引言
随着金融数据的不断增长和复杂化,传统的统计方法和机器学习技术面临着挑战。深度学习算法通过多层神经网络的构建,以及大规模数据的训练和优化,可以从数据中提取更加丰富、高级的特征表示,从而提供更准确、更稳定的预测和决策能力。
在金融领域,深度学习算法已经被广泛应用于多个关键任务。首先,风险评估是金融机构必须面对的重要问题之一。深度学习算法可以通过学习大规模的历史数据,识别隐藏在数据中的潜在风险因素,并预测未来的风险情况。其次,欺诈检测是金融行业必不可少的任务。深度学习算法可以通过对交易模式和用户行为的建模,发现异常模式和欺诈行为,提高金融机构对欺诈的识别和预防能力。
此外,深度学习算法在金融交易方面也发挥着重要作用。通过对市场数据、历史交易数据和其他相关信息进行建模和预测,深度学习算法可以帮助交易员做出更明智的交易决策,并提高交易策略的效果和收益。
然而,深度学习算法在金融领域的应用也面临着一些挑战和限制。首先,数据的质量和可靠性对算法的性能至关重要。其次,算法的可解释性和可信度也是金融监管和风控部门关注的重点。因此,在深度学习算法的发展和应用过程中,仍然需要进一步探索和研究,以确保其在金融领域的可靠性和稳定性。
本文将简要介绍金融领域中的十大深度学习算法原理及在金融领域的独特应用案例,并提供Python深度学习核心代码的案例模板,以便读者能在代码基础上结合自己的数据集和应用场景进行拓展。
算法简介及代码示例
01
长短期记忆网络
长短期记忆网络 (Long Short-Term Memory, LSTM)是一种递归神经网络 (RNN) 的类型,专门用于处理序列预测问题。与传统的RNN不同,LSTM可以有效地捕捉时间序列数据中的长期依赖关系,因此在金融领域非常有用。
这些网络包含能够在长序列中存储信息的记忆单元,使其能够克服传统RNN中的梯度消失问题。LSTM能够记住和利用过去的信息,使其适用于分析金融时间序列数据,如股票价格或经济指标。
应用案例:LSTM在金融领域有多种应用,例如股票价格预测、算法交易、投资组合优化和欺诈检测。它们还可以分析经济指标以预测市场趋势,帮助投资者做出更明智的决策。
这里是一个使用Python实现LSTM的示例代码:
from keras.models import Sequential
from keras.layers import LSTM, Dense
# define the model
model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, feature_dim)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit the model to the training data
model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))上面代码是简化了,需要带入数据变量才能运行。下面使用qstock获取数据,以股价预测为例,将上述模板进行扩展,使之能运行:
# 获取股票数据
import qstock as qs
import pandas as pd
import numpy as np
data = qs.get_price('hs300').iloc[:,0]
# 提取训练数据
train_data = data[:'2021']
train_prices = train_data.values.reshape(-1, 1)
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
train_scaled = scaler.fit_transform(train_prices)
# 创建训练数据集
X_train = []
y_train = []
timesteps = 30 # 时间步长,可根据需求进行调整
for i in range(timesteps, len(train_scaled)):
X_train.append(train_scaled[i - timesteps:i, 0])
y_train.append(train_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
# 调整输入数据的维度
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X_train.shape[1], 1)))
model.add(LSTM(50))
model.add(Dense(1))
# 编译模型
model.compile(loss='mean_squared_error', optimizer='adam')
# 拟合模型
model.fit(X_train, y_train, epochs=50, batch_size=32)
# 提取测试数据
test_data = data['2022':]
test_prices = test_data.values.reshape(-1, 1)
# 数据归一化
test_scaled = scaler.transform(test_prices)
# 创建测试数据集
X_test = []
y_test = []
for i in range(timesteps, len(test_scaled)):
X_test.append(test_scaled[i - timesteps:i, 0])
y_test.append(test_scaled[i, 0])
X_test, y_test = np.array(X_test), np.array(y_test)
# 调整输入数据的维度
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 使用模型进行预测
predicted_prices = model.predict(X_test)
import matplotlib.pyplot as plt
# 反归一化训练集和测试集的价格数据
train_prices_scaled = scaler.inverse_transform(train_scaled)
test_prices_scaled = scaler.inverse_transform(test_scaled)
# 反归一化预测结果
predicted_prices_scaled = scaler.inverse_transform(predicted_prices)
# 创建日期索引
train_dates = train_data.index[timesteps:]
test_dates = test_data.index[timesteps:]
