1.打家劫舍:
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]。
2.确定递推公式
决定dp[i]的因素就是第i房间偷还是不偷。
如果偷第i房间,那么dp[i] = dp[i - 2] + nums[i] ,即:第i-1房一定是不考虑的,找出 下标i-2(包括i-2)以内的房屋,最多可以偷窃的金额为dp[i-2] 加上第i房间偷到的钱。
如果不偷第i房间,那么dp[i] = dp[i - 1],即考 虑i-1房,(注意这里是考虑,并不是一定要偷i-1房,这是很多同学容易混淆的点)
然后dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
用我的思路来解释一下为什么如果不偷第i房间是考虑i-1房而不是偷:
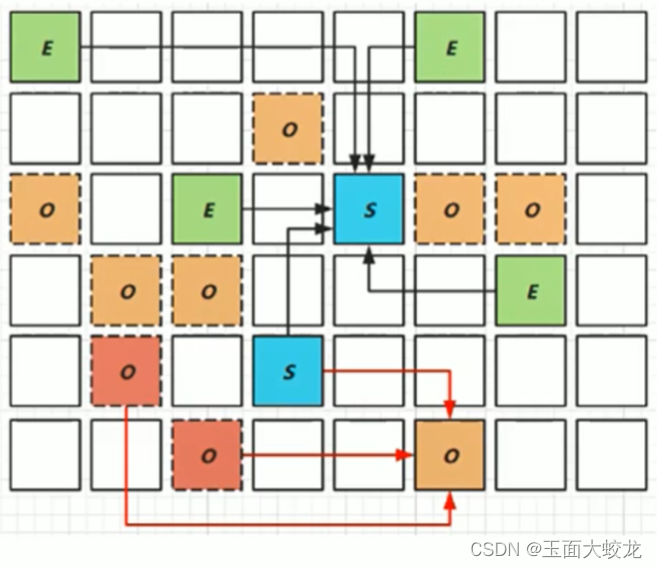
1.我的思路是两条路线比大小:

说实话就是一条路线是从第一位开始,第二条路线是从第2位开始,然后可以选择是跳1家打劫还是跳2家打劫(跳3家以上就没意义了,因为这还不如连续跳1家打劫来的多) 所以如果不偷i房不代表一定要偷i-1房
2.然后为什么题解的代码没有跳两家打劫呢?
因为dp[i]=dp[i-1]已经包括了,首先按照我的思路跳1家打劫是在原来的路线上,如果跳2家打劫是跳到另外一条路线,我的初始化是dp[1]=nums[0]; dp[2]=nums[1];我的递推公式是dp[i]=max(dp[i-3]+nums[i-1],dp[i-2]+nums[i-1]);是把两条路线的值进行比较,而题解的初始化代码是dp[1]=nums[0] ;dp[1] = max(nums[0], nums[1]);他从一开始就把2条路线给合起来了,然后假设i是我的思路中的第一条路线,i-2也是第一路线,而i-1是第二路线,他的递推公式是:dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);也是把两条路线的值进行比较。
3.dp数组如何初始化
从递推公式dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);可以看出,递推公式的基础就是dp[0] 和 dp[1]
从dp[i]的定义上来讲,dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);
代码如下:
vector<int> dp(nums.size());
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);4.确定遍历顺序
dp[i] 是根据dp[i - 2] 和 dp[i - 1] 推导出来的,那么一定是从前到后遍历!
