官方网站:柏码 - 让每一行代码都闪耀智慧的光芒! (itbaima.net)
p1:前言,走进微服务
注意:此阶段学习推荐的电脑配置,至少配备4核心CPU(主频3.0Ghz以上)+16GB内存,否则卡到你怀疑人生。
前面我们讲解了SpringBoot框架,通过使用SpringBoot框架,我们的项目开发速度可以说是得到了质的提升。同时,我们对于项目的维护和理解,也会更加的轻松。可见,SpringBoot为我们的开发带来了巨大便捷。而这一部分,我们将基于SpringBoot,继续深入到企业实际场景,探讨微服务架构下的SpringCloud。这个部分我们会更加注重于架构设计上的讲解,弱化实现原理方面的研究。
传统项目转型
要说近几年最火热的话题,那还得是微服务,那么什么是微服务呢?
我们可以先从技术的演变开始看起,在我们学习JavaWeb之后,一般的网站开发模式为Servlet+JSP,但是实际上我们在学习了SSM之后,会发现这种模式已经远远落后了,第一,一个公司不可能去招那么多同时会前端+后端的开发人员,就算招到,也并不一定能保证两个方面都比较擅长,相比前后端分开学习的开发人员,显然后者的学习成本更低,专注度更高。因此前后端分离成为了一种新的趋势。通过使用SpringBoot,我们几乎可以很快速地开发一个高性能的单体应用,只需要启动一个服务端,我们整个项目就开始运行了,各项功能融于一体,开发起来也更加轻松。
但是随着我们项目的不断扩大,单体应用似乎显得有点乏力了。
随着越来越多的功能不断地加入到一个SpringBoot项目中,随着接口不断增加,整个系统就要在同一时间内响应更多类型的请求,显然,这种扩展方式是不可能无限使用下去的,总有一天,这个SpringBoot项目会庞大到运行缓慢。并且所有的功能如果都集成在单端上,那么所有的请求都会全部汇集到一台服务器上,对此服务器造成巨大压力。
可以试想一下,如果我们的电脑已经升级到i9-12900K,但是依然在运行项目的时候缓慢,无法同一时间响应成千上万的请求,那么这个问题就已经不是单纯升级机器配置可以解决的了。
传统单体架构应用随着项目规模的扩大,实际上会暴露越来越多的问题,尤其是一台服务器无法承受庞大的单体应用部署,并且单体应用的维护也会越来越困难,我们得寻找一种新的开发架构来解决这些问题了。
Martin Fowler在2014年提出了“微服务”架构,它是一种全新的架构风格。
- 微服务把一个庞大的单体应用拆分为一个个的小型服务,比如我们原来的图书管理项目中,有登录、注册、添加、删除、搜索等功能,那么我们可以将这些功能单独做成一个个小型的SpringBoot项目,独立运行。
- 每个小型的微服务,都可以独立部署和升级,这样,就算整个系统崩溃,那么也只会影响一个服务的运行。
- 微服务之间使用HTTP进行数据交互,不再是单体应用内部交互了,虽然这样会显得更麻烦,但是带来的好处也是很直接的,甚至能突破语言限制,使用不同的编程语言进行微服务开发,只需要使用HTTP进行数据交互即可。
- 我们可以同时购买多台主机来分别部署这些微服务,这样,单机的压力就被分散到多台机器,并且每台机器的配置不一定需要太高,这样就能节省大量的成本,同时安全性也得到很大的保证。
- 甚至同一个微服务可以同时存在多个,这样当其中一个服务器出现问题时,其他服务器也在运行同样的微服务,这样就可以保证一个微服务的高可用。
当然,这里只是简单的演示一下微服务架构,实际开发中肯定是比这个复杂得多的。
可见,采用微服务架构,更加能够应对当今时代下的种种考验,传统项目的开发模式,需要进行架构上的升级。
