文章目录
- 一.基础命令
- 1.grep命令
- 1.1grep格式
- 1.2grep命令选项
- 2.特殊的符号
- 2.1空行——^$
- 2.2以什么为开头—^,以什么为结尾—$
- 2.2.1以什么为开头的格式:
- 2.2.2以什么为结尾的格式:
- 3.只匹配单行——^匹配的字符$
- 二.文本处理命令
- 1.sort命令
- 1.1命令解释及格式
- 1.2常用选项
- 2.uniq命令——快捷去重
- 2.1 格式
- 2.2常用选项
- 3.tr命令
- 3.1语法格式:
- 3.2常用选项:
- 4.cut命令——快速裁剪
- 4.1cut截取方法
- 4.2格式
- 4.3选项
- 4.4示例
- 5.split——文件拆分
- 5.1格式
- 5.2选项
- 5.3示例
- 6.paste——合并文件
- 6.1格式
- 6.2选项
- 7.拓展
- 7.1统计当前主机的连接状态
- 7.2统计当前连接主机数
一.基础命令
1.grep命令
对文本的内容进行过滤,针对行处理
1.1grep格式
grep [选项]…查找条件 目标文件
1.2grep命令选项
-m+数字——————匹配几次后停止
eg:grep -m 1 root /etc/passwd————————————多个匹配只取
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LSGtYGYq-1685701824028)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602142246571.png)]](https://img-blog.csdnimg.cn/34ee2a77e7eb48a6b70ebf46b54846e4.png)
-v ————————取反
eg:grep -v root /etc/passwd————————————————除了root其余展示出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hdofBbgk-1685701824030)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602142742489.png)]](https://img-blog.csdnimg.cn/6f28ef14501d471f808aafd807cab979.png)
-i —————————忽略字符大小写
eg:grep -i Root /etc/passwd————————————————不考虑大小写展示出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7XPNWlym-1685701824030)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602143112862.png)]](https://img-blog.csdnimg.cn/7ee0aed883654d82a9776294f550c5c8.png)
-n——————————显示匹配行号
eg:grep -n root /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ot6zA9kt-1685701824031)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602143425384.png)]](https://img-blog.csdnimg.cn/c569ad1eac364b83aae502a70a86c069.png)
-c—————————只显示匹配行号
eg:grep -c root /etc/passwd

-o——————————仅显示匹配到的字符串
eg:grep -o root /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m1E7px8O-1685701824031)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602143847711.png)]](https://img-blog.csdnimg.cn/721cab7de80f41e4a4246ed3cd931898.png)
-A——————————匹配自身当前行的后三行,包含自身展示出来
eg:grep -A 3 zjf /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PdGNFTln-1685701824032)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602144329840.png)]](https://img-blog.csdnimg.cn/e5c627630f2b4b8eb54c17d8dbdbfd7c.png)
-B————————————自身前几行包含自身展示
eg:grep -B 3 zjf /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iUFvCwAK-1685701824032)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602144549223.png)]](https://img-blog.csdnimg.cn/40194b99dc8b4de69d0133aaa8635d4b.png)
-C————————————本身的前三行和后三行以及本身展示出
eg:grep -C 3 zjf /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dRwgv3Nq-1685701824032)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602144954638.png)]](https://img-blog.csdnimg.cn/c0c1de70d27f439dbf87332d66e50d93.png)
-e——————————————逻辑或,可以跟多个条件,若有显示,没有不显示
eg:grep -e root -e bash /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JpntENZ6-1685701824033)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602145747572.png)]](https://img-blog.csdnimg.cn/4198532d2ab84840b766e4888788d0d9.png)