plt.figure(figsize=(15, 7))
plt.plot(test_dates, test_prices_scaled[timesteps:], label='沪深300-测试数据');
plt.plot(test_dates, predicted_prices_scaled, label='LSTM预测收盘价格');
plt.legend();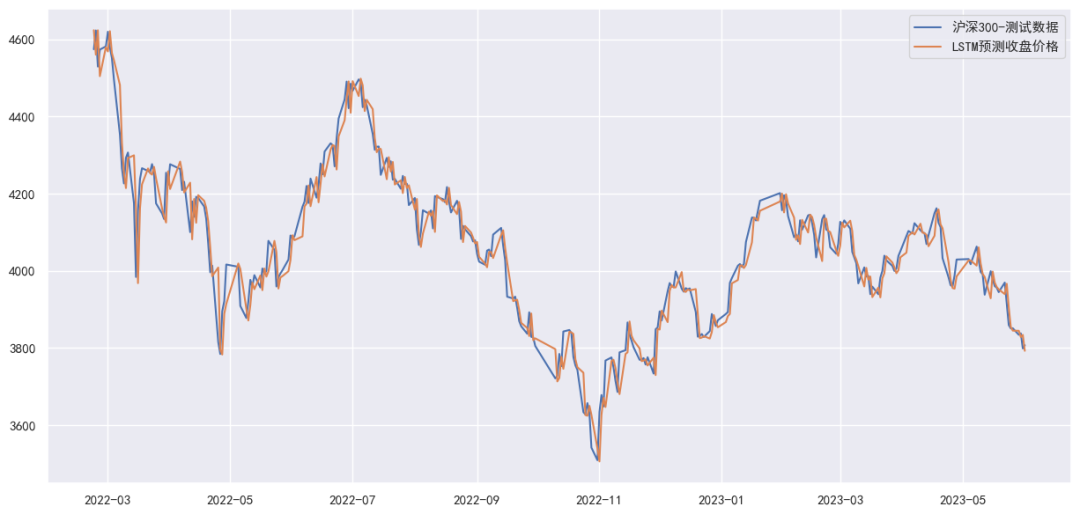
02
卷积神经网络
卷积神经网络 (Convolutional Neural Networks, CNN)是深度学习方法的一个子集,专门用于处理和分析像图片这样的网格状数据结构。在金融领域,它们被广泛应用于评估补充数据源,如卫星图像和文本数据。
CNN由多个层组成,每一层都执行特定的任务,如特征提取或分类。它们在金融领域特别有效,因为对于需要识别数据中的模式或结构的任务非常有效。
应用案例:在金融领域,CNN已被用于情感分析、文档分类,甚至根据停车场或油轮的卫星图像预测市场走势。此外,它们还可以通过分析交易数据中的模式来帮助检测欺诈交易。
这里是一个使用Python实现CNN的示例代码:
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.models import Sequential
# 定义模型
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3,3), activation='relu', input_shape=(input_rows, input_cols, input_channels)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 将模型拟合到训练数据
model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epochs, validation_data=(X_test, y_test))
# 在测试数据上评估模型
score = model.evaluate(X_test, y_test, verbose=0)
print(f'Test loss: {score[0]:.3f}')
print(f'Test accuracy: {score[1]:.3f}')03
自动编码器 (Autoencoders)
自动编码器是一种无监督的深度学习方法,通过以较小的损失重新构建输入数据来学习有效的数据模型。在金融领域,它们对于降维、数据压缩和异常检测等任务非常有帮助。
自动编码器由编码器和解码器组成。编码器将输入数据进行压缩,解码器使用压缩表示重新构建原始数据。通过教会网络减少输入数据与重构数据之间的差异,网络学习到了数据的简化表示。
应用案例:自动编码器在金融领域的应用包括投资组合优化,其中它们可以帮助降低大型数据集的维度。它们还可以用于检测金融数据中的异常模式,如信用卡欺诈或内部交易。
这里是一个使用Python实现自动编码器的示例代码:
from keras.layers import Input, Dense
from keras.models import Model
# 定义编码器模型
inputs = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(inputs)
# 定义解码器模型
decoded = Dense(input_dim, activation='sigmoid')(encoded)
# 定义自动编码器模型
autoencoder = Model(inputs, decoded)
# 编译自动编码器模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 将模型拟合到训练数据
autoencoder.fit(X_train, X_train, epochs=num_epochs, batch_size=batch_size, validation_data=(X_test, X_test))
validation_data=(X_test, X_test)04
深度强化学习
深度强化学习(Deep Reinforcement Learning, DRL)是深度学习和强化学习的结合,它允许算法通过学习行为并优化长期回报来进行学习。在金融领域,DRL已被应用于算法交易和投资组合管理等任务。
在DRL中,智能体与环境进行交互以实现特定目标。智能体通过奖励或惩罚的形式获得反馈,并相应地调整其行为。通过使用深度学习技术,智能体可以学习复杂的策略并做出更好的决策。
应用案例:在金融领域,DRL已被用于算法交易,智能体可以学习交易股票或其他资产以最大化利润。它还适用于投资组合管理,智能体可以基于历史数据和市场情况学习平衡风险和回报。
以下是使用Python实现DRL的示例:
# 导入必要的库
import gym
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import Adam
# 创建环境
env = gym.make('CartPole-v1')
# 创建神经网络
model = Sequential()
model.add(Dense(24, input_dim=4, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(2, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=0.001))
# 使用深度强化学习训练模型
for episode in range(500):
state = env.reset()
state = np.reshape(state, [1, 4])
done = False
for time in range(500):
action = np.argmax(model.predict(state)[0])
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, 4])
model.fit(state, model.predict(state), verbose=0)
state = next_state
if done:
break
# 进行预测
state = env.reset()
state = np.reshape(state, [1, 4])
done = False
while not done:
action = np.argmax(model.predict(state)[0])
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, 4])
