2 hive的两种访问方式
2.4.1 命令行的方式
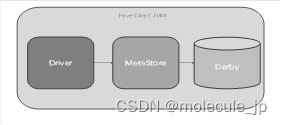
- 在前面的操作中,我们都是通过cli的方式访问hive的。
- 我们可以切身的体会到,通过cli的方式访问hive的不足,如:cli太过笨重,需要hive的jar支持。
2.4.2 HiveServer2模式
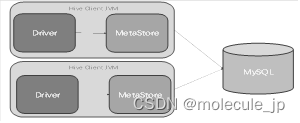
1.JDBC访问Hive示意图:
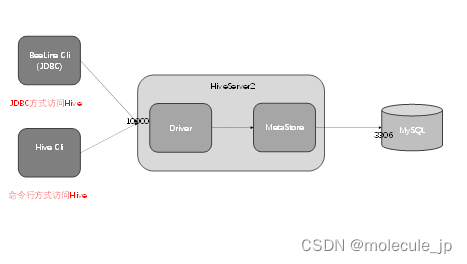
2. JDBC方式访问Hive
JDBC方式,本质上是将hive包装为服务发布出去,开发者使用JDBC的方式连接到服务,从而操作hive。
3. 开启Hiveserver2
1)在hive-site.xml文件中添加如下配置信息
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
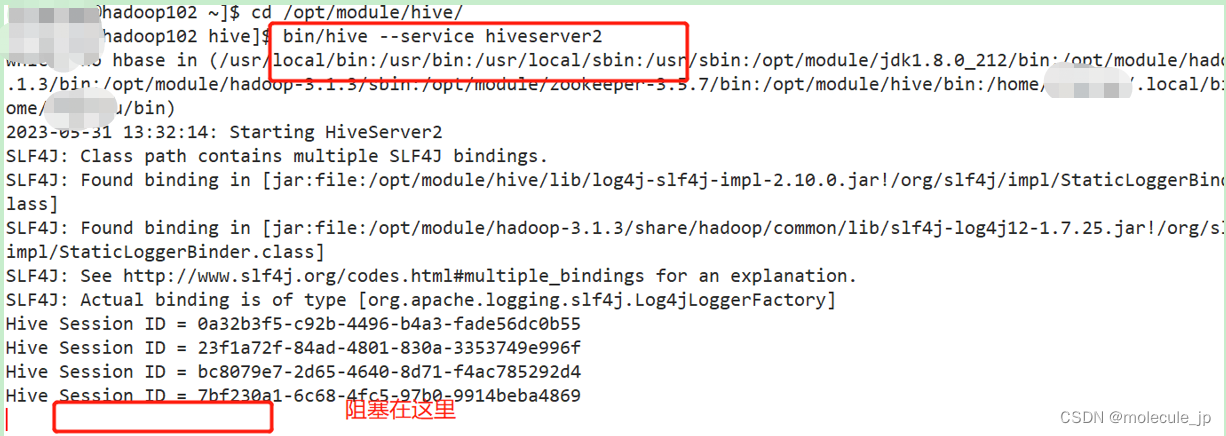
2)启动hive服务(这里需要考虑元数据的访问方式,如何使用元数据服务的模式,需要提前开启元数据服务)单独开一个窗口
[aa@hadoop102 hive]$ bin/hive --service hiveserver2
或者使用hive提供的hiveserver2脚本也可
这里启动服务的窗口不能CTRL+C也不能关闭,否则服务中断。这里必须回复到HA之前的集群,不用HA集群。
一个hadoop02窗口A
另一个hadoop102窗口B
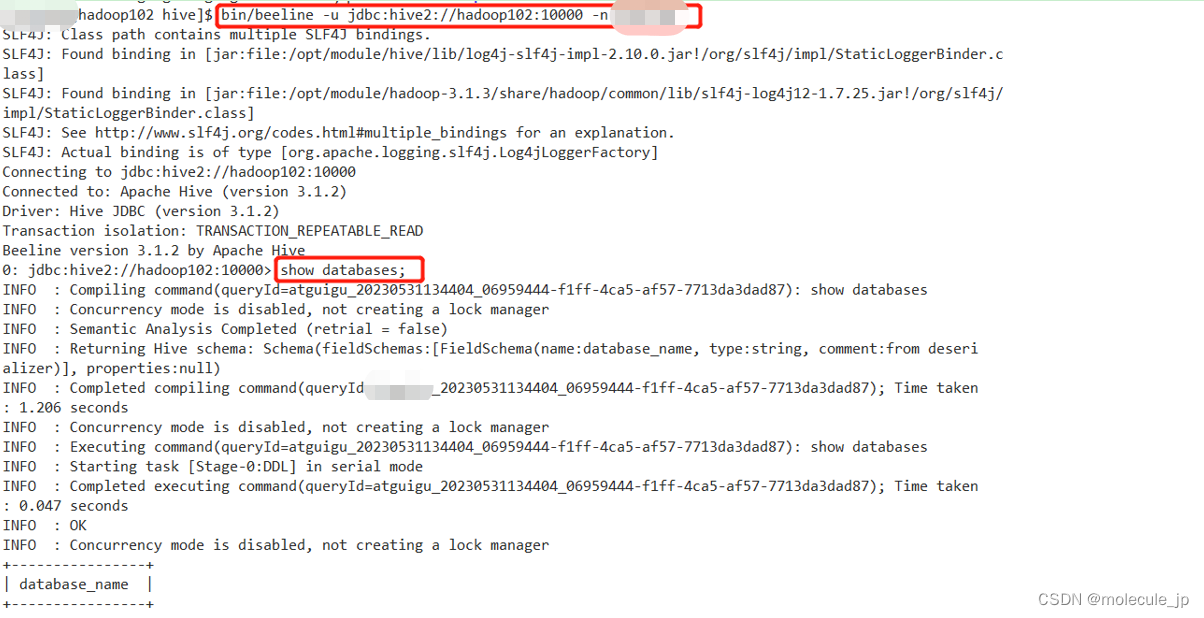
3)启动beeline客户端(需要多等待hadoop02窗口A一会,否则会报错连不上)再开另一个hadoop102窗口B
[aa@hadoop102 hive]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n aa
4)注意:如果出现异常报错,如aa is not allowed to impersonate aa
异常:aais not allowed to impersonate aa
解决方案:在hadoop中的core-site.xml中添加如下:
<property>
<name>hadoop.proxyuser.aa.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.aa.groups</name>
<value>*</value>
</property>
“*”表示可通过超级代理“xxx”操作hadoop的用户、用户组和主机
2.6 Hive常用交互命令
2.6.1 查看bin/hive 命令帮助
[aa@hadoop102 hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive commands. e.g. -d A=B or --define A=B
应用于hive命令的变量替换。如:-d A=B 或者 –-define A=B
--database <databasename> Specify the database to use
指定要使用的数据库
-e <quoted-query-string> SQL from command line
命令行中的SQL语句
-f <filename> SQL from files
文件中的SQL语句
-H,--help Print help information
