深入了解CUDA编程模型:并行计算的强大工具
本篇博客将详细介绍NVIDIA的CUDA编程模型,帮助您更好地理解并行计算的基本原理和技巧。CUDA是一种通用并行计算平台和编程模型,它允许开发者利用NVIDIA的GPU进行高性能计算。 CUDA已经成为GPU计算的事实标准,许多领域的研究人员和开发者都在使用CUDA进行高性能计算。本文将通过分析CUDA编程模型的基本概念、组织结构和执行模型,帮助您更好地理解和掌握CUDA编程。
1. CUDA编程模型的基本概念
1.1 核函数
在CUDA编程中,核函数(Kernel)是一个在GPU上执行的并行函数。核函数在许多线程中执行,每个线程都是一个独立的计算单元。通过将任务划分为许多独立的线程,CUDA可以实现高度的并行化。
__global__ void myKernel(int *array, int arrayCount)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < arrayCount)
{
array[idx] = idx * idx;
}
}
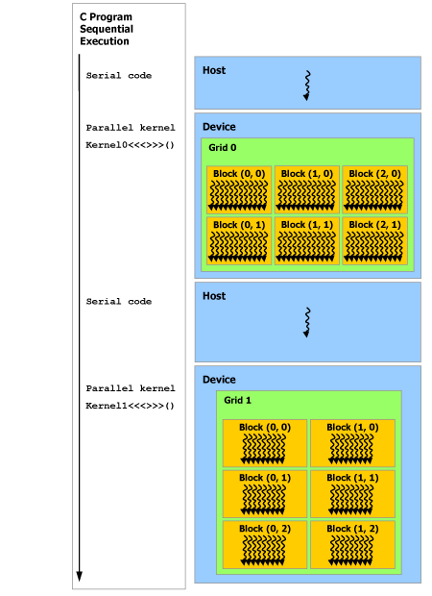
1.2 线程
线程是CUDA编程的基本执行单位。每个线程都是一个独立的计算单元,可以并行地执行相同的计算任务。线程之间可以通过共享内存和同步机制进行通信和协作。
1.3 线程块
线程块(Thread Block)是一组并行执行的线程,它们共享同一个代码和数据空间。线程块内的线程可以通过共享内存和同步机制进行通信和协作。线程块是CUDA编程的一个重要组织结构,它有助于将计算任务划分为更小、更易于管理的单位。
1.4 网格
网格(Grid)是一组线程块,它们共享相同的核函数和执行配置。网格是CUDA编程的另一个重要组织结构,它有助于将计算任务划分为更大、更易于管理的单位。

2. CUDA线程组织结构
2.1 一维线程块和网格
在CUDA编程中,线程块和网格可以是一维、二维或三维的。一维线程块和网格是最简单的组织结构,它们将线程和线程块组织为线性数组。例如,一个包含256个线程的一维线程块可以表示为:dim3 blockDim(256);;一个包含16个线程块的一维网格可以表示为:dim3 gridDim(16);。
2.2 二维线程块和网格
二维线程块和网格将线程和线程块组织为二维矩阵。这种组织结构非常适合处理二维数据,例如图像和矩阵。例如,一个包含16×16个线程的二维线程块可以表示为:dim3 blockDim(16, 16);;一个包含8×8个线程块的二维网格可以表示为:dim3 gridDim(8, 8);。
2.3 三维线程块和网格
三维线程块和网格将线程和线程块组织为三维立方体。这种组织结构非常适合处理三维数据,例如体积渲染和三维模拟。例如,一个包含8×8×8个线程的三维线程块可以表示为:dim3 blockDim(8, 8, 8);;一个包含4×4×4个线程块的三维网格可以表示为:dim3 gridDim(4, 4, 4);。
3. CUDA执行模型
3.1 设备和主机
在CUDA编程中,设备(Device)指的是GPU,而主机(Host)指的是CPU。 设备和主机分别执行不同的代码和任务。核函数是在设备上执行的,而主函数(main())是在主机上执行的。
3.2 核函数的启动和执行
CUDA核函数的启动和执行是异步的。在主机代码中,核函数的启动使用以下语法:kernel<<<gridDim, blockDim>>>(args);。其中,kernel表示核函数名,gridDim和blockDim分别表示网格和线程块的维度,args表示核函数的参数。
