一、说明
DeepSeek R1+蒸馏模型组是基于DeepSeek-R1模型体系,通过知识蒸馏技术优化形成的系列模型,旨在平衡性能与效率。
1、技术路径与核心能力
基础架构与训练方法
- DeepSeek-R1-Zero:通过强化学习(RL)训练,未使用监督微调(SFT),具备初步推理能力5。
- DeepSeek-R1:融合冷启动数据,采用多阶段SFT与RL交替训练,显著提升复杂任务(如科学预测、实验设计)的准确性15。
- 蒸馏模型:以DeepSeek-R1为教师模型,生成推理数据并蒸馏至小规模学生模型(如Qwen系列),降低计算资源需求35。
关键优化能力
- 思维链蒸馏:通过自然语言交互生成思维链数据集,提升模型在分子预测、材料设计等科学领域的逻辑推理能力17。
- 高效推理:蒸馏后的小模型(如1.5B、7B版本)在数学问题、代码生成等场景中,性能接近大模型但运行速度更快67。
2、模型版本与开源生态
主流蒸馏模型版本
- 参数规模覆盖1.5B至70B,包括DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B/70B,适配不同算力需求。
- 官方验证显示,32B与70B模型性能对标OpenAI o1-mini,但训练成本仅为十分之一。
开源支持与工具链
- Open-R1项目:提供单卡(如RTX 4090)蒸馏复现方案,支持从数据生成到模型合并的全流程。
- 第三方平台集成:如百度智能云千帆ModelBuilder,支持3小时内完成模型蒸馏,降低开发者门槛。
3、应用场景与实践效果
科学计算与工业设计
- 通过API调用实现科学术语增强、实验方案优化,提升材料预测与分子设计的准确性1。
- 典型案例:中国移动研究院AI4S工作站已部署满血版DeepSeek-R1,支持科研团队进行模型蒸馏1。
教育与竞赛场景
- 数学问题解答场景中,蒸馏模型通过逻辑链数据训练,输出准确性接近教师模型。
- 开源社区中,开发者可基于OrangePi AI Studio等设备部署蒸馏模型,实现低成本AI推理。
4、训练与部署建议
硬件与工具配置
- 单卡训练推荐:NVIDIA TESLA T4 16G或RTX 4090,搭配CUDA 12.4、PyTorch 2.6.0等环境。
- 工具链:HuggingFace Transformers、Weights & Biases(实验跟踪)、Unsloth(加速训练)。
微调注意事项
- 部分实践表明,直接微调蒸馏后的小模型(如Qwen-7B)可能效果有限,建议优先复用官方蒸馏数据集。
- 训练过程需监控损失函数变化,并通过WandB等工具可视化调优。
五、总结
DeepSeek R1+蒸馏模型组通过“大模型生成-小模型学习”路径,实现了高性能与低成本的平衡。其在科学计算、教育等领域的应用已验证其潜力,而开源生态与工具链支持进一步降低了开发者使用门槛。未来,随着蒸馏技术的持续优化,轻量级模型的实际效能有望进一步逼近原版
