- 主从复制
- 单机redis的风险和问题
- 机器故障:硬盘故障、系统崩溃
- 容量瓶颈:内存不足,无限升级内存
- 结论:为了避免单点redis服务器故障,准备多台服务器互相连通,将数据复制多个副本保存在不同的服务器上,并保证数据同步。即使其中一台服务器宕机,其他服务器依然可以继续提供服务,实现redis的高可用和数据冗余备份
- 主从复制:将master中的数据即时、有效地复制到到slave中
- 特征:一个master可以拥有多个slave,一个slave只对应一个master
- 职责
- master
- 写数据
- 执行写操作时,将变化的数据自动同步到slave
- slave
- 读数据
- master
- 主从分离的作用
- 读写分离:master写、slave读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高redis服务器并发量和数据吞吐量
- 故障恢复:当master出问题时,由slave提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制、构建哨兵模式与集群,实现redis的高可用方案
- 主从复制的三个阶段
-
建立连接阶段
- 建立slave到master的连接,使master能够识别slave,并保存slave端口号
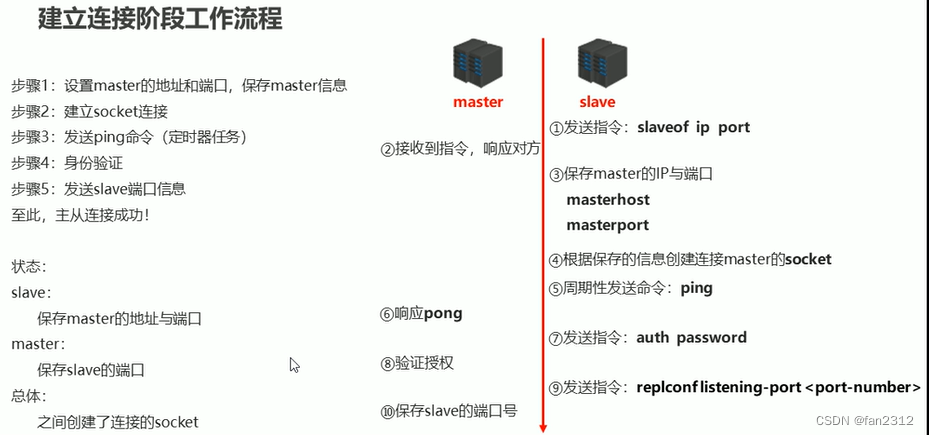
- 主从连接(slave连接master)
- 方式一:客户端发送命令
- slaveof <masterip> <masterport>
- 方式二:启动服务器参数
- redis-server --slaveof <masterip> <masterport>
- 方式三:服务器配置
- slaveof <masterip> <masterport>
- 主从断开连接
- (从)slaveof no one

- 方式一:客户端发送命令
-
数据同步阶段
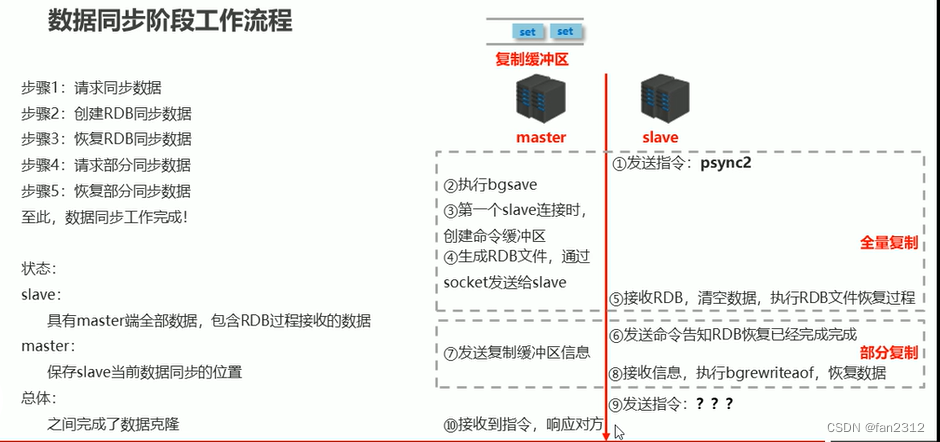
- master说明
- 如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
- 复制缓冲区大小设置不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已经丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态
- repl-backlog-size 1mb
- master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,剩下的内存用于执行bgsave命令和创建复制缓冲区
- slave说明
- 为了避免slave进行全量复制,部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
- slave-serve-stale-data yes|no
- 数据同步阶段,master发送给slave信息可以理解为master是slave的一个客户端,主动向slave发送命令
- 多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰
- slave过多时,建议调整拓扑结构,由一主多从变为树状结构,中间的节点既是master,也是slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择
- 为了避免slave进行全量复制,部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
-
命令传播阶段
-
- 主从复制常见问题
- 单机redis的风险和问题
Redis学习笔记(五)
news2026/2/11 7:55:35











