根据MMPose的官方文档学习一下
MMPose文档地址:https://mmpose.readthedocs.io/zh_CN/latest/index.html
文章目录
- 1. 概述
- 2. 安装
- 2.1 创建conda环境并激活
- 2.2 安装pytorch
- 2.3 使用 MIM 安装 MMEngine 和 MMCV
- 2.4 安装MMPose
- 3. 20 分钟了解 MMPose 架构设计
- 3.1 总览
- 3.2 配置文件
- 3.3 数据
- 3.3.1 数据集元信息
- 3.3.2 数据集
- 3.3.3 数据流水线
- 3.4 模型
1. 概述
MMPose 是一款基于 Pytorch 的姿态估计开源工具箱,是 OpenMMLab 项目的成员之一,包含了丰富的 2D 多人姿态估计、2D 手部姿态估计、2D 人脸关键点检测、133关键点全身人体姿态估计、动物关键点检测、服饰关键点检测等算法以及相关的组件和模块,下面是它的整体框架:
MMPose 由 8 个主要部分组成,apis、structures、datasets、codecs、models、engine、evaluation 和 visualization。
-
apis 提供用于模型推理的高级 API
-
structures 提供 bbox、keypoint 和 PoseDataSample 等数据结构
-
datasets 支持用于姿态估计的各种数据集
