前言 多尺度流层可以更有效地提取多尺度信息,而基于显著性的学习融合层有利于重要特征通道的自动选择,因此MuDeep在学习鉴别模式方面很强大。其实这也是目前大多数深度学习任务发表论文的趋势,即多尺度、显著性特征的表示。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
Transformer、目标检测、语义分割交流群
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV各大方向专栏与各个部署框架最全教程整理
Information
- Title:Multi-scale Deep Learning Architectures for Person Re-identifification
- From:ICCV2017
- Paper Link:https://openaccess.thecvf.com/content_ICCV_2017/papers/Qian_Multi-Scale_Deep_Learning_ICCV_2017_paper.pdf
- Fudan university
motivation
行人重识别问题中,许多行人的穿着和外形很相似,在外观上的差异很微妙,只有在正确的位置和尺度上才能检测到,因此提出手工设计的多尺度深度学习模型。
Abstract
监控录像中捕捉到的许多人都穿着类似的衣服,它们在外观上的差异往往是微妙的,只有在正确的位置和尺度上才能检测到。现有的re-id模型,特别是基于深度学习的模型仅在单一尺度上匹配人。
本文提出了一种多尺度深度学习模型。(1)能够学习不同尺度上的深度鉴别特征表示,并自动确定最适合的匹配尺度。(2)明确地学习了不同空间位置对提取鉴别特征的重要性。
Introduction
在不同的相机视图中,一个人的外观经常会由于身体姿势、相机视点、遮挡和照明条件的变化而发生显著的变化。在公共空间,许多人经常穿非常相似的衣服(例如,冬天的深色外套),可以用来区分它们的差异往往是微妙的。