state = next_state05
生成对抗网络
生成对抗网络Generative Adversarial Networks,GAN,是由生成器(Generator)和判别器(Discriminator)两个模型组成的一种神经网络形式。判别器旨在准确区分真实样本和伪造样本,而生成器则用于创建人工数据样本。在银行业中,GAN被用于创建用于机器学习模型训练的伪造金融数据。
判别器的目标是准确区分真实样本和合成样本,生成器的目标是创建足够逼真的样本以欺骗判别器。生成器和判别器在对抗性过程中进行训练。GAN已应用于金融领域,包括创建用于训练其他机器学习模型的伪造金融数据。
应用场景:GAN已被用于金融领域生成逼真的合成金融数据,有助于克服稀缺或机密数据的限制。它们还可以模拟各种市场情景,为金融机构进行压力测试和风险评估。
以下是使用Python实现GAN的示例代码:
from keras.layers import Input, Dense, LeakyReLU
from keras.models import Model, Sequential
import numpy as np
# 定义判别器模型
discriminator = Sequential()
discriminator.add(Dense(50, input_shape=(latent_dim,)))
discriminator.add(LeakyReLU(alpha=0.01))
discriminator.add(Dense(1, activation='sigmoid'))
# 编译判别器模型
discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 定义生成器模型
generator = Sequential()
generator.add(Dense(50, input_shape=(latent_dim,)))
generator.add(LeakyReLU(alpha=0.01))
generator.add(Dense(output_dim, activation='sigmoid'))
# 定义用于训练生成器的组合模型
gan = Sequential()
gan.add(generator)
gan.add(discriminator)
# 编译组合模型
gan.compile(optimizer='adam', loss='binary_crossentropy')
# 定义辅助函数
def sample_noise(batch_size, latent_dim):
"""生成随机噪声样本。"""
return np.random.rand(batch_size, latent_dim)
def sample_real_data(batch_size):
"""从数据集中抽样真实数据。"""
idx = np.random.randint(0, data.shape[0], batch_size)
return data[idx]
# 设置超参数
latent_dim = 10
batch_size = 32
num_epochs = 100
output_dim = data.shape[1]
# 训练GAN
for epoch in range(num_epochs):
# 生成合成数据样本
synthetic_data = generator.predict(sample_noise(batch_size, latent_dim))
# 连接合成数据和真实数据
real_data = sample_real_data(batch_size)
x = np.concatenate((synthetic_data, real_data))
# 为合成数据和真实数据创建标签
y = np.concatenate((np.zeros(batch_size), np.ones(batch_size)))
# 在合成数据和真实数据上训练判别器
d_loss, d_acc = discriminator.train_on_batch(x, y)
# 生成噪声作为生成器的输入
noise = sample_noise(batch_size, latent_dim)
# 训练生成器
g_loss = gan.train_on_batch(noise, np.ones(batch_size))
# 打印每个时期的损失和准确率
print(f'时期: {epoch+1},判别器损失: {d_loss:.3f},判别器准确率: {d_acc:.3f},生成器损失: {g_loss:.3f}')06
变分自编码器
变分自编码器(Variational Autoencoders,VAE)是一种扩展了自编码器的生成式深度学习算法,采用概率方法,使其能够对复杂的数据分布进行建模。在金融领域,VAE已用于期权定价和风险管理等任务。
VAE由编码器和解码器组成,类似于自编码器。然而,它们学习了潜在空间上的概率分布,使其能够从学习的分布中生成多样的样本。这种对复杂数据分布的建模能力使其适用于金融应用。
应用场景:VAE已用于金融领域的期权定价等任务,可以对基础资产的复杂分布进行建模。它们还对风险管理非常有用,因为它们能够生成潜在未来情景的逼真样本,使金融机构能够更有效地评估和管理风险。
以下是使用Python实现VAE的示例代码:
import tensorflow as tf
from tensorflow.keras import layers
# 定义编码器模型
input_shape = (28, 28, 1)
latent_dim = 2
encoder_inputs = tf.keras.Input(shape=input_shape)
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
# 定义采样层
def sampling(args):
z_mean, z_log_var = args
epsilon = tf.keras.backend.random_normal(shape=tf.shape(z_mean))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
z = layers.Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
# 定义解码器模型
decoder_inputs = layers.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(decoder_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2DTranspose(1, 3, activation="sigmoid", padding="same")(x)
