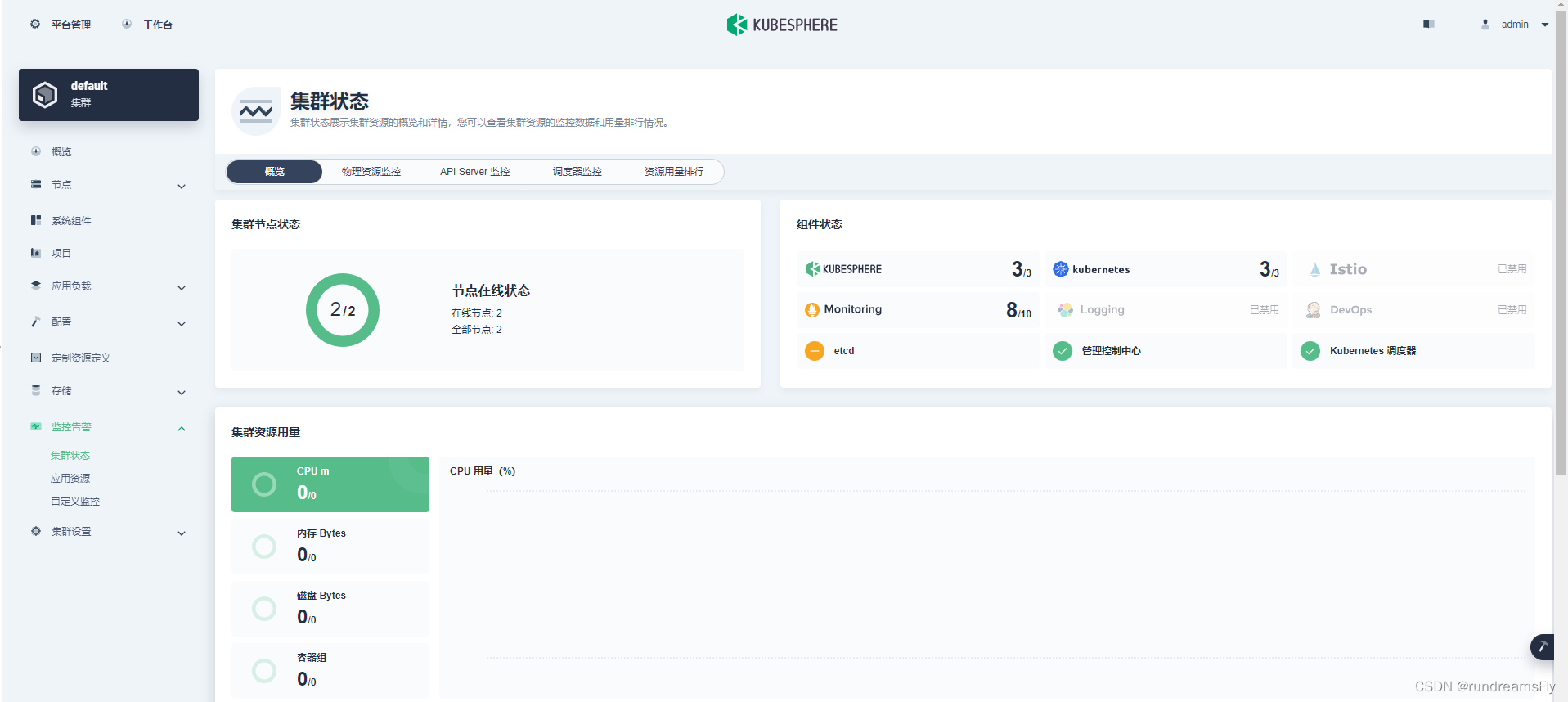
ChatGLM-6b也是一种预训练模型,它也可以通过微调来适应下游任务。实验表明,使用ChatGLM-6b微调和Bert类预训练模型微调的效果相近。如果采用多任务设计,ChatGLM-6b的效果会更好。你可以在这里了解更多关于ChatGLM-6B的信息: ChatGLM-6B![]() https://github.com/THUDM/ChatGLM-6B
https://github.com/THUDM/ChatGLM-6B
在本次实验中,我们使用了一个小规模的命名实体识别数据集。因此,我们可以构造以下样本:
输入:9月22日,英国皇家海军接收第三艘用于防空作战的45型驱逐舰钻石号........
输出:实体类型A1的实体有B1,C1
输出:实体类型A2的实体有B2
输出:没有属于实体类型A3的实体
比如,输出可以是:属于舰船舰艇的实体有45型驱逐舰钻石号,没有属于炮弹的类型的实体。
然而,如果我们有n个实体类型,这就意味着我们需要构建n个问答对。这样的设计虽然逻辑清晰,但训练和预测都会非常耗时。因此,我们需要设计一种方法,使得一个问答对就能解码出所有答案。
输入:9月22日,英国皇家海军接收第三艘用于防空作战的45型驱逐舰钻石号........
输出:A1#B1#C1&&A2#B2
例如,输出可以是:舰船舰艇#45型驱逐舰钻石号#40型驱逐舰&&火炮#777火炮
实验结果表明,这两种格式的微调效果几乎一样,但后者的效率提高了n倍。
但是,使用p-tuning v2微调的方式会存在一些问题,比如会预测出数据集中没有出现的实体类型,例如鱼类、火箭炮等。虽然这体现了模型的zero-shot能力,但是也给我们带来了问题。因此,我们希望对实体类型进行限制,我们选择使用多任务方式实现。LLM的模型天生的适合多任务学习
我们增加了实体识别和实体边界检测任务,同时保留了之前所有的训练数据。例如,我们添加了以下样本:
输入:HK417式突击步枪在句子'HK417式突击步枪还将添加一些新的部件'中是什么实体类型
输出:单兵武器
输入:突击步枪在句子'HK417式突击步枪还将添加一些新的部件'中是什么实体类型
输出:实体不完整
输入:HK417式突击步枪还将在句子'HK417式突击步枪还将添加一些新的部件'中是什么实体类型
输出:实体越界
我们可以通过规则去制作这种训练数据,当然,如果人工去制作效果可能会更好。
在训练过程中,模型同时学习实体抽取和实体判断两个任务,预测时,我们对每条预测结果进行二次判断,以提高准确率。实验表明,这种方法可以大幅提高模型性能。
总结
ChatGLM-6b微调和Bert类预训练模型微调的效果相近。如果采用多任务设计,ChatGLM-6b的效果会更好
我们将实体识别和实体边界检测作为两个独立的任务,这在训练过程中,不仅帮助模型更好地理解实体的概念,而且使其更清晰地了解实体的边界。同时在预测时,模型可以输出对实体判段的结果,增加了结果的可解释性,我们可以更快更针对性的增加数据集,提高训练效果。