[4-len(return_interm_indices):]
super().__init__(backbone, train_backbone, num_channels, return_interm_indices)4scale的return_interm_indices为[1,2,3]
为了能够更直观的解释一些细节,这里使用默认的设置,batch size为2,该batch中图像的最大尺寸为[640,701],对应的输入则是[2,3,640,701],那么通过下面这段代码得到三个尺度上输出的feature map,并且使用最后一层feature map 通过3*3卷积得到第四层feature map,即最终输出的src为[[N,256,80,88],[N,256,40,44],[N,256,20,22],[N,256,10,11]],其中N=2,对应的mask没有channel维度,poss是对mask进行位置编码的结果和src维度相同[[N,256,80,88],[N,256,40,44],[N,256,20,22],[N,256,10,11]]
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, poss = self.backbone(samples)
srcs = []
masks = []
for l, feat in enumerate(features):
src, mask = feat.decompose()
srcs.append(self.input_proj[l](src)) # 每一层的feature map通过1*1的卷积进行降维[N,512/1024/2048,H,W] -> [N,256,H,W],此处的H和W为对应层的feature map的尺寸
masks.append(mask) # mask的维度始终为[N,H,W]
assert mask is not None
if self.num_feature_levels > len(srcs):
_len_srcs = len(srcs)
for l in range(_len_srcs, self.num_feature_levels):
if l == _len_srcs:
src = self.input_proj[l](features[-1].tensors) # 取feature map的最后一层(最小的feature map)进行步长为2的3*3卷积降采样[N,2048,H,W] -> [N,256,H//2,W//2]
else:
src = self.input_proj[l](srcs[-1])
m = samples.mask
mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0] # 对最后一层的feature map做完3*3卷积后,需要得到对应的mask
pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype) # 前三层的mask的位置编码在backbone的前向过程中已经得到了,这里单独对第四层的mask做位置编码
srcs.append(src)
masks.append(mask)
poss.append(pos_l)
# 到这里就得到了四个尺度上的输出,假设输入大小为[N,640,701]那么输出的src为[[N,256,80,88],[N,256,40,44],[N,256,20,22],[N,256,10,11]],masks为[[N,80,88],[N,40,44],[N,20,22],[N,10,11]],poss为[[N,256,80,88],[N,256,40,44],[N,256,20,22],[N,256,10,11]]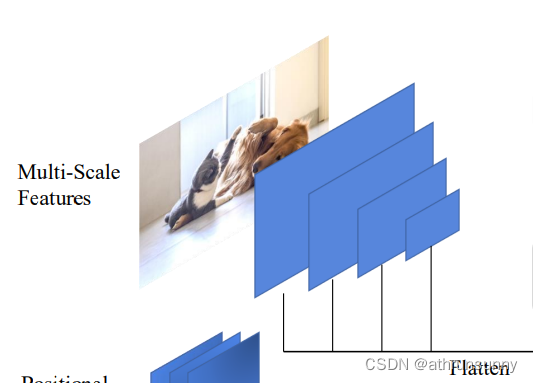
mask是为了记录未padding前的原始图像在padding后的图像中的位置。举例来说就是假设batch为2,其中一张图像的w*h=701*640,另一张图像的w*h为576*580,这个最大的W和H就是701和640。生成大小为[640,701]全0的张量,而较小的图像填充在这全0张量的左上角,也就是说张量中[576:701]以及[580:640]的部分都为0,反应在mask上就是[0:580,0:576]的部分为False,表示未被padding部分,[576:701]以及[580:640]的部分为True,表示被padding部分。图示效果如下:

生成mask的代码如下:
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
if tensor_list[0].ndim == 3:
if torchvision._is_tracing():
# nested_tensor_from_tensor_list() does not export well to ONNX
# call _onnx_nested_tensor_from_tensor_list() instead
return _onnx_nested_tensor_from_tensor_list(tensor_list)
# TODO make it support different-sized images
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
# 根据同一batch中最大的W和H对所有余图像进行padding
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
# 有padding的部分设为True
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)每个scale 的feature map都有对应mask为[[N,80,88],[N,40,44],[N,20,22],[N,10,11]]
poss是由mask经过PositionEmbeddingSineHW得到,PositionEmbeddingSineHW和DETR中的PositionEmbeddingSine不同之处在于,PositionEmbeddingSine中使用一个temperature同时控制W和H,而PositionEmbeddingSineHW可在W和H上使用不同的temperature,整体上的功能基本相同。DETR的原始设置的T=10000,文中作者发现设置为T=20的效果最好。