当核函数被启动时,设备将根据网格和线程块的维度创建线程,并将这些线程分配给多个处理单元。线程的执行顺序是不确定的,因此CUDA编程需要考虑线程之间的同步和通信问题。
4. 示例:矢量加法
#include <iostream>
#include <cuda_runtime.h>
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
int main()
{
int numElements = 50000;
size_t size = numElements * sizeof(float);
float *h_A = new float[numElements];
float *h_B = new float[numElements];
float *h_C = new float[numElements];
for (int i = 0; i < numElements; ++i)
{
h_A[i] = rand() / (float)RAND_MAX;
h_B[i] = rand() / (float)RAND_MAX;
}
float *d_A, *d_B, *d_C;
cudaMalloc((void **)&d_A, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMalloc((void **)&d_B, size);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
cudaMalloc((void **)&d_C, size);
int threadsPerBlock = 256;
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
for (int i = 0; i < numElements; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
std::cerr << "Result verification failed at element " << i << "!\n";
exit(EXIT_FAILURE);
}
}
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
delete[] h_A;
delete[] h_B;
delete[] h_C;
std::cout << "Test PASSED\n";
return 0;
}
5. CUDA内存管理
在CUDA编程中,内存管理是一个关键的主题。CUDA设备(GPU)和主机(CPU)具有各自独立的内存空间,因此在编程时需要考虑数据在设备和主机之间的传输。
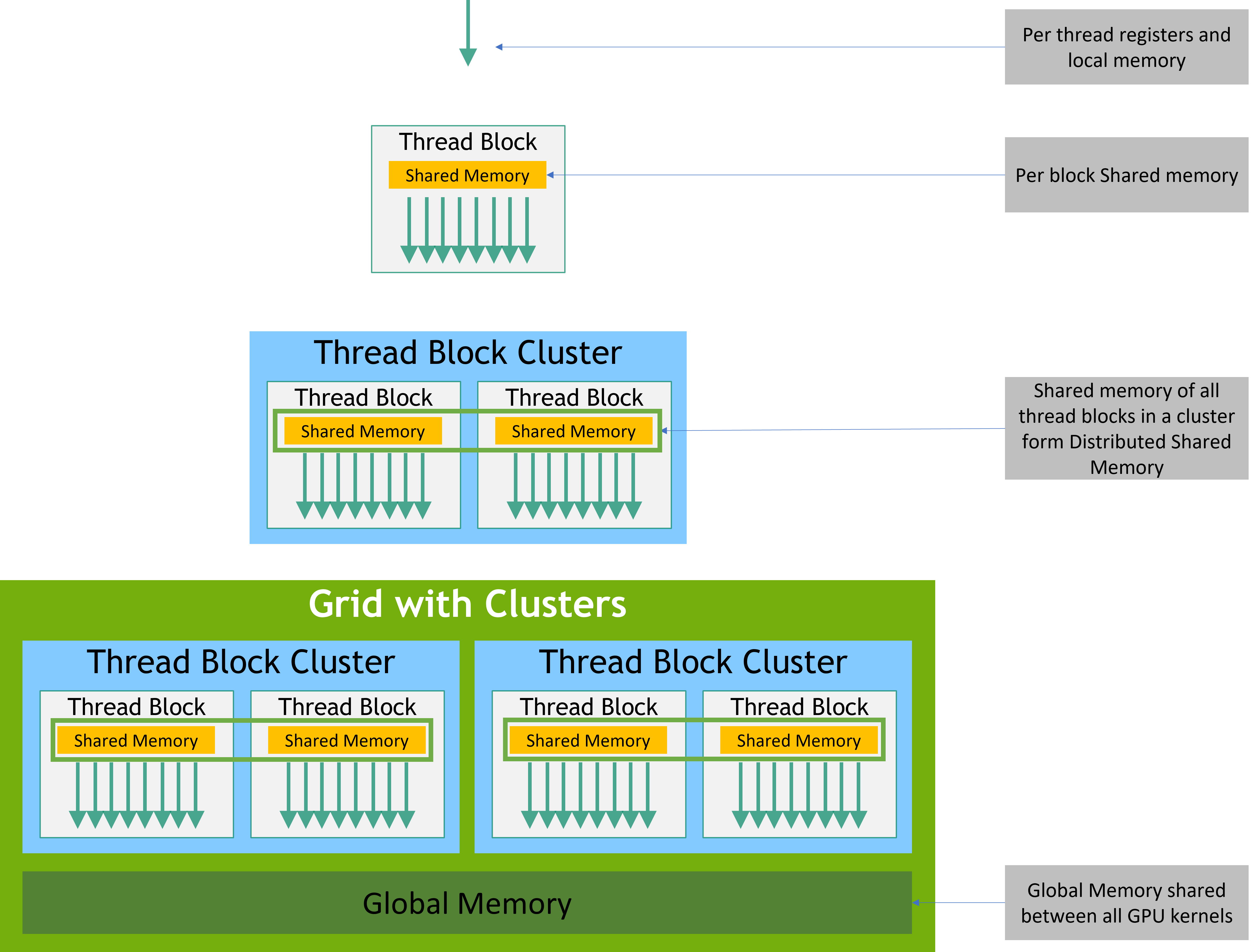
5.1 内存类型
CUDA中有以下几种类型的内存:
-
全局内存:全局内存位于设备上,容量较大(通常为数GB),但访问速度较慢。全局内存可以被所有线程以及主机访问。在CUDA编程中,通常需要将数据从主机内存复制到全局内存,然后在设备上执行计算,最后将结果从全局内存复制回主机内存。
-
共享内存:共享内存位于设备上,容量较小(通常为数KB),但访问速度较快。共享内存仅能被同一个线程块内的线程访问,因此可以用来实现线程之间的通信和协作。
-
常量内存:常量内存位于设备上,容量较小(通常为数KB),但访问速度较快。常量内存可以被所有线程访问,但只能在主机端进行初始化。常量内存适用于存储在整个计算过程中不会发生变化的数据。
-