学习判别特征表示是深度重识别模型的关键目标,这些特征需要在多个尺度上进行计算。以图1(a)中的两幅图像为例。在粗糙的层面上,衣服的颜色和文本信息非常相似;因此,人类会进入更精细的尺度,通过细微的局部差异(例如发型、鞋子和图1中左边人夹克上的白色条纹)得出结论,这是两个不同的人。
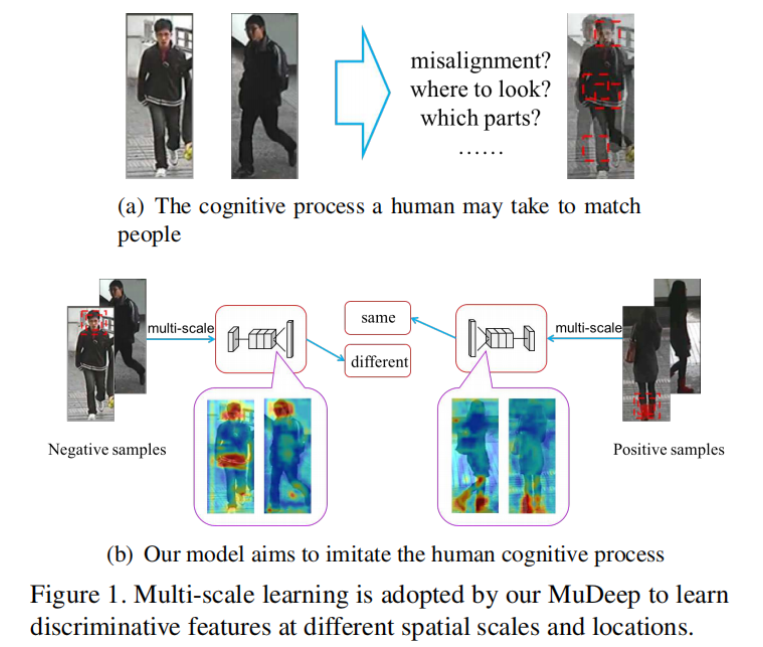
现有的模型通常采用多分支深度卷积神经网络,每个分支由多个卷积/池化层和全连接层组成,最后的全连接层被用作两两验证或三重排序损失的输入,以学习一个联合嵌入空间。一项对CNN的每一层实际学习的东西的可视化研究表明,更高层的网络在全局尺度上以更少的空间信息捕获了更抽象的语义概念。当特征到达最终的全连接层时,更精细和局部尺度的信息已经丢失,无法恢复。这意味着现有的深度re-id架构不适合进行多尺度的人员匹配。
作者提出了一种多尺度深度学习模型(MuDeep),旨在学习多尺度上的区别特征表示,并使用自动确定的尺度权重进行组合(图1(b))。更具体地说,MuDeep网络架构是基于Siamese网络,但关键是能够学习不同尺度的特征,并评估它们对跨摄像机匹配的重要性。这是通过引入两种新的层来实现的:multi-scale
stream layers(多尺度流层),通过分析多尺度的人图像来提取图像特征;以及saliency-based learning fusion layer(基于显著性的学习融合层),它有选择性地学习融合多尺度的数据流,生成MuDeep中每个分支更具区别性的特征。作者还在网络的中间层引入了一对分类损失,以监督多尺度特征学习。
Method
网络架构
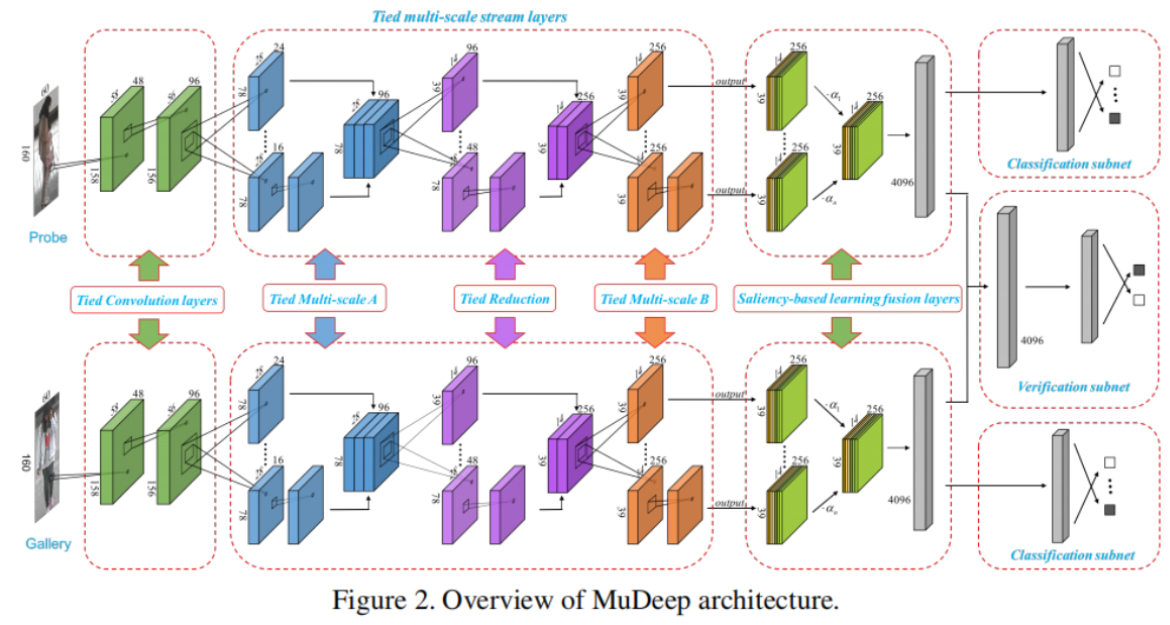
MuDeep有两个分支来处理每个图像对,它由五个组件组成:(分支间)捆绑的卷积层、多尺度的流层,基于显著性的学习融合层,验证子网络和分类子网络。