-w————————————匹配整个单词
eg:grep -w root /etc/passwd
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JIaL32hd-1685701824033)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602150124918.png)]](https://img-blog.csdnimg.cn/6eb85a315f154229bf2c756a5bf39121.png)
-E——————————表示使用扩展正则相当于egrep
-f——————————根据模式文件处理两个文件的相同内容,第一个文件作为匹配条件
eg:grep -f 123.txt 456.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BW9744BW-1685701824033)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602150904558.png)]](https://img-blog.csdnimg.cn/cbaf9c46a51b4eaf9585beed2467827b.png)
-r——————————递归目录文件当中的文件内容所包含的想要的文件内容
不对软链接处理
eg:grep -r a /opt/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3wS0pJA5-1685701824034)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602151623970.png)]](https://img-blog.csdnimg.cn/a11858d5864d42d187677cd023a9baf9.png)
-R——————————可以处理软链接中的文件内容
eg:grep -R a /opt/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTDTBiia-1685701824034)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602151836620.png)]](https://img-blog.csdnimg.cn/79c1448e88c24591a2849966115eac01.png)
2.特殊的符号
2.1空行——^$
示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JbtVhtJI-1685701824034)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602152458433.png)]](https://img-blog.csdnimg.cn/9bc1fa9c6d9c4325813d39b2c56ac87f.png)
cat 123.txt | grep -v "^$" > test.txt————过滤掉123.txt里的空行将内容传送给test.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e5ICWYj4-1685701824034)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602152740158.png)]](https://img-blog.csdnimg.cn/733ad3f375024b34a5972e0f4f7a7584.png)
2.2以什么为开头—^,以什么为结尾—$
2.2.1以什么为开头的格式:
grep “^所要让开头的字符” 文件名
示例:
grep "^4" 123.txt
grep "^a" 123.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iqPWm943-1685701824035)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602153842148.png)]](https://img-blog.csdnimg.cn/215156a912f54ba49180f2fe984987b8.png)
2.2.2以什么为结尾的格式:
grep “^所要让开头的字符” 文件名
示例:
grep "h$" 123.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3mRCVGV6-1685701824035)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602154141168.png)]](https://img-blog.csdnimg.cn/7902f6a7eefb473b9ee340517864f6bf.png)
3.只匹配单行——^匹配的字符$
格式:
^匹配的字符$
示例:
grep -n "^root$" dh.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5A2oWdb5-1685701824035)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602154717545.png)]](https://img-blog.csdnimg.cn/2c9ca45592d249f0a36b7034050b6267.png)
二.文本处理命令
1.sort命令
1.1命令解释及格式
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
语法格式:
sort 选项 参数
1.2常用选项
-f————————————————忽略大小写,默认会大写字母排在前面
eg:sort -f test.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PSt7vCAL-1685701824036)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602155817235.png)]](https://img-blog.csdnimg.cn/da665dede58347c4bf98d836be27c3bf.png)