二、 本文硬件配置
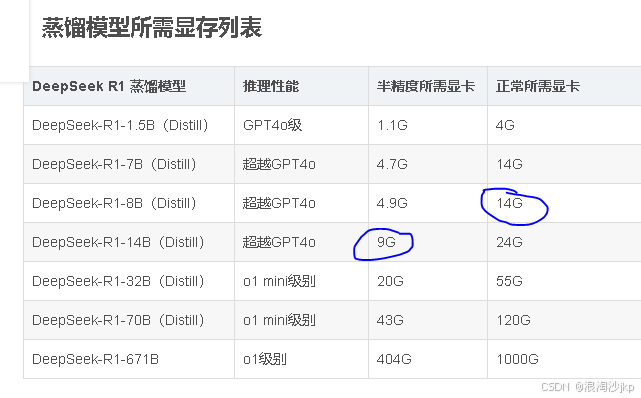
1、蒸馏模型所需显存列表
| DeepSeek R1 蒸馏模型 | 推理性能 | 半精度所需显卡 | 正常所需显卡 |
|---|---|---|---|
| DeepSeek-R1-1.5B(Distill) | GPT4o级 | 1.1G | 4G |
| DeepSeek-R1-7B(Distill) | 超越GPT4o | 4.7G | 14G |
| DeepSeek-R1-8B(Distill) | 超越GPT4o | 4.9G | 14G |
| DeepSeek-R1-14B(Distill) | 超越GPT4o | 9G | 24G |
| DeepSeek-R1-32B(Distill) | o1 mini级别 | 20G | 55G |
| DeepSeek-R1-70B(Distill) | o1 mini级别 | 43G | 120G |
| DeepSeek-R1-671B | o1级别 | 404G | 1000G |
2、部署硬件
Cloud Studio![]() https://ide.cloud.tencent.com/dashboard/gpu-workspace
https://ide.cloud.tencent.com/dashboard/gpu-workspace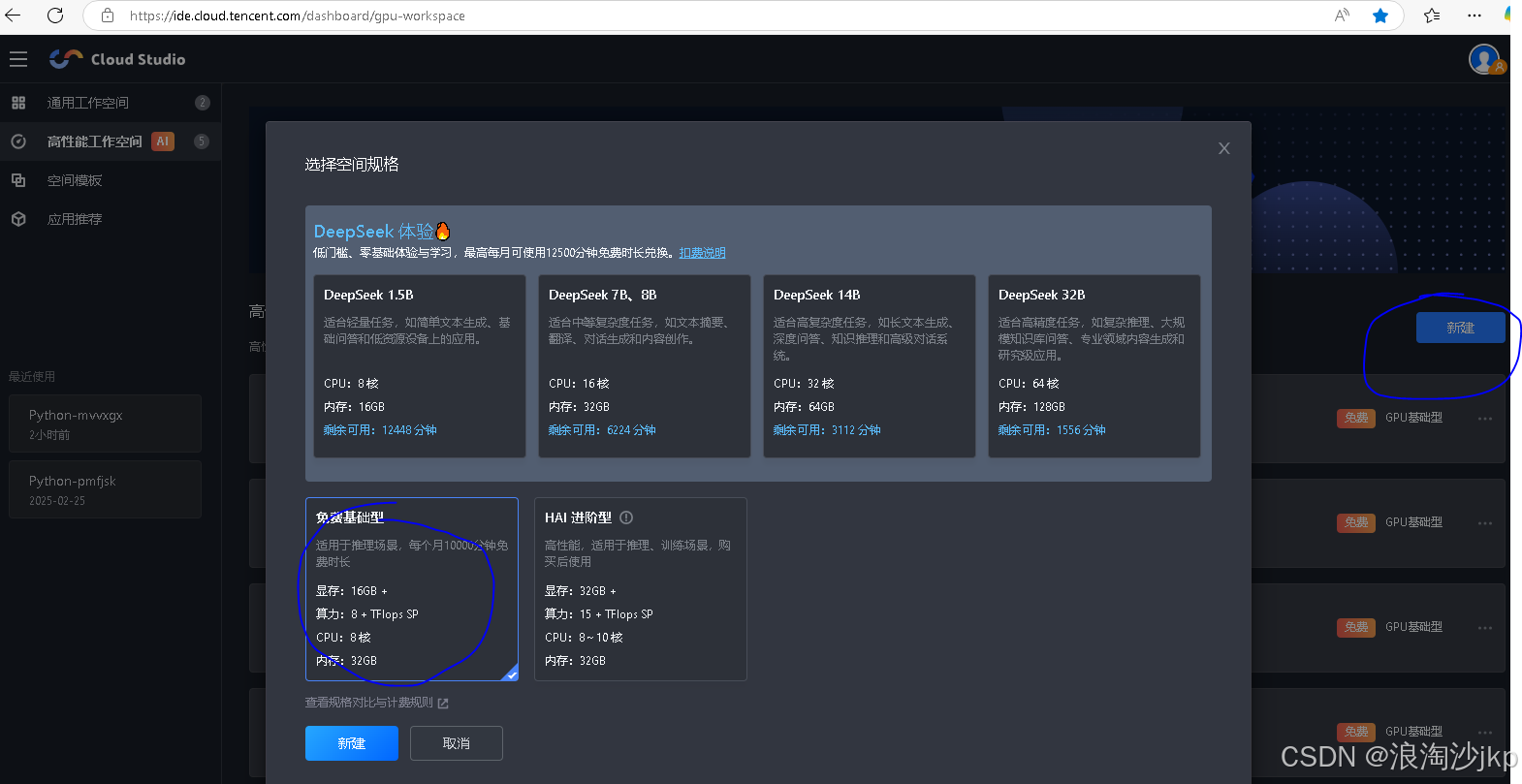

要看时候,现在用的人多,有时候没有资源,有时候进不去,不要钱就这么回事,不过开始用的还是爽,创建会要几分钟 ,我们就选这个,有16g显存

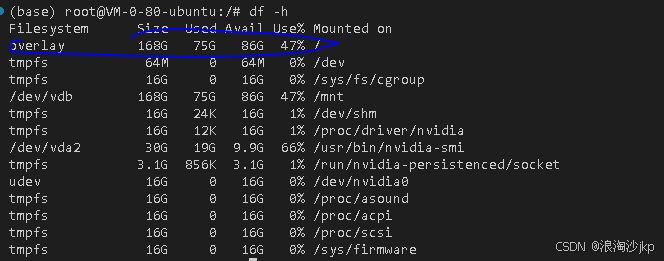
其实系统已经有了模型,但是我们是自己装喔
(base) root@VM-0-80-ubuntu:/# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 7 weeks ago
deepseek-r1:32b 38056bbcbb2d 19 GB 7 weeks ago
deepseek-r1:8b 28f8fd6cdc67 4.9 GB 7 weeks ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 2 months ago
deepseek-r1:7b 0a8c26691023 4.7 GB 2 months ago
我们的选择,可以选两种,我们看情况选择,基本确定使用14b
三、软件环境配置与实施
1、创建虚拟环境
conda create --name R1 python=3.10
conda init
source ~/.bashrc
conda activate R12、创建项目主目录
cd /workspace
mkdir -p R1-Distill
