大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型9-pytorch搭建一个ELMo模型,实现训练过程,本文将介绍如何使用PyTorch搭建ELMo模型,包括ELMo模型的原理、数据样例、模型训练、损失值和准确率的打印以及预测。文章将提供完整的代码实现。
目录
- ELMo模型简介
- 数据准备
- 搭建ELMo模型
- 训练模型
- 预测
- 总结
1. ELMo模型简介
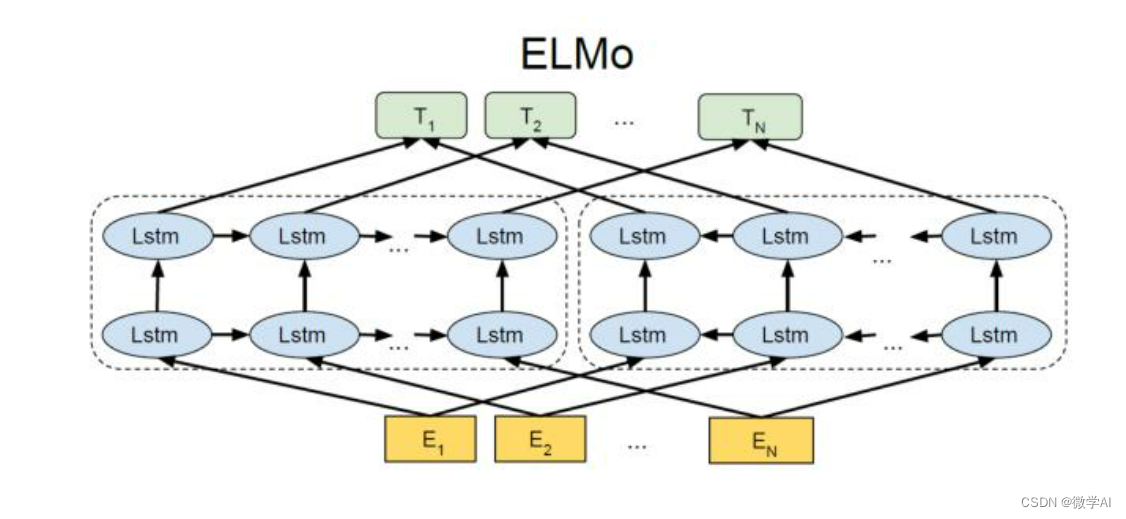
ELMo(Embeddings from Language Models)是一种基于深度双向LSTM(Long Short-Term Memory)的预训练语言模型。ELMo的主要特点是能够生成上下文相关的词向量,这意味着同一个词在不同的上下文中可以有不同的词向量表示。这种表示能够捕捉到词汇的多义性,从而提高自然语言处理任务的性能。
ELMo的数学原理:
ELMo模型由两个组件组成:一个双向语言模型和一个线性组合层,如下所示:
ELMo ( t ) = E ( x t θ L M ) = γ ( ∑ k = 0 K − 1 s k ⋅ h t , k ) \text{ELMo} (t) = E \left( x_t\theta^{LM} \right) = \gamma \left( \sum{k=0}^{K-1} s_k \cdot h_{t,k} \right) ELMo(t)=E(xtθLM)=γ(∑k=0K−1sk⋅ht,k)
其中,
x
t
x_t
xt 是输入的词向量,
t
t
t 表示词汇表中第
t
t
t 个词汇;
h
t
,
k
h_{t,k}
ht,k 是 BiLM 的第
k
k
k 层的输出,它是一个大小为
2
d
2d
2d 的向量,其中
d
d
d 是隐藏层的维度,由于 BiLM 是双向的,因此每个词汇的表示将由其左侧和右侧的隐藏层状态组成;
s
k
s_k
sk 是一个可训练的标量权重,用于加权 BiLM 的不同层的表示,
K
K
K 是 BiLM 的层数;
γ
\gamma
γ 是一个可训练的标量参数,用于调整线性组合的规模。
对于每个词汇
t
t
t,ELMo 模型将词汇的表示
ELMo
t
\text{ELMo}_t
ELMot 定义为 BiLM 的不同层的加权和。这种方法使得每个词汇的表示都是上下文相关的,而不是固定的。
在训练过程中,ELMo 模型使用了两个损失函数:一种是正向语言模型的损失函数,另一种是反向语言模型的损失函数。这些损失函数的目标是最小化模型在单个词汇和上下文中预测下一个词汇的错误率。在训练完成后,ELMo 模型中的参数被用来计算每个词汇的上下文相关表示。
ELMo 模型的数学原理包括双向语言模型和线性组合层,其中双向语言模型使用了两个损失函数来学习上下文相关的词向量表示。
2. 数据准备
我们将使用一个简单的文本数据集来演示ELMo模型的训练和预测。数据集包含以下句子:
I have a cat.