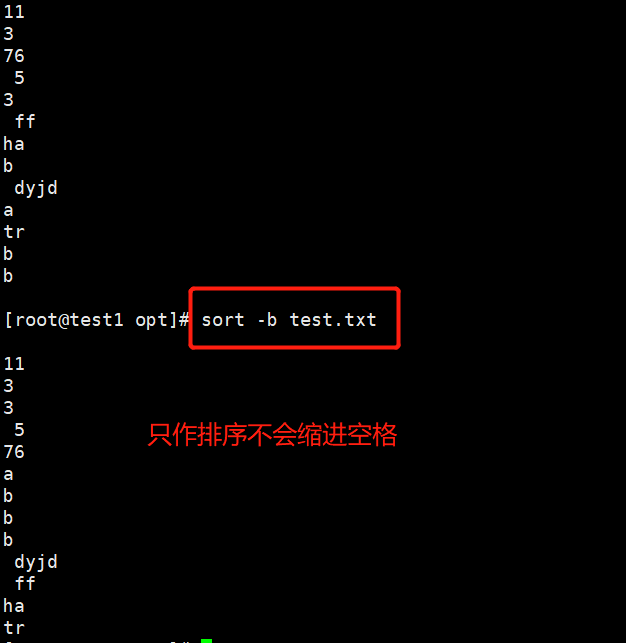
-b——————————————只排序不会忽略空格,忽略每行前面的空格
eg:sort -b test.txt
-n:按照数字进行排序
eg:sort -n test.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-17mYvmVR-1685701824036)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602160733689.png)]](https://img-blog.csdnimg.cn/f1bd3c73bb2c4c4bb85ad218a13cd85a.png)
-r:针对字母的反向排序
eg:sort -r test.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tw3X42Ni-1685701824036)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602161202272.png)]](https://img-blog.csdnimg.cn/8dc7c0b752b3476585b03b47096f8203.png)
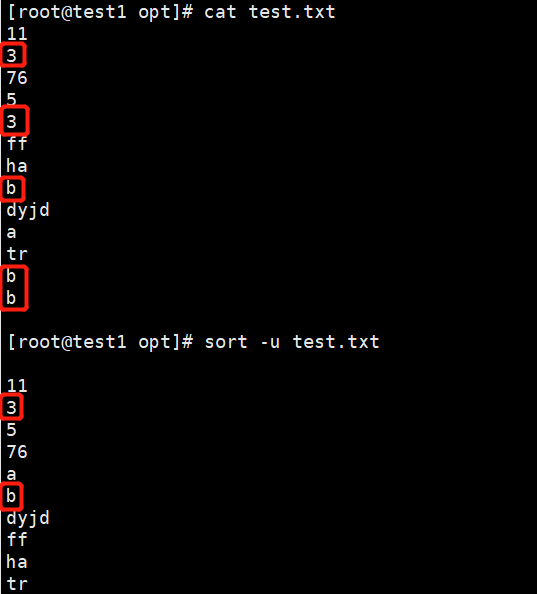
-u:等同uniq,表示相同的数据仅显示一行,去重
eg:sort -u test.txt
-o <输出文件>:将排序后的结果转存至指定文件
eg:cat /opt/test.txt | sort -o zjf.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vtzIn0Ba-1685701824037)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602162550200.png)]](https://img-blog.csdnimg.cn/5db97dae6c284bf0a38b46cd7b2ead2f.png)
按原来的行一模一样的传到新的文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RUCg5lXV-1685701824037)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602162917014.png)]](https://img-blog.csdnimg.cn/d3b4cca3a09b4a5db7f09c8ad2e3eb18.png)
2.uniq命令——快捷去重
uniq命令用于报告或者忽略文件中连续的重复行,常与sort命令结合使用。
2.1 格式
uniq [选项] 参数
cat 文件| uniq 选项
2.2常用选项
-c——————————————统计连续重复的行的次数,并且合并重复的行
eg:uniq -c test1.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xuEVhMlb-1685701824038)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602164512538.png)]](https://img-blog.csdnimg.cn/8428d15f78504773bc525afb641d0e16.png)
去重排序:
cat test1.txt | uniq -c test1.txt | sort -n
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-etBlhPsj-1685701824038)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602164711073.png)]](https://img-blog.csdnimg.cn/296b940810f145578ee0c6ec43fd5861.png)
-u——————————————显示仅出现一次的行(包括不连续的重复行)
eg:uniq -u test1.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oDxAiuaq-1685701824038)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602165105360.png)]](https://img-blog.csdnimg.cn/71b880fc707e45bfab9748fed9029910.png)
-d 仅显示重复出现的行(必须是连续的重复行)
eg:uniq -d test1.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h9K2KTOc-1685701824039)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602165632674.png)]](https://img-blog.csdnimg.cn/ef12ffd1af724612b7a7ecb0a2d81dec.png)
3.tr命令
常用于对来自标准输入的字符进行替换、压缩和删除
参数:
字符集1:
指定要转换或删除的原字符集。当执行转换操作时,
必须使用参数”字符集2“指定转换操作时,必须使用参数”字符集2“指定转换的目标字符集。
但执行删除操作时,不需要参数”字符集2“
字符集2:
指定要转换成的目标字符集
3.1语法格式:
tr 选项 参数
3.2常用选项:
-c:保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换
eg:echo abc | tr -c ‘ab’ ‘a’
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XvmdV6ji-1685701824039)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602175012821.png)]](https://img-blog.csdnimg.cn/793f3f2d21ec4e56a7e2e66fb6468b7a.png)
