准备工作!
1.本文章MySQL使用的是5.7,引擎使用的是innodb
2. 使用的表结构(t1),字段a上有一个索引,

1. group by常用方法:
group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤。
聚合函数:
- count(),返回指定列中数据的个数
- sum(),返回指定列中数据的总和
- avg(),返回指定列中数据的平均值
- min(),返回指定列中数据的最小值
- max(),返回指定列中数据的最大值
示例1: 查询t1表,按照字段b进行分组,并求出分组后b字段a的总和。
SELECT MAX(a) from t1 GROUP BY b
实例2:查询t1表,按照字段b进行分组,拿到b<100的所有数据,求出a的总和。
SELECT MAX(a) from t1 GROUP BY b HAVING b<100
where和having区别
where子句将单个行过滤到查询结果中,而having子句将分组过滤到查询结果中 having子句中使用的列名必须出现在group by子句列表中,或包括在聚集函数中。
having子句的条件运算至少包括一个聚集函数,否则可以把查询条件移到where字句中来过滤单个行(注意聚集函数不可以用在where子句中)
2. group by语句执行流程:
我们执行以下语句
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100
查看explain执行情况,由于b字段上没有索引,所以进行全表扫描。

Using temporary; 表示使用了临时表;
Using filesort ,表示需要排序。
由于字段b上没有索引,它的执行顺序是这样的
- 创建内存临时表,表里有两个字段 b 和 c,主键是 b;
- 对t1表进行全表扫描,并取出第一条数据,判断b是否小于100。如果b<100,就记录b的值为X,并存入临时表。
1.如果临时表中没有主键为b的行,就插入一条记录 b,c(x,1)
2.如果临时表中有主键为b的行,就更新主键为b的这一行,并把c的值进行加1 - 遍历完成后,再根据字段 b做排序,得到结果集返回给客户端。
在MySQL当中排序有两种
第一种是 全字段排序 ,第二种是 rowid 排序。 具体可以通过我的这篇文章去了解一篇文章搞懂MySQL的order by
3.使用group by会有哪些问题:
我们执行以下语句
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100
在上述中,由于b字段没有索引,索引MySQL默认会对此语句进行排序。相信你也看了我的一篇文章搞懂MySQL的order by这篇文章,也了解了MySQL什么时候会用全字段排序,什么时候用 rowid 排序。
1. 使用磁盘临时文件进行排序
在此语句中,优化器使用的是全字段排序,那么使用全字段排序会有哪些问题?
在全字段排序中,它是通过sort_buffer进行排序,定义如下。
sort_buffer_size:就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
假如我们如下SQL语句查出有1亿行,这时由于我们查询数据大小超过了定义的 临时排序文件( sort_buffer_size)的大小时,
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100000000
那么,这时就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 n份,每一份单独排序后存在这些临时文件中。然后把这n个有序文件再合并成一个有序的大文件。由于分成的的临时文件很多,就会造成排序的性能很差。
2. 查询数据超过临时文件大小(tmp_table_size)
这个例子里由于临时表只有 100 行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限制的,参数 tmp_table_size 就是控制这个内存大小的,默认是 16M。接下来我把tmp_table_size大小改成1kb。
假如我们如下SQL语句查出有1亿行,这时由于我们查询数据大小超过了定义的 临时文件( tmp_table_size)的大小时。
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100000000
那么,这时就会把内存临时表转成磁盘临时表(磁盘临时表默认使用的引擎是 InnoDB)。由于我们数据量很大,很可能这个查询需要的磁盘临时表就会占用大量的磁盘空间。
4.group by的优化方法:
我们还是以这条SQL语句为准
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100
1. 如果你的需求并不需要对结果进行排序,那你可以在 SQL 语句末尾增加 order by null
explain SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100 ORDER BY null
查看explain 结果
Using temporary; 表示使用了临时表;
2. 可以对group by字段建立索引
众所周知,由于我们MySQL的InnoDB引擎使用的数据结构是B+树,而B+树相比于B树最显著的特征就是B+树叶子节点是一个有序的双向列表。既然他已经有序了,那么我们是不是可以直接不进行排序了。
我们执行以下SQL语句,并在字段b上建立索引
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100
查看explain执行情况,没有进行排序,没有使用临时文件

