一、问题描述
Python的自然语言处理库NLTK在安装之后需要下载一些data文件才能使用。官方比较推荐的方式是直接运行下载data的代码:
import nltk
nltk.download('punkt')但是实际操作之后发现由于网络原因无法下载成功。
除了运行代码之外,官方还推荐了两种下载数据包的方法:命令行执行安装命令以及手动添加。由于命令行执行安装命令也需要网络顺畅,跟运行代码本质上是一样的,所以我选择了比较稳妥的手动添加方式。
二、解决方法(以下载punkt相关数据为例)
第1步:先把全部data下载到电脑里。这里我提供一个我自己存放这些data的网盘地址: https://pan.baidu.com/s/1HrcWaPGAMx3eXouURHGZJA 提取码: 9aue
第2步:解压下载下来的data,存放到电脑里合适的位置。我放到了D:\nltk_data目录下。目录结构如图所示:
D:\nltk_data\
└─tokenizers
└─punkt
│ czech.pickle
│ danish.pickle
│ dutch.pickle
│ english.pickle
│ estonian.pickle
│ finnish.pickle
│ french.pickle
│ german.pickle
│ greek.pickle
│ italian.pickle
│ norwegian.pickle
│ portuguese.pickle
│ README
│ slovene.pickle
│ spanish.pickle
│ swedish.pickle
│ turkish.pickle
│
└─PY3
czech.pickle
danish.pickle
dutch.pickle
english.pickle
estonian.pickle
finnish.pickle
french.pickle
german.pickle
greek.pickle
italian.pickle
norwegian.pickle
portuguese.pickle
README
slovene.pickle
spanish.pickle
swedish.pickle
turkish.pickle
可以看到,这些pickle文件在punkt目录里保存了一份,又在punkt下的PY3目录里保存了一份,这是因为NLTK库下的data.py模块中会从这两个路径读取数据,少一份都会报错。所以,大家也要这样构造目录结构,把文件保存两份。
第3步:创建环境变量,指向顶层目录D:\nltk_data。win10系统创建环境变量方法如下:
查看高级系统设置->环境变量->系统变量->新建->填写变量名和变量值->每个窗口都点击“确定”
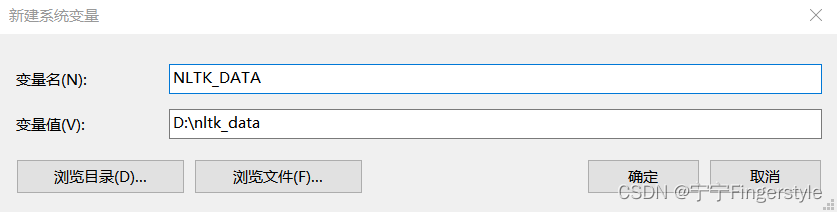
第4步:检验数据是否添加成功。可以运行下面的代码:
from nltk import word_tokenize
input = "What's the best way to split a sentence into words?"
print(word_tokenize(input))运行结果是:['What', "'s", 'the', 'best', 'way', 'to', 'split', 'a', 'sentence', 'into', 'words', '?']
如果得到了正确的切分结果,那就说明数据添加成功了。
![[附源码]JAVA毕业设计客户台账管理(系统+LW)](https://img-blog.csdnimg.cn/f5b7e5c20cfd462496b7a8e4da85e210.png)