一.概念
B树是一种多路平衡查找树,不同于二叉平衡树,他不只是有两个分支,而是有多个分支,一棵m阶B树(balanced tree of order m)是一棵平衡的m路搜索树,B树用于磁盘寻址,它是一种高效的查找算法。
二.性质
- 根节点至少有2个子女
- 每个非根节点所包含的关键字个数x满足以下关系:⌈m/2⌉−1⩽x⩽m−1\lceil m/2 \rceil - 1 \leqslant x \leqslant m - 1⌈m/2⌉−1⩽x⩽m−1
- 所有叶子结点都在同一层
- 除根结点以外的所有结点(不包括叶子结点)的度数正好是关键字总数加1,故内部子树个数 k 满足:⌈m/2⌉⩽k⩽m\lceil m/2 \rceil \leqslant k \leqslant m⌈m/2⌉⩽k⩽m
三.B树的各种操作
1.B树的插入
B树的插入操作只能在叶子结点上进行操作,而且叶子结点上关键字的个数要严格满足B树的性质:⌈m/2⌉−1⩽x⩽m−1\lceil m/2 \rceil - 1 \leqslant x \leqslant m - 1⌈m/2⌉−1⩽x⩽m−1
插入步骤如下:
- 寻找合适的叶子结点
- 在叶子结点上找到合适的插入位置
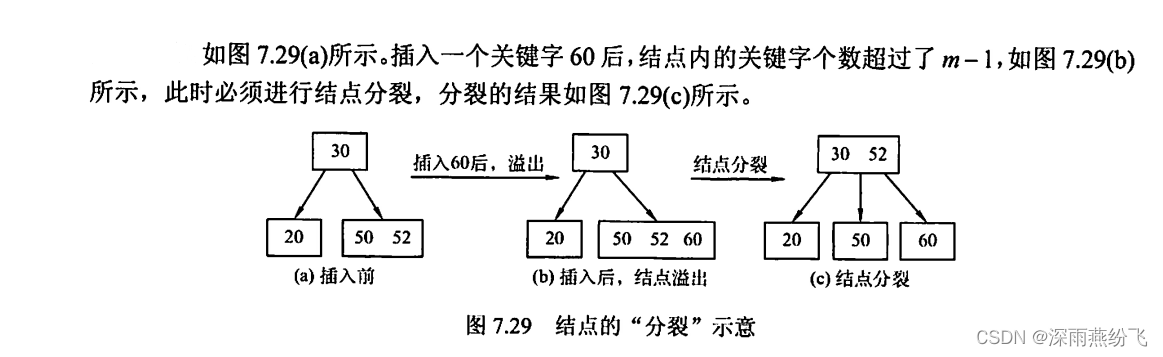
- 插入后判断关键字个数是否超过m-1,如果超过则结点需要分裂,分裂从中间劈开,并将中间的元素插入到当前结点的父亲结点中,判断父亲结点关键字个数是否超过m-1,如果超过继续分裂,重复第3步
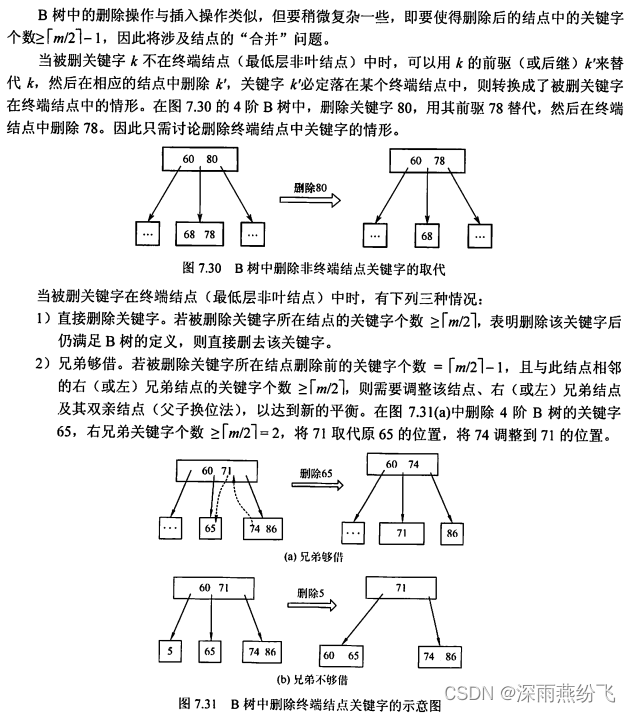
2.B树的删除

四.代码各函数分解实例
1.结点的结构体定义
typedef struct Node
{
int level;//阶数
int keyNum;//关键数的数量
int childNum;//孩子的数量
int *keys;//关键字指针数组
struct Node **children;//孩子数组
struct Node *parent;//父亲指针
}Node;2.初始化结点
Node *initNode(int level)
{/*参数:树的阶数*/
Node *node = (Node*)malloc(sizeof(Node));//申请结点的空间
node->level = level;//将阶数写入
node->keyNum = 0;//关键字个数初始为0
node->childNum = 0;//孩子个数初始为0
/*level+1是为了后面的插入和删除,方便索引*/
node->keys = (int*)malloc(sizeof(int)*(level+1));//结点内关键字指针申请空间
node->children = (Node**)malloc(sizeof(Node*)*level);//孩子指针申请空间
node->parent = NULL;//父结点初始为空
int i;
for(i=0;i<level;i++)
{/*关键字和孩子指针循环遍历都初始化*/
node->keys[i] = 0;
node->children[i] = NULL;
}
node->keys[i] = 0;//关键字指针多一个,因此额外初始化
return node;//指针函数,返回值为指针
}3.找合适的索引方便插入和删除
int findSuiteIndex(Node *node,int data)
{/*参数一:结点指针
参数二:要查找的元素*/
int index;//下标
for(index=1;index<=node->keyNum;index++)
{/*从1开始,向后遍历寻找第一个比该元素大的key,返回该key的下标,就是要插入的位置*/
if(data<node->keys[index])
break;
}
return index;
}4.找合适的叶子结点
Node *findSuiteLeafNode(Node *T,int data)
{/*参数一:根节点指针
参数二:要插入的元素*/
int index;//元素下标
if(T->childNum==0)//结点无孩子说明找到了叶子结点
return T;
else
{
index = findSuiteIndex(T,data);//寻找合适的插入位置
return findSuiteLeafNode(T->children[index-1],data);//递归,往左子树走
}
}5.往结点中插入数据
void addData(Node *node,int data,Node **T)
{/*参数一:结点指针
参数二:要插入的数据
参数三:父结点,由于要改变,因此使用二级指针*/
int index = findSuiteIndex(node,data);
int i,mid;
for(i=node->keyNum;i>=index;i--)
node->keys[i+1] = node->keys[i];
node->keys[index] = data;
node->keyNum += 1;
//判断是否进行分裂
if(node->keyNum==node->level)
{//找到分裂的位置
mid = node->level/2+node->level%2;
//分裂
Node *lchild = initNode(node->level);//初始化左孩子结点
Node *rchild = initNode(node->level);//初始化右孩子结点
//将mid左边的值赋值给左孩子
for(i=1;i<mid;i++)
addData(lchild,node->keys[i],T);
//将mid右边的值赋值给右孩子
for(i=mid+1;i<=node->keyNum;i++)
addData(rchild,node->keys[i],T);
//将原先结点mid左边的孩子赋值给分裂出来的左孩子