class PositionEmbeddingSineHW(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperatureH=10000, temperatureW=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperatureH = temperatureH
self.temperatureW = temperatureW
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_tx = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_tx = self.temperatureW ** (2 * (dim_tx // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_tx
dim_ty = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_ty = self.temperatureH ** (2 * (dim_ty // 2) / self.num_pos_feats)
pos_y = y_embed[:, :, :, None] / dim_ty
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos那么到这里就得到了后续输入到transformer中的src,mask以及poss(位置编码),在进入transformer之前还需要得到用于计算辅助loss的cdn参数,即加了噪声的label和bbox
这里还有一些先决条件,就是该batch中的batch_0上有3个标签,batch_1上有10个标签。num_queries默认设置为900,prepare_for_cdn的作用是在label和bbox上生成一定量的噪声数据,和后续的tgt一起输入到decoder中,细节在代码中有注释,就不展开了
def prepare_for_cdn(dn_args, training, num_queries, num_classes, hidden_dim, label_enc):
"""
A major difference of DINO from DN-DETR is that the author process pattern embedding pattern embedding in its detector
forward function and use learnable tgt embedding, so we change this function a little bit.
:param dn_args: targets, dn_number, label_noise_ratio, box_noise_scale
:param training: if it is training or inference
:param num_queries: number of queires
:param num_classes: number of classes
:param hidden_dim: transformer hidden dim
:param label_enc: encode labels in dn
:return:
"""
if training:
targets, dn_number, label_noise_ratio, box_noise_scale = dn_args # dn_number=100 label_noise_ratio=0.5 box_noise_scale=1.0
# positive and negative dn queries
dn_number = dn_number * 2
known = [(torch.ones_like(t['labels'])).cuda() for t in targets] #一个元素全为1的列表,根据batch中的label数进行初始化,假设两个batch,known长度为2,假设batch0的label数3,batch1的label数10 known=[tensor([1, 1, 1], device='cuda:0'),tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1], device='cuda:0')]
batch_size = len(known)
known_num = [sum(k) for k in known] # [tensor(3, device='cuda:0'),tensor(10, device='cuda:0')]
if int(max(known_num)) == 0:
dn_number = 1
else:
if dn_number >= 100:
dn_number = dn_number // (int(max(known_num) * 2)) # dn_number=20(根据batch中的最大label数动态设置,决定了去噪组数)
elif dn_number < 1:
dn_number = 1
if dn_number == 0:
dn_number = 1
unmask_bbox = unmask_label = torch.cat(known)
labels = torch.cat([t['labels'] for t in targets]) # 每个batch上所有label
boxes = torch.cat([t['boxes'] for t in targets]) # 每个batch上所有bbox
batch_idx = torch.cat([torch.full_like(t['labels'].long(), i) for i, t in enumerate(targets)]) # 每个label在batch上的索引 如:tensor([0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], device='cuda:0')
known_indice = torch.nonzero(unmask_label + unmask_bbox)
known_indice = known_indice.view(-1)
known_indice = known_indice.repeat(2 * dn_number, 1).view(-1)
known_labels = labels.repeat(2 * dn_number, 1).view(-1) # DN-DETR中设置scalar=5组去噪组数,这里使用2 * dn_number动态设置[2 * dn_number * len(labels)] [260]