捆绑的卷积层
这些层的权重被绑定到两个分支中,以强制执行滤波器来学习由两个分支共享的视觉模式。
多尺度流层
分析多尺度(1×1、3×3和5×5)的数据流。Multi-scale-A layer为了增加这一层的深度和宽度,将5×5的滤波器大小分成两个级联的3×3流,多尺度数据可以隐式地作为一种增加训练数据的方法。所有这些层在两个分支的对应流之间共享权值;但是,在同一分支的每个两个数据流中,参数不绑定。Reduction layer进一步以多尺度的方式通过数据流,并将特征图的宽度和高度减少一半,原则上应该从78×28减少到39×14,同样,这里的每个滤波器的权重被绑定为成对的流。Multi-scale-B layer作为1×1、3×3和5×5的多尺度的高级特征提取的最后阶段,除了将5×5流分解为两个级联的3×3流,进一步将3×3大小的滤波器分解为一个1×3滤波器,然后是3×1滤波器。这带来了几个好处,包括降低3×3滤波器的计算成本,进一步增加该组件的深度,以及能够从接受域提取非对称特征。这里仍然绑定每个过滤器的权重。
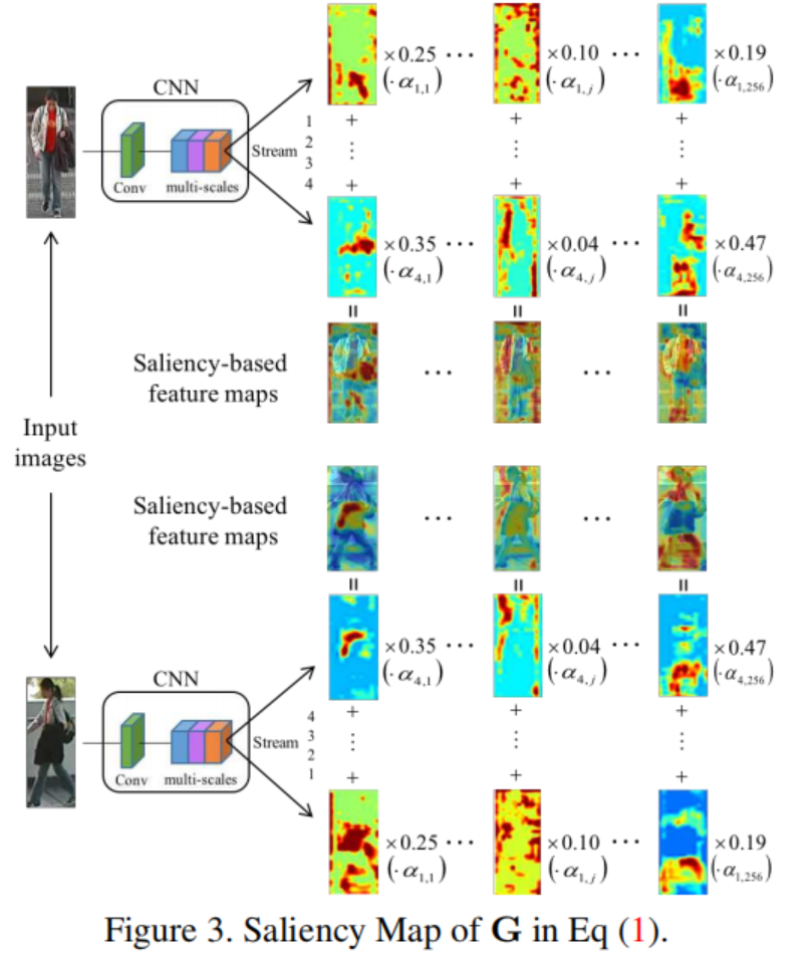
基于显著性的学习融合层
提出了该层用于融合多尺度流层的输出。直观地说,通过前一层处理的输出,产生的数据通道具有冗余信息,一些通道可能捕获到相对重要的人员信息,而其他通道可能只对背景上下文建模。因此,本文利用基于显著性的学习策略,自动发现并强调提取出高度区分模式的通道,如头部、身体、手臂、衣服、包等信息,如图3所示。因此,我们假设*Fi⋆*表示每个分支中第1−个流(1≤i≤4)的输入特征图,*Fij表示Fi⋆*的第j个通道,即(1≤j≤256),输出特征图表示为G,将融合四种流;Gj表示G的第j个通道图,计算方法为:
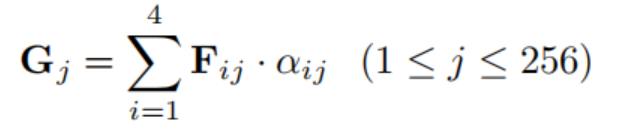