-d:删除所有属于字符集1的字符
eg:echo abc | tr -d ‘ab’————————删除ab,打印c
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CEJa77XG-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602175215342.png)]](https://img-blog.csdnimg.cn/8bb6fd568ad04ca899d8a4e88f7b2816.png)
-s:将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1
eg:cat xx.txt | tr -s “w” “b”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S8GV9VUl-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602180045338.png)]](https://img-blog.csdnimg.cn/f4f72e267b8a41c683174aa2c17bc9fb.png)
-t:字符集2 替换 字符集1,不加也行
eg:echo 192.168.198.11 | tr “.” “:”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p5gDSIG5-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602180239906.png)]](https://img-blog.csdnimg.cn/f7ca010434d648cfb7aa4a0f9cc86b12.png)
echo 192.168.198.11 | tr -d “.”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nsQ0jww-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602180334654.png)]](https://img-blog.csdnimg.cn/d83056e82ad04f64a89070a7681f49c0.png)
将 echo $PATH中的":"替换为换行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zKVyFMkw-1685701824040)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602180611435.png)]](https://img-blog.csdnimg.cn/e30b26e2873f40e9a7d412a9e6c4d327.png)
4.cut命令——快速裁剪
4.1cut截取方法
cut截取方法
对字段进行截取和剪裁
4.2格式
格式一:cut [选项] 参数
格式二:cat 文件名 | cut [选项]
4.3选项
-d 指定分隔符(默认分隔符为Tab)
-f 按字段进行截取。指定第n个字段;
-b 以字节为单位进行截取
-c 以字符为单位进行截取
–complement 排除所指定的字段
–output-delimiter 更改输出内容的分隔符
4.4示例
(1)cut -d ":" -f 1-3 /etc/passwd————————以":"作为分隔符,指定第一个到第三个字段进行输出
cat /etc/passwd | cut -d ":" -f 1-3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PWxTcPmg-1685701824041)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602181156535.png)]](https://img-blog.csdnimg.cn/86f31c0b530b470ab566d831ad33b389.png)
head -n 2 /etc/passwd | cut -d ":" --complement -f 2————————指定以":"作为分隔符,但是删除了第二个字段进行输出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XECcMAHA-1685701824041)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230602181541183.png)]](https://img-blog.csdnimg.cn/ee79f34f764b4937b4112e35a8f36dd1.png)
head -n 2 /etc/passwd | cut -d ":" --complement -f 1-5 --output-delimiter="@"——————————将分隔符转换为@,进行输出

5.split——文件拆分
split命令用于在Linux下将大文件拆分为若干小文件。
5.1格式
split 选项 参数 原始文件 拆分后文件名前缀
5.2选项
-l 指定行数对文件拆分
-b 指定文件的大小拆分
5.3示例
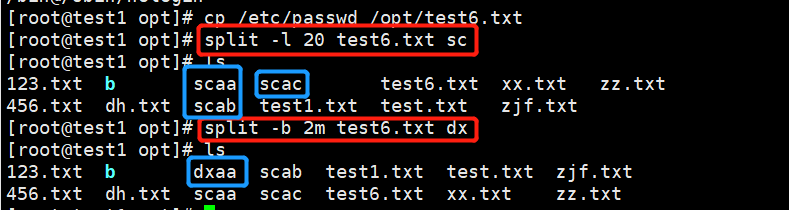
split -l 20 test6.txt sc
split -b 2m test6.txt dx
6.paste——合并文件
按照字段来进行文件的合并
6.1格式
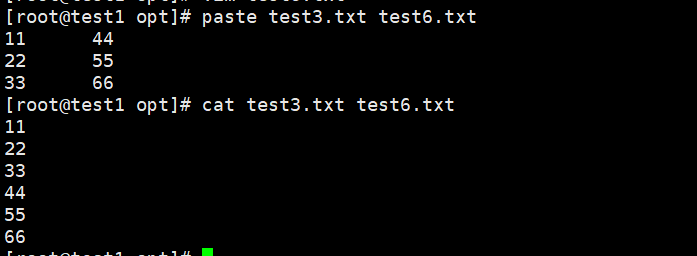
paste [选项] 文件1 文件2
6.2选项
-d 用于指定文件的分隔符(默认情况下为制表符"\n")
-s 将列和行的内容进行互相交换
paste和cat合并有什么区别
cat是上下合并
paste是左右合并
7.拓展
7.1统计当前主机的连接状态
ss -nta | grep -v ‘^State’ |cut -d " " -f 1| sort | uniq -c
3 ESTAB #表示建立的 TCP 连接处于活动状态
17 LISTEN
7.2统计当前连接主机数
ss -nt | tr -s " "|cut -d " " -f 5 | sort -n | uniq -c
1 Local
2 192.168.233.21:22