known_bid = batch_idx.repeat(2 * dn_number, 1).view(-1) # [260]
known_bboxs = boxes.repeat(2 * dn_number, 1) # [260,4]
known_labels_expaned = known_labels.clone()
known_bbox_expand = known_bboxs.clone()
if label_noise_ratio > 0: # 随机初始化一个known_labels_expaned大小的张量([260]),挑出小于label_noise_ratio的索引生成chosen_indice,再随机生成chosen_indice大小的新类别,最后将新label按索引替换原始的label
p = torch.rand_like(known_labels_expaned.float())
chosen_indice = torch.nonzero(p < (label_noise_ratio * 0.5)).view(-1) # half of bbox prob
new_label = torch.randint_like(chosen_indice, 0, num_classes) # randomly put a new one here
known_labels_expaned.scatter_(0, chosen_indice, new_label)
single_pad = int(max(known_num)) # 表示在该batch中包含的最大的label数 如:10
pad_size = int(single_pad * 2 * dn_number)
positive_idx = torch.tensor(range(len(boxes))).long().cuda().unsqueeze(0).repeat(dn_number, 1) # [dn_number,len(boxes)] 如[10,13]
positive_idx += (torch.tensor(range(dn_number)) * len(boxes) * 2).long().cuda().unsqueeze(1)
positive_idx = positive_idx.flatten() # [dn_number,len(boxes)]
negative_idx = positive_idx + len(boxes) # positive_idx和negative_idx以len(boxes)长度为一组交替
if box_noise_scale > 0: # 将根known_bboxs转成xyxy形式存在known_bbox_中,据known_bboxs生成diff,按known_bboxs的shape生成随机数,按给定的公式将diff与该随机数(经过一系列处理)相乘后加在known_bbox_,最后将known_bbox_转成cxcywh形式
known_bbox_ = torch.zeros_like(known_bboxs) # [260,4]
known_bbox_[:, :2] = known_bboxs[:, :2] - known_bboxs[:, 2:] / 2
known_bbox_[:, 2:] = known_bboxs[:, :2] + known_bboxs[:, 2:] / 2 # 把known_bboxs转成xyxy形式
diff = torch.zeros_like(known_bboxs)
diff[:, :2] = known_bboxs[:, 2:] / 2
diff[:, 2:] = known_bboxs[:, 2:] / 2
rand_sign = torch.randint_like(known_bboxs, low=0, high=2, dtype=torch.float32) * 2.0 - 1.0
rand_part = torch.rand_like(known_bboxs)
rand_part[negative_idx] += 1.0 # negative_idx上的box都+1
rand_part *= rand_sign
known_bbox_ = known_bbox_ + torch.mul(rand_part,
diff).cuda() * box_noise_scale
known_bbox_ = known_bbox_.clamp(min=0.0, max=1.0)
known_bbox_expand[:, :2] = (known_bbox_[:, :2] + known_bbox_[:, 2:]) / 2
known_bbox_expand[:, 2:] = known_bbox_[:, 2:] - known_bbox_[:, :2] # 把known_bbox_转成cxcywh形式
# known_labels_expaned和known_bbox_expand为添加噪声之后的labels和bbox
m = known_labels_expaned.long().to('cuda')
input_label_embed = label_enc(m) # 对加入噪声的label进行编码 [260,256]
input_bbox_embed = inverse_sigmoid(known_bbox_expand)
padding_label = torch.zeros(pad_size, hidden_dim).cuda() # pad_size是个动态的变量,该batch中padding_label[200,256]全零tensor
padding_bbox = torch.zeros(pad_size, 4).cuda() # 该batch中padding_bbox[200,4]
input_query_label = padding_label.repeat(batch_size, 1, 1) # [single_pad * 2 * dn_number,256]即[200,256] -> [N,200,256]
input_query_bbox = padding_bbox.repeat(batch_size, 1, 1) # [200,4] -> [N,200,4]
map_known_indice = torch.tensor([]).to('cuda')
if len(known_num):
