前言
四代无感验证码相较于滑块验证码区别就是没有底图,一键通过模式,所以不需要轨迹以及计算缺口距离,步骤更少,四代滑块可以阅读:【JavaScript 逆向】极验四代滑块验证码逆向分析
声明
本文章中所有内容仅供学习交流,相关链接做了脱敏处理,若有侵权,请联系我立即删除!
案例目标
无感验证码:aHR0cHM6Ly93d3cuZ2VldGVzdC5jb20vYWRhcHRpdmUtY2FwdGNoYS1kZW1v
文件版本:gcaptcha4.js
以上均做了脱敏处理,Base64 编码及解码方式:
import base64
# 编码
# result = base64.b64encode('待编码字符串'.encode('utf-8'))
# 解码
result = base64.b64decode('待解码字符串'.encode('utf-8'))
print(result)案例分析
抓包
进入网页后,F12 打开开发者人员工具,进行抓包,抓包到的 load 文件跟四代都没什区别,处理方式一样,verify 请求中的 risk_type 为 ai,滑块验证码为 slide,其他的都一样:

响应返回内容如下:

w 参数逆向
w 参数的加密位置还是特征值 "\u0077",也可以跟栈跟到,Initiator 堆栈中跟到 s 位置:

进去格式化文件后,在 6256 行打下断点,跟四代滑块一样,w 参数的值定义在第 6249 行,有 r 参数生成,r 定义在第 6237 行,加密方式也跟四代滑块一样,RSA + AES 加密,不同的在于 e 字典中的内容,下面那个是滑块的,无感没有 setLeft、track、passtime 和 userresponse,其他的加密算法可以看 【JavaScript 逆向】极验四代滑块验证码逆向分析:

里面的键值都是能直接获取到的,重点来讲讲这个,这个键值对每天的值都会变化,虽然几乎没校验,但是也可以来看看是怎么生成的:

在 6251 行打下断点,可以看到此时这个键值对已经生成了:

向上跟栈,找到其还没生成值的位置,跟到 $_BCFj 中,e 字典在第 6201 行传值:

在 6207 行打下断点,可以 e 字典此时只有四个键值对:

在第 6208 行打下断点,断住后,此时 e 字典中的其他参数值都生成了,证明是执行了 n[$_CBHIE(791)](e); 后生成的:

跟进到 n[$_CBHIE(791)] 中,在第 5766 行,先在 5779 行打下断点,n 中是一些固定值:

再在 5781 行打下断点,断住后会发现那个每天变的值生成了,证明是 _gct(n) 函数返回的:

跟进到 _gct 中,跳转到了 gct.3ac5bbc42b81a701e860478b3566405f.js 文件中,这一串是会变的,从 load 中可以获取到,即 gct_path 的值:

关键算法在第 178 行,GKUV 函数中,全局导出即可:

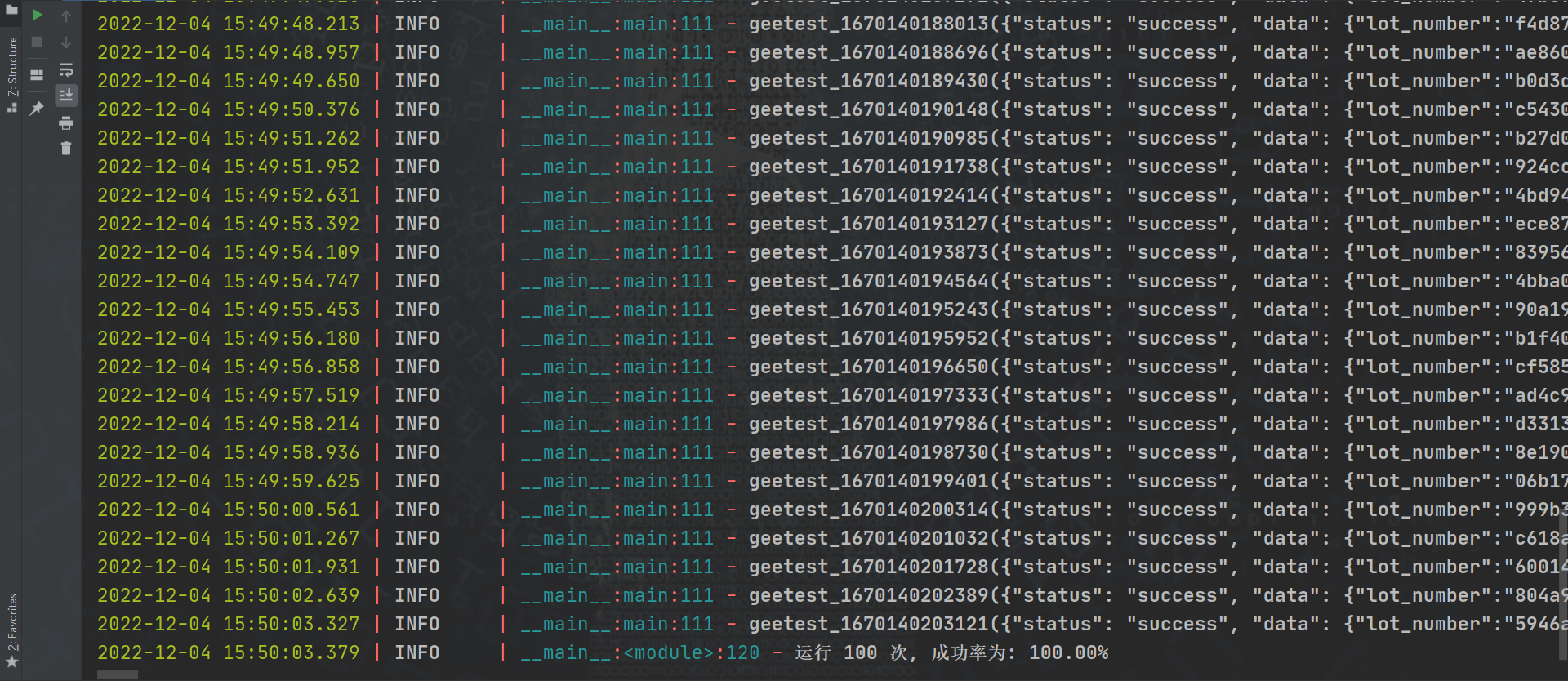
结果验证
![[附源码]计算机毕业设计ssm新能源电动汽车充电桩服务APP](https://img-blog.csdnimg.cn/90c5d8fcd0ec4ebfa2f979697cc2fafd.png)







![[附源码]计算机毕业设计现代诗歌交流平台Springboot程序](https://img-blog.csdnimg.cn/c5a29dcc2d3c42659883d1690ac1d28f.png)