- transforms 包含各种数据增强变换
-
codecs 提供姿态编解码器:编码器用于将姿态信息(通常为关键点坐标)编码为模型学习目标(如热力图),解码器则用于将模型输出解码为姿态估计结果
-
models 以模块化结构提供了姿态估计模型的各类组件
-
pose_estimators 定义了所有姿态估计模型类
-
data_preprocessors 用于预处理模型的输入数据
-
backbones 包含各种骨干网络
-
necks 包含各种模型颈部组件
-
heads 包含各种模型头部
-
losses 包含各种损失函数
-
-
engine 包含与姿态估计任务相关的运行时组件
- hooks 提供运行时的各种钩子
-
evaluation 提供各种评估模型性能的指标
-
visualization 用于可视化关键点骨架和热力图等信息
2. 安装
我电脑已经安装了anaconda
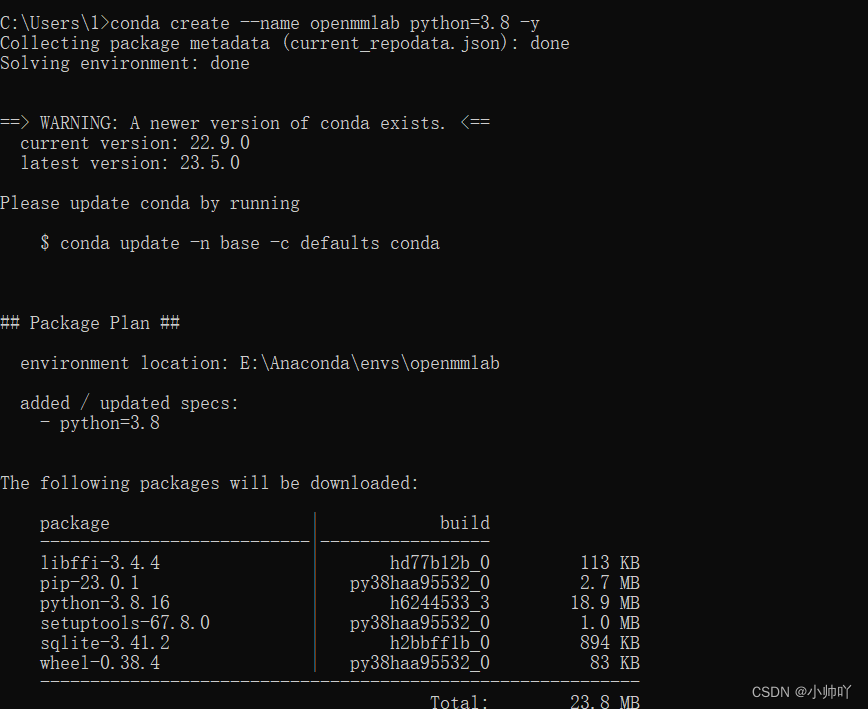
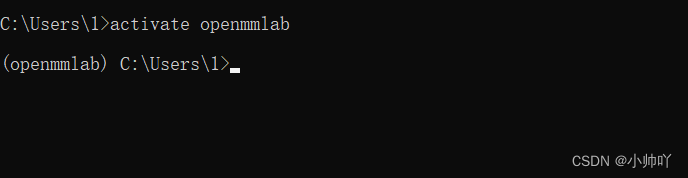
2.1 创建conda环境并激活
conda create --name openmmlab python=3.8 -y
激活环境
activate openmmlab
2.2 安装pytorch
这里第一遍按照mmpose官方文档安成cpu版本了
这次用pytorch的官方文档安装
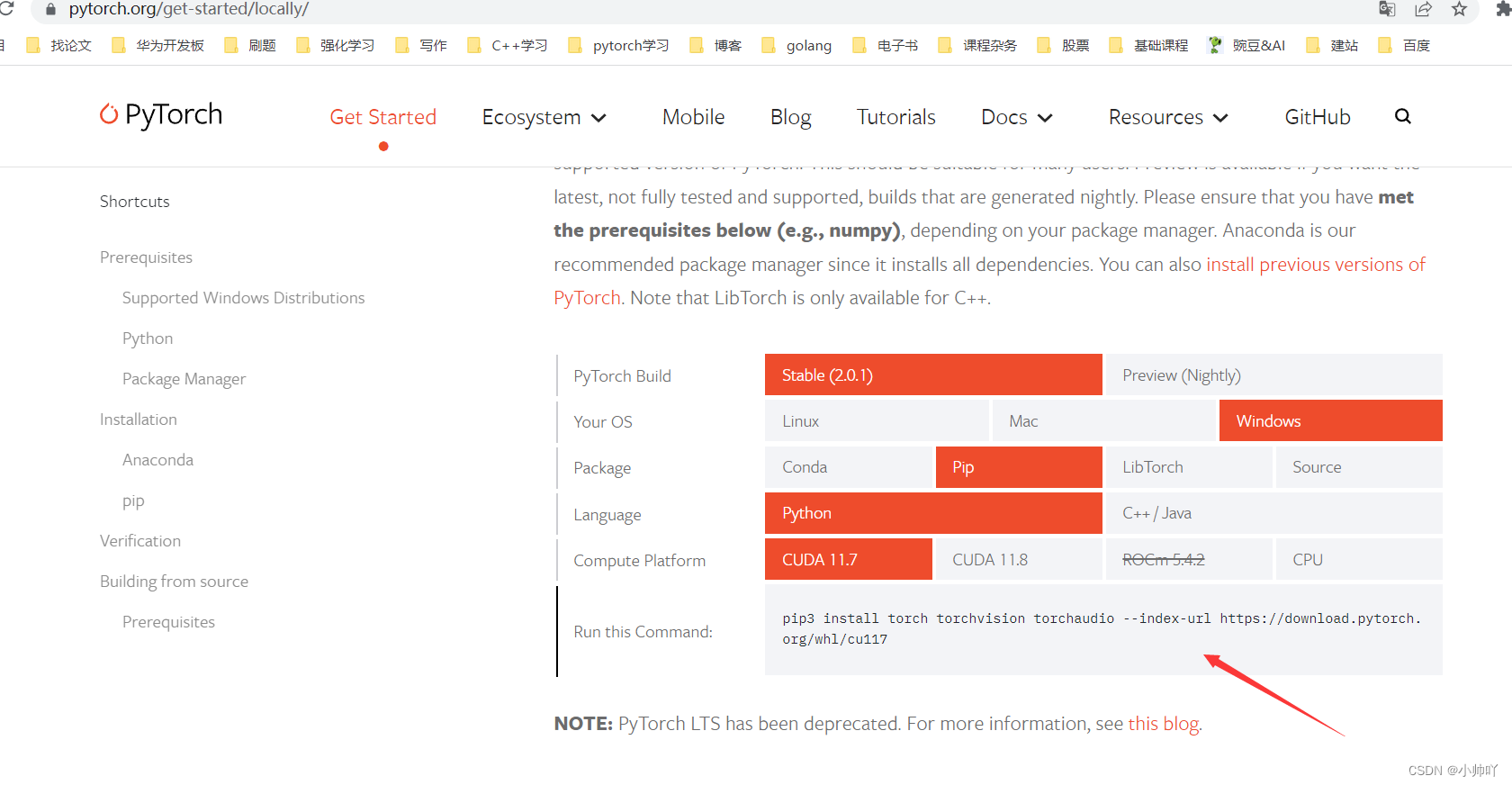