map_known_indice = torch.cat([torch.tensor(range(num)) for num in known_num]) # [1,2, 1,2,3] # 该batch中map_known_indice = tensor([0, 1, 2, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
map_known_indice = torch.cat([map_known_indice + single_pad * i for i in range(2 * dn_number)]).long() # [260]
if len(known_bid): # 将编码后的label和bbox按(known_bid.long(), map_known_indice)的索引插入到input_query中
input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed
input_query_bbox[(known_bid.long(), map_known_indice)] = input_bbox_embed
# 加入噪声后,还需要注意的一点便是信息之间的是否可见问题,噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起送入 transformer中的。
# 在 transformer 中,它们会经过 attention 交互,这势必会得知一些信息,这是作弊行为,是绝对不允许的
# 一、首先,如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries。
# 二、其次,不同 dn group 的 queries 也不能相互看到。因为综合所有组来看,gt -> query 是 one-to-many 的,每个 gt 在
# 每组都会有 1 个 query 拥有自己的信息。于是,对于每个 query 来说,在其它各组中都势必存在 1 个 query 拥有自己负责预测的那个 gt 的信息。
# 三、接着,同一个 dn group 的 queries 是可以相互看的 。因为在每组内,gt -> query 是 one-to-one 的关系,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息。
# 四、最后,DN 任务的 queries 可以去看匈牙利匹配任务的 queries ,因为只有前者才拥有 gt 信息,而后者是“凭空构造”的(主要是先验,需要自己去学习)。
# 总的来说,attention mask 的设计归纳为:
# 1、匈牙利匹配任务的 queries 不能看到 DN任务的 queries;
# 2、DN 任务中,不同组的 queries 不能相互看到;
# 3、其它情况均可见
tgt_size = pad_size + num_queries # single_pad * 2 * dn_number + 900
attn_mask = torch.ones(tgt_size, tgt_size).to('cuda') < 0
# match query cannot see the reconstruct
attn_mask[pad_size:, :pad_size] = True # 左下角 900 * single_pad * 2 * dn_number的区域为True
# reconstruct cannot see each other
for i in range(dn_number): # 分dn_number组,每组长度single_pad * 2
if i == 0:
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), single_pad * 2 * (i + 1):pad_size] = True
if i == dn_number - 1:
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), :single_pad * i * 2] = True
else:
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), single_pad * 2 * (i + 1):pad_size] = True
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), :single_pad * 2 * i] = True
dn_meta = {
'pad_size': pad_size,
'num_dn_group': dn_number,
}
else:
input_query_label = None
input_query_bbox = None
attn_mask = None
dn_meta = None
return input_query_label, input_query_bbox, attn_mask, dn_meta其中attn_mask:
tgt_size = pad_size + num_queries # single_pad * 2 * dn_number + 900
attn_mask = torch.ones(tgt_size, tgt_size).to('cuda') < 0
# match query cannot see the reconstruct
attn_mask[pad_size:, :pad_size] = True # 左下角 900 * single_pad * 2 * dn_number的区域为True
# reconstruct cannot see each other
for i in range(dn_number): # 分dn_number组,每组长度single_pad * 2
if i == 0:
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), single_pad * 2 * (i + 1):pad_size] = True
if i == dn_number - 1:
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), :single_pad * i * 2] = True
else:
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), single_pad * 2 * (i + 1):pad_size] = True