for(i=0;i<mid;i++)
{
lchild->children[i] = node->children[i];
if(node->children[i]!=NULL)
{
node->children[i]->parent = lchild;
lchild->childNum++;
}
}
//将原先结点mid右边的孩子赋值给分裂出来的右孩子
int index = 0;
for(i=mid;i<node->childNum;i++)
{
rchild->children[index++] = node->children[i];
if(node->children[i]!=NULL)
{
node->children[i]->parent = rchild;
rchild->childNum++;
}
}
//判断当前结点是不是根结点
if(node->parent==NULL)
{//是根结点
Node *newParent = initNode(node->level);
addData(newParent,node->keys[mid],T);
newParent->children[0] = lchild;
newParent->children[1] = rchild;
newParent->childNum = 2;
lchild->parent = newParent;
rchild->parent = newParent;
*T = newParent;
}
else
{//不是根结点
index = findSuiteIndex(node->parent,node->keys[mid]);
lchild->parent = node->parent;
rchild->parent = node->parent;
node->parent->children[index-1] = lchild;
if(node->parent->children[index]!=NULL)
{
for(i=node->parent->childNum-1;i>=index;i--)
node->parent->children[i+1] = node->parent->children[i];
}
node->parent->children[index] = rchild;
node->parent->childNum++;
addData(node->parent,node->keys[mid],T);
}
}
}6.插入结点
void insert(Node** T, int data)
{/*参数一:父结点
参数二:要插入的数据*/
Node* node = findSuiteLeafNode(*T, data);//先找到适合插入的叶子结点
addData(node, data, T);//执行插入数据函数
}7.遍历输出
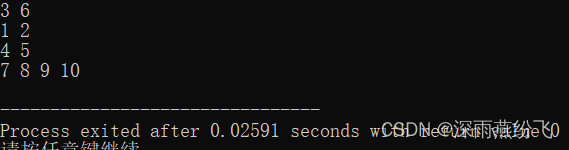
void printTree(Node* T)
{/*参数:根结点*/
int i;
if (T != NULL) {
for (i = 1; i <= T -> keyNum; i++)//按序遍历结点内的关键字
printf("%d ", T -> keys[i]);
printf("\n");
for (i = 0; i < T -> childNum; i++)//按序遍历孩子结点
printTree(T -> children[i]);//递归遍历
}
}8.主函数
int main()
{
int i;
Node *T = initNode(5);//初始化
for(i=1;i<=10;i++)
insert(&T,i);//插入
printTree(T);//遍历打印
return 0;
}完整代码:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node
{
int level;//阶数
int keyNum;//关键数的数量
int childNum;//孩子的数量
int *keys;//关键字指针数组
struct Node **children;//孩子数组
struct Node *parent;//父亲指针
}Node;
/*初始化结点*/
Node *initNode(int level)
{/*参数:树的阶数*/
Node *node = (Node*)malloc(sizeof(Node));//申请结点的空间
node->level = level;//将阶数写入
node->keyNum = 0;//关键字个数初始为0
node->childNum = 0;//孩子个数初始为0
/*level+1是为了后面的插入和删除,方便索引*/
node->keys = (int*)malloc(sizeof(int)*(level+1));//结点内关键字指针申请空间
node->children = (Node**)malloc(sizeof(Node*)*level);//孩子指针申请空间
node->parent = NULL;//父结点初始为空
int i;
for(i=0;i<level;i++)
{/*关键字和孩子指针循环遍历都初始化*/
node->keys[i] = 0;
node->children[i] = NULL;
}
node->keys[i] = 0;//关键字指针多一个,因此额外初始化
return node;//指针函数,返回值为指针
}
/*找合适的索引方便插入和删除*/
int findSuiteIndex(Node *node,int data)
{/*参数一:结点指针
参数二:要查找的元素*/
int index;//下标
for(index=1;index<=node->keyNum;index++)
{/*从1开始,向后遍历寻找第一个比该元素大的key,返回该key的下标,就是要插入的位置*/