打印帮助信息
--hiveconf <property=value> Use value for given property
设置属性值
--hivevar <key=value> Variable subsitution to apply to hive commands. e.g. --hivevar A=B
应用于hive命令的变量替换,如:--hivevar A=B
-i <filename> Initialization SQL file
初始化SQL文件
-S,--silent Silent mode in interactive shell
交互式Shell中的静默模式
-v,--verbose Verbose mode (echo executed SQL to the console)
详细模式(将执行的SQl回显到控制台)
2.6.2 命令中参数-e的使用
使用-e参数,可以不进入hive的交互窗口执行sql语句 临时
[atguigu@hadoop102 hive]$ bin/hive -e "select * from test2;"
……
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = 8f19d950-9936-4543-8b32-501dd61fa395
OK
1002
Time taken: 1.918 seconds, Fetched: 1 row(s)
2.6.3 命令中参数-f的使用
使用-f参数,可以不进入hive交互窗口,执行脚本中sql语句
1)在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
[aa@hadoop102 hive]$ mkdir /opt/module/hive/datas
[aa@hadoop102 hive]$ touch /opt/module/hive/datas/hive-f.sql
2)文件中写入正确的sql语句
[aa@hadoop102 datas]$ vim /opt/module/hive/datas/hive-f.sql
select * from test2;
3)执行文件中的sql语句
[aa@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql
4)我们还可以通过执行文件中的sql语句,将结果写入指定文件中
[aa@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/datas/hive_result.txt
2.7 Hive常见属性配置
2.7.1 Hive运行日志信息配置
1.Hive的log默认存放路径:/tmp/aa/hive.log(当前用户名下)
2.修改hive的log存放路径:到/opt/module/hive/logs
① 修改conf目录下hive-log4j2.properties.template文件名称为hive-log4j2.properties
[aa@hadoop102 hive]$ mv conf/hive-log4j2.properties.template conf/hive-log4j2.properties
② 在hive-log4j.properties文件中修改log存放位置
[aa@hadoop102 hive]$ vim conf/hive-log4j2.properties
property.hive.log.dir=/opt/module/hive/logs