在基于显著性的学习融合层的基础上添加一个全连接层,提取每幅图像的4096维特征。该设计的思想是:1)集中基于显著性的学习特征并降维,2)提高测试的效率。
验证子网络
接受前一层提取的特征对作为输入,用特征差异层计算距离,然后是512个神经元的全连接层,有2个softmax输出,输出表示“同一个人”或“不同的人”的概率。本文采用特征差异层来融合两个分支的特征,并计算两幅图像之间的距离。如果输入图像对被标记为“同一人”,则多尺度流层和基于显著性的学习融合层生成的特征应该相似;换句话说,特征差异层的输出值应该接近于零;否则,值有不同的响应。
分类子网络
为了学习外观表示的强鉴别特征,我们在每个分支的基于显著性的学习融合层之后添加了分类子网。分类子网对具有不同行人身份的图像进行分类。在基于显著性的学习融合层中提取4096维特征后,连接一个具有N个输出神经元的softmax,其中N表示行人身份的数量。
实验细节
框架:Caffe
计算卡:TITANX
学习率:0.001,每50000次迭代衰减十分之一
batch size:32
图像输入大小:60*160*3
drop out:0.3
实验结果
不同数据集的比较
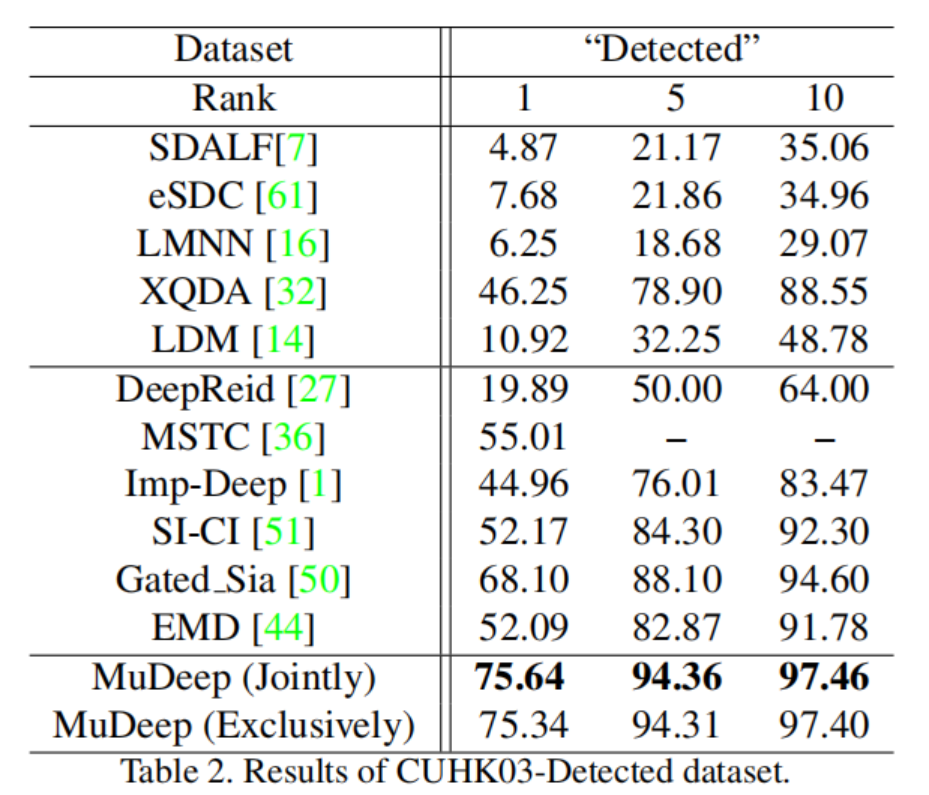
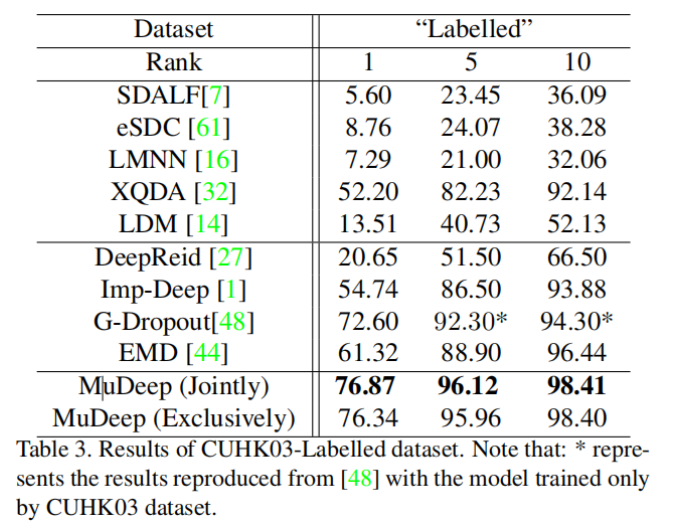
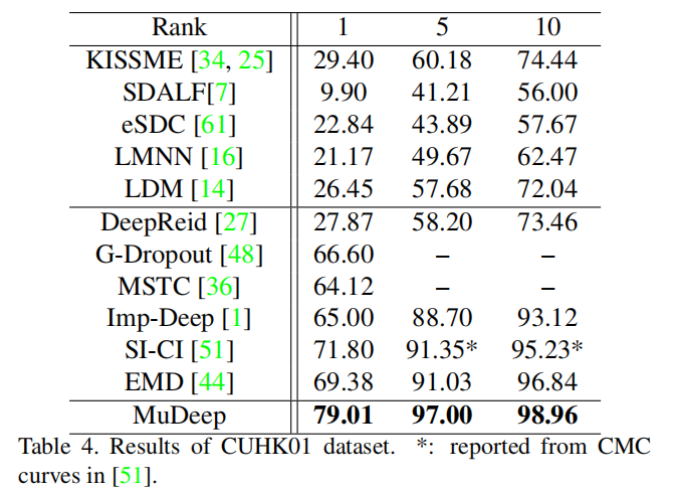
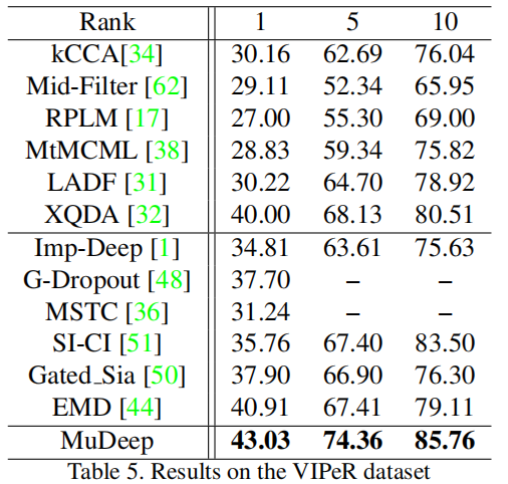
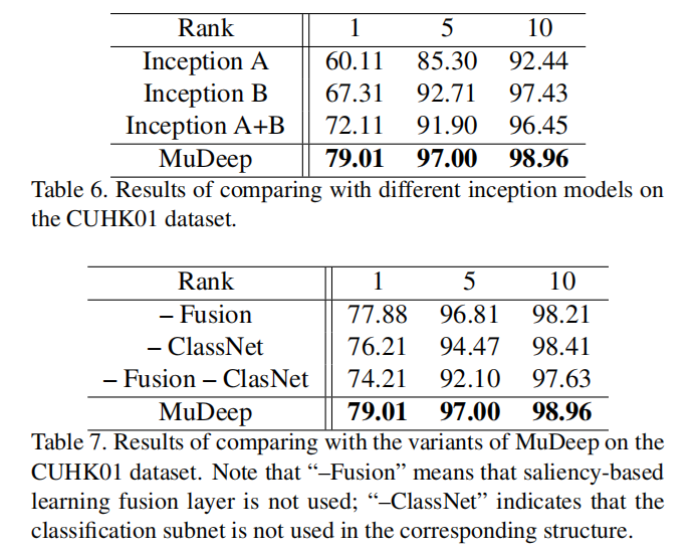
消融实验
结论
多尺度流层可以更有效地提取多尺度信息,而基于显著性的学习融合层有利于重要特征通道的自动选择,因此MuDeep在学习鉴别模式方面很强大。其实这也是目前大多数深度学习任务发表论文的趋势,即多尺度、显著性特征的表示。此外,在全局特征学习的前提下,重识别中的注意力机制自然发展了起来。在下一篇论文解读中,我们将介绍一种新颖的注意感知特征学习方法,该方法针对行人全局和局部分别计算注意力相关的信息。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式
CVPR 2023 | 即插即用的注意力模块 HAT: 激活更多有用的像素助力low-level任务显著涨点!
ICML 2023 | 轻量级视觉Transformer (ViT) 的预训练实践手册
即插即用系列 | 高效多尺度注意力模块EMA成为YOLOv5改进的小帮手
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
ReID专栏(三) 注意力的应用
ReID专栏(二)多尺度设计与应用
ReID专栏(一) 任务与数据集概述
libtorch教程(三)简单模型搭建
libtorch教程(二)张量的常规操作
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
异常检测专栏(三)传统的异常检测算法——上
异常检测专栏(二):评价指标及常用数据集
异常检测专栏(一)异常检测概述
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!_
CV最全知识体系和技术教程
![问题解决:微信开发者工具显示清除登录状态失败 TypeError: Failed to fetch [1.06.2303220][win32-x64]](https://img-blog.csdnimg.cn/b426ef86c7874571987deec18c6453cc.png#pic_center)





![[SpringBoot]Knife4j框架Knife4j的显示内容的配置](https://img-blog.csdnimg.cn/dfabe1d4d96b41b0b32d3c62dc99f02d.png)