代码如下:
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
1
5.举例推导dp数组
以示例二,输入[2,7,9,3,1]为例。

红框dp[nums.size() - 1]为结果。
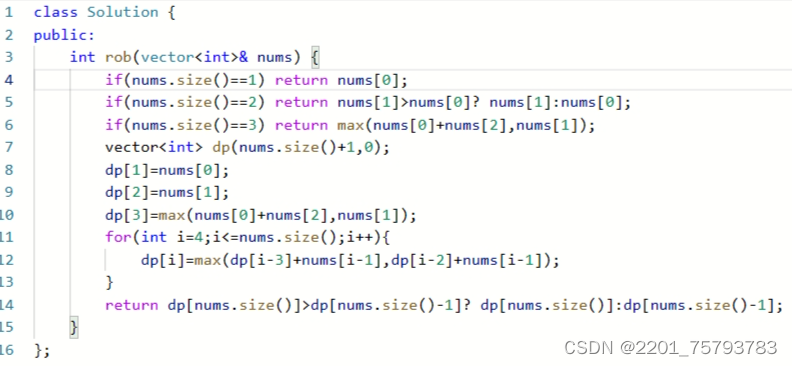
以上分析完毕,C++代码如下:
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
vector<int> dp(nums.size());
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[nums.size() - 1];
}
};2.打家劫舍||:
对于一个数组,成环的话主要有如下三种情况:
- 情况一:考虑不包含首尾元素

- 情况二:考虑包含首元素,不包含尾元素

- 情况三:考虑包含尾元素,不包含首元素

注意我这里用的是"考虑",例如情况三,虽然是考虑包含尾元素,但不一定要选尾部元素! 对于情况三,取nums[1] 和 nums[3]就是最大的。
而情况二 和 情况三 都包含了情况一了,所以只考虑情况二和情况三就可以了。
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
int result1 = robRange(nums, 0, nums.size() - 2); // 情况二
int result2 = robRange(nums, 1, nums.size() - 1); // 情况三
return max(result1, result2);
}
// 198.打家劫舍的逻辑
int robRange(vector<int>& nums, int start, int end) {
if (end == start) return nums[start];
vector<int> dp(nums.size());
dp[start] = nums[start];
dp[start + 1] = max(nums[start], nums[start + 1]);
for (int i = start + 2; i <= end; i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[end];
}
};注:
1.他传入start和end后dp数组的长度还是nums.size(),在robRange函数里就把start想象成0,把end想象成nums.size()-1;
3.打家劫舍 III:
暴力递归(超时的):
class Solution {
public:
int rob(TreeNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right == NULL) return root->val;
// 偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left,相当于不考虑左孩子了
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right,相当于不考虑右孩子了
// 不偷父节点
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
return max(val1, val2);
}
};和我在打家劫舍|里面的思路是一样的,比较2条路线第一条是从第一层开始(偷头节点), 第二条是从2层开始(不偷头节点):
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right这个是偷正在递归的节点并考虑他的孙子节点,他的孙子节点不一定要偷,看上面的图中橙黄色的线就是偷二叉树的头节点但是不偷二叉树的头节点的孙子节点,相当于中间隔了2层,他是第一层递归考虑父节点,第二层递归不考虑父节点。
当然以上代码超时了,这个递归的过程中其实是有重复计算了。
我们计算了root的四个孙子(左右孩子的孩子)为头结点的子树的情况,又计算了root的左右孩子为头结点的子树的情况,计算左右孩子的时候其实又把孙子计算了一遍。
记忆化递推
所以可以使用一个map把计算过的结果保存一下,这样如果计算过孙子了,那么计算孩子的时候可以复用孙子节点的结果。
代码如下:
class Solution {
public:
unordered_map<TreeNode* , int> umap; // 记录计算过的结果
int rob(TreeNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right == NULL) return root->val;
if (umap[root]) return umap[root]; // 如果umap里已经有记录则直接返回
// 偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right
// 不偷父节点
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
umap[root] = max(val1, val2); // umap记录一下结果
return max(val1, val2);
}
};为什么把记录结果放在不偷父节点那?
