一:语法执行背景
ES boo查询中过多的拼接bool导致报maxClauseCount is set to 5000
{
- "caused_by": {
}
- "type": "too_many_clauses",
- "reason": "maxClauseCount is set to 5000"
}
查询DSL语句:
{
"from": 0,
"size": 20,
"query": {
"bool": {
"must": [
{
"match": {
"name": {
"query": "普通硅酸盐水泥(P·O)",
"boost": 5
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"min_score": 5,
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
二:分析原因
报错原因:是Search限制一个bool查询中最多只能有5000个值或子查询,当超过5000时,会抛出异常。
实际原因:name字段使用的分词器使用了同义词,导致“普通硅酸盐水泥(P·O) 42.5级”,被识别成了“水泥,复合硅酸盐水泥(P·O) 42.5级,普通硅酸盐水泥(P·O) 42.5级”,再经过分词器分词之后,会出现很多个term,导致查询bool超过限制。
三:解决办法
方案一:当超过5000时可以将一个bool查询拆成两个子bool查询,使用must关键字,使得两个子bool查询是与的关系。【拆分要去优化的查询语法,本次未实验】
方案二:编辑elasticsearch.yml,添加如下配置 index.query.bool.max_clause_count: 10240 注意:必须在最前面添加一个空格,即和其他配置首字母对齐,不然es启动报错。
【随着数据量的增大,其实这个值会不断的需要改大,我就是从0改到1000改到5000又触发了】
方案三:由于索引分词使用了同义词,可以将查询分词和索引分词分开,单独设置查询分词。因为如果我们查询时不传入分词器,则默认会用索引词的分词器,同义词的分词器一般都很大,如下图:
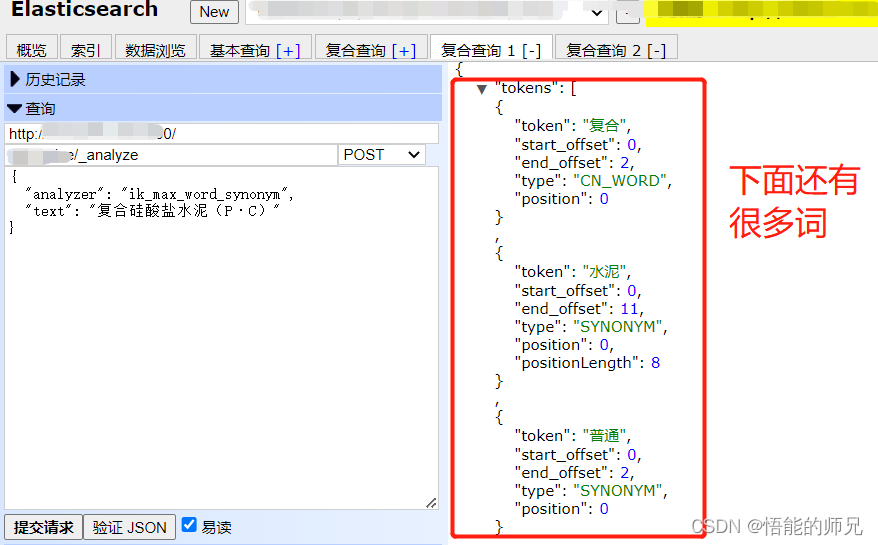
{
"from": 0,
"size": 20,
"query": {
"bool": {
"must": [
{
"match": {
"name": {
"query": "普通硅酸盐水泥(P·O)",
"analyzer": "ik_max_word",
"boost": 5
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"min_score": 5,
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
这种方式是治本模式,发现哪几个词出现了子查询超出,就对这几个词单独处理,当然这几个词也会丢失同义词的匹配算法,但是我们可以加入完整匹配权重。
![问题解决:微信开发者工具显示清除登录状态失败 TypeError: Failed to fetch [1.06.2303220][win32-x64]](https://img-blog.csdnimg.cn/b426ef86c7874571987deec18c6453cc.png#pic_center)





![[SpringBoot]Knife4j框架Knife4j的显示内容的配置](https://img-blog.csdnimg.cn/dfabe1d4d96b41b0b32d3c62dc99f02d.png)