# 定义VAE模型
vae = tf.keras.Model(encoder_inputs, decoder_outputs)
# 定义损失函数
reconstruction_loss = tf.keras.losses.binary_crossentropy(encoder_inputs, decoder_outputs)
reconstruction_loss *= input_shape[0] * input_shape[1]
kl_loss = 1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var)
kl_loss = tf.reduce_mean(kl_loss, axis=-1)
kl_loss *= -0.5
vae_loss = tf.reduce_mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
# 预测模型
vae.compile(optimizer="adam")
vae.fit(x_train, x_train, epochs=10, batch_size=128)
# 预测结果
x_test_encoded = vae.encoder.predict(x_test, batch_size=128)
x_test_decoded = vae.decoder.predict(x_test_encoded, batch_size=128)07
图神经网络
图神经网络(Graph Neural Networks,GNN)是一类用于处理和分析图结构数据的深度学习算法。它们已应用于金融领域的欺诈检测和风险评估等任务。
GNN操作的是图数据,其中节点代表实体,边代表实体之间的关系。它们可以学习节点和边的有意义表示,捕捉数据中的复杂关系。这种建模复杂关系的能力使其适用于金融领域。
应用场景:GNN已在金融领域中用于欺诈检测等任务,可以分析金融网络中实体之间的关系,如客户和交易。它们还对风险评估非常有用,因为它们可以模拟金融机构之间的相互关联性并评估系统性风险。
以下是使用Python实现GNN的示例代码:
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, global_max_pool
class GNN(torch.nn.Module):
def __init__(self, num_features, num_classes):
super(GNN, self).__init__()
self.conv1 = GCNConv(num_features, 16)
self.conv2 = GCNConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
x = global_max_pool(x, data.batch)
return F.log_softmax(x, dim=1)
# 训练模型
model = GNN(num_features, num_classes)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(100):
model.train()
optimizer.zero_grad()
out = model(data)
loss = criterion(out, data.y)
loss.backward()
optimizer.step()
# 预测结果并计算精确度和召回率
model.eval()
with torch.no_grad():
pred = model(data).max(dim=1)[1]
correct = pred.eq(data.y).sum().item()
total = len(data.y)
precision = correct / total
recall = precision
print(f"精确度:{precision},召回率:{recall}")08
Transformer模型
Transformer模型是一类设计用于序列到序列任务(如自然语言处理)的深度学习算法。它们已成功应用于金融领域的情感分析和金融文档摘要等任务。
Transformer模型依赖于一种称为自注意力机制的机制,使其能够权衡序列中不同元素的重要性。这种捕捉长距离依赖关系和上下文信息的能力使其适用于涉及文本数据的金融应用。
应用场景:Transformer模型已在金融领域中用于情感分析等任务,可以分析新闻文章、社交媒体帖子或财报电话交流记录等,以预测市场动向。它们还可以对金融文件(如年度报告或监管文件)进行摘要,为决策者提供简洁的见解。
以下是使用Python实现Transformer的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, num_classes=10, d_model=512, nhead=8, num_encoder_layers=6, dim_feedforward=2048, dropout=0.1):
super(TransformerModel, self).__init__()
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout),
num_layers=num_encoder_layers
)
self.fc = nn.Linear(d_model, num_classes)
def forward(self, x):
x = self.transformer_encoder(x)
x = x.mean(dim=0)
x = self.fc(x)
return x
# 定义数据转换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='data/', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='data/', train=False, transform=transform)
# 定义数据加载器
batch_size = 128
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 实例化模型和优化器
model = TransformerModel().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义损失
# 训练模型
epochs = 10
