论文笔记--Efficient Estimation of Word Representations in Vector Space
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 NNLM(Neural Network Language Model)
- 3.1.1 NNLM
- 3.1.2 RNNLM(Recurrent Neural Net Language Model)
- 3.2 Continuous Bag-of-Words Model(CBOW)
- 3.3 Continuous Skip-gram Model
- 4. 数值实验
- 5. 文章亮点
- 6. 原文传送门
- 6. References
1. 文章简介
- 标题:Efficient Estimation of Word Representations in Vector Space
- 作者:Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
- 日期:2013
- 期刊:arxiv preprint
2. 文章概括
文章提出了两种Word2Vec模型(CBOW, Skip-gram),可以在大量的语料库上快速训练出高质量的词向量。且Word2Vec的词向量不仅可以保持相似单词的词向量相近,还可以保持词向量之间的线性操作(如
K
i
n
g
−
m
a
n
+
w
o
m
a
n
≈
Q
u
e
e
n
King-man+woman \approx Queen
King−man+woman≈Queen)。
由于训练方法相比于传统的NNLM(Neural Network Language Model)更快,文章可以在更大的数据集上训练更高维度的词向量,从而词向量表达更丰富。数值实验表明Word2Vec得到的词向量质量更高(见第四节)。
3 文章重点技术
3.1 NNLM(Neural Network Language Model)
3.1.1 NNLM
Word2Vec的基本架构基于[1]提出的NNLM。所谓LM(Language Model,语言模型),即通过前面的token预测当前的token。如下图所示,在输入层,给定当前单词的上文n个单词,模型首先对每个单词进行编码。NNLM采用的编码方式为Table look-up,即通过预先定义的hash表对一些常见的token进行映射,使用时直接查找当前token在映射表
C
\mathcal{C}
C中对应的编码即可。得到当前时刻
t
t
t对应的
N
N
N(对应图中的
n
n
n)个上文的编码分别为
C
(
w
t
−
N
)
,
…
,
C
(
w
t
−
1
)
C(w_{t-N}), \dots, C(w_{t-1})
C(wt−N),…,C(wt−1),其中每个token的编码
C
t
−
i
∈
R
D
,
i
=
1
,
…
,
N
C_{t-i}\in \mathbb{R}^D, i = 1, \dots, N
Ct−i∈RD,i=1,…,N。我们将查表映射这一步称为project,得到的编码层为projection layer,维度为
R
N
×
D
\mathbb{R}^{N\times D}