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
2.3 使用 MIM 安装 MMEngine 和 MMCV
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"
请注意,MMPose 中的一些推理示例脚本需要使用 MMDetection (mmdet) 检测人体。如果您想运行这些示例脚本,可以通过运行以下命令安装 mmdet:
mim install "mmdet>=3.0.0"
2.4 安装MMPose
根据具体需求,我们支持两种安装模式: 从源码安装(推荐)和作为 Python 包安装。
如果基于 MMPose 框架开发自己的任务,需要添加新的功能,比如新的模型或是数据集,或者使用我们提供的各种工具。按官方推荐的源码安装来,从源码按如下方式安装 mmpose:
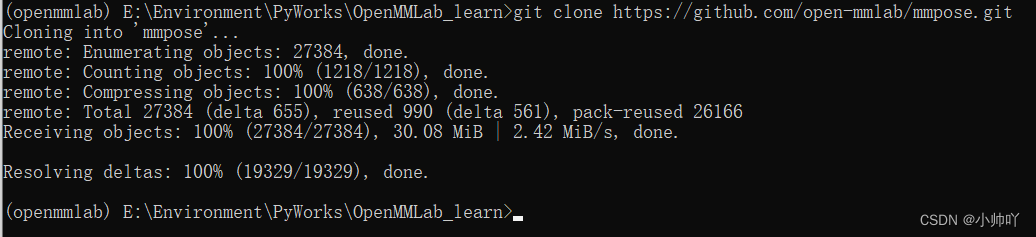
这里首先进入一个你想放置项目的文件下
然后执行以下命令下载安装mmpose
git clone https://github.com/open-mmlab/mmpose.git
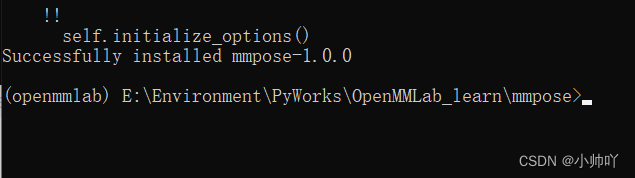
cd mmpose
pip install -r requirements.txt
pip install -v -e .