-------------------------------------------------------------------------------------------------------------------------
P2:认识SpringCloud
走进SpringCloud
前面我们介绍了微服务架构的优点,那么同样的,这些优点的背后也存在着诸多的问题:
- 要实现微服务并不是说只需要简单地将项目进行拆分,我们还需要考虑对各个微服务进行管理、监控等,这样我们才能够及时地寻找和排查问题。因此微服务往往需要的是一整套解决方案,包括服务注册和发现、容灾处理、负载均衡、配置管理等。
- 它不像单体架构那种方便维护,由于部署在多个服务器,我们不得不去保证各个微服务能够稳定运行,在管理难度上肯定是高于传统单体应用的。
- 在分布式的环境下,单体应用的某些功能可能会变得比较麻烦,比如分布式事务。
所以,为了更好地解决这些问题,SpringCloud正式登场。
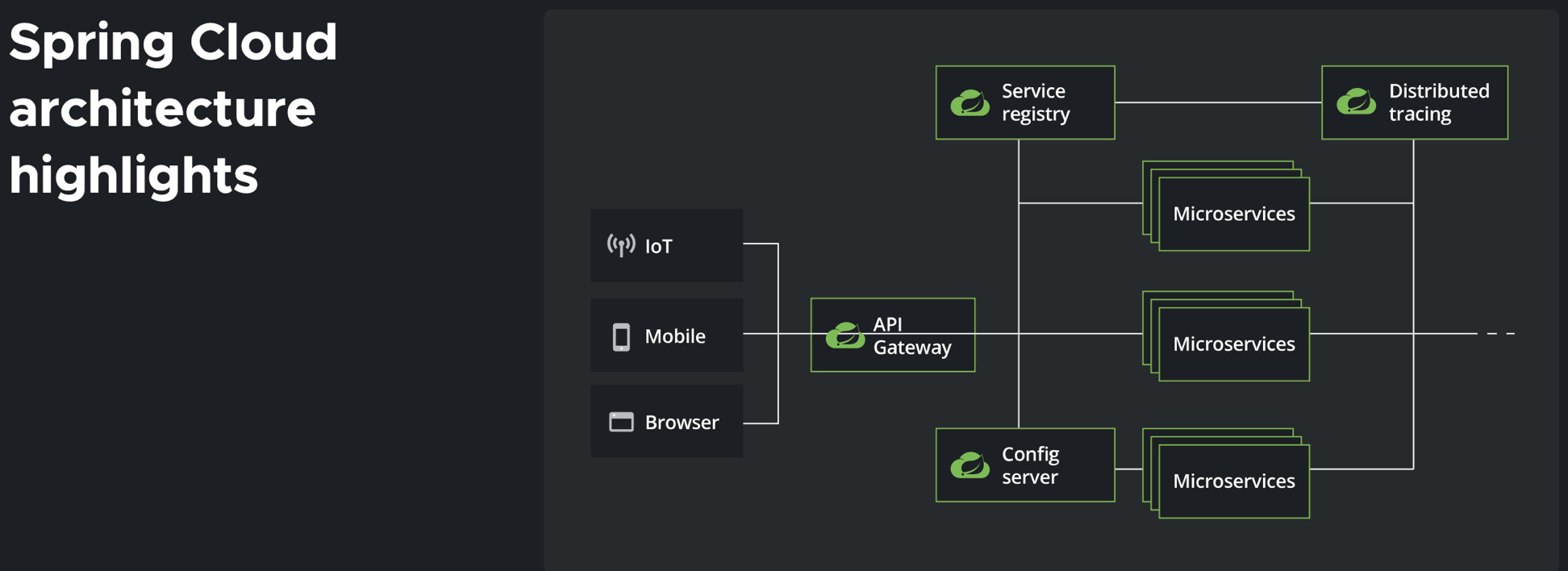
SpringCloud是Spring提供的一套分布式解决方案,集合了一些大型互联网公司的开源产品,包括诸多组件,共同组成SpringCloud框架。并且,它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、熔断机制、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
由于中小型公司没有独立开发自己的分布式基础设施的能力,使用SpringCloud解决方案能够以最低的成本应对当前时代的业务发展。
可以看到,SpringCloud整体架构的亮点是非常明显的,分布式架构下的各个场景,都有对应的组件来处理,比如基于Netflix(奈飞)的开源分布式解决方案提供的组件:
- Eureka - 实现服务治理(服务注册与发现),我们可以对所有的微服务进行集中管理,包括他们的运行状态、信息等。
- Ribbon - 为服务之间相互调用提供负载均衡算法(现在被SpringCloudLoadBalancer取代)
- Hystrix - 断路器,保护系统,控制故障范围。暂时可以跟家里电闸的保险丝类比,当触电危险发生时能够防止进一步的发展。
- Zuul - api网关,路由,负载均衡等多种作用,就像我们的路由器,可能有很多个设备都连接了路由器,但是数据包要转发给谁则是由路由器在进行(已经被SpringCloudGateway取代)
- Config - 配置管理,可以实现配置文件集中管理
当然,这里只是进行简单的了解即可,实际上微服务的玩法非常多,我们后面的学习中将会逐步进行探索。
那么首先,我们就从注册中心开始说起。
-------------------------------------------------------------------------------------------------------------------------
p3:微服务项目搭建(一)
Eureka 注册中心
官方文档:Spring Cloud Netflix
小贴士:各位小伙伴在学习的过程中觉得有什么疑惑的可以直接查阅官方文档,我们会在每一个技术开始之前贴上官方文档的地址,方便各位进行查阅,同时在我们的课程中并不一定会完完整整地讲完整个框架的内容,有关详细的功能和使用方法文档中也是写的非常清楚的,感兴趣的可以深入学习哦。
微服务项目结构
现在我们重新设计一下之前的图书管理系统项目,将原有的大型(也许 项目进行拆分,注意项目拆分一定要尽可能保证单一职责,相同的业务不要在多个微服务中重复出现,如果出现需要借助其他业务完成的服务,那么可以使用服务之间相互调用的形式来实现(之后会介绍):
- 登录验证服务:用于处理用户注册、登录、密码重置等,反正就是一切与账户相关的内容,包括用户信息获取等。
- 图书管理服务:用于进行图书添加、删除、更新等操作,图书管理相关的服务,包括图书的存储等和信息获取。
- 图书借阅服务:交互性比较强的服务,需要和登陆验证服务和图书管理服务进行交互。
那么既然要将单体应用拆分为多个小型服务,我们就需要重新设计一下整个项目目录结构,这里我们就创建多个子项目,每一个子项目都是一个服务,这样由父项目统一管理依赖,就无需每个子项目都去单独管理依赖了,也更方便一点。
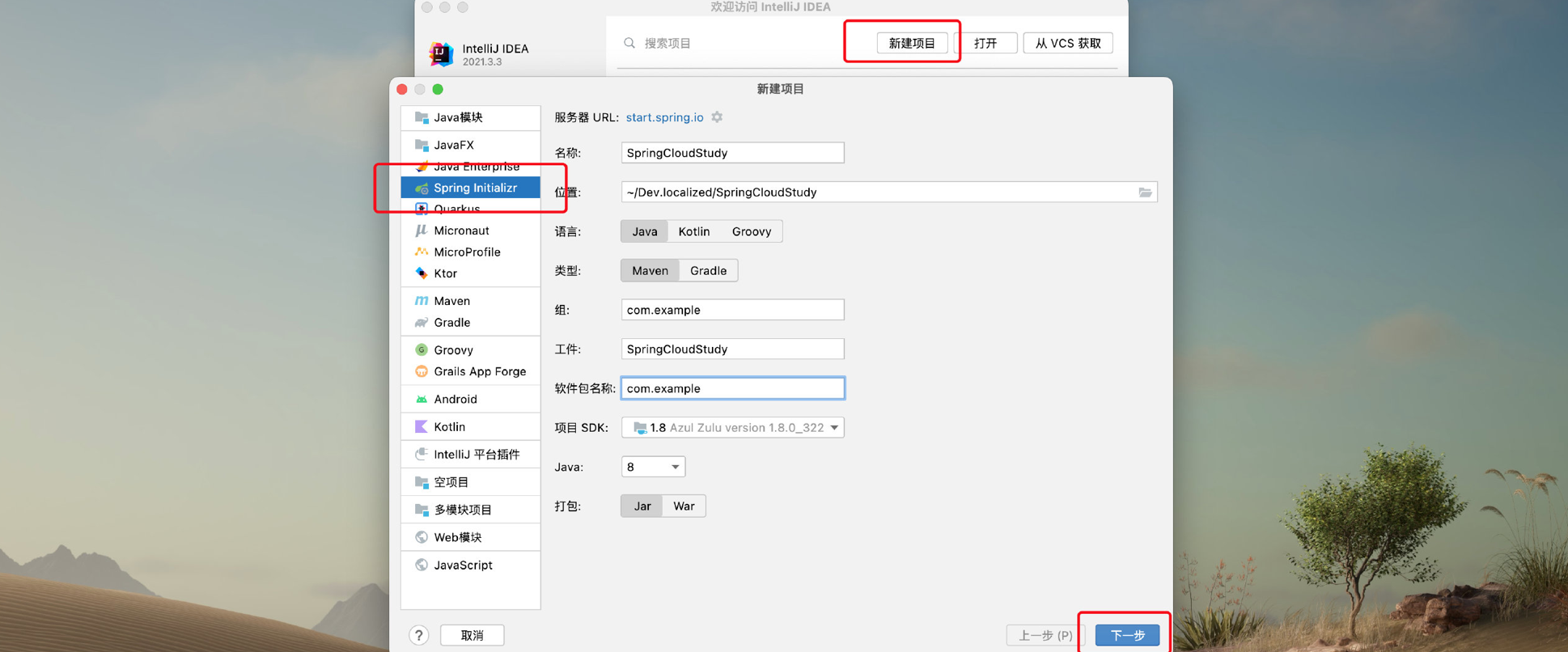
我们首先创建一个普通的SpringBoot项目:
然后不需要勾选任何依赖,直接创建即可,项目创建完成并初始化后,我们删除父工程的无用文件,只保留必要文件,像下面这样:
接着我们就可以按照我们划分的服务,进行子工程创建了,创建一个新的Maven项目,注意父项目要指定为我们一开始创建的的项目,子项目命名随意:
子项目创建好之后,接着我们在子项目中创建SpringBoot的启动主类:
接着我们点击运行,即可启动子项目了,实际上这个子项目就一个最简单的SpringBoot web项目,注意启动之后最下方有弹窗,我们点击"使用 服务",这样我们就可以实时查看当前整个大项目中有哪些微服务了:
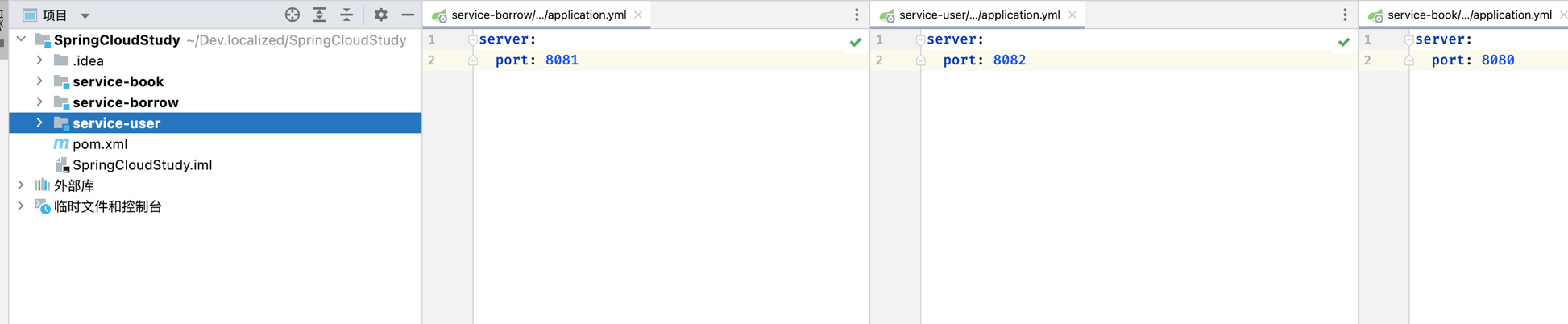
接着我们以同样的方法,创建其他的子项目,注意我们最好将其他子项目的端口设置得不一样,不然会导致端口占用,我们分别为它们创建
application.yml文件:
接着我们来尝试启动一下这三个服务,正常情况下都是可以直接启动的:
可以看到它们分别运行在不同的端口上,这样,就方便不同的程序员编写不同的服务了,提交当前项目代码时的冲突率也会降低。
P4:微服务项目搭建(二)
接着我们来创建一下数据库,这里还是老样子,创建三个表即可,当然实际上每个微服务单独使用一个数据库服务器也是可以的,因为按照单一职责服务只会操作自己对应的表,这里UP主比较穷,就只用一个数据库演示了:
创建好之后,结果如下,一共三张表,各位可以自行添加一些数据到里面,这就不贴出来了:
接着我们来稍微写一点业务,比如用户信息查询业务,我们先把数据库相关的依赖进行导入,这里依然使用Mybatis框架,首先在父项目中添加MySQL驱动和Lombok依赖:
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency>由于不是所有的子项目都需要用到Mybatis,我们在父项目中只进行版本管理即可:
<dependencyManagement> <dependencies> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.2.0</version> </dependency> </dependencies> </dependencyManagement>接着我们就可以在用户服务子项目中添加此依赖了:
<dependencies> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> </dependency> </dependencies>接着添加数据源信息(UP用到是阿里云的MySQL云数据库,各位注意修改一下数据库地址):
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://cloudstudy.mysql.cn-chengdu.rds.aliyuncs.com:3306/cloudstudy username: test password: 123456接着我们来写用户查询相关的业务:
@Data public class User { int uid; String name; String sex; }@Mapper public interface UserMapper { @Select("select * from DB_USER where uid = #{uid}") User getUserById(int uid); }public interface UserService { User getUserById(int uid); }@Service public class UserServiceImpl implements UserService { @Resource UserMapper mapper; @Override public User getUserById(int uid) { return mapper.getUserById(uid); } }@RestController public class UserController { @Resource UserService service; //这里以RESTFul风格为例 @RequestMapping("/user/{uid}") public User findUserById(@PathVariable("uid") int uid){ return service.getUserById(uid); } }现在我们访问即可拿到数据:
同样的方式,我们完成一下图书查询业务,注意现在是在图书管理微服务中编写(别忘了导入Mybatis依赖以及配置数据源):
@Data public class Book { int bid; String title; String desc; }@Mapper public interface BookMapper { @Select("select * from DB_BOOK where bid = #{bid}") Book getBookById(int bid); }public interface BookService { Book getBookById(int bid); }@Service public class BookServiceImpl implements BookService { @Resource BookMapper mapper; @Override public Book getBookById(int bid) { return mapper.getBookById(bid); } }@RestController public class BookController { @Resource BookService service; @RequestMapping("/book/{bid}") Book findBookById(@PathVariable("bid") int bid){ return service.getBookById(bid); } }同样进行一下测试:
-------------------------------------------------------------------------------------------------------------------------
P5:微服务项目搭建(三)
前面我们完成了用户信息查询和图书信息查询,现在我们来接着完成借阅服务。
借阅服务是一个关联性比较强的服务,它不仅仅需要查询借阅信息,同时可能还需要获取借阅信息下的详细信息,比如具体那个用户借阅了哪本书,并且用户和书籍的详情也需要同时出现,那么这种情况下,我们就需要去访问除了借阅表以外的用户表和图书表。
但是这显然是违反我们之前所说的单一职责的,相同的业务功能不应该重复出现,但是现在由需要在此服务中查询用户的信息和图书信息,那怎么办呢?我们可以让一个服务去调用另一个服务来获取信息。
这样,图书管理微服务和用户管理微服务相对于借阅记录,就形成了一个生产者和消费者的关系,前者是生产者,后者便是消费者。
现在我们先将借阅关联信息查询完善了:
@Data public class Borrow { int id; int uid; int bid; }@Mapper public interface BorrowMapper { @Select("select * from DB_BORROW where uid = #{uid}") List<Borrow> getBorrowsByUid(int uid); @Select("select * from DB_BORROW where bid = #{bid}") List<Borrow> getBorrowsByBid(int bid); @Select("select * from DB_BORROW where bid = #{bid} and uid = #{uid}") Borrow getBorrow(int uid, int bid); }现在有一个需求,需要查询用户的借阅详细信息,也就是说需要查询某个用户具体借了那些书,并且需要此用户的信息和所有已借阅的书籍信息一起返回,那么我们先来设计一下返回实体:
@Data @AllArgsConstructor public class UserBorrowDetail { User user; List<Book> bookList; }但是有一个问题,我们发现User和Book实体实际上是在另外两个微服务中定义的,相当于当前项目并没有定义这些实体类,那么怎么解决呢?
因此,我们可以将所有服务需要用到的实体类单独放入另一个一个项目中,然后让这些项目引用集中存放实体类的那个项目,这样就可以保证每个微服务的实体类信息都可以共用了:
然后只需要在对应的类中引用此项目作为依赖即可:
<dependency> <groupId>com.example</groupId> <artifactId>commons</artifactId> <version>0.0.1-SNAPSHOT</version> </dependency>之后新的公共实体类都可以在
commons项目中进行定义了,现在我们接着来完成刚刚的需求,先定义接口:public interface BorrowService { UserBorrowDetail getUserBorrowDetailByUid(int uid); }@Service public class BorrowServiceImpl implements BorrowService{ @Resource BorrowMapper mapper; @Override public UserBorrowDetail getUserBorrowDetailByUid(int uid) { List<Borrow> borrow = mapper.getBorrowsByUid(uid); //那么问题来了,现在拿到借阅关联信息了,怎么调用其他服务获取信息呢? } }需要进行服务远程调用我们需要用到
RestTemplate来进行:@Service public class BorrowServiceImpl implements BorrowService{ @Resource BorrowMapper mapper; @Override public UserBorrowDetail getUserBorrowDetailByUid(int uid) { List<Borrow> borrow = mapper.getBorrowsByUid(uid); //RestTemplate支持多种方式的远程调用 RestTemplate template = new RestTemplate(); //这里通过调用getForObject来请求其他服务,并将结果自动进行封装 //获取User信息 User user = template.getForObject("http://localhost:8082/user/"+uid, User.class); //获取每一本书的详细信息 List<Book> bookList = borrow .stream() .map(b -> template.getForObject("http://localhost:8080/book/"+b.getBid(), Book.class)) .collect(Collectors.toList()); return new UserBorrowDetail(user, bookList); } }现在我们再最后完善一下Controller:
@RestController public class BorrowController { @Resource BorrowService service; @RequestMapping("/borrow/{uid}") UserBorrowDetail findUserBorrows(@PathVariable("uid") int uid){ return service.getUserBorrowDetailByUid(uid); } }在数据库中添加一点借阅信息,测试看看能不能正常获取(注意一定要保证三个服务都处于开启状态,否则远程调用会失败):
可以看到,结果正常,没有问题,远程调用成功。
这样,一个简易的图书管理系统的分布式项目就搭建完成了,这里记得把整个项目压缩打包备份一下,下一章学习SpringCloud Alibaba也需要进行配置。
SpringCloud_微服务基础day1(走进微服务,认识springcloud,微服务(图书管理)项目搭建(一))
news2026/2/16 8:05:18






















本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/608605.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【CH32V】CH32V307驱动4P_OLED
前言 手上正好有 CH32V307 的板子就耍耍,网上4P的OLED例程也不少 4P OLED 屏驱动例程。在加上一些 STM32 标准库的知识,改改引脚定义,就可以将 OLED 屏连接到板子上进行显示了。当然,我也将会分享我整理好的库文件代码和完整的工程…

【22】SCI易中期刊推荐——计算机 | 人工智能(中科院4区)
🍀🍀>>>【YOLO魔法搭配&论文投稿咨询】<<<🍀🍀
✨✨>>>学习交流 | 温澜潮生 | 合作共赢 | 共同进步<<<✨✨
📚📚>>>人工智能 | 计算机视觉 | 深度学习Tricks | 第一时间送达<<<📚📚 🚀🚀🚀…
【java 基础二 】- 面向对象、类、接口等
一、定义
Java面向对象编程(OOP)是一种编程范式,其旨在通过将程序逻辑封装在对象中来使代码更易于理解和维护。Java是一种面向对象的编程语言,它支持封装、继承和多态等概念。以下是Java面向对象编程的核心概念:
对象(Object):对…
Linux进程间通信——管道,共享内存,消息队列,信号量
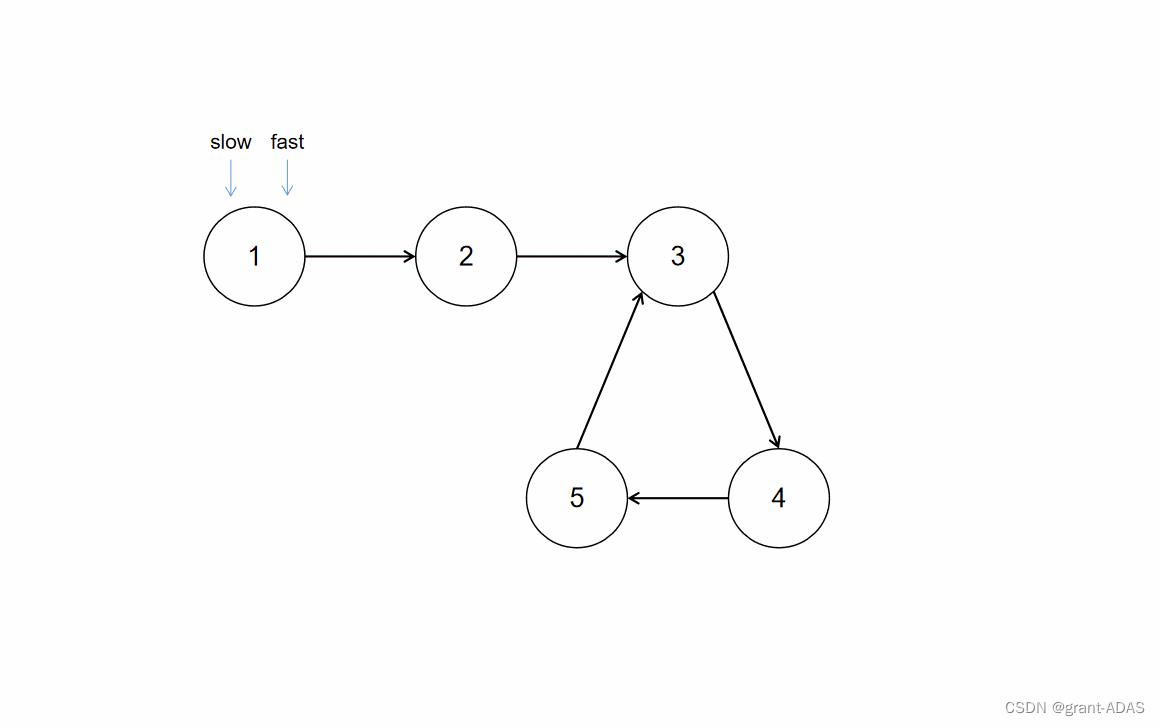
进程间通信 文章目录 进程间通信进程间通信的方式进程间通信的概念如何实现进程间通信管道什么是管道 进程间怎么通信 匿名管道pipe函数创建管道通信读写特征写慢读快写快读慢写端关闭,读端读完读端关闭,写端? 管道特征 命名管道命名管道特性…
近期学习论文总结 2
公众号:EDPJ 目录
0. 摘要
1. Artificial Fingerprinting for Generative Models: Rooting Deepfake Attribution in Training Data
1.1 核心思想
1.2 步骤
2. HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks
2.1 核心思想…
使用Chat gpt提高Android开发效率
简介
在过去几周里,我进行了一项令人大开眼界的实验,将 Chat-GPT(我使用的是 Bing Chat,它在后台使用了 GPT-4,并且可以免费使用)融入到我的日常 Android 开发工作流程中,以探索它是否能够提高…
黑马Redis视频教程高级篇(安装OpenResty)
目录
一、安装
1.1、安装开发库
1.2、安装OpenResty仓库
1.3、安装OpenResty
1.4、安装opm工具
1.5、目录结构
1.6、配置nginx的环境变量
二、启动和运行
三、备注 一、安装
首先你的Linux虚拟机必须联网。
1.1、安装开发库
首先要安装OpenResty的依赖开发库&#…

Spring Bean生命周期之三级缓存循环依赖
文章目录 1 三级缓存1.1 引言1.2 三级缓存各个存放对象1.3 解决循环依赖条件1.3.1 解决循环依赖条件1.3.2 Sprin中Bean的顺序1.3.3 更改加载顺序1.3.3.1 构造方法依赖 (推荐)1.3.3.2 参数注入1.3.3.3 DependsOn(“xxx”)1.3.3.4 BeanDefinitionRegistryPostProcessor接口 1.3.4…
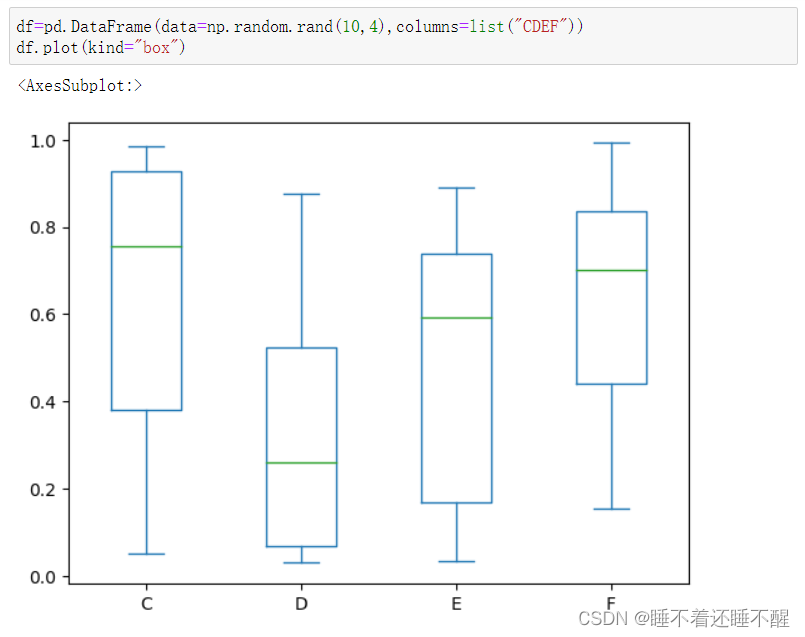
Pandas从入门到精通
一、什么是Pandas
Pandas是基于NumPy的一种工具,该工具是为解决数据分析任务而创建的,Pandas提供了大量能使我们快速便捷的处理数据的功能
Pandas与出色的Jupyter 工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作…
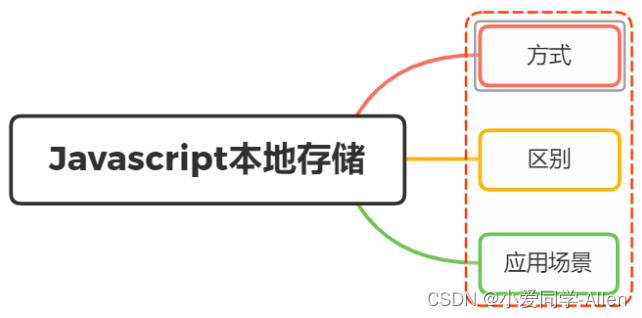
javascript基础二十四:JavaScript中本地存储的方式有哪些?区别及应用场景?
一、方式 javaScript本地缓存的方法我们主要讲述以下四种:
cookiesessionStoragelocalStorageindexedDB
cookie
Cookie,类型为「小型文本文件」,指某些网站为了辨别用户身份而储存在用户本地终端上的数据。是为了解决 HTTP无状态导致的问题…

IDEA插件Free Mybatis Tool
之前经常的操作是在 Mapper 接口中将接口名称复制一下,然后去查找对应的 XML 文件,打开后 CRTLF 查找对应的 xml 实现,整个过程效率很低下。搜了搜果然有前辈已经出了一款 IDEA 的插件解决了这个问题,把这个好用的跳转插件推荐给大…
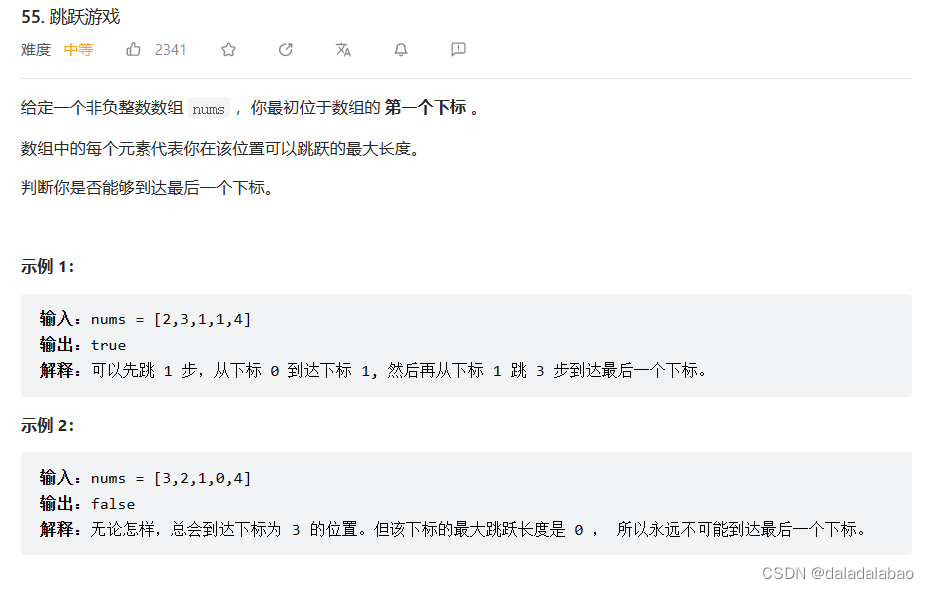
leetcode 55.跳跃游戏
题目描述跳转至leetcode 给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标。 来源:力扣(LeetCode) 链接:https://lee…
软件测试-黑盒测试方法
这里写自定义目录标题 测试用例的定义和特征设计测试用例的基本准则黑盒测试用例设计的几种方法(一)等价类划分法等价类的类型 如何划分等价类等价类划分步骤等价类的划分原则等价类划分法设计测试用例的步骤 (二)边界值分析法边界…
oVirt 4.4.10三节点超融合集群安装配置及集群扩容(一)
环境
oVrit版本: 4.4.10 oVirt image: https://mirrors.aliyun.com/ovirt/ovirt-4.4/iso/ovirt-node-ng-installer/4.4.10-2022030308/el8/ovirt-node-ng-installer-4.4.10-2022030308.el8.iso?spma2c6h.25603864.0.0.46c8a3e6ELIYzK oVirt engine appliance: https://mirror…

osgViewer中的ScreenCaptureHandler、LODScaleHandler、HelpHandler事件处理器用法
目录
1. 前言
2. osgViewer::ScreenCaptureHandler
3. osgViewer::LODScaleHandler
4. osgViewer::HelpHandler
5. osgViewer::ThreadingHandler
1. 前言 osg为视景器的使用和调试提供了丰富的辅助组件,它们主要是以osg::ViewerBase的成员变量或交互事件处理器…

风险SQL 规范及案例
一、 原则
1、程序处理优先:数据库最容易也通常是一个系统的瓶颈,因此不要给数据库加压力,能够程序处理就程序处理。 2、简单操作数据库:一个系统越简单越稳定越不容易出问题, 因此要尽量简单使用数据库, 如SQL简单,事务小 3、数据存储评估:数据库资源宝贵,是很难水平…
饮用水污染预警系统的设计与开发(前后端分离)
1.饮用水污染预警系统的介绍
随着工业化和城市化进程的加速,水污染问题越来越引起人们的关注。饮用水是人类赖以生存的重要资源之一,饮用水污染对人类健康和社会经济发展产生的影响愈加突出。近年来,我国政府高度重视饮用水污染治理工作&…
车牌识别系统Python,基于深度学习CNN卷积神经网络算法
一、介绍
车牌识别系统,基于Python实现,通过TensorFlow搭建CNN卷积神经网络模型,对车牌数据集图片进行训练最后得到模型,并基于Django框架搭建网页端平台,实现用户在网页端输入一张图片识别其结果,并基于P…

自学黑客!一般人我劝你还是算了吧!
笔者本人 17 年就读于一所普通的本科学校,20 年 6 月在三年经验的时候顺利通过校招实习面试进入大厂,现就职于某大厂安全联合实验室。 我为啥说自学黑客,一般人我还是劝你算了吧!因为我就是那个不一般的人。
首先我谈下对黑客&am…