其实上面已经解释过了,我来推演一下有什么用这玩意:
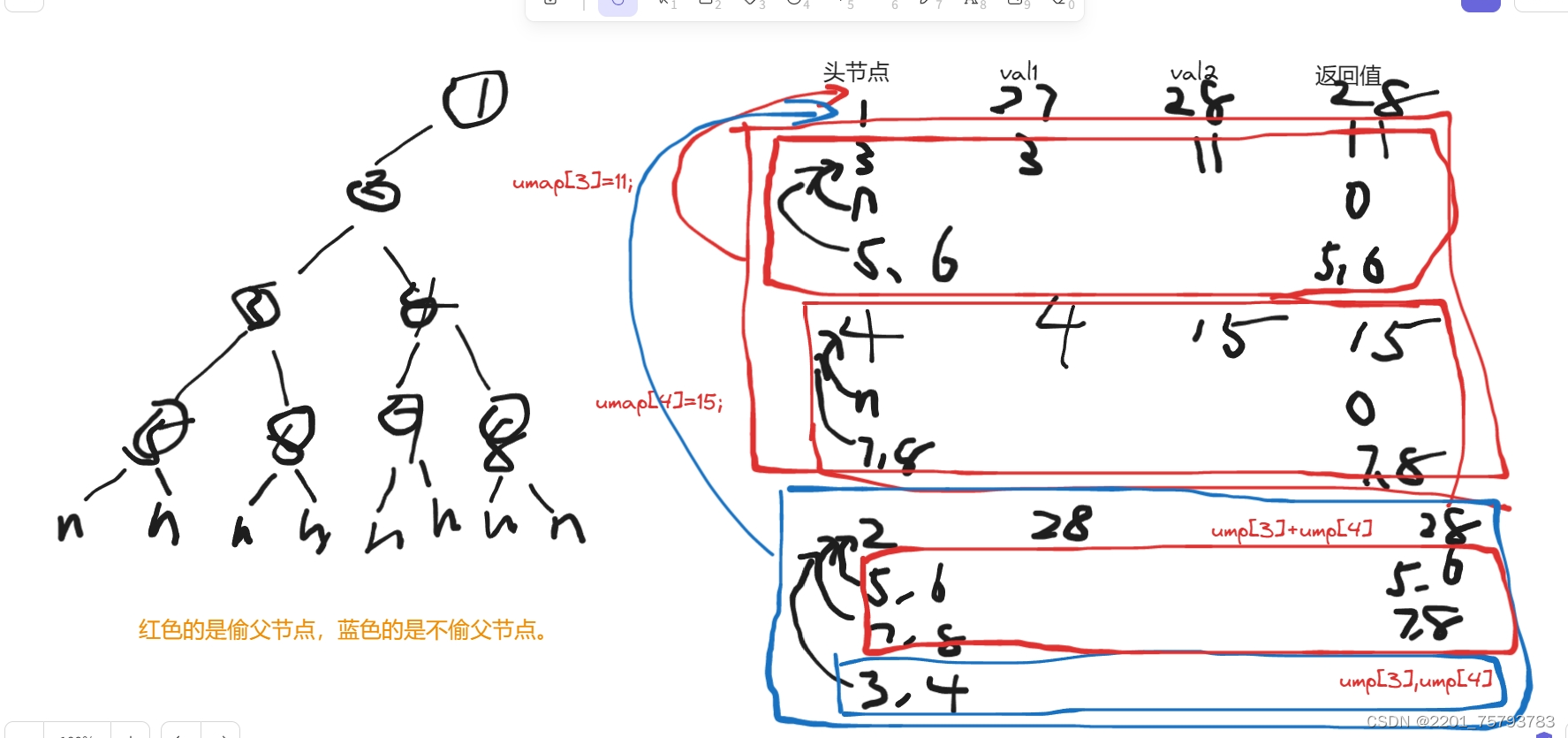
动态规划:
- 确定递归函数的参数和返回值
这里我们要求一个节点 偷与不偷的两个状态所得到的金钱,那么返回值就是一个长度为2的数组。
参数为当前节点,代码如下:
vector<int> robTree(TreeNode* cur) {其实这里的返回数组就是dp数组。
所以dp数组(dp table)以及下标的含义:下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。
所以本题dp数组就是一个长度为2的数组!
那么有同学可能疑惑,长度为2的数组怎么标记树中每个节点的状态呢?