验证安装
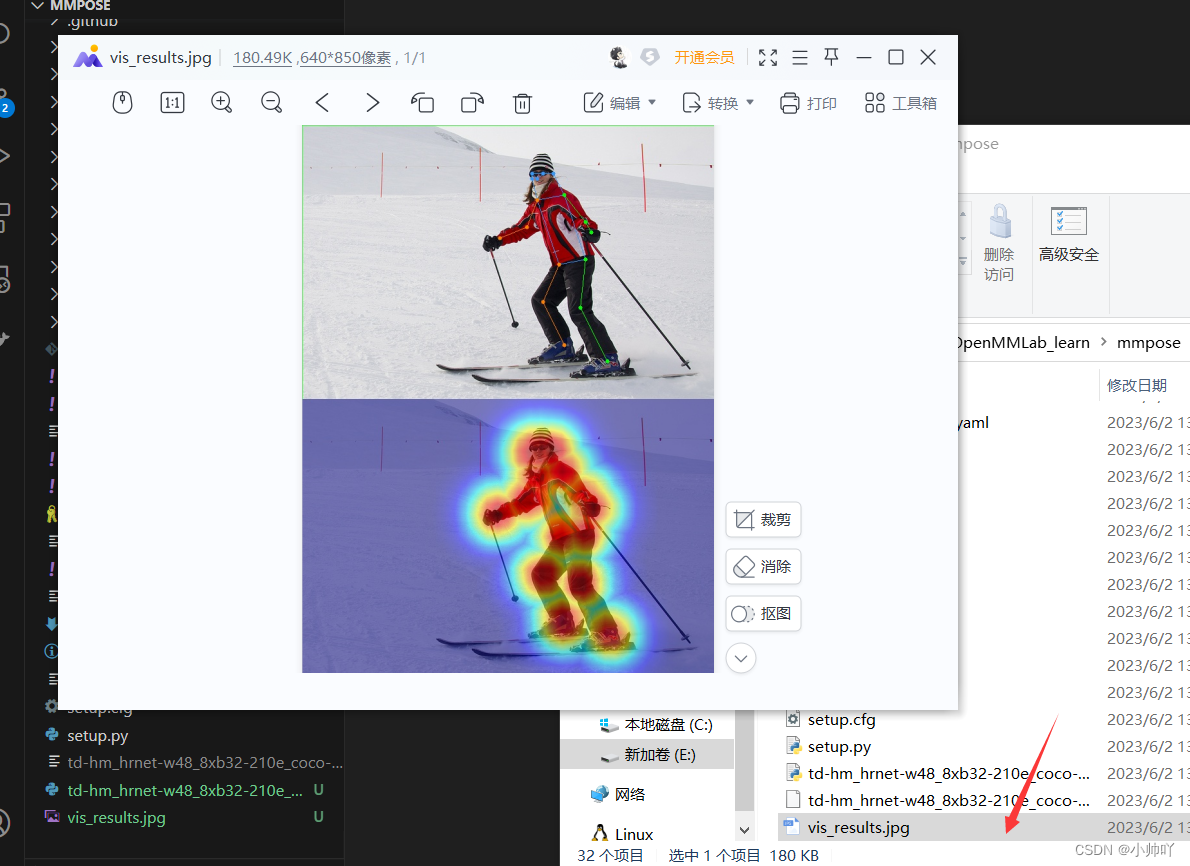
为了验证 MMPose 是否安装正确,您可以通过以下步骤运行模型推理。
第 1 步 我们需要下载配置文件和模型权重文件
mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest .
下载过程往往需要几秒或更多的时间,这取决于您的网络环境。完成之后,您会在当前目录下找到这两个文件:td-hm_hrnet-w48_8xb32-210e_coco-256x192.py 和 hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth, 分别是配置文件和对应的模型权重文件。

第 2 步 验证推理示例
如果您是从源码安装的 mmpose,可以直接运行以下命令进行验证:
python demo/image_demo.py tests/data/coco/000000000785.jpg td-hm_hrnet-w48_8xb32-210e_coco-256x192.py td-hm_hrnet-w48_8xb32-210e_coco-256x192-0e67c616_20220913.pth --out-file vis_results.jpg --draw-heatmap
emmmm这里注意官方文档里这个命令的模型文件名错了,用上面这个命令执行即可。
3. 20 分钟了解 MMPose 架构设计
MMPose 1.0 与之前的版本有较大改动,对部分模块进行了重新设计和组织,降低代码冗余度,提升运行效率,降低学习难度。
MMPose 1.0 采用了全新的模块结构设计以精简代码,提升运行效率,降低学习难度。对于有一定深度学习基础的用户,本章节提供了对 MMPose 架构设计的总体介绍。不论你是旧版 MMPose 的用户,还是希望直接从 MMPose 1.0 上手的新用户,都可以通过本教程了解如何构建一个基于 MMPose 1.0 的项目。
3.1 总览
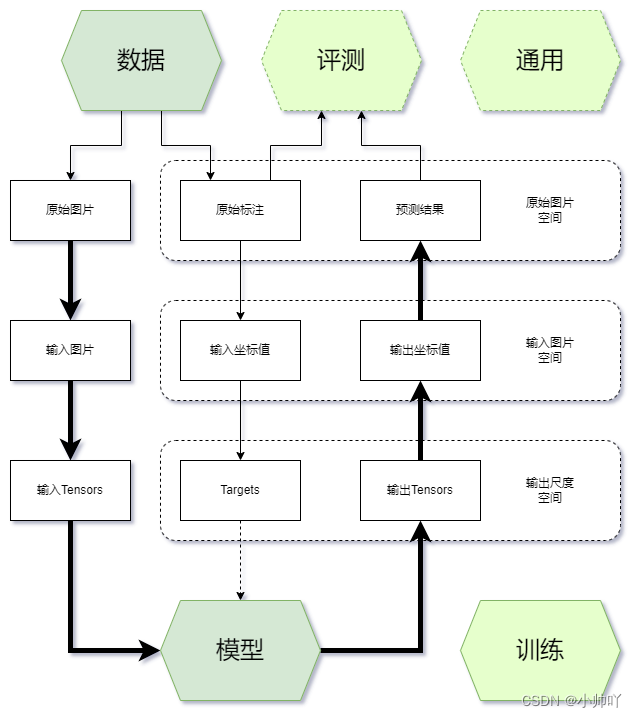
一般来说,开发者在项目开发过程中经常接触内容的主要有五个方面:
-
通用:环境、钩子(Hook)、模型权重存取(Checkpoint)、日志(Logger)等
-
数据:数据集、数据读取(Dataloader)、数据增强等
-
训练:优化器、学习率调整等
-
模型:主干网络、颈部模块(Neck)、预测头模块(Head)、损失函数等
-
评测:评测指标(Metric)、评测器(Evaluator)等
其中通用、训练和评测相关的模块往往由训练框架提供,开发者只需要调用和调整参数,不需要自行实现,开发者主要实现的是数据和模型部分。
3.2 配置文件
在MMPose中,我们通常 python 格式的配置文件,用于整个项目的定义、参数管理,因此我们强烈建议第一次接触 MMPose 的开发者,查阅 配置文件 学习配置文件的定义。
需要注意的是,所有新增的模块都需要使用注册器(Registry)进行注册,并在对应目录的 init.py 中进行 import,以便能够使用配置文件构建其实例。
MMPose 拥有一套强大的配置系统,在注册器的配合下,用户可以通过一个配置文件来定义整个项目需要用到的所有内容,以 Python 字典形式组织配置信息,传递给注册器完成对应模块的实例化。
下面是一个常见的 Pytorch 模块定义的例子:
# 在loss_a.py中定义Loss_A类
Class Loss_A(nn.Module):
def __init__(self, param1, param2):
self.param1 = param1
self.param2 = param2
def forward(self, x):
return x
# 在需要的地方进行实例化
loss = Loss_A(param1=1.0, param2=True)
只需要通过一行代码对这个类进行注册:
# 在loss_a.py中定义Loss_A类
from mmpose.registry import MODELS
@MODELS.register_module() # 注册该类到 MODELS 下
Class Loss_A(nn.Module):
def __init__(self, param1, param2):
self.param1 = param1
self.param2 = param2
def forward(self, x):
return x
并在对应目录下的 init.py 中进行 import:
# __init__.py of mmpose/models/losses
from .loss_a.py import Loss_A
__all__ = ['Loss_A']
我们就可以通过如下方式来从配置文件定义并进行实例化:
# 在config_file.py中定义
loss_cfg = dict(
type='Loss_A', # 通过type指定类名
param1=1.0, # 传递__init__所需的参数
param2=True
)
# 在需要的地方进行实例化
loss = MODELS.build(loss_cfg) # 等价于 loss = Loss_A(param1=1.0, param2=True)
3.3 数据
3.3.1 数据集元信息
元信息指具体标注之外的数据集信息。姿态估计数据集的元信息通常包括:关键点和骨骼连接的定义、对称性、关键点性质(如关键点权重、标注标准差、所属上下半身)等。这些信息在数据在数据处理、模型训练和测试中有重要作用。在 MMPose 中,数据集的元信息使用 python 格式的配置文件保存,位于 $MMPOSE/configs/base/datasets 目录下。
在 MMPose 中使用自定义数据集时,你需要增加对应的元信息配置文件。以 MPII 数据集($MMPOSE/configs/base/datasets/mpii.py)为例:
dataset_info = dict(
dataset_name='mpii',
paper_info=dict(
author='Mykhaylo Andriluka and Leonid Pishchulin and '
'Peter Gehler and Schiele, Bernt',
title='2D Human Pose Estimation: New Benchmark and '
'State of the Art Analysis',
container='IEEE Conference on Computer Vision and '
'Pattern Recognition (CVPR)',
year='2014',
homepage='http://human-pose.mpi-inf.mpg.de/',
),
keypoint_info={
0:
dict(
name='right_ankle',
id=0,
color=[255, 128, 0],
type='lower',
swap='left_ankle'),
## 内容省略
},
skeleton_info={
0:
dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
## 内容省略
},
joint_weights=[
1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
],
# 使用 COCO 数据集中提供的 sigmas 值
sigmas=[
0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
0.062, 0.072, 0.179, 0.179, 0.072, 0.062
])
在模型配置文件中,你需要为自定义数据集指定对应的元信息配置文件。假如该元信息配置文件路径为 $MMPOSE/configs/base/datasets/custom.py,指定方式如下:
# dataset and dataloader settings
dataset_type = 'MyCustomDataset' # or 'CocoDataset'
train_dataloader = dict(
batch_size=2,
dataset=dict(
type=dataset_type,
data_root='root/of/your/train/data',
ann_file='path/to/your/train/json',
data_prefix=dict(img='path/to/your/train/img'),
# 指定对应的元信息配置文件
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
...),
)
val_dataloader = dict(
batch_size=2,
dataset=dict(
type=dataset_type,
data_root='root/of/your/val/data',
ann_file='path/to/your/val/json',
data_prefix=dict(img='path/to/your/val/img'),
# 指定对应的元信息配置文件
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
...),
)
test_dataloader = val_dataloader
3.3.2 数据集
在 MMPose 中使用自定义数据集时,我们推荐将数据转化为已支持的格式(如 COCO 或 MPII),并直接使用我们提供的对应数据集实现。如果这种方式不可行,则用户需要实现自己的数据集类。
3.3.3 数据流水线
一个典型的数据流水线配置如下:
# pipelines
train_pipeline = [
dict(type='LoadImage'),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
dict(type='RandomHalfBody'),
dict(type='RandomBBoxTransform'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
test_pipeline = [
dict(type='LoadImage'),
dict(type='GetBBoxCenterScale'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='PackPoseInputs')
]
在关键点检测任务中,数据一般会在三个尺度空间中变换:
原始图片空间:图片存储时的原始空间,不同图片的尺寸不一定相同
输入图片空间:模型输入的图片尺度空间,所有图片和标注被缩放到输入尺度,如 256x256,256x192 等
输出尺度空间:模型输出和训练监督信息所在的尺度空间,如64x64(热力图),1x1(回归坐标值)等。
3.4 模型
在 MMPose 1.0中,模型由以下几部分构成:
预处理器(DataPreprocessor):完成图像归一化和通道转换等前处理
主干网络 (Backbone):用于特征提取
颈部模块(Neck):GAP,FPN 等可选项
预测头(Head):用于实现核心算法功能和损失函数定义
![问题解决:微信开发者工具显示清除登录状态失败 TypeError: Failed to fetch [1.06.2303220][win32-x64]](https://img-blog.csdnimg.cn/b426ef86c7874571987deec18c6453cc.png#pic_center)





![[SpringBoot]Knife4j框架Knife4j的显示内容的配置](https://img-blog.csdnimg.cn/dfabe1d4d96b41b0b32d3c62dc99f02d.png)