Using index;使用了覆盖索引。
由于字段b上有索引,它的执行顺序是这样的
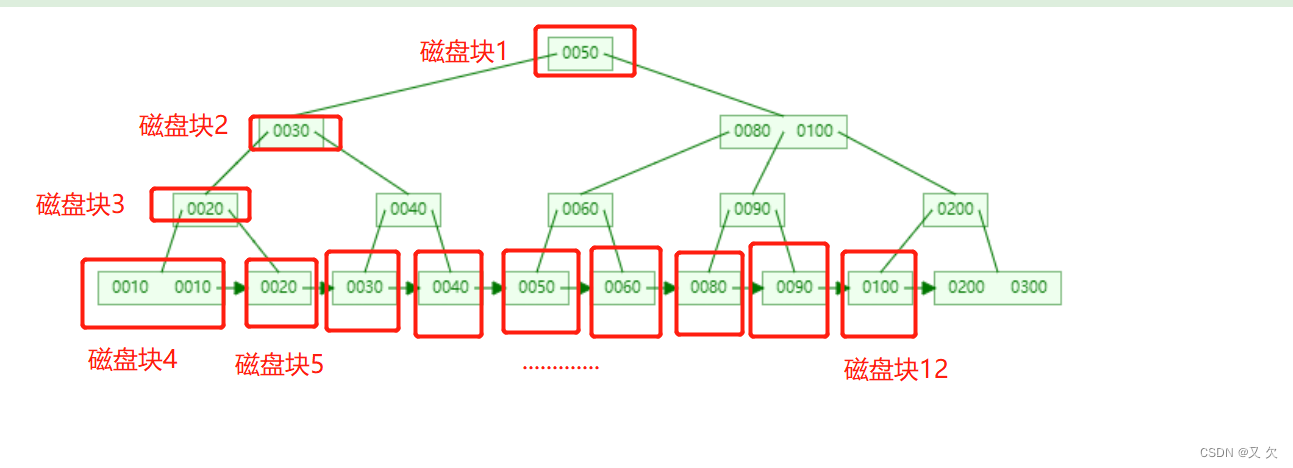
执行流程:
-
扫描t1表的索引b,读取磁盘块1,将磁盘块加载到内存中判断50是否小于100,是就走左边,不是就走右边。
-
扫描磁盘块2,将磁盘块加载到内存中判断判断30是否小于100,是就走左边,不是就走右边。
-
读取磁盘块3,将磁盘块加载到内存中判断判断20是否小100,是就走左边,不是就走右边。
-
读取磁盘块4也就是叶子节点,它是一个有序的链表。从键值10开始向后遍历筛选所有符合筛选条件的数据,并将符合筛选条件的data值数据缓存到结果集。(因为是双向有序的,所以会依次读取,并不需要回到父节点。因此当读取到20后会直接读取磁盘块5)
1.当碰到第一个 10 的时候,结果集里的第一行就是 (10,1);
2.当碰到第二个 10 的时候,已经知道累积了 1 个 10,修改结果集里的第一行为(10,2); -
当依次读取导磁盘块12后,将磁盘块加载到内存中判断100是否小于100,不是;就不需再向后查找,查询终止。将结果集返回给用户。
因此当我们扫描到整个输入的数据结束,就可以拿到 group by 的结果,不需要临时表,也不需要再额外排序。
3. group by字段无法建立索引时
如果可以通过加索引来完成 group by 逻辑就再好不过了。但是,如果碰上不适合创建索引的场景,我们还是要老老实实做排序的。那么,这时候的 group by 要怎么优化呢?
如果我们明明知道,一个 group by语句中需要放到临时表上的数据量特别大,却还是要按照“先放到内存临时表,插入一部分数据后,发现内存临时表不够用了再转成磁盘临时表”,这样看上去就有点儿傻。
我们执行以下SQL语句,并使用 SQL_BIG_RESULT(SQL_BIG_RESULT告诉mysql的分组语句必须使用磁盘临时表)
SELECT SQL_BIG_RESULT b, count(*) as c from t1 GROUP BY b HAVING b<100
查看explain执行情况
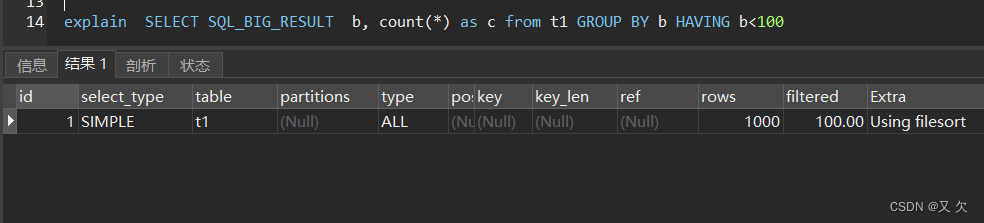
Using filesort 表示需要排序。
执行流程:
- .初始化 sort_buffer,确定放入一个整型字段,记为 b;
- . 扫描表 t1 ,依次取出里面b<100的值, 将b的值存入 sort_buffer 中;
- . 扫描完成后,对 sort_buffer 的字段 b 做排序(如果 sort_buffer 内存不够用,就会利用磁盘临时文件辅助排序);
- . 排序完成后,就得到了一个有序数组。
在根据有序数组,得到数组里面的不同值,以及每个值的出现次数。
5. MySQL8.0之后版本的group by
我们还是以这条SQL语句为准(MySQL版本8.0.26)
SELECT b, count(*) as c from t1 GROUP BY b HAVING b<100
查看explain执行情况

Using temporary; 表示使用了临时表;
group by 在 MySQL5.7 版本会自动排序,但是在MySQL8 .0之后版本就去掉了自动排序功能。
6.总结
1.如果对 group by 语句的结果没有排序要求,要在语句后面加 order by null;
2.尽量让 group by 过程用上表的索引,确认方法是 explain 结果里没有 Using temporary 和 Using filesort;
3.如果 group by 需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大 tmp_table_size 参数,来避免用到磁盘临时表;
4.如果数据量实在太大,使用 SQL_BIG_RESULT 这个提示,来告诉优化器直接使用排序算法得到 group by 的结果。
5.group by 在 MySQL5.7 版本会自动排序,但是在MySQL8 .0之后版本就去掉了排序功能。





![[附源码]计算机毕业设计JAVA医药管理系统](https://img-blog.csdnimg.cn/d8d2cad4211d4e8ca258ad6f9ac2bd18.png)
![[附源码]计算机毕业设计JAVA医院床位管理系统](https://img-blog.csdnimg.cn/07358283159d418cb19376b0f9f84f83.png)