别忘了在递归的过程中,系统栈会保存每一层递归的参数。
如果还不理解的话,就接着往下看,看到代码就理解了哈。
2.确定终止条件
在遍历的过程中,如果遇到空节点的话,很明显,无论偷还是不偷都是0,所以就返回
if (cur == NULL) return vector<int>{0, 0};
这也相当于dp数组的初始化
- 确定遍历顺序
首先明确的是使用后序遍历。 因为要通过递归函数的返回值来做下一步计算。
通过递归左节点,得到左节点偷与不偷的金钱。
通过递归右节点,得到右节点偷与不偷的金钱。
代码如下:
// 下标0:不偷,下标1:偷
vector<int> left = robTree(cur->left); // 左
vector<int> right = robTree(cur->right); // 右
// 中
3. 确定单层递归的逻辑
如果是偷当前节点,那么左右孩子就不能偷,val1 = cur->val + left[0] + right[0]; (如果对下标含义不理解就再回顾一下dp数组的含义)
如果不偷当前节点,那么左右孩子就可以偷,至于到底偷不偷一定是选一个最大的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);
这里用max(left[0], left[1])来举例,如果是max取left[0]那么就是中间隔了2层,如果是取left[1]的话就是中间隔了1层
最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最大金钱,偷当前节点得到的最大金钱}
代码如下:
vector<int> left = robTree(cur->left); // 左
vector<int> right = robTree(cur->right); // 右
// 偷cur
int val1 = cur->val + left[0] + right[0];
// 不偷cur
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
return {val2, val1};
- 举例推导dp数组
以示例1为例,dp数组状态如下:(注意用后序遍历的方式推导)
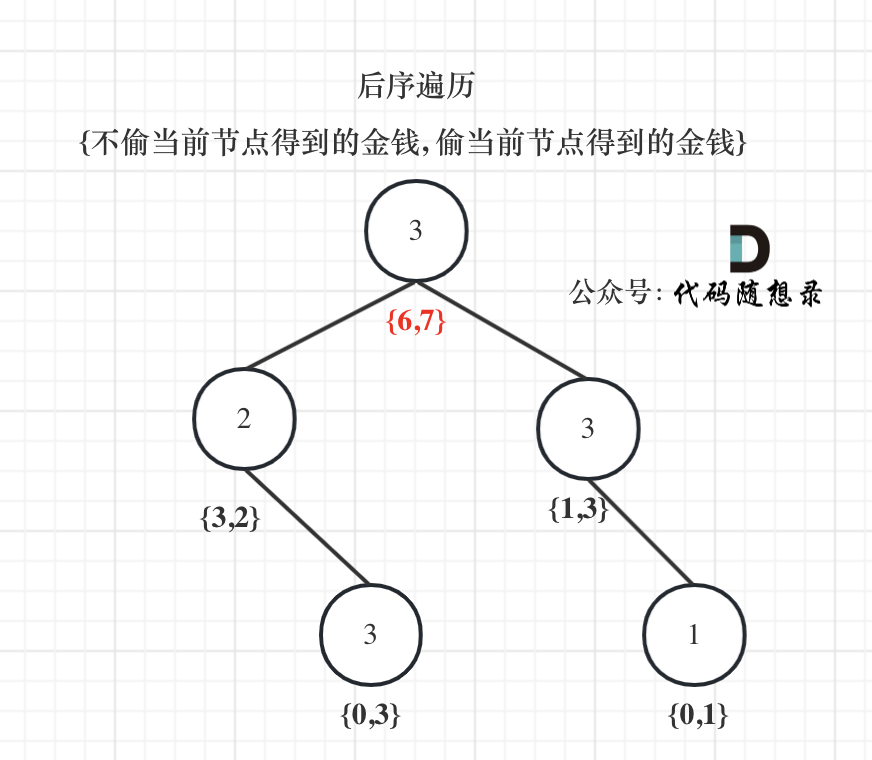
最后头结点就是 取下标0 和 下标1的最大值就是偷得的最大金钱。
递归三部曲与动规五部曲分析完毕,C++代码如下:
class Solution {
public:
int rob(TreeNode* root) {
vector<int> result = robTree(root);
return max(result[0], result[1]);
}
// 长度为2的数组,0:不偷,1:偷
vector<int> robTree(TreeNode* cur) {
if (cur == NULL) return vector<int>{0, 0};
vector<int> left = robTree(cur->left);
vector<int> right = robTree(cur->right);
// 偷cur,那么就不能偷左右节点。
int val1 = cur->val + left[0] + right[0];
// 不偷cur,那么可以偷也可以不偷左右节点,则取较大的情况
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
return {val2, val1};
}
};