for epoch in range(1, epochs+1):
model.train()
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 在测试集上评估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Epoch [{epoch}/{epochs}], Loss: {loss.item():.4f}, Test Accuracy: {(correct/total)*100:.2f}%")09
深度置信网络
深度置信网络(Deep Belief Networks,DBN)是一种深度学习算法,它可以使用分层结构来学习表示数据。在金融领域,它们已用于特征提取、分类和回归等任务。
DBN由多层受限玻尔兹曼机(RBMs)或其他无监督学习算法堆叠而成。每一层都学习以更抽象和更高层次的方式表示数据,使网络能够捕捉数据中的复杂模式和关系。
应用场景:DBN已应用于金融领域,用于预测股票价格、分析市场情绪和建模金融时间序列数据等任务。它们还可用于信用风险评估,因为它们可以识别大型数据集中的隐藏模式,并帮助确定违约的可能性。此外,DBN对于投资组合优化和资产配置也很有用,因为它们可以学习各种资产和市场因素之间的层次关系。
以下是使用Python实现DBN的示例代码:
import tensorflow as tf
# 定义Deep Belief Network的各层
n_inputs = 784 # 输入特征数
n_hidden1 = 500 # 第一隐藏层的神经元数
n_hidden2 = 200 # 第二隐藏层的神经元数
n_outputs = 10 # 输出类别数
# 创建函数来定义每一层的权重和偏置
def create_layer(input_size, output_size, name):
with tf.name_scope(name):
weights = tf.Variable(tf.truncated_normal([input_size, output_size], stddev=0.1), name='weights')
biases = tf.Variable(tf.constant(0.1, shape=[output_size]), name='biases')
return weights, biases
# 定义网络的输入占位符
x = tf.placeholder(tf.float32, shape=[None, n_inputs], name='x')
# 定义每一层的权重和偏置
w1, b1 = create_layer(n_inputs, n_hidden1, 'hidden1')
w2, b2 = create_layer(n_hidden1, n_hidden2, 'hidden2')
w3, b3 = create_layer(n_hidden2, n_outputs, 'output')
# 定义网络的各层
hidden1 = tf.nn.relu(tf.matmul(x, w1) + b1)
hidden2 = tf.nn.relu(tf.matmul(hidden1, w2) + b2)
logits = tf.matmul(hidden2, w3) + b3
# 定义网络的标签占位符
y = tf.placeholder(tf.int32, shape=[None], name='y')
# 定义损失函数(交叉熵)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y)
loss = tf.reduce_mean(cross_entropy, name='loss')
# 定义优化器(Adam)
learning_rate = 0.01
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
# 定义准确率矩阵
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
# 定义初始设置
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# 导入数据集 (MNIST)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
# 训练模型
n_epochs = 10
batch_size = 100
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={x: X_batch, y: y_batch})
acc_train = accuracy.eval(feed_dict={x: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={x: mnist.test.images, y: mnist.test.labels})
print("Epoch:", epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
save_path = saver.save(sess, "./my_model.ckpt")
# 利用模型进行预测
with tf.Session() as sess:
saver.restore(sess, "./my_model.ckpt")
X_new_scaled = [...] # 要预测的数据
y_pred = sess.run(logits, feed_dict={x: X_new_scaled})
y_pred_class = tf.argmax(y_pred, axis=1).eval()010
胶囊网络
胶囊网络(Capsule Networks,CapsNet)是一种创新的深度学习架构,解决了传统卷积神经网络(CNN)的一些局限性,例如无法捕捉数据中的空间层次和整体-部分关系。尽管相对较新,但CapsNet在各个领域,包括金融领域,显示出了很大的潜力。
CapsNet由胶囊组成,胶囊是表示输入的不同属性的一小组神经元。这些胶囊被组织成层,并且可以与网络中的其他胶囊进行通信。CapsNet可以学习识别对象或模式,而不考虑其在输入中的方向、比例或位置,使其比CNN更具鲁棒性和灵活性。
应用场景:CapsNet可以应用于金融领域中涉及数据中模式、关系或结构识别的各种任务。它们可用于情感分析,可以捕捉金融新闻或社交媒体数据中单词和短语之间的层次关系。此外,CapsNet可用于信用风险评估,因为它们可以学习识别各种借款人特征和违约风险之间的复杂关系。它们还可以用于市场预测、欺诈检测和其他需要模式识别和鲁棒性的应用。
以下是使用Python实现CapsNet的示例代码:
from keras import layers
from keras import models
from keras import backend as K
from keras.utils import to_categorical
from keras.datasets import mnist
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 重新调整输入数据的形状
train_images = train_images.reshape(-1, 28, 28, 1).astype('float32') / 255.0
test_images = test_images.reshape(-1, 28, 28, 1).astype('float32') / 255.0
# 将标签转换为独热编码
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Define the Capsule Network architecture
class CapsuleLayer(layers.Layer):
def __init__(self, num_capsules, capsule_dim, routings=3, **kwargs):
super(CapsuleLayer, self).__init__(**kwargs)
self.num_capsules = num_capsules
self.capsule_dim = capsule_dim
self.routings = routings
self.activation = layers.Activation('softmax')
self.W = self.add_weight(shape=[num_capsules, 784, capsule_dim],
initializer='glorot_uniform',
trainable=True)
def call(self, inputs):
inputs_expand = K.expand_dims(inputs, 1)
inputs_tiled = K.tile(inputs_expand, [1, self.num_capsules, 1, 1])
inputs_hat = K.batch_dot(inputs_tiled, self.W, [3, 2])
b = K.zeros(shape=[K.shape(inputs_hat)[0], self.num_capsules, 784])
for i in range(self.routings):
c = self.activation(b)
outputs = K.batch_dot(c, inputs_hat, [2, 3])
if i < self.routings - 1:
b += outputs
else:
return K.reshape(outputs, [-1, self.num_capsules * self.capsule_dim])
def compute_output_shape(self, input_shape):
return tuple([None, self.num_capsules * self.capsule_dim])
input_shape = (28, 28, 1)
inputs = layers.Input(shape=input_shape)
conv1 = layers.Conv2D(filters=256, kernel_size=9, strides=1, padding='valid', activation='relu')(inputs)
primary_capsules = layers.Conv2D(filters=32, kernel_size=9, strides=2, padding='valid')(conv1)
primary_capsules = layers.Reshape(target_shape=[-1, 8])(primary_capsules)
digit_capsules = CapsuleLayer(num_capsules=10, capsule_dim=16, routings=3)(primary_capsules)
output = layers.Dense(units=10, activation='softmax')(digit_capsules)
# Define the model
model = models.Model(inputs=inputs, outputs=output)
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(train_images, train_labels, epochs=10, batch_size=128, validation_data=(test_images, test_labels))
# Evaluate the model
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
# Predict some results
predictions = model.predict(test_images[:10])
print('Predictions:', predictions)结语
深度学习算法在金融领域的应用正在取得突破性的进展,并为金融机构带来了许多机遇和挑战。通过利用深度学习算法,金融机构可以更好地理解和利用大数据,提高业务效率和决策质量。然而,我们也要意识到深度学习算法在金融领域的应用仍面临着一些问题,如数据隐私和安全性、算法的可解释性等。因此,需要在技术研发、监管政策和行业标准方面保持持续的努力。随着深度学习算法的进一步发展和创新,我们可以期待在金融领域看到更多的应用案例和成功故事。这些算法的不断演化将为金融机构带来更准确、更可靠的预测和决策能力,推动金融行业的创新和发展。
英文原文"Top 10 Deep Learning Algorithms in Finance" , Christophe Atten
链接:https://medium.datadriveninvestor.com/top-10-deep-learning-algorithms-in-finance-5b70ed251bb7

关于Python金融量化

专注于分享Python在金融量化领域的应用。加入知识星球,可以免费获取qstock源代码、30多g的量化投资视频资料、量化金融相关PDF资料、公众号文章Python完整源码、与博主直接交流、答疑解惑等。添加个人微信sky2blue2可获取八五折优惠。