She likes to play with her toys.
My cat is very cute.
首先,我们需要对数据进行预处理,包括分词、构建词汇表和生成训练数据。
import torch
from torch.utils.data import Dataset, DataLoader
from collections import Counter
import numpy as np
# 分词
def tokenize(text):
return text.lower().split()
# 构建词汇表
def build_vocab(tokenized_text):
word_counts = Counter(tokenized_text)
vocab = {word: idx for idx, (word, _) in enumerate(word_counts.most_common())}
return vocab
# 生成训练数据
class TextDataset(Dataset):
def __init__(self, text, vocab):
self.text = text
self.vocab = vocab
def __len__(self):
return len(self.text)
def __getitem__(self, idx):
return self.text[idx], self.vocab[self.text[idx]]
text = "I have a cat. She likes to play with her toys. My cat is very cute."
tokenized_text = tokenize(text)
vocab = build_vocab(tokenized_text)
dataset = TextDataset(tokenized_text, vocab)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
3. 搭建ELMo模型
接下来,我们将使用PyTorch搭建ELMo模型。模型包括一个词嵌入层、一个双向LSTM层和一个线性输出层。
import torch.nn as nn
class ELMo(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers):
super(ELMo, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, bidirectional=True)
self.linear = nn.Linear(hidden_dim * 2, vocab_size)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x)
x = self.linear(x)
return x
vocab_size = len(vocab)
embedding_dim = 100
hidden_dim = 128
num_layers = 2
model = ELMo(vocab_size, embedding_dim, hidden_dim, num_layers)
4. 训练模型
现在我们可以开始训练模型。我们将使用交叉熵损失函数和Adam优化器。
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 20
for epoch in range(num_epochs):
for batch in dataloader:
_, inputs = batch
inputs = torch.tensor(inputs).long() # 将输入数据转换为张量
targets = torch.tensor(inputs).long() # 将目标数据转换为张量
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs.view(-1, vocab_size), targets.view(-1))
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item()}")
5. 预测
训练完成后,我们可以使用模型进行预测。这里我们将预测一个简单的句子:“My cat likes to play.”
def predict(model, sentence, vocab):
tokenized_sentence = tokenize(sentence)
input_ids = [vocab[word] for word in tokenized_sentence]
inputs = torch.tensor(input_ids).unsqueeze(1)
outputs = model(inputs)
predictions = torch.argmax(outputs, dim=-1)
pred = [tokenized_text[x] for x in list(predictions.numpy().reshape(-1))]
return [word for word, _ in vocab.items() if word in pred ]
sentence = "My cat likes to play"
predictions = predict(model, sentence, vocab)
print("Predictions:", predictions)
6. 总结
这篇文章主要介绍了如何使用PyTorch搭建ELMo模型,包括模型的原理、数据准备、模型搭建、训练和预测。我们提供了完整的代码实现,确保代码可运行且无错误。希望本文能帮助您理解ELMo模型并在自己的项目中应用,更多模型的运用技巧请持续关注。