RN×D。这一步骤的计算量为
N
×
D
N\times D
N×D
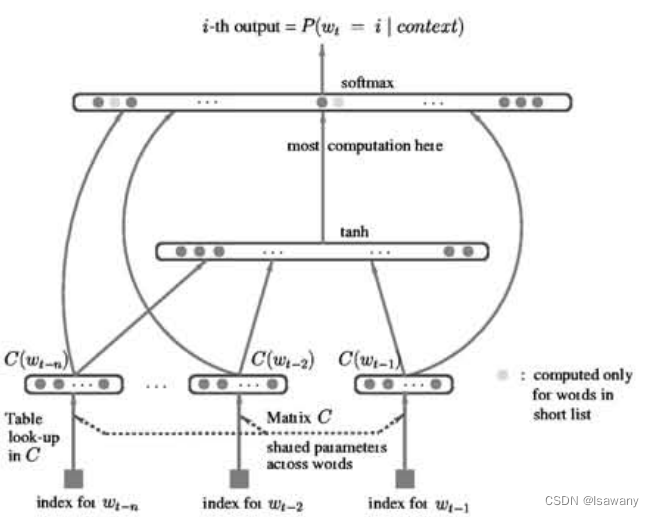
得到projection layer之后,我们将其映射到大小为
H
H
H的隐藏层,这一步骤的计算量为
N
×
D
×
H
N\times D \times H
N×D×H。
最后传入到Softmax输出层预测词表中每个单词的输出概率,输出概率最大的token。这一步骤需要将隐藏层映射到每个词表中的token(共
V
V
V个token),计算量最大(因为一般来说
V
≫
H
,
V
≫
D
V\gg H, V\gg D
V≫H,V≫D),计算量为
H
×
V
H\times V
H×V。
NNLM的总计算量为
N
×
D
+
N
×
D
×
H
+
H
×
V
N\times D + N \times D \times H + H \times V
N×D+N×D×H+H×V。
3.1.2 RNNLM(Recurrent Neural Net Language Model)
上述NNLM需要指定上下文的大小
N
N
N,不易捕捉长期依赖,从而RNNLM[2]应运而生。如下图所示,RNNLM没有映射层,只有输入层、隐藏层和输出层。不同于NNLM,模型的输入为当前时刻的编码
I
n
p
u
t
(
t
)
=
w
t
−
i
∈
R
H
,
i
=
1
,
…
,
N
Input(t) = w_{t-i}\in\mathbb{R}^{H}, i=1, \dots, N
Input(t)=wt−i∈RH,i=1,…,N(考虑词维度等于隐藏层维度的情况),将其映射到大小为
H
H
H的隐藏层,隐藏层不仅基于
I
n
p
u
t
(
t
)
Input(t)
Input(t),而且要考虑上一个时刻的隐藏层
C
o
n
t
e
x
t
(
t
−
1
)
Context(t-1)
Context(t−1),即
C
o
n
t
e
x
t
(
t
)
=
f
(
C
o
n
t
e
x
t
(
t
−
1
)
,
I
n
p
u
t
(
t
)
)
Context(t) = f(Context(t-1), Input(t))
Context(t)=f(Context(t−1),Input(t))。最后输出层同NNLM。从而RNNLM的计算量为
2
×
H
×
H
+
H
×
V
2\times H \times H + H \times V
2×H×H+H×V
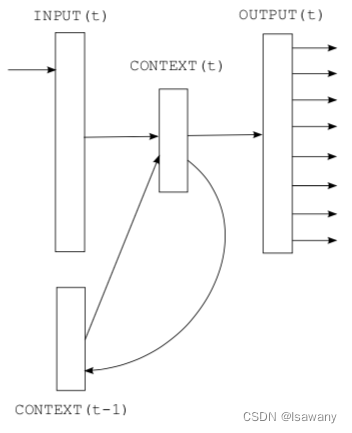
3.2 Continuous Bag-of-Words Model(CBOW)
文本基于上述NNLM提出了两种词向量训练方法:CBOW和Skip-gram。传统BOW(词袋模型)单纯基于token的计数给出词向量表达,而本文的CBOW给出了词向量在高维空间的连续嵌入。之所以命名为CBOW是因为模型未考虑上下文单词的顺序。
下图给出了CBOW的模型架构。如图,在
t
t
t时刻,模型接受其上下文
N
N
N个单词作为输入(图中给出
N
=
2
N=2