本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/60670.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
Vue 官方文档2.x教程学习笔记 1 基础 1.5 计算属性和侦听器 1.5.2 侦听器
Vue 官方文档2.x教程学习笔记 文章目录Vue 官方文档2.x教程学习笔记1 基础1.5 计算属性和侦听器1.5.2 侦听器1 基础
1.5 计算属性和侦听器
1.5.2 侦听器
虽然计算属性在大多数情况下更合适,但有时也需要一个自定义的侦听器。
这就是为什么 Vue 通过 watch 选项提…

图像处理:模糊图像判断
目录
上期回顾
采用Laplace算子的原因
实现的效果
图片素材
代码的展示与讲解
效果展示
项目资源 上期回顾
上一次的图像清晰度评价没有成功,主要的原因是那几张图像清晰度评价函数都实际都采用了梯度求解,不同的场景灰度的明暗不同,…

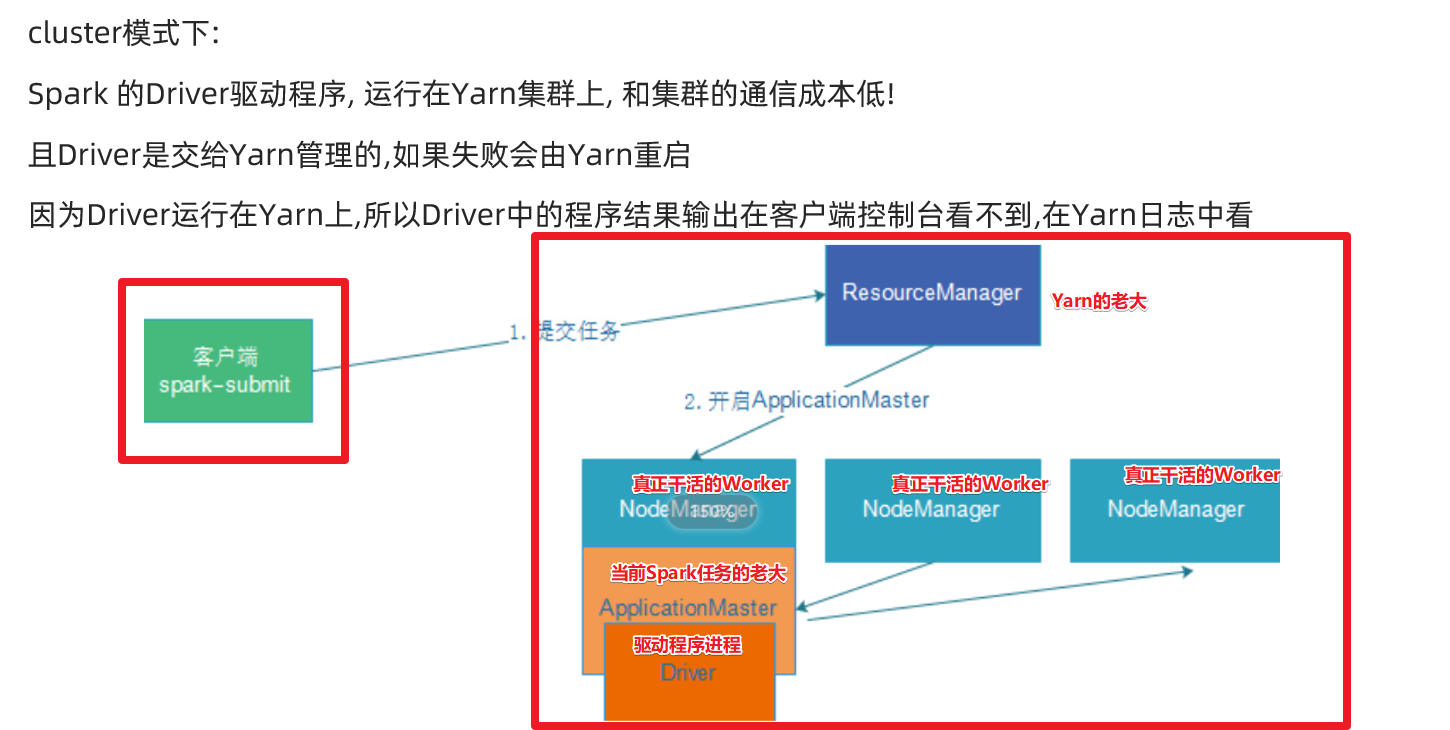
Spark - OnYARN 模式搭建,并使用 Scala、Java、Python 三种语言测试
一、SparkOnYarn搭建
安装前需要提前安装好 hadoop 环境,关于 HDFS 和 Yarn 集群的搭建可以参考下面我的博客: https://blog.csdn.net/qq_43692950/article/details/127158935 下面是我 Hadoop 的安装结构
主机规划设置主机名角色192.168.40.172node1N…
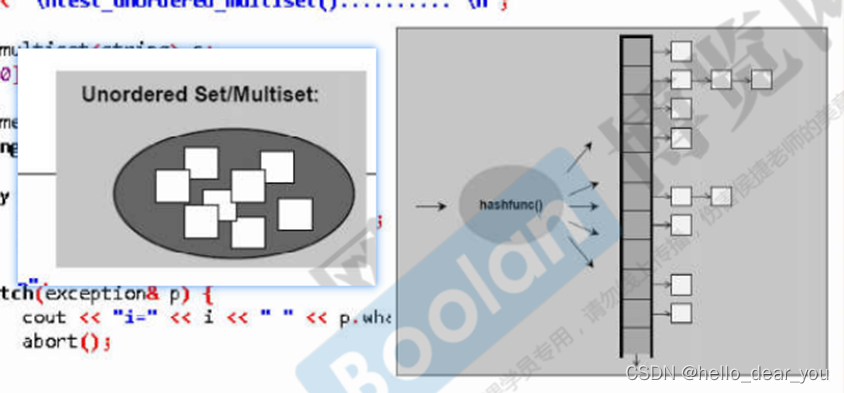
1. STL六大组件
0. 介绍
STL提供六大组件,它们之间可以彼此套用,如下图所示: 容器(containers):用于存放数据; 算法(algorithms):包含各种常用算法; 迭代器&…

