上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。
MapReduce是一个经典的大数据处理框架,可以帮助我们高效地处理庞大的数据集。本文将介绍MapReduce的基本原理和实现方法,并给出一个简单的示例。
一、MapReduce基本原理
MapReduce的基本原理包括两个阶段:Map和Reduce。
1、Map阶段
Map阶段的作用是将原始输入数据分解成一组键值对,以便后续的处理。在Map阶段中,开发者需要定义一个Map函数来完成具体的数据处理工作。Map函数的输入参数是一组键值对,包括输入数据的键和值。Map函数的输出结果也是一组键值对,其中键是经过处理后的值,而值则是与该键相关的计数器。
2、Reduce阶段
Reduce阶段的作用是将Map阶段输出的大量中间结果进行归并,得到最终的输出结果。在Reduce阶段中,开发者需要定义一个Reduce函数来完成具体的数据处理工作。Reduce函数的输入参数是一组键值对,其中键是之前Map阶段输出的键值对中的键,而值则是之前Map阶段输出的键值对中与该键相关的计数器。Reduce函数的输出结果可以是任何类型的数据,用于满足特定的业务需求。
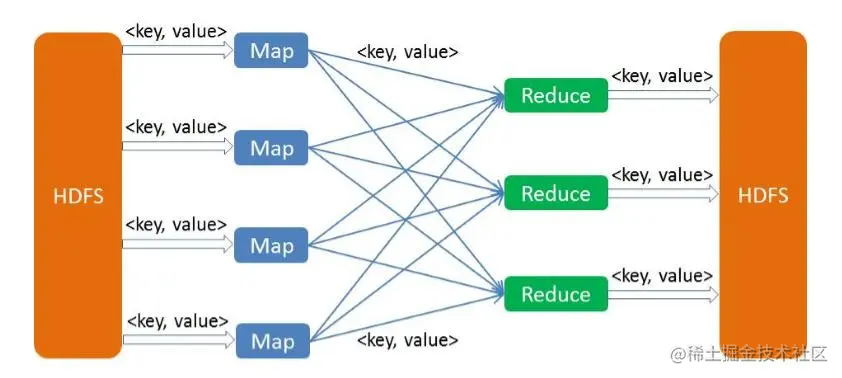
二、MapReduce实现方法
MapReduce的实现方法包括以下几个步骤:
1、数据的划分和分发
在MapReduce中,输入数据被划分成多个数据块,每个数据块由一个Map任务处理。数据块的大小一般为64MB或128MB。划分后,数据块会被分发到不同的计算节点上。
2、Map阶段的执行
Map任务的输入是数据块,输出是键值对列表。开发者需要编写Map函数,将输入数据转换成一组键值对列表。为了提高Map任务的执行效率,通常会使用数据本地化技术,即将存储在相同计算节点上的数据块优先分配给Map任务进行处理。
3、Shuffle阶段的执行
在Shuffle阶段中,Map任务产生的中间结果会被发送到Reduce任务所在的节点。在该阶段中,需要进行复杂的数据传输和数据排序任务。Shuffle阶段的目标是将Map任务产生的中间结果进行合并和排序,以便Reduce任务能够高效地处理。
4、Reduce阶段的执行
在Reduce阶段中,开发者需要编写Reduce函数来处理Map任务产生的中间结果。Reduce任务的输入是键值对列表,输出是特定业务需求的结果。
三、MapReduce示例
下面给出一个简单的WordCount示例,来说明MapReduce的实际应用。
WordCount示例程序输入一个文本文件,计算该文件中每个单词出现的次数。程序的实现步骤如下:
1、Map函数实现
Map函数的输入是一行文本,输出是每个单词作为键,对应的计数器作为值的键值对列表。
public class MapFunction extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// 使用正则表达式匹配单词
Pattern pattern = Pattern.compile("\w+");
Matcher matcher = pattern.matcher(line);
while (matcher.find()) {
word.set(matcher.group());
context.write(word, ONE);
}
}
}
2、Reduce函数实现
Reduce函数的输入是每个单词作为键,对应的计数器作为值的键值对列表,输出是每个单词和对应的计数器之和。
public class ReduceFunction extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
3、MapReduce程序的运行
将Map函数和Reduce函数放到一个MapReduce作业中,然后提交到Hadoop集群中执行即可。
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MapFunction.class);
job.setReducerClass(ReduceFunction.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
四、总结
本文介绍了MapReduce的基本原理和实现方法,并给出了一个简单的WordCount示例。MapReduce是大数据处理领域的经典框架,对于处理庞大的数据集十分有效。开发者可以通过实现Map函数和Reduce函数来构建自己的数据处理应用程序,并通过MapReduce框架来实现高效的数据处理。