N=2的示意),然后将上下文映射到projection layer(维度为D),再得到输出。和NNLM不同的是,这里我们移除了hidden layer层,且所有token共用同一个projection layer。
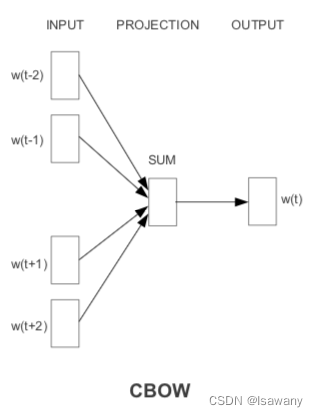
CBOW的计算量为
N
×
D
+
D
×
log
2
(
V
)
N\times D + D \times \log_2(V)
N×D+D×log2(V)。其中文章采用了hierarchical Softmax将
D
×
V
D\times V
D×V计算量缩减为
D
×
log
2
(
V
)
D\times \log_2(V)
D×log2(V)。
3.3 Continuous Skip-gram Model
文章提出的第二种训练方法为Skip-gram。上述CBOW是通过当前词的上下文预测当前词,Skip-gram则是通过当前词预测当前词的上下文,预测难度更高,且上下文窗口越大,预测难度越高。Skip-gram的架构如下图所示。
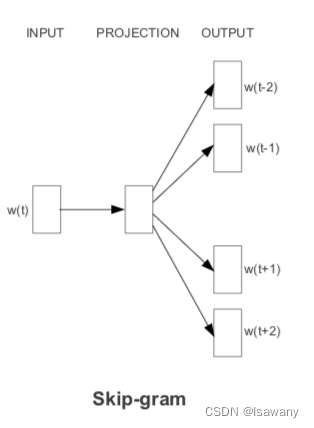
Skip-gram的计算量为
N
×
(
1
×
D
+
D
×
log
2
(
V
)
)
N \times (1\times D + D \times \log_2(V) )
N×(1×D+D×log2(V))。
4. 数值实验
为了评估词向量的质量,文章定义了5种语义问题和9种语法问题,如下表所示。给定word pair1(w1, w2)和word pair2的第一个单词(w3),我们计算
w
3
−
(
w
1
−
w
2
)
w3-(w1-w2)
w3−(w1−w2),在词表中找到和该向量最接近的单词作为结果。比如给定(Athens, Greece)和(Oslo, ?),模型预测的结果为Norway时才认为是正确的,其它任何答案均不正确。
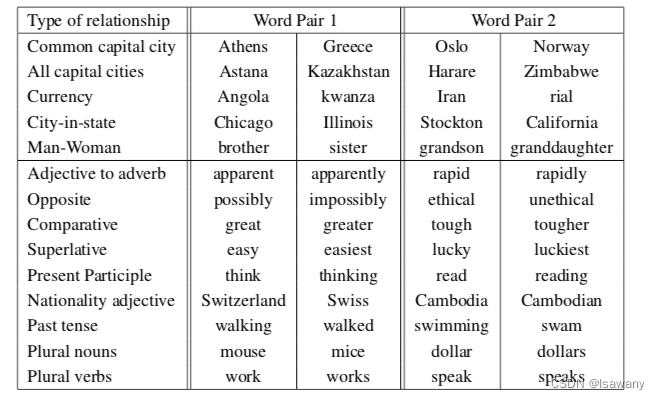
上述9个任务的评估结果如下表所示,CBOW和Skip-gram的准确率远高于NNLM。
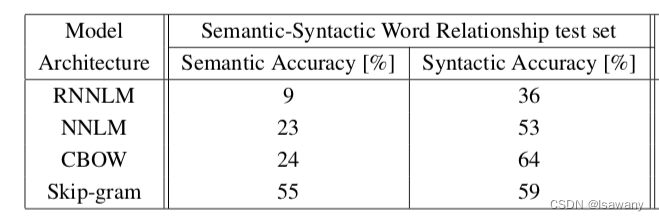
此外,因为无需计算复杂的隐藏层,Word2Vec的训练成本也很乐观。
5. 文章亮点
文章给出了两种基于改良版NNLM的Word2Vec模型:CBOW和Skip-gram,可以高效的在大量语料库上给出高质量的词向量嵌入,从而满足下游NLP任务的需求。在GPT、BERT等模型提出之前,Word2Vec一直是NLP预训练词嵌入的一种受欢迎的选择,但Word2Vec未考虑上下文的顺序,且无法处理多义词。而基于Transformer的模型有效的解决了Word2Vec的不足,感兴趣的读者可阅读BERT和GPT系列文章[3][4]。
6. 原文传送门
Efficient Estimation of Word Representations in Vector Space
6. References
[1] A Neural Probabilistic Language Model
[2] Recurrent neural network based language model
[3] BERT系列文章阅读
[4] ChatGPT+自定义Prompt=发文神器