attn_mask[single_pad * 2 * i:single_pad * 2 * (i + 1), :single_pad * 2 * i] = True
此处假设single_pad为10,该single_pad表示在该batch中包含的最大的label个数。dn_number为分的去噪组数,这里dn_number为10,每组长度single_pad * 2
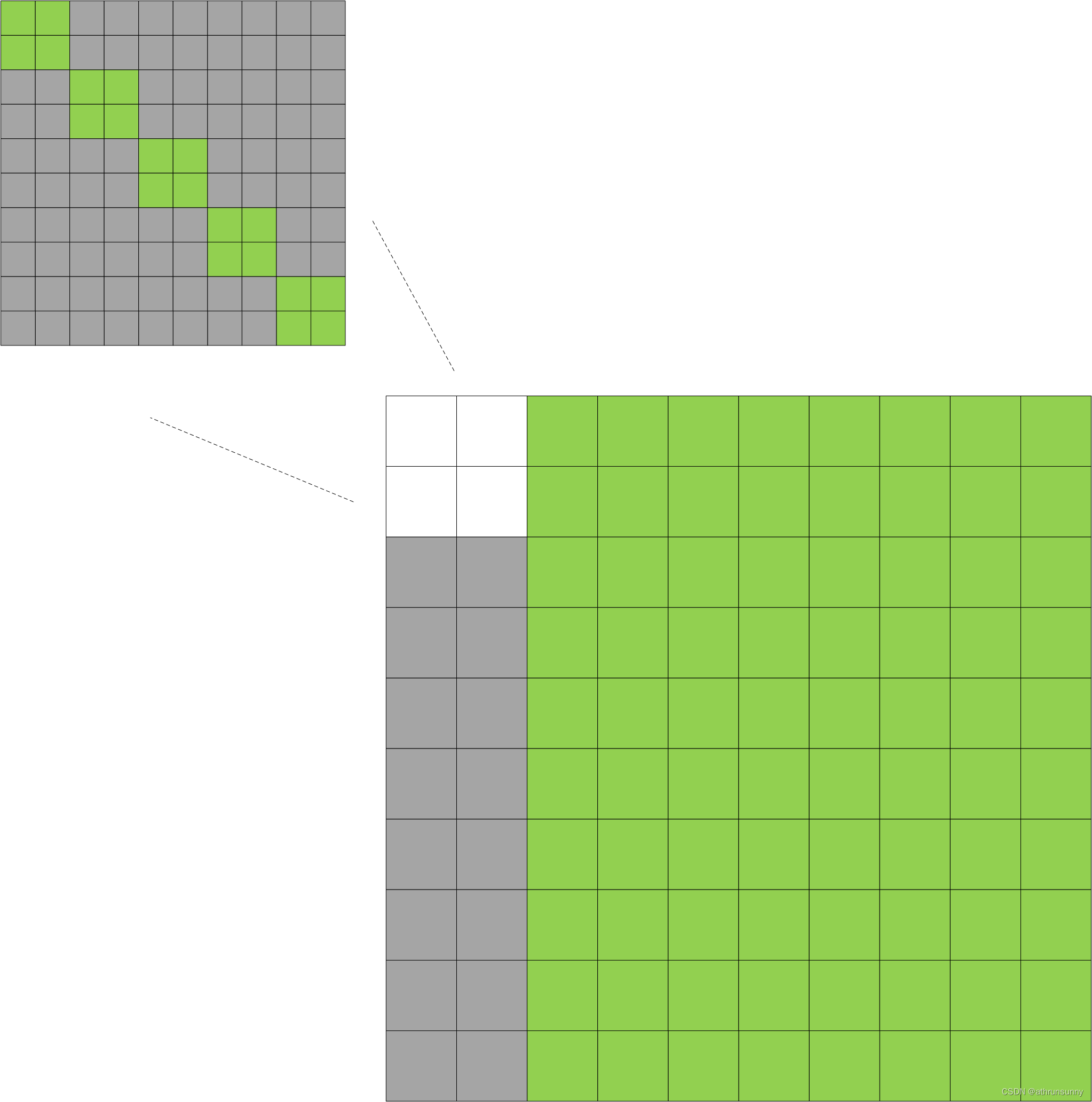
其中绿色部分表示为False,灰色部分表示为True。上图是个示意图,右下角的大图为[900 * single_pad * 2 * dn_number,900 * single_pad * 2 * dn_number],这里为[1100,1100]因为single_pad表示该batch中最大的标签数,为2,single_pad在上面提到过为10,左上的小图[single_pad * 2 * dn_number,single_pad * 2 * dn_number],这里为[200,200],分了dn_number(10)个去噪组,每组大小为single_pad * 2=20。
DINO完整代码(未展开transformer):
class DINO(nn.Module):
""" This is the Cross-Attention Detector module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries,
aux_loss=False, iter_update=False,
query_dim=2,
random_refpoints_xy=False,
fix_refpoints_hw=-1,
num_feature_levels=1,
nheads=8,
# two stage
two_stage_type='no', # ['no', 'standard']
two_stage_add_query_num=0,
dec_pred_class_embed_share=True,
dec_pred_bbox_embed_share=True,
two_stage_class_embed_share=True,
two_stage_bbox_embed_share=True,
decoder_sa_type = 'sa',
num_patterns = 0,
dn_number = 100,
dn_box_noise_scale = 0.4,
dn_label_noise_ratio = 0.5,
dn_labelbook_size = 100,
):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
Conditional DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
fix_refpoints_hw: -1(default): learn w and h for each box seperately
>0 : given fixed number
-2 : learn a shared w and h
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
self.num_classes = num_classes
self.hidden_dim = hidden_dim = transformer.d_model
self.num_feature_levels = num_feature_levels
self.nheads = nheads
self.label_enc = nn.Embedding(dn_labelbook_size + 1, hidden_dim)
# setting query dim
self.query_dim = query_dim
assert query_dim == 4
self.random_refpoints_xy = random_refpoints_xy
self.fix_refpoints_hw = fix_refpoints_hw
# for dn training
self.num_patterns = num_patterns
self.dn_number = dn_number
self.dn_box_noise_scale = dn_box_noise_scale
self.dn_label_noise_ratio = dn_label_noise_ratio
self.dn_labelbook_size = dn_labelbook_size
# prepare input projection layers
if num_feature_levels > 1:
num_backbone_outs = len(backbone.num_channels)
input_proj_list = []
for _ in range(num_backbone_outs):
in_channels = backbone.num_channels[_]
input_proj_list.append(nn.Sequential(
nn.Conv2d(in_channels, hidden_dim, kernel_size=1),
nn.GroupNorm(32, hidden_dim),
))
for _ in range(num_feature_levels - num_backbone_outs):
input_proj_list.append(nn.Sequential(
nn.Conv2d(in_channels, hidden_dim, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(32, hidden_dim),
))
in_channels = hidden_dim
self.input_proj = nn.ModuleList(input_proj_list)
else:
assert two_stage_type == 'no', "two_stage_type should be no if num_feature_levels=1 !!!"
self.input_proj = nn.ModuleList([
nn.Sequential(
nn.Conv2d(backbone.num_channels[-1], hidden_dim, kernel_size=1),
nn.GroupNorm(32, hidden_dim),