if(data<node->keys[index])
break;
}
return index;
}
/*找合适的叶子结点*/
Node *findSuiteLeafNode(Node *T,int data)
{/*参数一:根节点指针
参数二:要插入的元素*/
int index;//元素下标
if(T->childNum==0)//结点无孩子说明找到了叶子结点
return T;
else
{
index = findSuiteIndex(T,data);//寻找合适的插入位置
return findSuiteLeafNode(T->children[index-1],data);//递归,往左子树走
}
}
/*往结点中插入数据*/
void addData(Node *node,int data,Node **T)
{/*参数一:结点指针
参数二:要插入的数据
参数三:父结点,由于要改变,因此使用二级指针*/
int index = findSuiteIndex(node,data);
int i,mid;
for(i=node->keyNum;i>=index;i--)
node->keys[i+1] = node->keys[i];
node->keys[index] = data;
node->keyNum += 1;
//判断是否进行分裂
if(node->keyNum==node->level)
{//找到分裂的位置
mid = node->level/2+node->level%2;
//分裂
Node *lchild = initNode(node->level);//初始化左孩子结点
Node *rchild = initNode(node->level);//初始化右孩子结点
//将mid左边的值赋值给左孩子
for(i=1;i<mid;i++)
addData(lchild,node->keys[i],T);
//将mid右边的值赋值给右孩子
for(i=mid+1;i<=node->keyNum;i++)
addData(rchild,node->keys[i],T);
//将原先结点mid左边的孩子赋值给分裂出来的左孩子
for(i=0;i<mid;i++)
{
lchild->children[i] = node->children[i];
if(node->children[i]!=NULL)
{
node->children[i]->parent = lchild;
lchild->childNum++;
}
}
//将原先结点mid右边的孩子赋值给分裂出来的右孩子
int index = 0;
for(i=mid;i<node->childNum;i++)
{
rchild->children[index++] = node->children[i];
if(node->children[i]!=NULL)
{
node->children[i]->parent = rchild;
rchild->childNum++;
}
}
//判断当前结点是不是根结点
if(node->parent==NULL)
{//是根结点
Node *newParent = initNode(node->level);
addData(newParent,node->keys[mid],T);
newParent->children[0] = lchild;
newParent->children[1] = rchild;
newParent->childNum = 2;
lchild->parent = newParent;
rchild->parent = newParent;
*T = newParent;
}
else
{//不是根结点
index = findSuiteIndex(node->parent,node->keys[mid]);
lchild->parent = node->parent;
rchild->parent = node->parent;
node->parent->children[index-1] = lchild;
if(node->parent->children[index]!=NULL)
{
for(i=node->parent->childNum-1;i>=index;i--)
node->parent->children[i+1] = node->parent->children[i];
}
node->parent->children[index] = rchild;
node->parent->childNum++;
addData(node->parent,node->keys[mid],T);
}
}
}
/*插入结点*/
void insert(Node** T, int data)
{/*参数一:父结点
参数二:要插入的数据*/
Node* node = findSuiteLeafNode(*T, data);//先找到适合插入的叶子结点
addData(node, data, T);//执行插入数据函数
}
/*遍历输出*/
void printTree(Node* T)
{/*参数:根结点*/
int i;
if (T != NULL) {
for (i = 1; i <= T -> keyNum; i++)//按序遍历结点内的关键字
printf("%d ", T -> keys[i]);
printf("\n");
for (i = 0; i < T -> childNum; i++)//按序遍历孩子结点
printTree(T -> children[i]);//递归遍历
}
}
int main()
{
int i;
Node *T = initNode(5);//初始化
for(i=1;i<=10;i++)
insert(&T,i);//插入
printTree(T);//遍历打印
return 0;
}运行结果: