一、什么是Pandas
Pandas是基于NumPy的一种工具,该工具是为解决数据分析任务而创建的,Pandas提供了大量能使我们快速便捷的处理数据的功能
Pandas与出色的Jupyter 工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力反面都是卓越的
Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数案例
处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化,Pandas是处理数据的理想工具
二、Pandas数据结构

Series
Series是一种类似于一维数组的对象,由下面两个部分组成:
values:一组数据(ndarray类型)
index:相关的数据索引标签
1)Series的创建
(1)通过列表或NumPy数组创建
默认索引为0到N-1的整数型索引

值与索引:

修改索引:注意保持索引个数相同
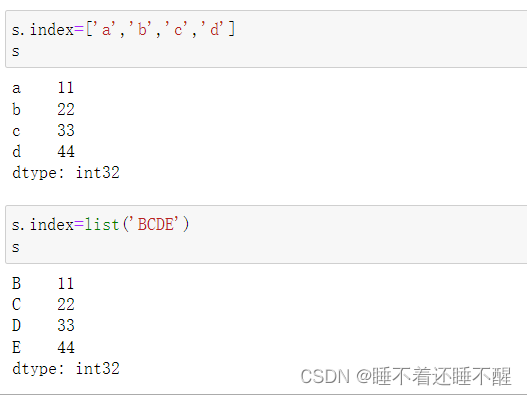
通过index获取和修改值:数字索引要使用[]()

(2)由字典创建
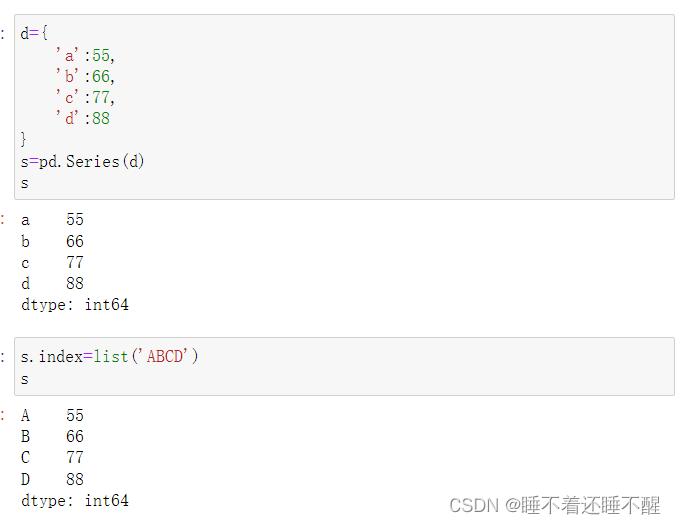
值values可以是多维数组:

Series的参数:

2)Series的索引
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表区多个索引(此时返回的仍然是一个Series类型)。分为显示索引和隐式索引:
显示索引:
使用index中的元素作为索引值
使用.loc[](推荐)

隐式索引:
使用整数作为索引值
使用.iloc[](推荐)

3)Series的切片
切片操作:

4)Series的基本属性和方法
shape:形状
size:长度
index:索引
values:值
name:名字

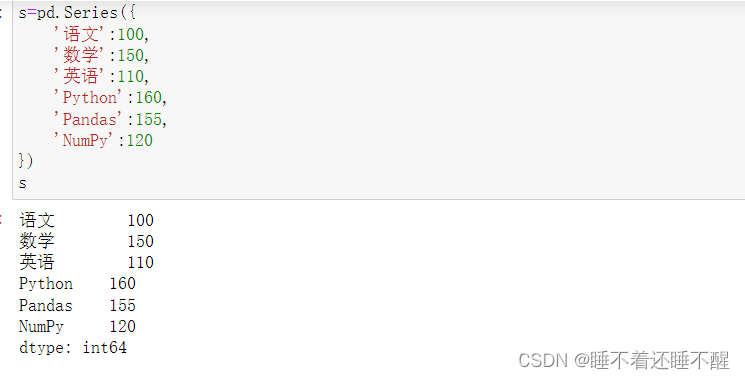
head():查看前几条数据,默认为5
tail():查看后几条数据,默认为5
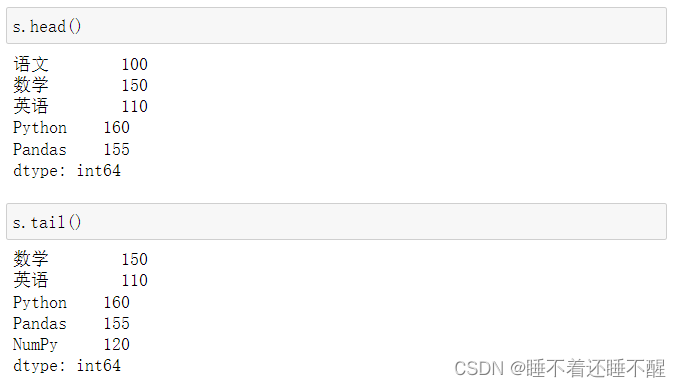
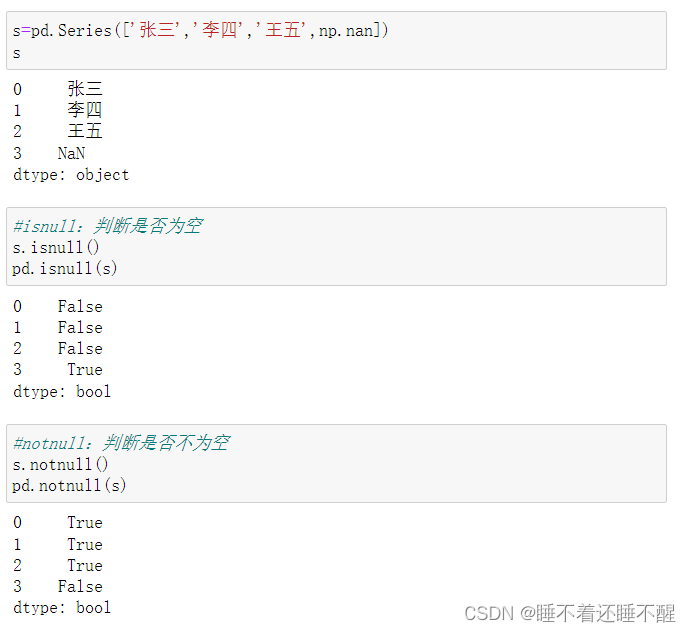
检测缺失数据:
pd.isnull()
pd.notnull()
isnull()
notnull()
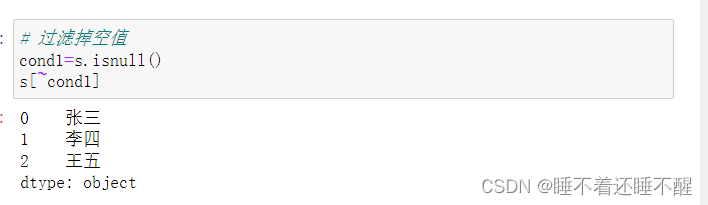
使用bool值索引过滤数据
~代表取反
5)Series的运算
(1)适用于NumPy的数组运算也适用于Series
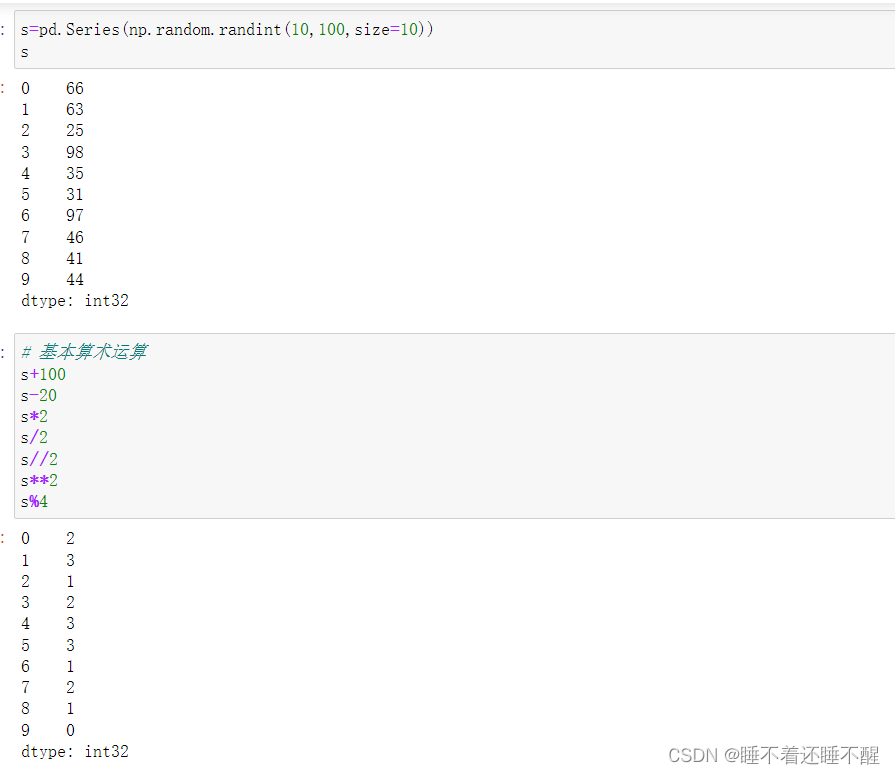
(2)Series之间的运算
在运算中自动对齐索引
如果索引不对应,则补NaN
Series没有广播机制

按索引相加:

如果想要保留所有的index,则需要使用.add()函数

总结:Series可以看做是一个有序的字典结构
DataFrame
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计的初衷是将Series的使用场景从一维扩展到多维。DataFrame既有行索引,也有列索引
行索引:index
列索引:columns
值:values(NumPy的二维数组)
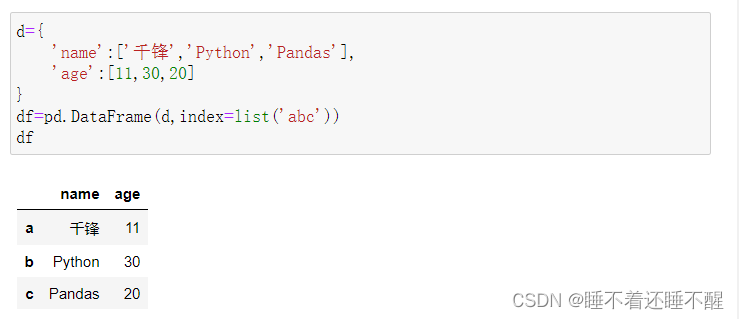
1)DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列
此外,DataFrame会自动加上每一行的索引(和Series一样)
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN


DataFrame的基本属性和方法:
values:值,二维ndarray数组
columns:列索引
index:行索引
shape:形状
head():查看前几条数据,默认5条
tail():查看后几条数据,默认5条
d={
'name':['千锋','黑马','尚硅谷'],
'age':[11,12,20]
}
df=pd.DataFrame(d)
display(df)
display(df.values,df.columns,df.shape,df.head(2),df.tail(2))
#设置index
df.index=list('ABC')
df.columns=['name2','age2']
df
可以在创建的时候指定行索引:
也可以使用二维数组的方式创建DataFrame:

2)DataFrame的索引
(1)对列进行索引
通过类似字典的方式
通过属性的方式
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名

(2) 对行进行索引

取单独一个数据:
加了loc或iloc都是先取行。默认是先取列,再取行

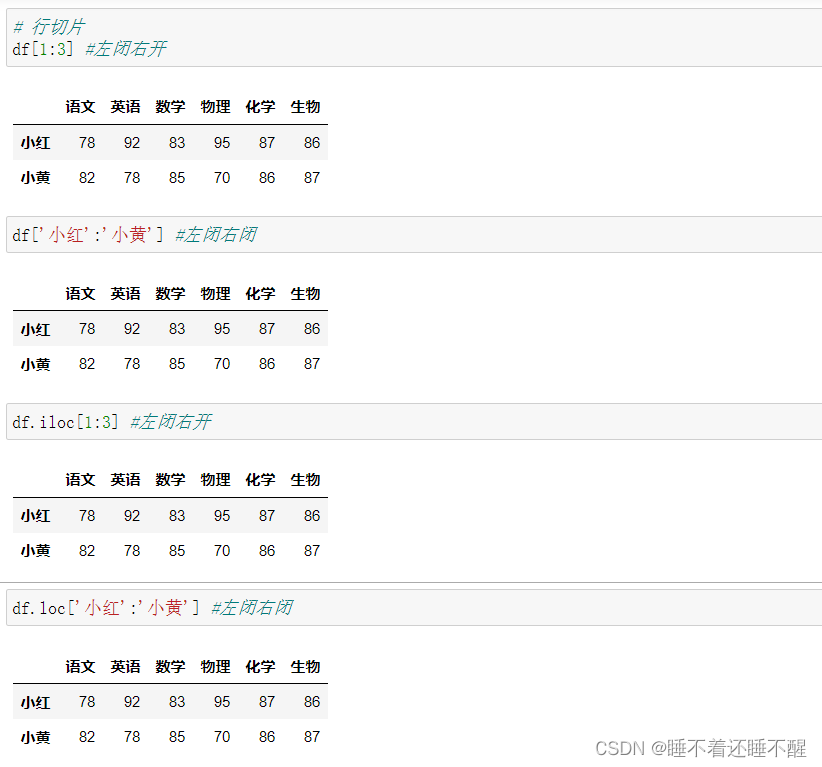
3)DataFrame的切片
行切片:
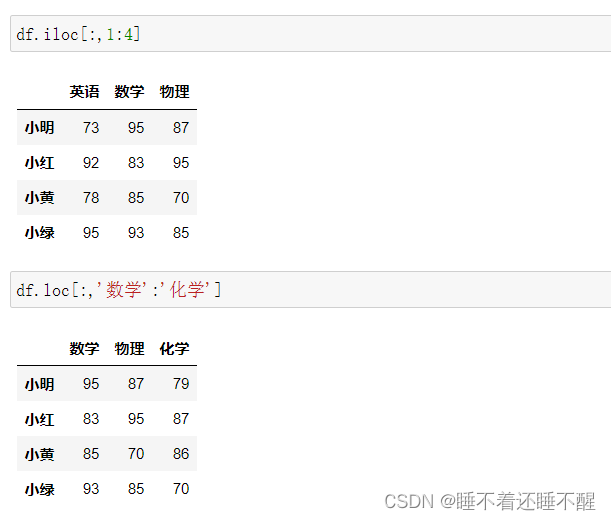
列切片
对列做切片,也必须先对行做切片
同时对行和列切片:

取不连续的行或列:


4)DataFrame运算
基本演示数据:
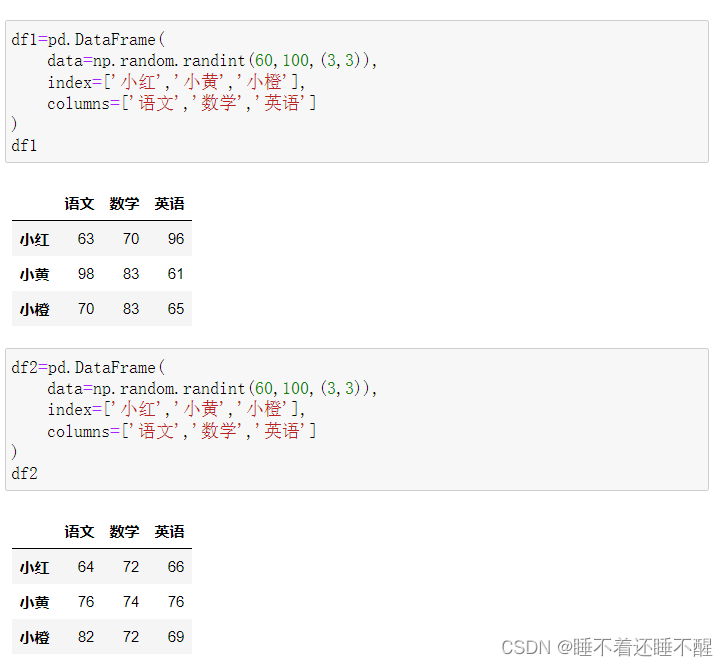
DataFrame和标量的运算
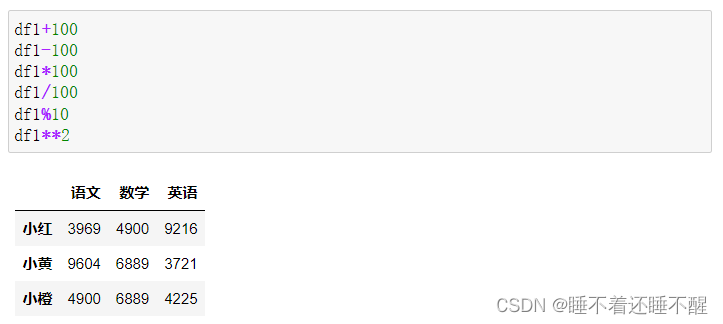
DataFrame之间的运算:

DataFrame没有广播机制:
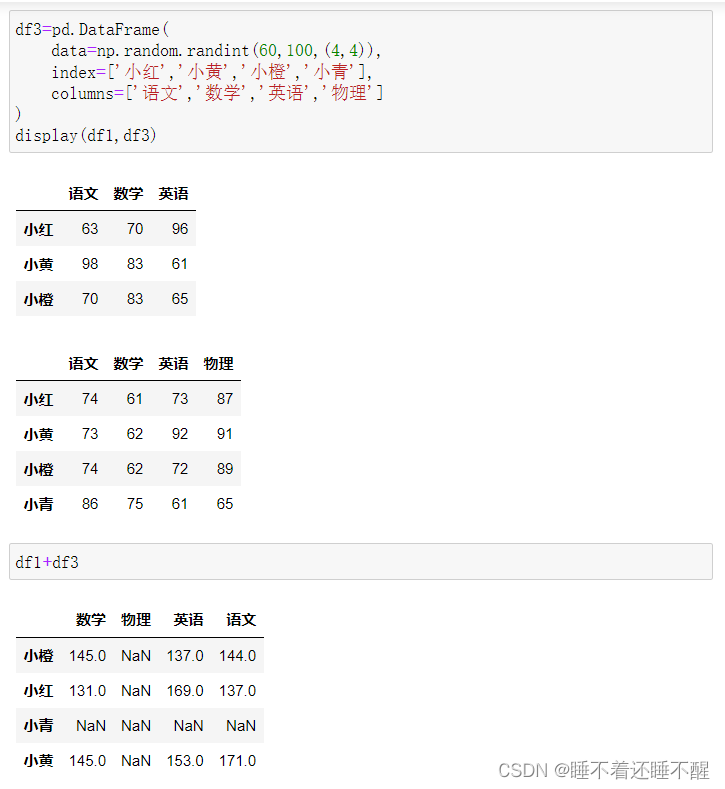
可以使用add()默认填充:

Series与DataFrame之间的运算
使用Python操作符:以行为单位操作(参数必须是行),对所有行都有效
类似于NumPy中二维数组与一维数组的运算,但可能出现NaN

使用Pandas操作函数:
axis=0:以列为单位操作(参数必须是列),对所有列都有效
axis=1:以行为单位操作(参数必须是行),对所有行都有效
注意axis=0和axis='index'等价,axis=1和axis='columns'等价

三、Pandas层次化索引

创建层次化索引
1)隐式创建

Series也可以创建多层索引

2)显式构造 pd.MultiIndex

使用tuple

使用product
笛卡尔积 {a,b} {c,d}===>{a,c},{a,d},{b,c},{b,d}

多层索引对象的索引与切片操作
1)Series的操作
对于Series来说,直接中括号[]和使用loc()是完全一样的

隐式索引:
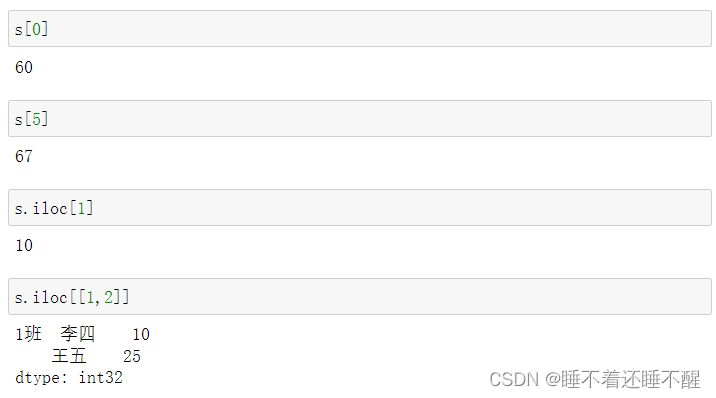
切片:
显式切片:

隐式切片(建议使用):

2)DataFrame的操作

列索引:
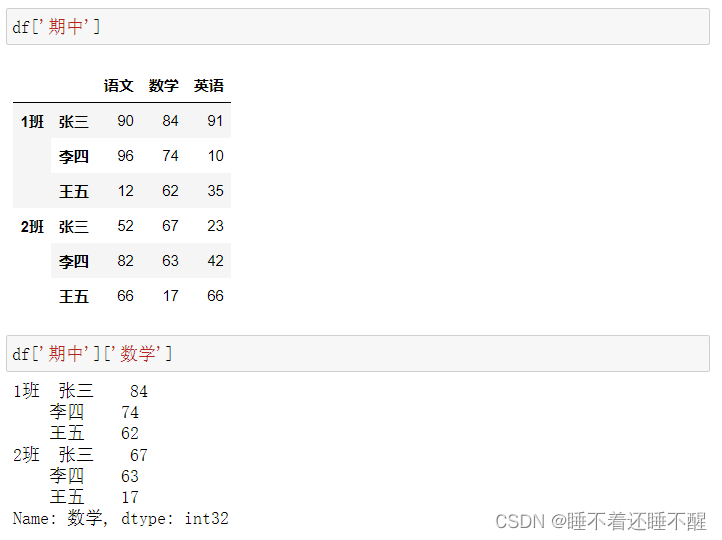

切片:
行切片
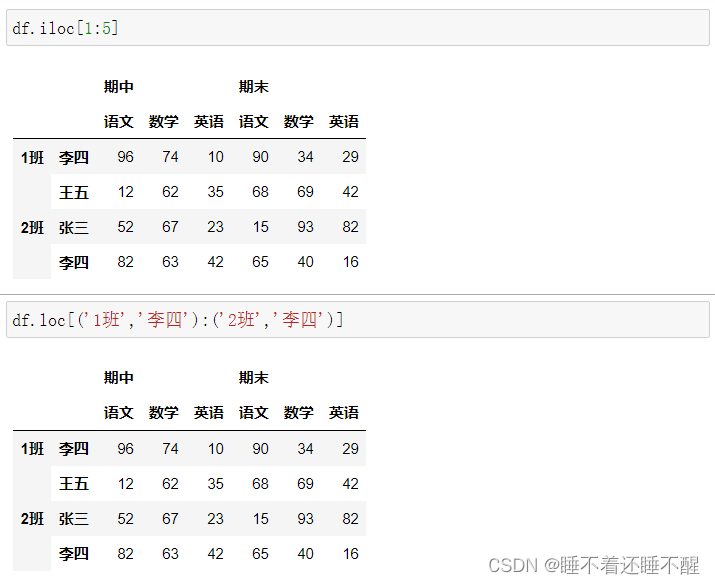
列切片

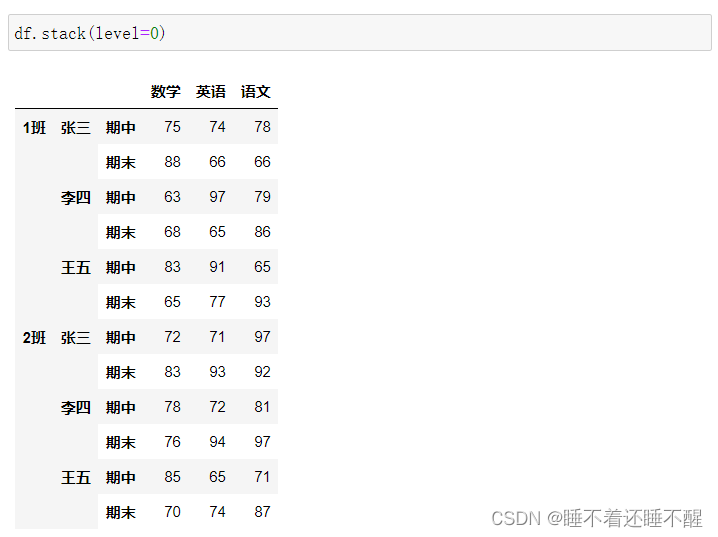
索引的堆叠
stack()、unstack()
使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里
stack():将列索引变成行索引,而且默认是将最里层的列索引变成行索引
基本数据:

使用stack():

默认level=-1,想把哪个列索引变成行索引可以自己指定
使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里
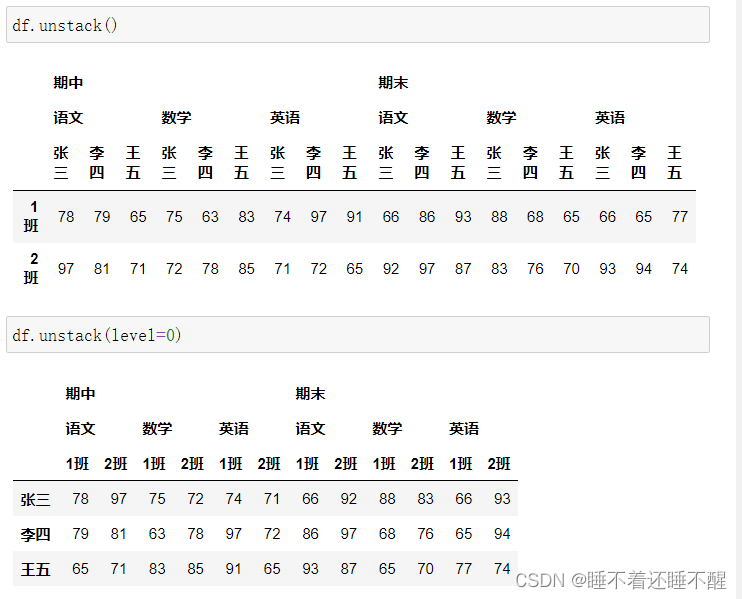
使用fill_value填充
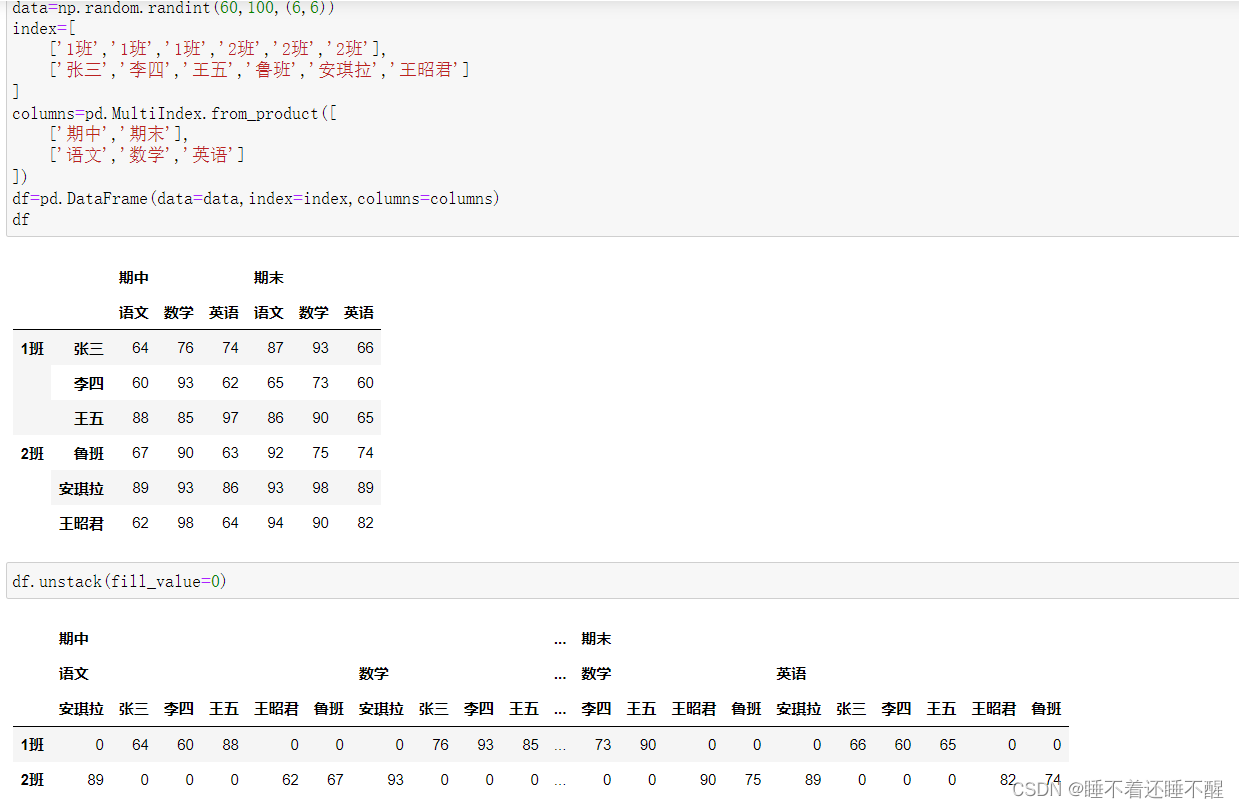
聚合操作
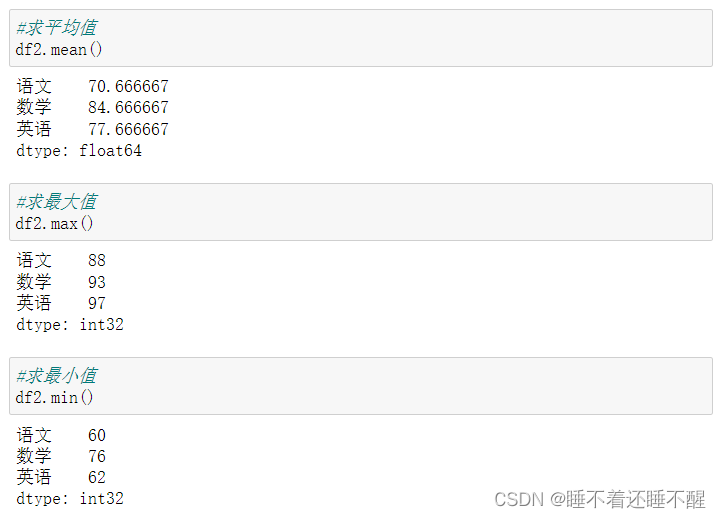
DataFrame聚合函数:
求和
平均值
最大值
最小值

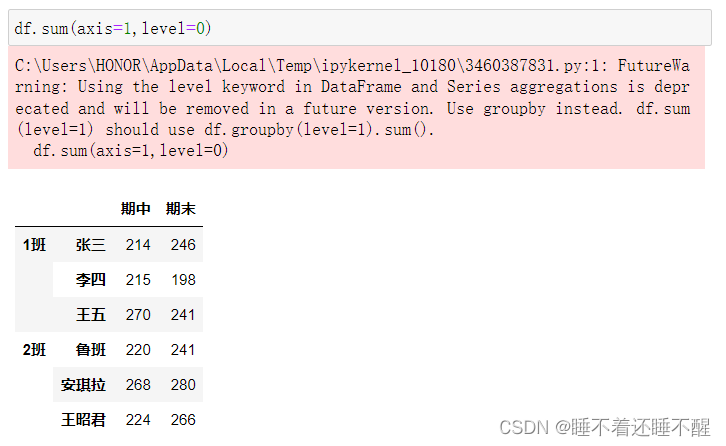
求行的最外层和:

求列的最外层:
四、数据合并

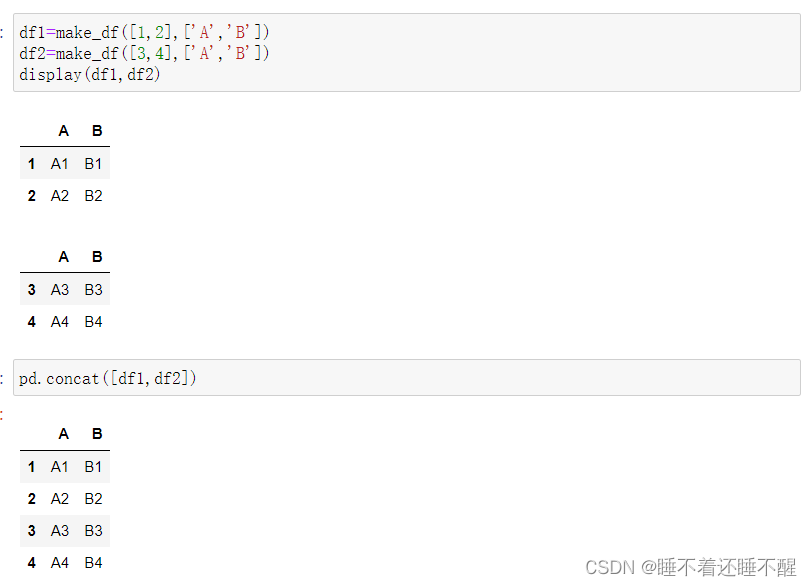
基础数据和用法:

pd.concat()
pandas使用pd.concat函数,与np.concatenate函数类似
1)简单级联
默认是上下合并(垂直合并)
如果想要列合并,可以指定axis=1

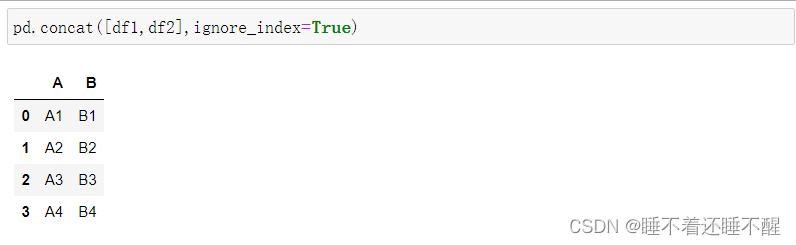
忽略行索引 ignore_index(会重置索引)
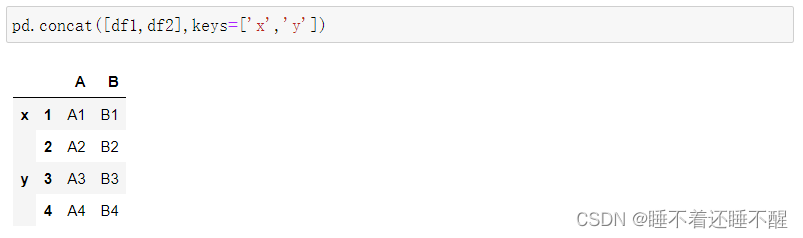
使用多层索引 keys(加一层索引)

2)不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
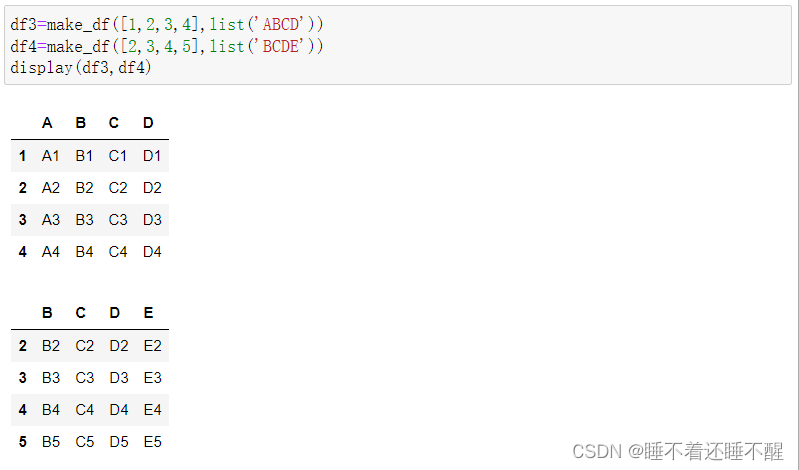
基础数据:
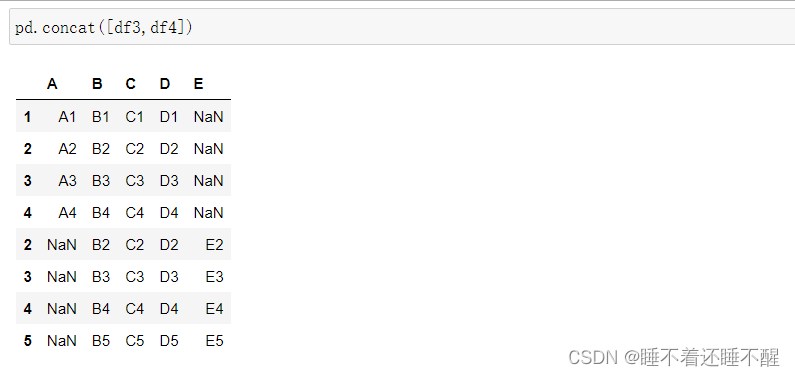
外连接:不匹配的时候默认会用NaN填充
等价于:pd.concat([df3,df4],join="outer")
类似于并集,显示所有数据
内连接:只连接匹配的项
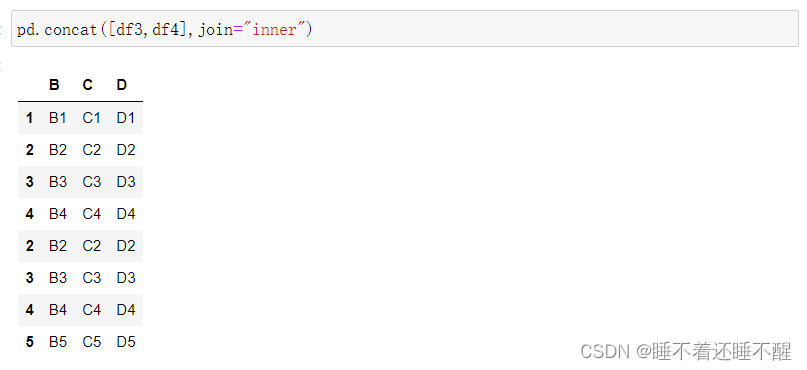
3)使用append()函数添加
由于在后面级联的使用非常普遍,因此有一个函数append专门用于在后面添加

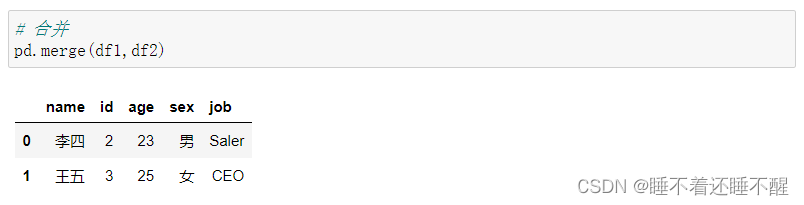
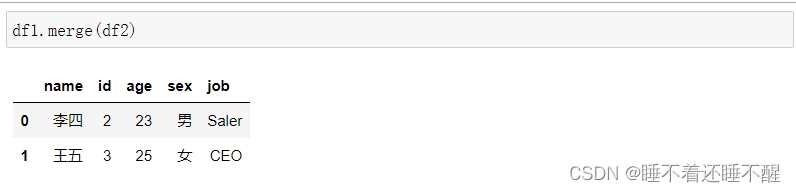
使用pd.merge()合并
类似MySQL中表和表直接的合并
merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并
每一列元素的顺序不要求一致
基本数据:
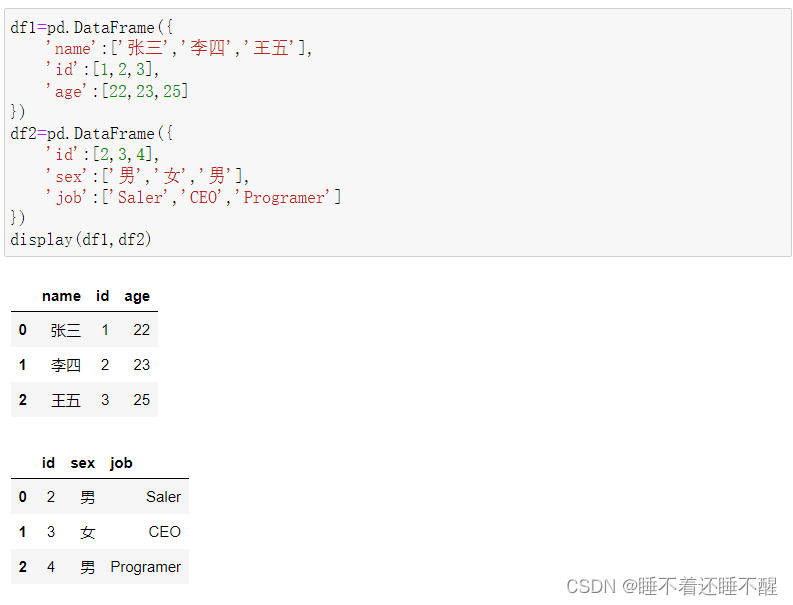
1)一对一合并
2)多对一合并
修改基础数据的id,使其重复

合并的时候多的一方每个都和一的一方合并一次
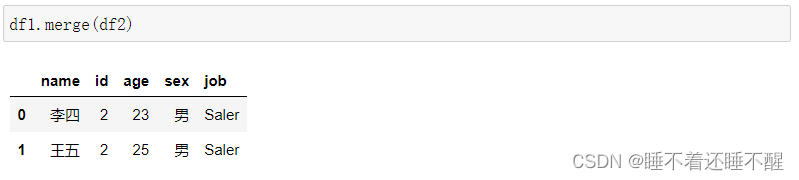
3)多对多合并

合并的时候类似于笛卡尔积
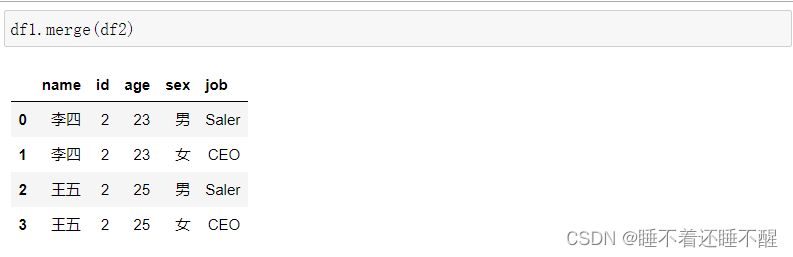
4)key的规范化
使用on=显式指定哪一列为key,当2个DataFrame有多列相同时使用

现在有两列名称相同,但是两列没有值完全等价,所以匹配不到

匹配不到:

匹配得到的情况:

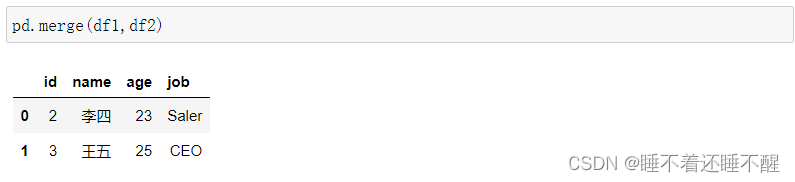
如果有多列名称相同,需要指定一列作为连接的字段

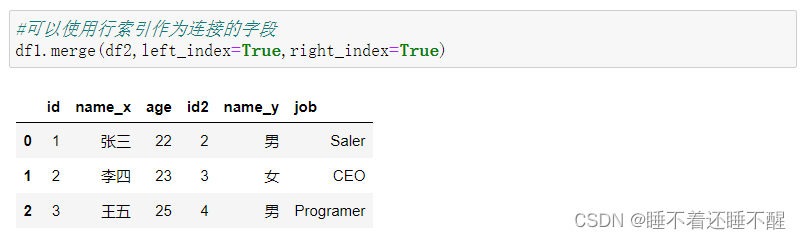
如果没有相同的列名,则需要使用left_on,right_on来分别指定2个表中的不同列作为连接的字段

当左边的列和右边的index相同的时候,可以使用right_index=True

5)内合并与外合并
内合并:只保留两者都有的key(默认就是内连接 inner join)
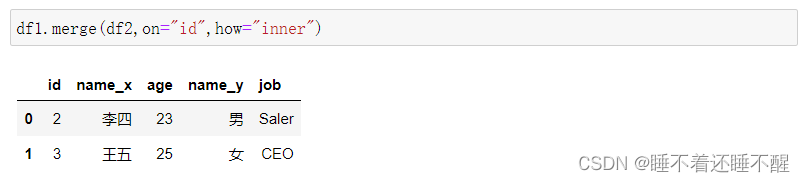
外合并:how="outer" :补NaN
外连接会显示2个表的所有数据

左合并、右合并:how="left",how="right"
左连接:显示左边df1表的所有数据和右边表df2的公共数据

右连接:显示右边df2表的所有数据和左边表df1的公共数据

6)列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
可以使用suffixes=自己指定后缀

merge合并总结:
合并有三种现象:一对一、多对一、多对多
合并默认会找相同的列名进行合并,如果有多个列名相同,用on来指定
如果没有列名相同,但是数据又相同,可以通过left_on,right_on 来分别指定要合并的列
如果想和index合并,可以使用left_index,right_index来指定
如果多个列相同合并之后可以通过suffixes来区分
还可以通过how来控制合并的结果,默认是内合并,还有外合并outer、左合并left、右合并right
五、Pandas缺失值处理

1)缺失值
None:
None是Python自带的,是Python中的空对象。None不能参与到任何计算中。
object类型的运算要比int类型的运算慢很多

np.nan:
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN
np.nansum()可以自动过滤nan不计算

2)Pandas中的None与NaN
(1)Python中None与np.nan都视作np.nan
创建DataFrame
使用DataFrame行索引和列索引修改DataFrame数据

(2)pandas中None与np.nan的操作
isnull()
notnull()
all()
any()
dropna():过滤丢失数据
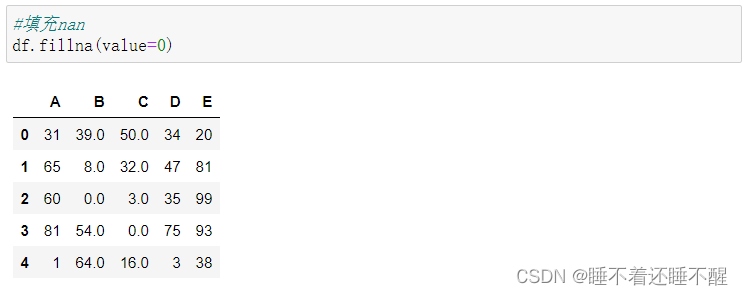
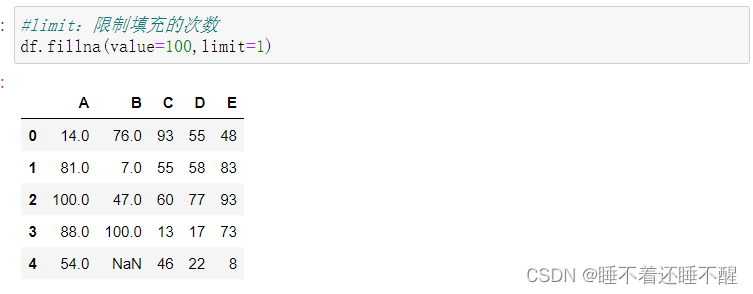
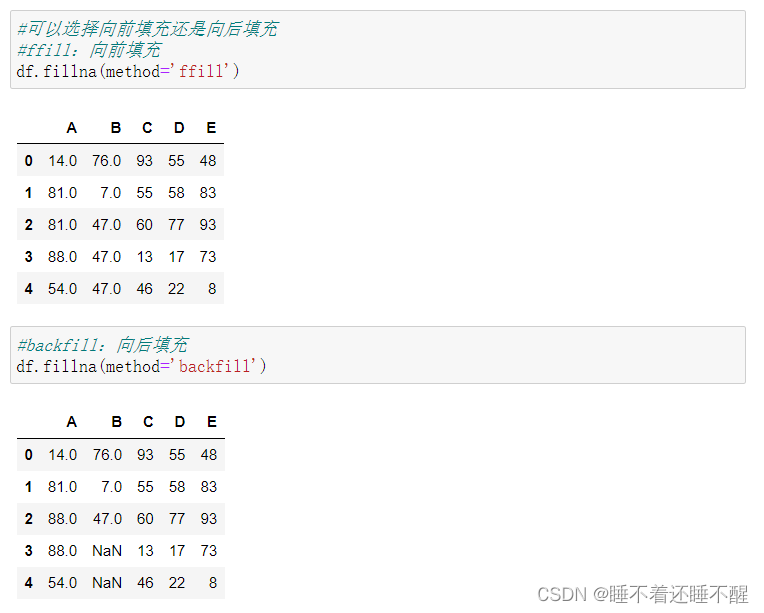
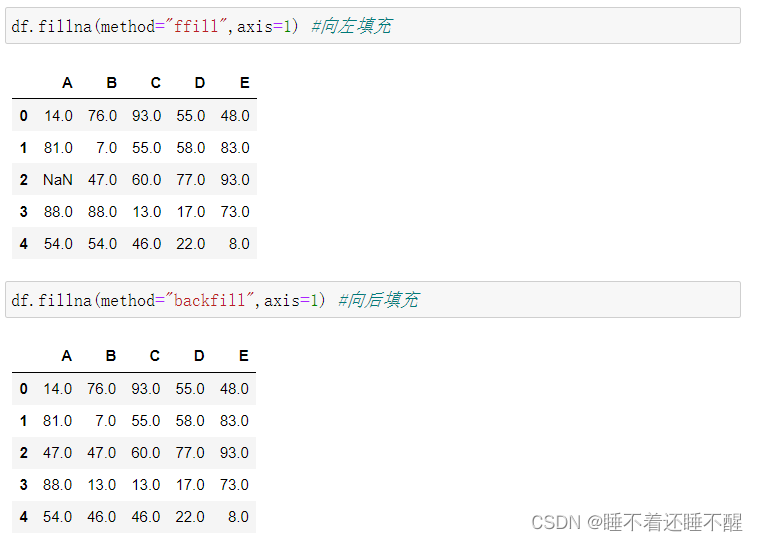
fillna():填充丢失数据
a.判断函数
isnull()
notnull()

b.
all():必须全为True才为True,类似于and
any():只要有一个为True就为True,类似于or


案例:

c.使用bool值索引过滤数据
过滤行:
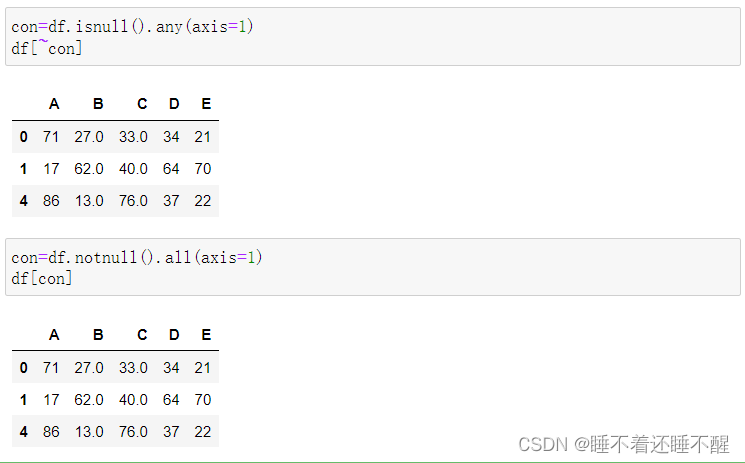
过滤列:

d.dropna():过滤丢失数据

也可以选择过滤的方式 how="all"
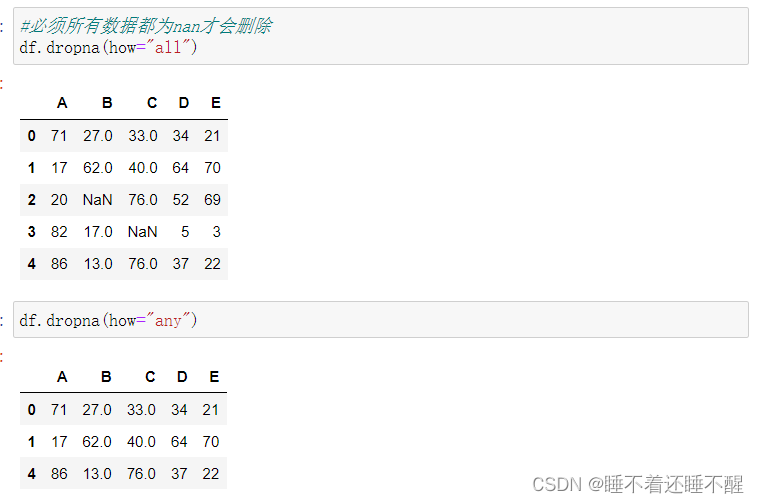
inplace=True 修改原数据,无返回值

e.fillna():填充丢失数据
填充函数 Series/DataFrame
六、Pandas重复值处理
duplicated()函数检测重复的行
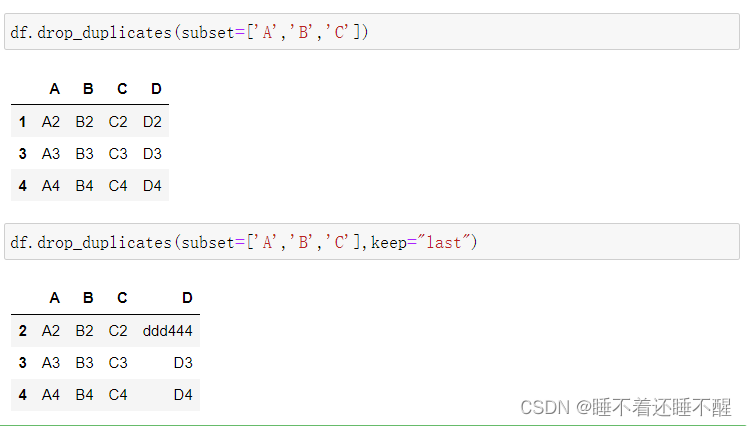
drop_duplicates()函数删除重复的行
1)删除重复行
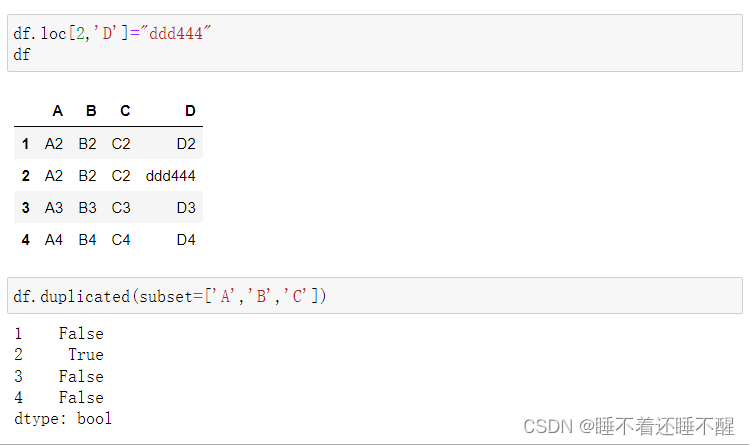
使用duplicated()函数检测重复的行
返回元素为布尔类型的Series对象
每个元素对应一行,如果该行不是第一次出现,则元素为True

默认是两行完全一致才判断为重复,但也可以指定子集
删除重复值:
七、Pandas数据映射

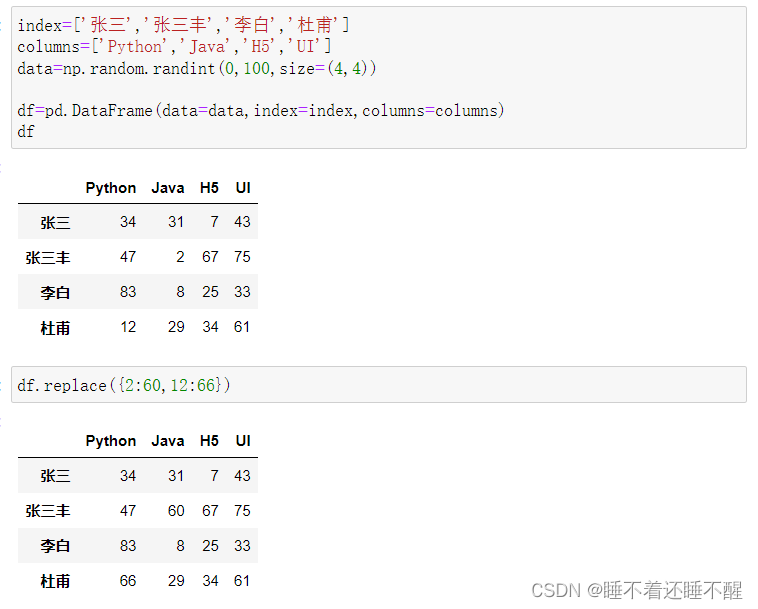
1)replace()函数:替换元素
2)map()函数:适合处理某一单独的列
map()函数中可以使用lambda函数



3)rename()函数:替换索引

也可以使用index={},或columns={}

重置索引:

设置索引:

4)apply()函数:既支持Series,又支持DataFrame
基础数据:
apply应用:lambda
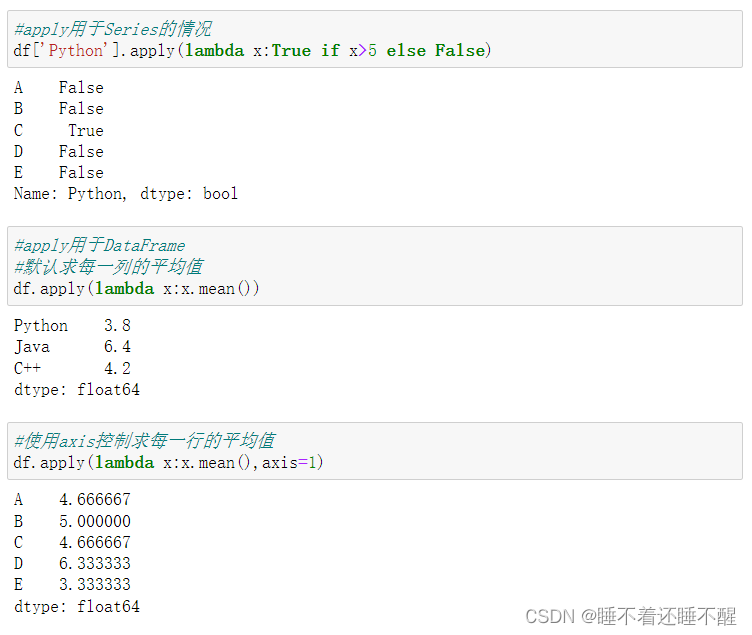
apply应用:普通函数

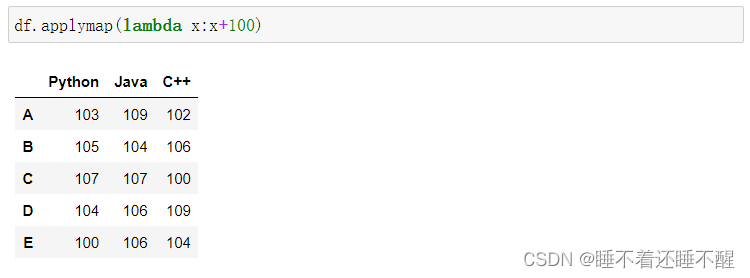
applymap():是DataFrame专有的,其中的x是每个元素
5)transform()函数
用于Series:

用于DataFrame:默认处理每一列
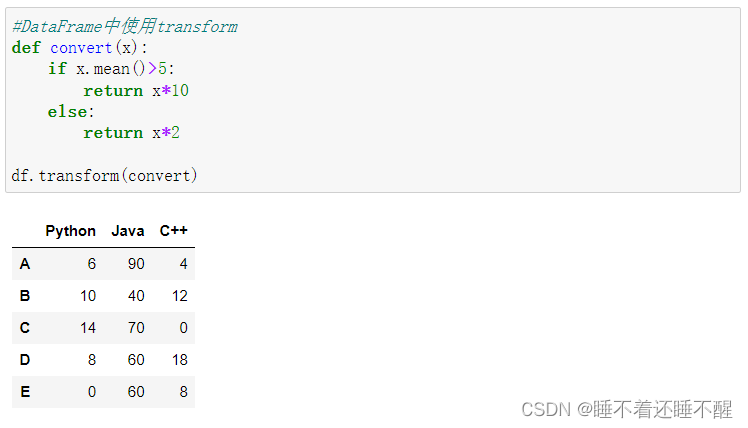
控制为处理每一行:

八、Pandas异常值处理

异常值检测和过滤(一)
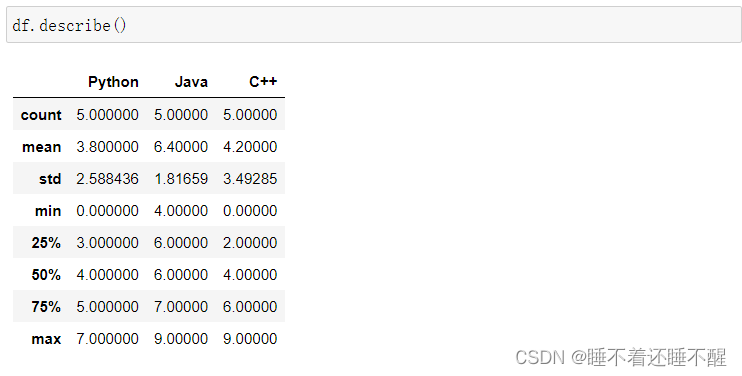
describe():
也可以自己指定百分数:
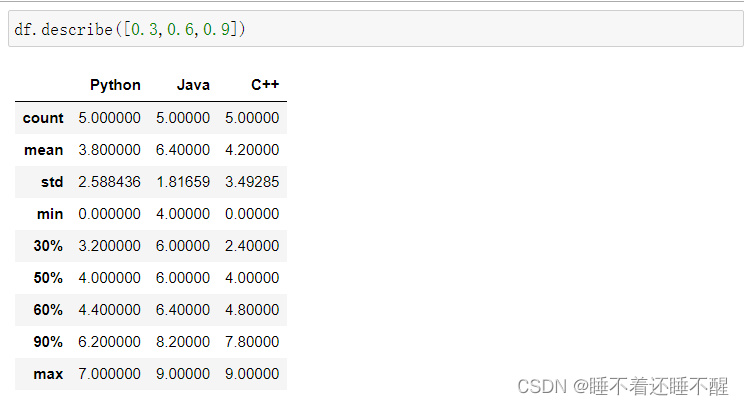
如果行数太多不方便查阅,可以使用.T转置

df.std():可以求得DataFrame对象每一列的标准差

df.drop():删除特定索引
默认删除行索引,如果想要删除列索引,需要加上axis=1

也可以用index=[],columns=[]

异常值检测与过滤(二)
unique():唯一,去重

query():query支持 == ,> ,< 等符号
也支持and &、or | 、in
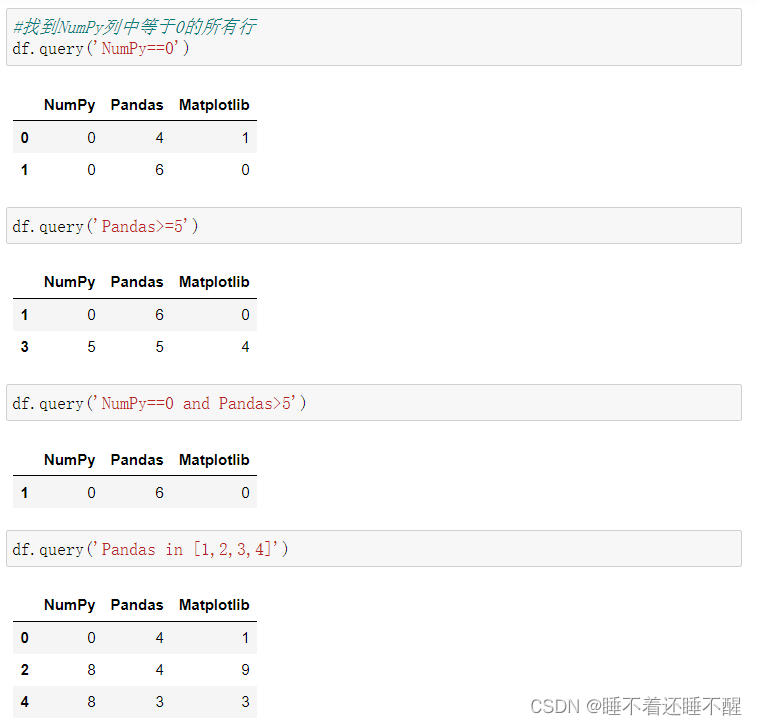
query中也可以使用变量:
@n 表示使用外部的变量n的值
不加@,query无法识别为外部的变量

异常值检测与过滤(三)
df.sort_values():根据值排序
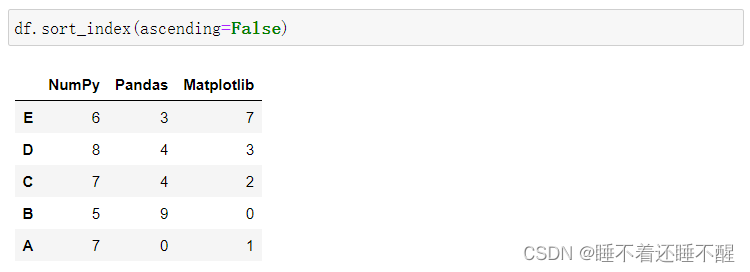
df.sort_index():根据索引排序
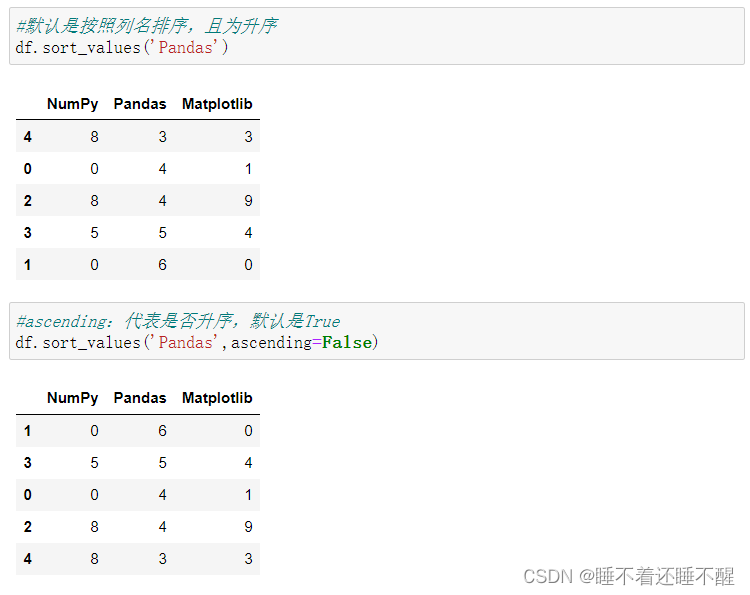
大部分情况下都使用行索引排序,很少按列排序:

按索引名排序(大部分针对索引名为数字的情况):
info():查看数据信息
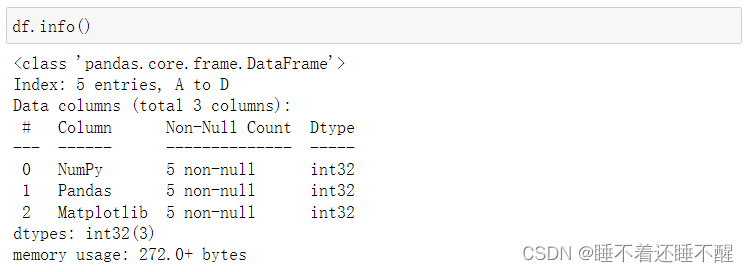
练习
新建一个形状为10000*3的标准正态分布的DataFrame(np.random.randn),去除掉所有满足以下情况的行:
其中任一元素绝对值大于3倍标准差
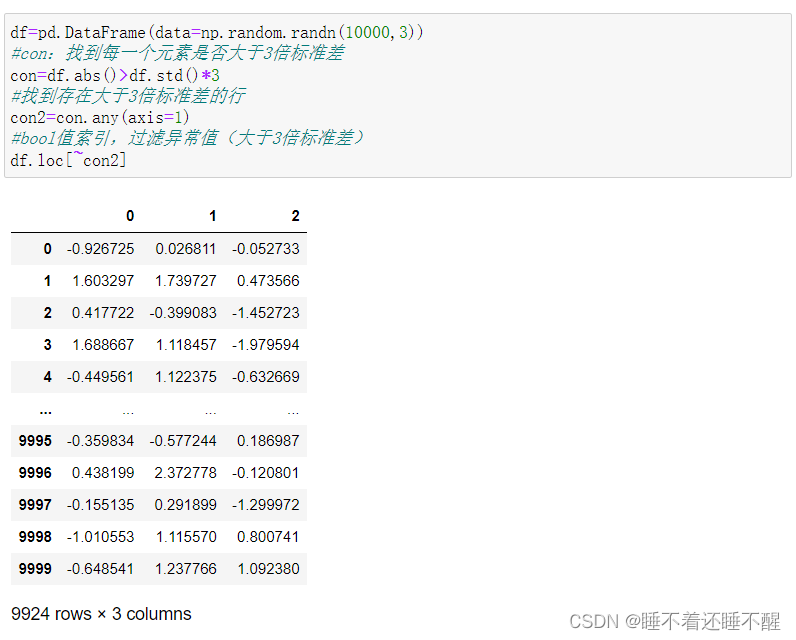
九、数学运算
抽样
使用.take()函数排序
可以借助np.random.permutation()函数随机排序
排列:

随机排列:

模拟无放回抽样:依次随机取出,没有重复值

模拟有放回抽样:可能会出现重复值
相当于取了五次,每次的下标都是[0,3)中的一个随机数
数学函数

聚合函数:
基础数据:

应用:

方差
方差:
当数据分布比较分散(即数据在平均数附近波动较大)时,各个数据与平均数的差的平方和较大,方差就较大
当数据分布比较集中时,各个数据与平均数的差的平方和较小
因此方差越大,数据的波动越大;方差越小,数据的波动就越小
标准差:
标准差 = 方差的算术平方根

统计数据分布情况:
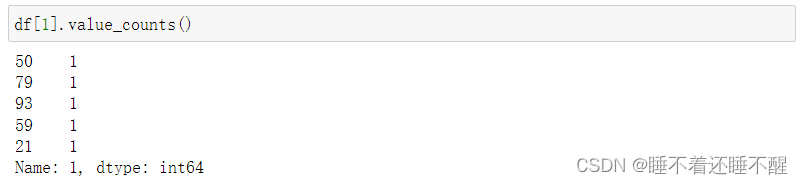
累加运算:
默认是同一列行的累加
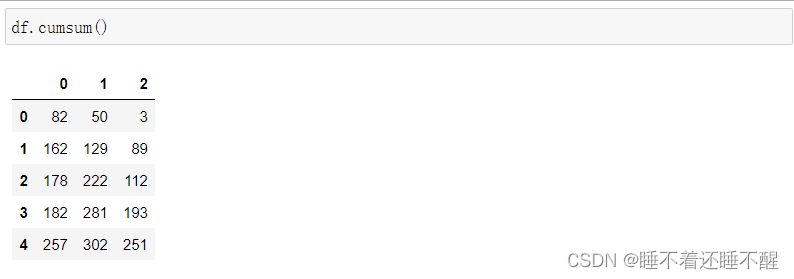
累乘运算:

协方差
两组数值中每队变量的偏差乘积的平均值
协方差>0:表示两组变量正相关
如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值时另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值
协方差<0:表示两组变量负相关
如果两个变量的变化趋势相反,即其中一个变量大于自身的期望值时另外一个却小于自身的期望值,那么两个变量之间的协方差九十负值
协方差=0:表示两组变量不相关

相关系数r
相关系数 = X与Y的协方差 / (X的标准差 * Y的标准差)
相关系数值的范围在-1和+1之间
r>0为正相关,r<0为负相关,r=0表示不相关
r的绝对值越大,1相关程度越高
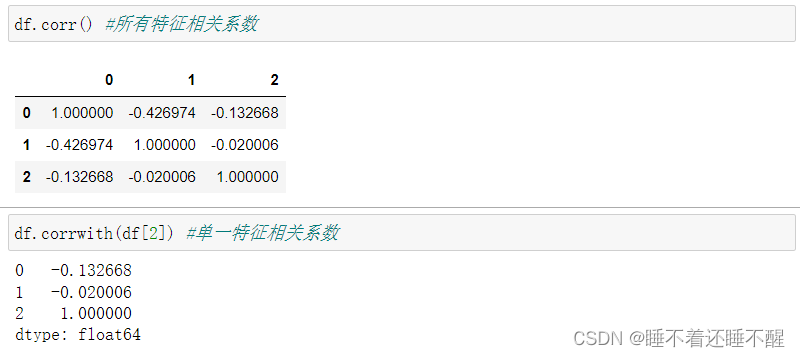
Pandas分组聚合
groupby()函数
.groups属性查看各行的分组情况
数据聚合时数据处理的最后一步,通常是要使每一个数组生成一个单一的数值
数据分类处理:
分组:先把数据分为几组
用函数处理:为不同组的数据应用不同的函数以转换数据
合并:把不同组得到的结果合并起来
数据分类处理的核心:groupby()函数
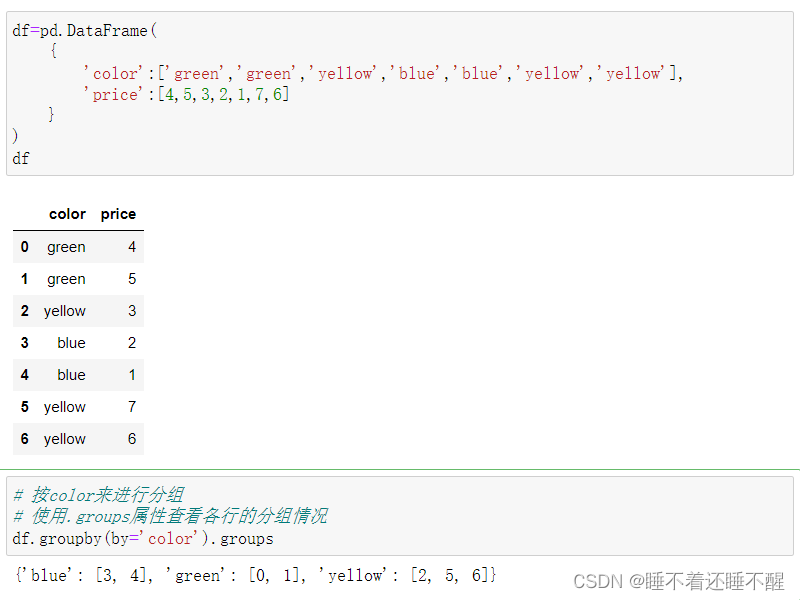
分组+聚合:

练习:
假设菜市场张大妈在买菜,有以下属性:
菜品(item):萝卜、白菜、辣椒、冬瓜
颜色(color):白、青、红
重量(weight)
价格(price)
1.要求以属性作为列索引,新建一个ddd
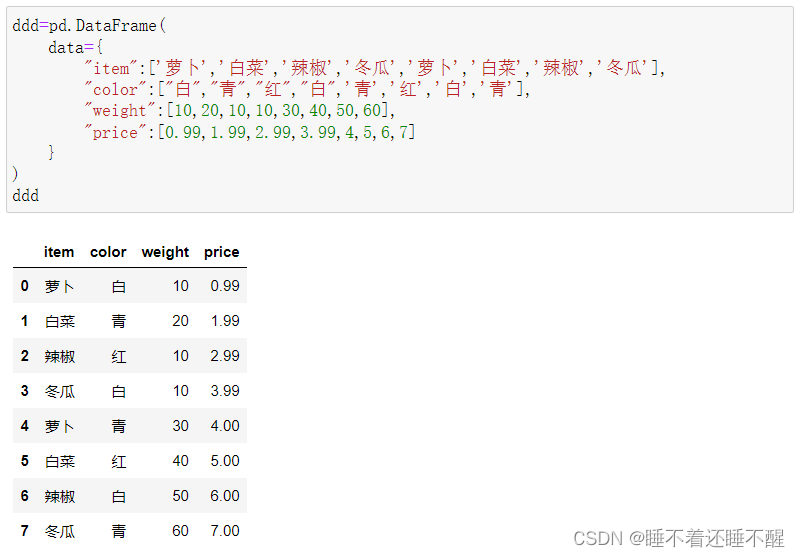
2.对ddd进行聚合操作,求出颜色为白色的价格总和
注:使用两个中括号返回DataFrame,使用一个中括号返回Series

3.对ddd进行聚合操作,分别求出萝卜的所有重量以及平均价格

4.使用merge合并总重量及平均价格

九、Pandas数据加载
CSV数据加载
to_csv:保存到csv
read_csv:加载csv数据
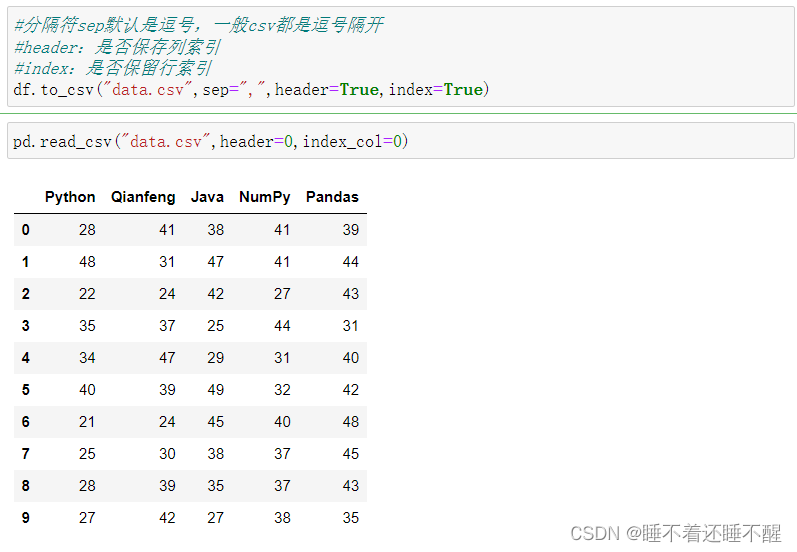
不获取列:header=None
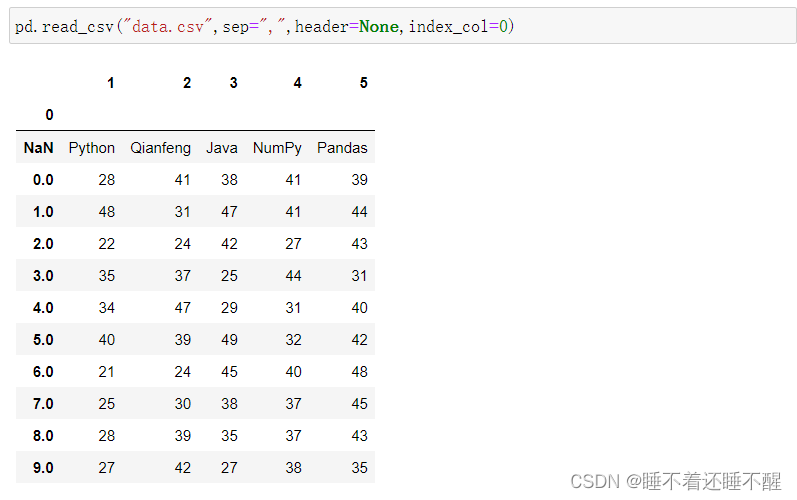
pd.read_table():分隔符默认为sep="\t",如果读取csv格式数据,需要手动指定分隔符

excel数据加载
df.to_excel():保存到excel文件
sheet_name:工作表名称
xlsx是excel的格式类型,xls也是,但未来可能不再支持xls格式

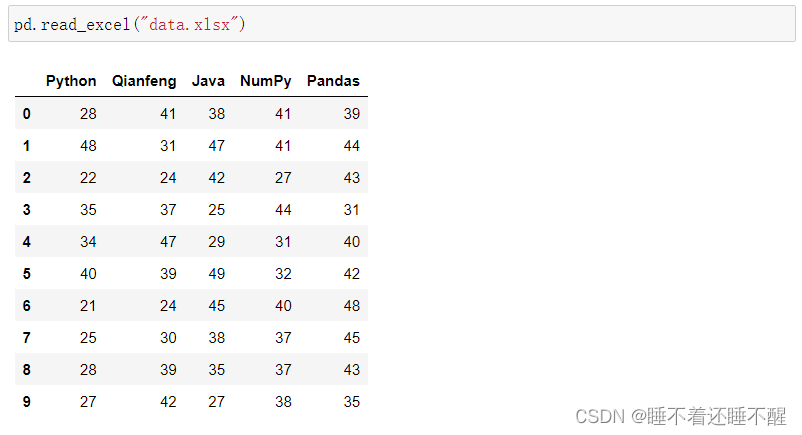
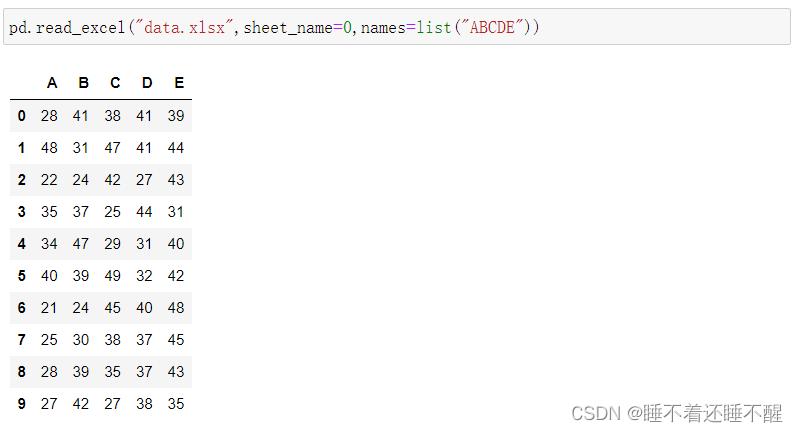
pd.read_excel:读取excel
如果有多个工作表,需要指定sheet_name
可以用names替换原来的列名
十、Pandas分享操作


1.等宽分箱

绘图效果:

自己指定分箱:

2.等频分箱

一般来说,等距分箱用的更多,因为可以自己设置断点
十一、Pandas时间序列
创建时间


时间转换&索引&切片和属性
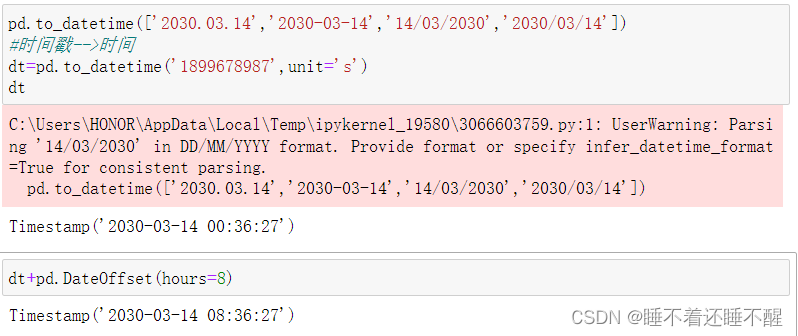
时间转换:

时间差:DateOffset
常见参数:hours、days
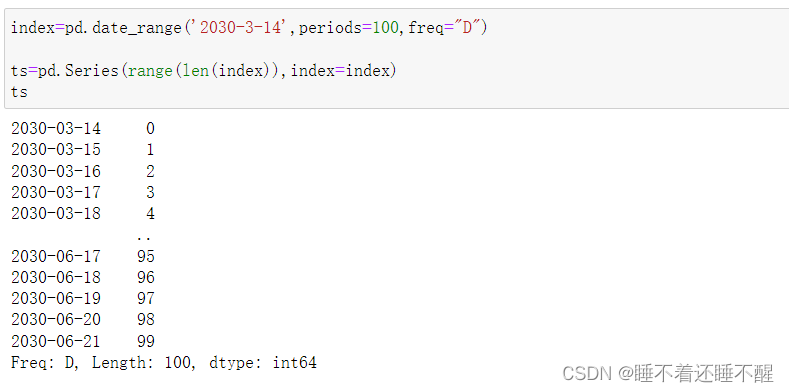
时间戳的索引和切片:
基础数据:
应用:

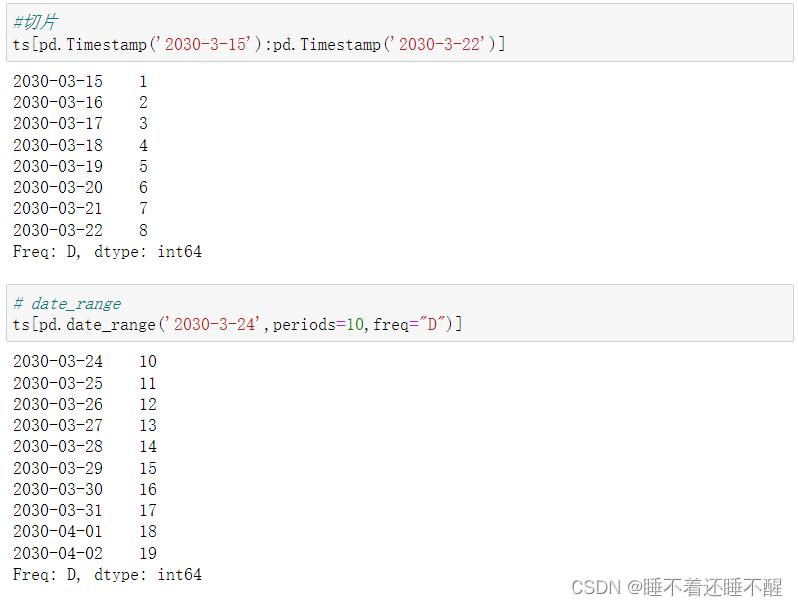
属性:

时间移动和频率转换
对时间做一些移动/滞后、频率转换、采样等相关操作

移动:默认后移一位

频率转换:

pd.tseries.offset.MonthEnd() 得到一个月的最后一天
pd.tseries.offset.MonthBegin() 得到一个月的第一天
由少变多,fill_value填充

resample:根据日期维度进行数据聚合
按照分钟(T),小时(H),日(D),周(W),月(M),年(Y)等来作为日期维度
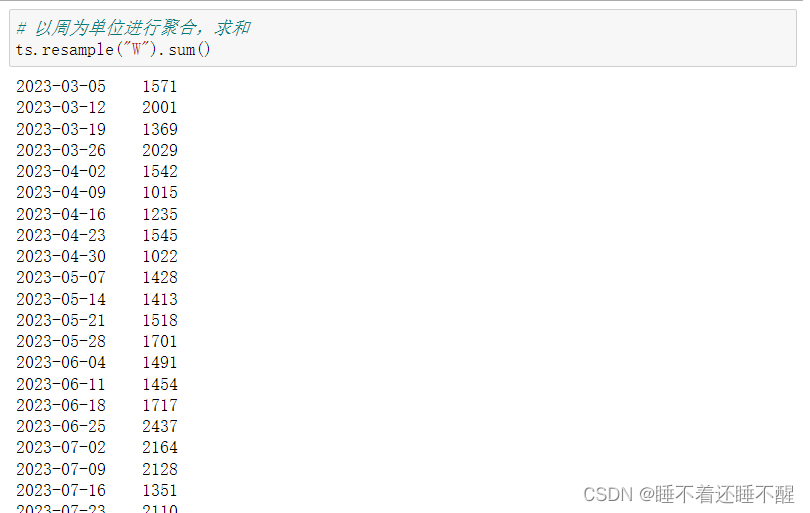


需求:对week列进行按月汇总:price求平均值,score求和

时区

十二、Pandas绘图

折线图
Series图表
画折线图:
画正弦曲线:

DataFrame图表:
图例的位置可能会随着数据的不同而不同
默认是每一列一根线,也可以转置为每一行一根线

条形图和柱状图
DataFrame柱状图示例:kind="bar"/"barh"

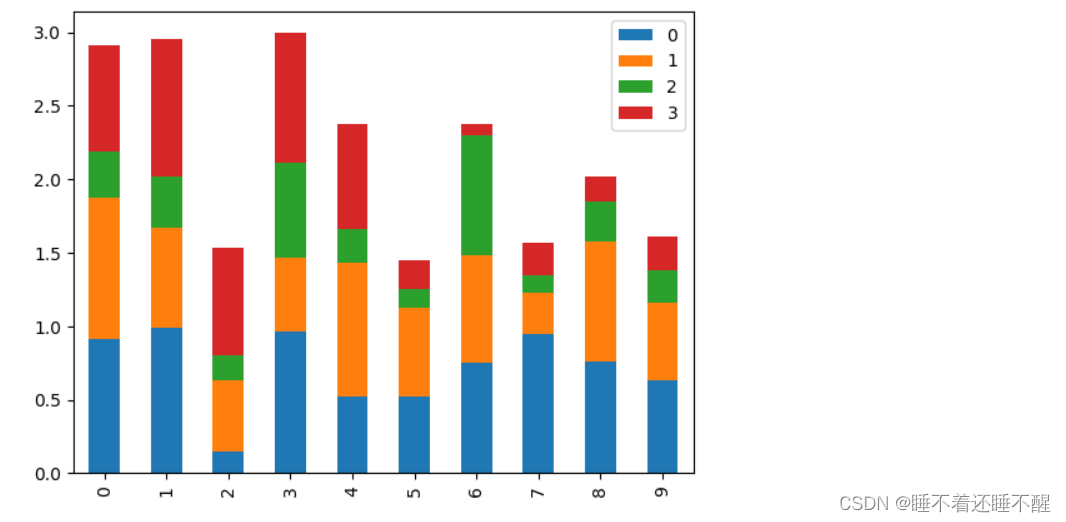
Series:


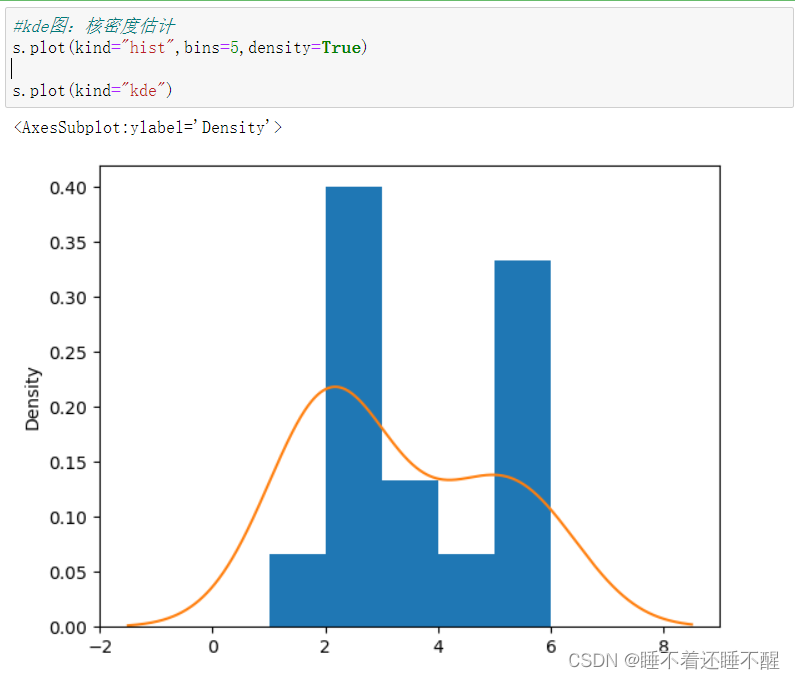
直方图
random生成随机数百分比直方图,调用hist()方法
柱高表示数据的频数,柱宽表示各组数据的组距
参数bins可以设置直方图方柱的个数上限,越大柱宽越小,数据分组越细致
设置density参数为True,可以把频数转换为概率

可以用bins指定分组个数:

使用density将频数转换为概率

kde图:核密度估计,用于弥补直方图由于参数bins设置的不合理导致的精度缺失的问题
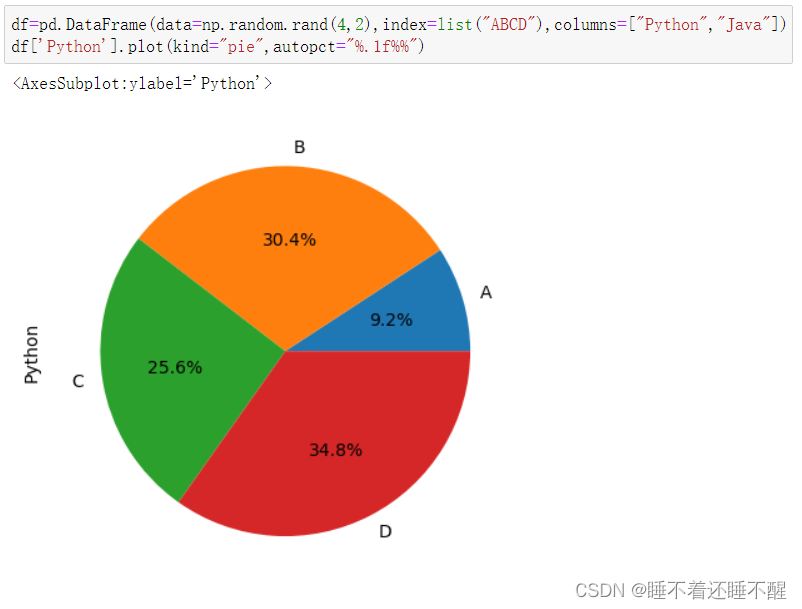
饼图
散点图
散点图是观察两个一位数据数列之间的关系的有效方法,DataFrame对象可用
x="A":使用A列作为X轴
y="B":使用B列作为Y轴

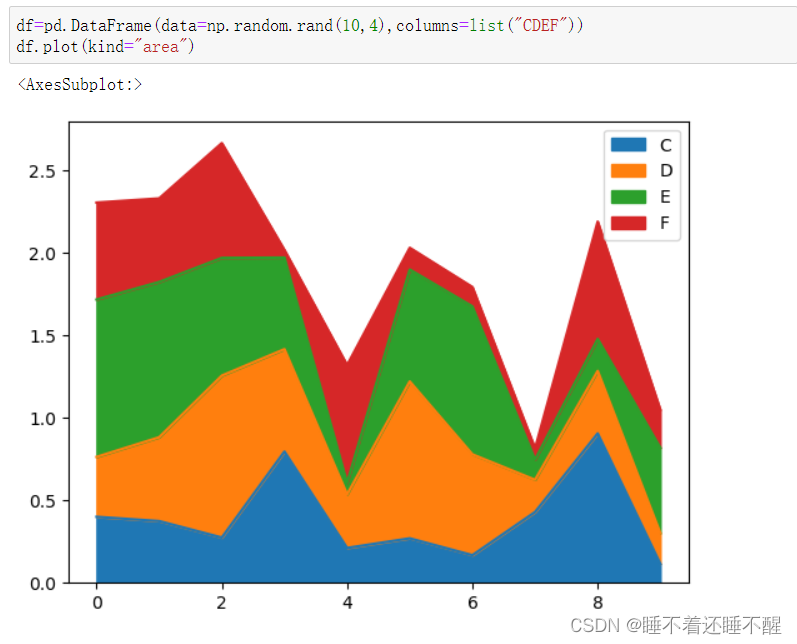
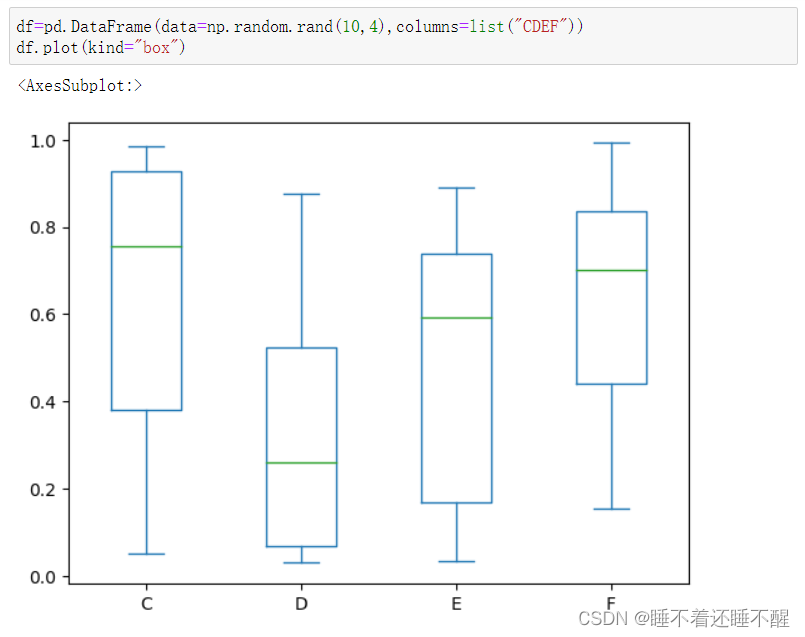
面积图和箱型图
面积图:
箱型图:
最上边的短横线是最大值
75%
50%
25%
最下边的短横线是最小值
如果有空心的圆点:表示异常值(离群点)
Pandas完结,祝大家学习顺利~~❀