)])
self.backbone = backbone
self.aux_loss = aux_loss
self.box_pred_damping = box_pred_damping = None
self.iter_update = iter_update
assert iter_update, "Why not iter_update?"
# prepare pred layers
self.dec_pred_class_embed_share = dec_pred_class_embed_share
self.dec_pred_bbox_embed_share = dec_pred_bbox_embed_share
# prepare class & box embed
_class_embed = nn.Linear(hidden_dim, num_classes)
_bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
# init the two embed layers
prior_prob = 0.01
bias_value = -math.log((1 - prior_prob) / prior_prob)
_class_embed.bias.data = torch.ones(self.num_classes) * bias_value
nn.init.constant_(_bbox_embed.layers[-1].weight.data, 0)
nn.init.constant_(_bbox_embed.layers[-1].bias.data, 0)
if dec_pred_bbox_embed_share:
box_embed_layerlist = [_bbox_embed for i in range(transformer.num_decoder_layers)]
else:
box_embed_layerlist = [copy.deepcopy(_bbox_embed) for i in range(transformer.num_decoder_layers)]
if dec_pred_class_embed_share:
class_embed_layerlist = [_class_embed for i in range(transformer.num_decoder_layers)]
else:
class_embed_layerlist = [copy.deepcopy(_class_embed) for i in range(transformer.num_decoder_layers)]
self.bbox_embed = nn.ModuleList(box_embed_layerlist)
self.class_embed = nn.ModuleList(class_embed_layerlist)
self.transformer.decoder.bbox_embed = self.bbox_embed
self.transformer.decoder.class_embed = self.class_embed
# two stage
self.two_stage_type = two_stage_type
self.two_stage_add_query_num = two_stage_add_query_num
assert two_stage_type in ['no', 'standard'], "unknown param {} of two_stage_type".format(two_stage_type)
if two_stage_type != 'no':
if two_stage_bbox_embed_share:
assert dec_pred_class_embed_share and dec_pred_bbox_embed_share
self.transformer.enc_out_bbox_embed = _bbox_embed
else:
self.transformer.enc_out_bbox_embed = copy.deepcopy(_bbox_embed)
if two_stage_class_embed_share:
assert dec_pred_class_embed_share and dec_pred_bbox_embed_share
self.transformer.enc_out_class_embed = _class_embed
else:
self.transformer.enc_out_class_embed = copy.deepcopy(_class_embed)
self.refpoint_embed = None
if self.two_stage_add_query_num > 0:
self.init_ref_points(two_stage_add_query_num)
self.decoder_sa_type = decoder_sa_type
assert decoder_sa_type in ['sa', 'ca_label', 'ca_content']
if decoder_sa_type == 'ca_label':
self.label_embedding = nn.Embedding(num_classes, hidden_dim)
for layer in self.transformer.decoder.layers:
layer.label_embedding = self.label_embedding
else:
for layer in self.transformer.decoder.layers:
layer.label_embedding = None
self.label_embedding = None
self._reset_parameters()
def _reset_parameters(self):
# init input_proj
for proj in self.input_proj:
nn.init.xavier_uniform_(proj[0].weight, gain=1)
nn.init.constant_(proj[0].bias, 0)
def init_ref_points(self, use_num_queries):
self.refpoint_embed = nn.Embedding(use_num_queries, self.query_dim)
if self.random_refpoints_xy:
self.refpoint_embed.weight.data[:, :2].uniform_(0,1)
self.refpoint_embed.weight.data[:, :2] = inverse_sigmoid(self.refpoint_embed.weight.data[:, :2])
self.refpoint_embed.weight.data[:, :2].requires_grad = False
if self.fix_refpoints_hw > 0:
print("fix_refpoints_hw: {}".format(self.fix_refpoints_hw))
assert self.random_refpoints_xy
self.refpoint_embed.weight.data[:, 2:] = self.fix_refpoints_hw
self.refpoint_embed.weight.data[:, 2:] = inverse_sigmoid(self.refpoint_embed.weight.data[:, 2:])
self.refpoint_embed.weight.data[:, 2:].requires_grad = False
elif int(self.fix_refpoints_hw) == -1:
pass
elif int(self.fix_refpoints_hw) == -2:
print('learn a shared h and w')
assert self.random_refpoints_xy
self.refpoint_embed = nn.Embedding(use_num_queries, 2)
self.refpoint_embed.weight.data[:, :2].uniform_(0,1)
self.refpoint_embed.weight.data[:, :2] = inverse_sigmoid(self.refpoint_embed.weight.data[:, :2])
self.refpoint_embed.weight.data[:, :2].requires_grad = False
self.hw_embed = nn.Embedding(1, 1)
else:
raise NotImplementedError('Unknown fix_refpoints_hw {}'.format(self.fix_refpoints_hw))
def forward(self, samples: NestedTensor, targets:List=None):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x num_classes]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, width, height). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, poss = self.backbone(samples)
srcs = []
masks = []
for l, feat in enumerate(features):
src, mask = feat.decompose()
srcs.append(self.input_proj[l](src)) # 每一层的feature map通过1*1的卷积进行降维[N,512/1024/2048,H,W] -> [N,256,H,W],此处的H和W为对应层的feature map的尺寸
masks.append(mask) # mask的维度始终为[N,H,W]
assert mask is not None
if self.num_feature_levels > len(srcs):
_len_srcs = len(srcs)
for l in range(_len_srcs, self.num_feature_levels):
if l == _len_srcs:
src = self.input_proj[l](features[-1].tensors) # 取feature map的最后一层(最小的feature map)进行步长为2的3*3卷积降采样[N,2048,H,W] -> [N,256,H//2,W//2]
else:
src = self.input_proj[l](srcs[-1])
m = samples.mask
mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0] # 对最后一层的feature map做完3*3卷积后,需要得到对应的mask
pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype) # 前三层的mask的位置编码在backbone的前向过程中已经得到了,这里单独对第四层的mask做位置编码
srcs.append(src)
masks.append(mask)
poss.append(pos_l)
# 到这里就得到了四个尺度上的输出,假设输入大小为[N,640,701]那么输出的src为[[N,256,80,88],[N,256,40,44],[N,256,20,22],[N,256,10,11]],masks为[[N,80,88],[N,40,44],[N,20,22],[N,10,11]],poss为[[N,256,80,88],[N,256,40,44],[N,256,20,22],[N,256,10,11]]
if self.dn_number > 0 or targets is not None:
input_query_label, input_query_bbox, attn_mask, dn_meta =\
prepare_for_cdn(dn_args=(targets, self.dn_number, self.dn_label_noise_ratio, self.dn_box_noise_scale),
training=self.training,num_queries=self.num_queries,num_classes=self.num_classes,
hidden_dim=self.hidden_dim,label_enc=self.label_enc)
else:
assert targets is None
input_query_bbox = input_query_label = attn_mask = dn_meta = None