3)再次启动hive,观察目录/opt/module/hive/logs下是否产生日志
2.7.2 Hive启动JVM堆内存配置
1.问题:
新版Hive启动时,默认申请的JVM堆内存大小为256M,内存太小,导致若后期开启本地模式,执行相对复杂的SQL经常会报错:java.lang.OutOfMemoryError: Java heap space
2.解决:修改HADOOP_HEAPSIZE参数的值
1)修改/opt/module/hive/conf/下的hive-env.sh.template
[aa@hadoop102 hive]$ mv conf/hive-env.sh.template conf/hive-env.sh
[aa@hadoop102 hive]$ vim conf/hive-env.sh
……
export HADOOP_HEAPSIZE=1024
2.7.3 hive窗口打印默认库和表头
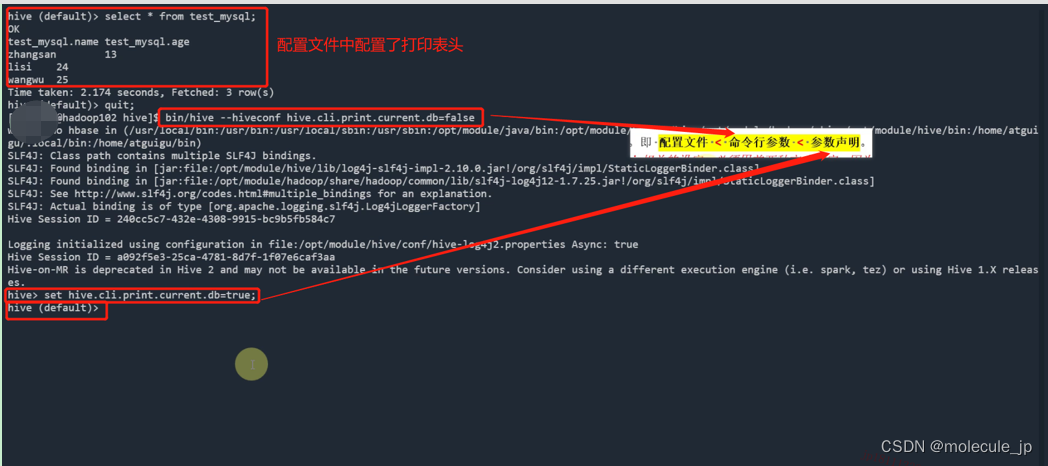
1.问题:在hive命令行交互窗口中,切换数据库后,不会提示当前所在数据库是哪个,并且在列出的查询结果中也不会带有列名的信息,使用中多有不便。
2.配置:可以修改hive.cli.print.header和hive.cli.print.current.db两个参数的值,打印出当前库头。
编辑hive-site.xml添加如下两个配置:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
修改之后重新启动hive
2.7.4 参数配置方式
1.set 命令使用:查看当前所有的配置信息
hive>set;
2.配置参数的三种方式:

3.三种配置方式的优先级
上述三种设定方式的优先级依次递增。即 配置文件 < 命令行参数 < 参数声明。
注意:某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
4.测试三种配置方式优先级
1)在2.7.3中配置文件中设置了hive.cli.print.header和 hive.cli.print.current.db这两个参数。
[aa@hadoop102 hive]$ bin/hive
hive (default)> select * from test2;
OK
test2.id
1002
Time taken: 1.565 seconds, Fetched: 1 row(s)
2)通过set命令,设置hive.cli.print.current.db 参数位false
hive(default)> set hive.cli.print.current.db = false;
hive>
3)退出,重启hive,命令如下
[aa@hadoop102 hive]$ bin/hive –hiveconf hive.cli.print.current.db = false
hive>


![问题解决:微信开发者工具显示清除登录状态失败 TypeError: Failed to fetch [1.06.2303220][win32-x64]](https://img-blog.csdnimg.cn/b426ef86c7874571987deec18c6453cc.png#pic_center)





![[SpringBoot]Knife4j框架Knife4j的显示内容的配置](https://img-blog.csdnimg.cn/dfabe1d4d96b41b0b32d3c62dc99f02d.png)