本文是在模仿中精进数据分析与可视化系列的第三期——散点密度图,本文所用的数据和代码可在公众号GeodataAnalysis回复20230602下载。
一、简介
散点密度图(Scatter Density Plot)是一种用于可视化二维数据分布的图表。它将散点图和核密度估计图(Kernel Density Estimation,KDE)结合起来,通过在散点图上叠加一定透明度的核密度估计图来显示数据点的密度分布情况。
散点密度图可以用来探索数据的分布情况,尤其适用于大量数据点的情况。它可以帮助我们识别出数据的聚集区域、密度高低以及异常值等信息。

二、遥感反演PM2.5数据准备
本文所用的遥感数据来源于Surface PM2.5 | Atmospheric Composition Analysis Group | Washington University in St. Louis,该数据是圣路易斯华盛顿大学大气成分分析组分享的PM2.5数据。网站公布了多个精度的PM2.5数据,我们下载了2015-2020年精度最高的0.01°× 0.01°分辨率的数据,数据格式为.nc。采用如下代码将其转为TIF数据:
import os
import netCDF4 as nc
from glob import glob
from pyproj import CRS
from osgeo import gdal
years = list(range(2015, 2021))
x_res, y_res = 0.01, 0.01
for year in years:
nc_path = glob(os.path.join('./nc/', f'*{year}*.nc'))[0]
tif_path = os.path.join('./tif/', f'{year}.tif')
# 获取分辨率和左上角像素坐标值
rootgrp = nc.Dataset(nc_path)
lon = rootgrp['lon'][...].data
lat = rootgrp['lat'][...].data
x_min, y_max = lon.min(), lat.max()
# 仿射变换六参数
gt = (x_min, x_res, 0, y_max, 0, -y_res)
# 获取地理坐标系
crs = CRS.from_epsg(4326)
wkt = crs.to_wkt()
# 读取数据
pm = rootgrp['GWRPM25'][::-1, :]
pm = pm.filled(np.nan)
# 创建GeoTIFF文件并写入数据
driver = gdal.GetDriverByName('GTiff')
ds = driver.Create(tif_path, pm.shape[1], pm.shape[0], 1, gdal.GDT_Float32)
ds.SetGeoTransform(gt)
ds.SetProjection(wkt)
band = ds.GetRasterBand(1)
band.WriteArray(pm)
band.SetNoDataValue(np.nan)
ds = band = None
三、地基PM2.5数据
全国2000+站点2015-2020年的年均PM2.5浓度数据,可在公众号回复20230602下载。以下代码用于筛选掉不符合要求的站点:
df = pd.read_csv('pm25.csv')
df.dropna(subset=["lon", "lat"], inplace=True)
extent = [73.00499725341797, 139.9949951171875, 18.0049991607666, 53.994998931884766]
def in_extent(row):
lon, lat = row['lon'], row['lat']
if lon<extent[0] or lon>extent[1]:
return False
if lat<extent[2] or lat>extent[3]:
return False
return True
mask = df.apply(in_extent, axis=1)
df = df.loc[mask, :]
pm_gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df['lon'], df['lat']), crs='EPSG:4326')
pm_gdf.plot();

四、计算每个站点对应的各年的反演PM2.5浓度
根据站点经纬度计算该站点对应的各年的反演PM2.5浓度,代码如下:
years = [2015, 2016, 2017, 2018, 2019, 2020]
for year in years:
src = rio.open(f'./tif/{year}.tif')
band = src.read(1)
for i in pm_gdf.index:
lon, lat = pm_gdf.loc[i, 'lon'], pm_gdf.loc[i, 'lat']
row, col = src.index(lon, lat)
# 获取指定行列号的像元值
value = band[row, col]
pm_gdf.loc[i, f'r{year}'] = value
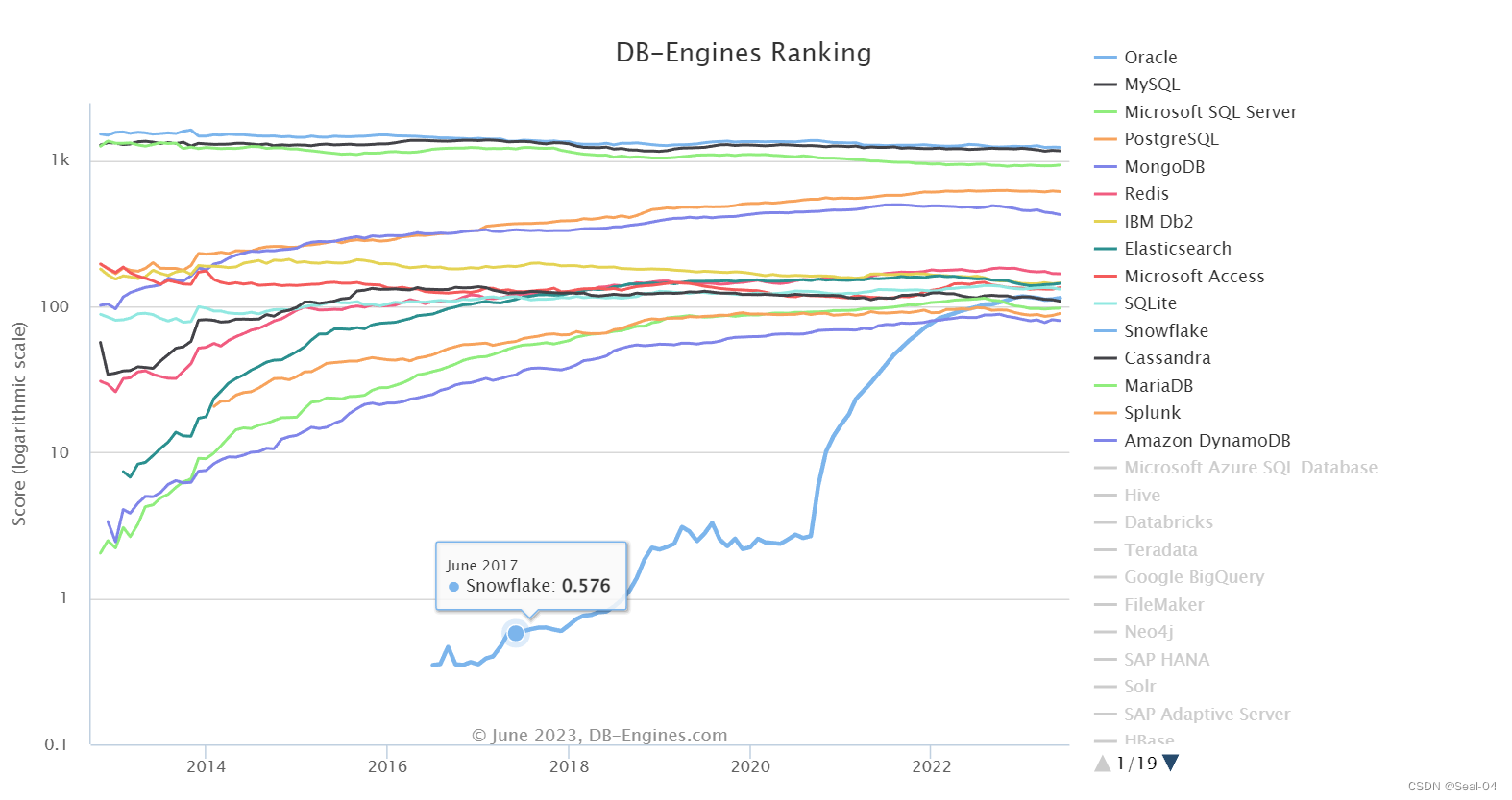
五、散点密度图绘图
import numpy as np
from statistics import mean
import matplotlib.pyplot as plt
from matplotlib import colors, cm
from sklearn.metrics import mean_squared_error
# 显示中文
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
def get_xyz(year):
real = pm_gdf.loc[:, f'y{year}'].to_numpy()
pred = pm_gdf.loc[:, f'r{year}'].to_numpy()
mask1 = ~np.isnan(real)
mask2 = ~np.isnan(pred)
mask = mask1 & mask2
real = real[mask]
pred = pred[mask]
xy = np.vstack([real, pred])
# 建立概率密度分布,并计算每个样本点的概率密度
z = gaussian_kde(xy)(xy)
return real, pred, z
def get_regression_line(real, pred, data_range=(0, 110)):
# 拟合(若换MK,自行操作)最小二乘
def slope(xs, ys):
m = (((mean(xs) * mean(ys)) - mean(xs * ys)) / ((mean(xs) * mean(xs)) - mean(xs * xs)))
b = mean(ys) - m * mean(xs)
return m, b
k, b = slope(real, pred)
regression_line = []
for a in range(data_range[0], data_range[1]+1):
regression_line.append((k * a) + b)
return regression_line
# 绘图,可自行调整颜色等等
fig, axs = plt.subplots(2, 3, constrained_layout=True, figsize=(9, 5))
years = [2015, 2016, 2017, 2018, 2019, 2020]
i = 1
vmin, vmax = 0, 0.5
for year, ax in zip(years, axs.flatten()):
real, pred, z = get_xyz(year)
scatter = ax.scatter(real, pred, marker='o', c=z*100, edgecolors=None, s=5,
label='LST', cmap='Spectral_r', vmin=vmin, vmax=vmax)
ax.plot([0, 120], [0, 120], 'k--', lw=1) # 画的1:1线
regression_line = get_regression_line(real, pred, data_range=(0, 120))
ax.plot(regression_line, 'r-', lw=1.) # 预测与实测数据之间的回归线
if i>3:
ax.set_xlabel('地基$\mathrm{PM_{2.5}(ug/m^3)}$')
if i==1 or i==4:
ax.set_ylabel('反演$\mathrm{PM_{2.5}(ug/m^3)}$')
if i<4:
ax.axes.xaxis.set_visible(False)
if i in [2, 3, 5, 6]:
ax.axes.yaxis.set_visible(False)
ax.set_xlim(0, 120) # 设置x坐标轴的显示范围
ax.set_xticks(range(0, 121, 20))
ax.set_ylim(0, 120) # 设置y坐标轴的显示范围
x, y = real, pred
BIAS = mean(x - y)
MSE = mean_squared_error(x, y)
RMSE = np.power(MSE, 0.5)
R = np.corrcoef(x, y)[0, 1]
ax.text(10, 110, '$N=%.f$' % len(y), family = 'Times New Roman')
ax.text(45, 110, '$R=%.2f$' % R, family = 'Times New Roman')
ax.text(10, 100, '$BIAS=%.2f$' % BIAS, family = 'Times New Roman')
ax.text(10, 90, '$RMSE=%.2f$' % RMSE, family = 'Times New Roman')
i += 1
cbar = fig.colorbar(cm.ScalarMappable(norm=colors.Normalize(vmin=vmin, vmax=vmax), cmap="RdYlBu_r"),
pad=0.012, orientation='vertical', aspect=30, ax=axs, label='Scatter Density')