Dubbo-RPC核心接口介绍
前言
Dubbo源码阅读分享系列文章,欢迎大家关注点赞
SPI实现部分 Dubbo-SPI机制 Dubbo-Adaptive实现原理 Dubbo-Activate实现原理 Dubbo SPI-Wrapper
注册中心 Dubbo-聊聊注册中心的设计 Dubbo-时间轮设计
通信 Dubbo-聊聊通信模块设计
RPC 聊聊Dubbo协议
…
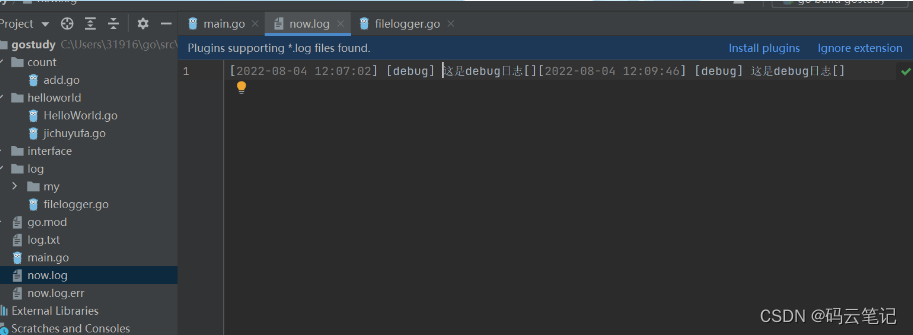
go语言日志实现详解(打印日志、日志写入文件和日志切割)
log包定义了Logger类型,该类型提供了一些格式化输出的方法。本包也提供了一个预定义的“标准”logger,可以通过调用函数Print系列(Print|Printf|Println)、Fatal系列(Fatal|Fatalf|Fatalln)、和Panic系列(P…
![[附源码]计算机毕业设计JAVA医院挂号管理系统](https://img-blog.csdnimg.cn/b659e39d22824c08a3894ceb5125c7ae.png)
[附源码]计算机毕业设计JAVA医院挂号管理系统
[附源码]计算机毕业设计JAVA医院挂号管理系统
项目运行
环境配置:
Jdk1.8 Tomcat7.0 Mysql HBuilderX(Webstorm也行) Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术:
SSM mybati…

简单的咖啡文化静态HTML网页设计作品 DIV布局咖啡馆文化网页模板代码 DW咖啡网站制作成品
🎉精彩专栏推荐 💭文末获取联系 ✍️ 作者简介: 一个热爱把逻辑思维转变为代码的技术博主 💂 作者主页: 【主页——🚀获取更多优质源码】 🎓 web前端期末大作业: 【📚毕设项目精品实战案例 (10…

达梦安装目录各个文件夹解析
达梦安装目录各个文件夹解析
总览: 1、bin目录 bin目录:存放常用命令和.so(shared object)文件(动态链接库类似Windows的ddl文件、Linux的lib目录) 2、bin2目录 bin2目录:存放utf8的lib库 3、data目录 data目录&#…

LeetCode 744. 寻找比目标字母大的最小字母
🌈🌈😄😄 欢迎来到茶色岛独家岛屿,本期将为大家揭晓LeetCode 744. 寻找比目标字母大的最小字母 ,做好准备了么,那么开始吧。 🌲🌲🐴🐴 一、题目名…

Centos7 内核升级(5.4.225)
文章目录一、背景二、在线 yum 安装1)查看当前内核版本信息2)导入仓库源3)选择 ML 或 LT 版本安装4)设置启动5)生成 grub 配置文件6)重启7)验证是否升级成功8)删除旧内核(…


CommonsCollections4利用链分析
目录
前言:
0x01 代码分析 总结一下利用链:
POC:
完整的POC: 图 1-1 cc利用链前言: CC4这条链用到了新的Commons-Collections4这个依赖,由于这个依赖与之前的版本具有较大的出入,连groupId和artifactId…

Android 基础知识4-2.1常用控件文本框(TextView)
TextView就是用来显示文本标签的控件,修改使用TextView显示文本的颜色、大小等属性。 实例代码:
xml:
<?xml version"1.0" encoding"utf-8"?>
<LinearLayout xmlns:android"http://schemas.android.co…
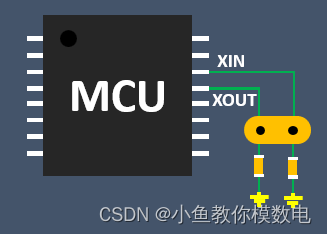
有源晶振与无源晶振的区别
今天就来和大家分享下有源晶振和无源晶振的区别。
1.从外形上有源大部分有源晶振是这种四脚贴片的,差分有源晶振的话一般是6脚的,当然还有其它的一些封装 而无源晶振的有两脚插件的也有和有源晶振一样的这种四脚贴片的 2.无源晶振不需要额外供电&#x…

.移动端适配的解决方案
何为移动端适配
移动端适配就是值在不同的移动端 可以去讲我们的内容适应不同屏幕尺寸大小
我们之前写单位用的是px这个单位 但是这是一个写死的单位
rem
所以我们用一个可变的单位 rem
(是指用html字体大小作为单位 比如说我们设置html字体大小为16px
那么
…
![[附源码]计算机毕业设计基于springboot的残障人士社交平台](https://img-blog.csdnimg.cn/e2c1757cf3184c4fada58934dfff9f9a.png)
[附源码]计算机毕业设计基于springboot的残障人士社交平台
项目运行
环境配置:
Jdk1.8 Tomcat7.0 Mysql HBuilderX(Webstorm也行) Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术:
SSM mybatis Maven Vue 等等组成,B/S模式 M…

一篇文章了解MySQL的group by
准备工作!
1.本文章MySQL使用的是5.7,引擎使用的是innodb 2. 使用的表结构(t1),字段a上有一个索引,
1. group by常用方法:
group by的常规用法是配合聚合函数,利用分组信息进行统…

公众号网课查题接口使用方法
公众号网课查题接口使用方法
本平台优点: 多题库查题、独立后台、响应速度快、全网平台可查、功能最全!
1.想要给自己的公众号获得查题接口,只需要两步! 2.题库:
题库:题库后台(点击跳转&…