# input_query_bbox [N,single_pad * 2 * dn_number,256](该batch中[N,200,256]); input_query_label [N,200,4];attn_mask [single_pad * 2 * dn_number + 900,single_pad * 2 * dn_number + 900](该batch中[1100,1100])
hs, reference, hs_enc, ref_enc, init_box_proposal = self.transformer(srcs, masks, input_query_bbox, poss,input_query_label,attn_mask)
# In case num object=0 hs [N,1100,256]*6, reference [N,1100,4]*7, hs_enc [1,N,900,256], ref_enc [1,N,900,4], init_box_proposal [N,900,4]
hs[0] += self.label_enc.weight[0,0]*0.0
# deformable-detr-like anchor update
# reference_before_sigmoid = inverse_sigmoid(reference[:-1]) # n_dec, bs, nq, 4
outputs_coord_list = []
for dec_lid, (layer_ref_sig, layer_bbox_embed, layer_hs) in enumerate(zip(reference[:-1], self.bbox_embed, hs)):
layer_delta_unsig = layer_bbox_embed(layer_hs) # layer_bbox_embed Linear(256,256) Linear(256,256) Linear(256,4) [N,1100,4]
layer_outputs_unsig = layer_delta_unsig + inverse_sigmoid(layer_ref_sig)
layer_outputs_unsig = layer_outputs_unsig.sigmoid()
outputs_coord_list.append(layer_outputs_unsig)
outputs_coord_list = torch.stack(outputs_coord_list) # [6,N,1100,4]
outputs_class = torch.stack([layer_cls_embed(layer_hs) for
layer_cls_embed, layer_hs in zip(self.class_embed, hs)]) # layer_cls_embed Linear(256,91) outputs_class [6,N,1100,91]
if self.dn_number > 0 and dn_meta is not None:
outputs_class, outputs_coord_list = \
dn_post_process(outputs_class, outputs_coord_list,
dn_meta,self.aux_loss,self._set_aux_loss)
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord_list[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord_list)
# for encoder output
if hs_enc is not None:
# prepare intermediate outputs
interm_coord = ref_enc[-1] # [N,900,4]
interm_class = self.transformer.enc_out_class_embed(hs_enc[-1]) # Linear(256,91) [N,900,91]
out['interm_outputs'] = {'pred_logits': interm_class, 'pred_boxes': interm_coord}
out['interm_outputs_for_matching_pre'] = {'pred_logits': interm_class, 'pred_boxes': init_box_proposal}
# prepare enc outputs
if hs_enc.shape[0] > 1:
enc_outputs_coord = []
enc_outputs_class = []
for layer_id, (layer_box_embed, layer_class_embed, layer_hs_enc, layer_ref_enc) in enumerate(zip(self.enc_bbox_embed, self.enc_class_embed, hs_enc[:-1], ref_enc[:-1])):
layer_enc_delta_unsig = layer_box_embed(layer_hs_enc)
layer_enc_outputs_coord_unsig = layer_enc_delta_unsig + inverse_sigmoid(layer_ref_enc)
layer_enc_outputs_coord = layer_enc_outputs_coord_unsig.sigmoid()
layer_enc_outputs_class = layer_class_embed(layer_hs_enc)
enc_outputs_coord.append(layer_enc_outputs_coord)
enc_outputs_class.append(layer_enc_outputs_class)
out['enc_outputs'] = [
{'pred_logits': a, 'pred_boxes': b} for a, b in zip(enc_outputs_class, enc_outputs_coord)
]
out['dn_meta'] = dn_meta
return out
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]DINO的内容有点多,encoder和decoder以及loss部分后续更新