纹理内存:纹理内存位于设备上,容量较大(通常为数GB),访问速度较快。纹理内存通过特殊的缓存机制实现高效访问。纹理内存主要用于处理图形和图像数据,例如纹理映射和滤波操作。
5.2 内存分配和释放
在CUDA编程中,我们需要在设备和主机上分配和释放内存。设备内存的分配和释放使用cudaMalloc()和cudaFree()函数,而主机内存的分配和释放使用标准的C++ new和delete操作符。
float *d_A;
cudaMalloc((void **)&d_A, size);
cudaFree(d_A);
5.3 内存传输
在CUDA编程中,我们需要将数据在设备和主机之间进行传输。内存传输使用cudaMemcpy()函数,该函数接受四个参数:目标地址、源地址、传输大小和传输方向。传输方向可以是cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost、cudaMemcpyDeviceToDevice或cudaMemcpyHostToHost。
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
6. CUDA线程同步
在CUDA编程中,线程同步是另一个重要的主题。线程同步可以确保线程按照正确的顺序执行,并在需要时等待其他线程完成操作。
6.1 设备同步
设备同步使用cudaDeviceSynchronize()函数。该函数会阻塞主机代码的执行,直到设备上所有核函数执行完成。设备同步通常用于核函数之间的同步,以及在主机端获取计算结果之前确保设备端的计算已经完成。
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
cudaDeviceSynchronize();
6.2 线程块内同步
线程块内同步使用__syncthreads()函数。该函数会阻塞线程块内所有线程的执行,直到所有线程都执行到同步点。线程块内同步通常用于实现线程之间的通信和协作,例如在共享内存中交换数据和计算中间结果。
__global__ void myKernel(int *array, int arrayCount)
{
__shared__ int sdata[256];
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < arrayCount)
{
sdata[threadIdx.x] = array[idx];
__syncthreads();
// Do something with sdata
}
}
7. CUDA性能优化
在CUDA编程中,性能优化是一个重要的课题。为了充分利用GPU的并行计算能力,我们需要关注以下几个方面:
-
线程数和线程块大小:合适的线程数和线程块大小可以提高设备的资源利用率,从而提高性能。通常,线程块大小应该是32的倍数,以便于线程能够与设备的处理单元(每个处理单元包含32个线程)对齐。
-
内存访问模式:合适的内存访问模式可以减少内存访问冲突,从而提高性能。例如,我们可以尽量使用共享内存、常量内存和纹理内存,避免使用全局内存。此外,我们还可以通过调整数据布局和访问顺序来实现内存的连续访问和对齐访问。
-
计算和内存传输重叠:为了减少内存传输的开销,我们可以尝试将计算和内存传输操作重叠。这可以通过使用异步内存传输函数(如
cudaMemcpyAsync())和流(Stream)机制来实现。
通过以上的介绍,我们已经掌握了CUDA编程的一些高级主题,包括内存管理、线程同步和性能优化等方面。这些知识将帮助您更好地理解和掌握CUDA编程,从而充分利用GPU的并行计算能力。
祝您在CUDA编程旅程中取得更多的进步和成就!