cd R1-Distill3、编辑&安装requirements.txt
torch==2.4.1
triton==3.0.0
transformers==4.46.3
safetensors==0.4.5
accelerate>=0.26.0pip install -r requirements.txt4、下载项目权重
DeepSeek-R1-Distill-Qwen-14B · 模型库![]() https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B/files
https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B/files
pip install modelscope
mkdir -p DeepSeek-R1-14B
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --local_dir ./DeepSeek-R1-14B(R1) root@VM-0-80-ubuntu:/workspace/R1-Distill# cd DeepSeek-R1-14B/
(R1) root@VM-0-80-ubuntu:/workspace/R1-Distill/DeepSeek-R1-14B# ls
LICENSE configuration.json model-00001-of-000004.safetensors model-00004-of-000004.safetensors tokenizer_config.json
README.md figures model-00002-of-000004.safetensors model.safetensors.index.json
config.json generation_config.json model-00003-of-000004.safetensors tokenizer.json
5、编写python程序
/workspace/R1-Distill/runDeepSeek.py
runDeepSeek.py
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
import time
start_time = time.time() # 获取当前时间
# 要测量运行时间的代码段
# ...
# 输入模型下载地址
model_name = "/workspace/R1-Distill/DeepSeek-R1-14B"
# 实例化预训练模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
# torch_dtype=torch.float16, #半精度
torch_dtype="auto", #全精度
device_map="auto",
low_cpu_mem_usage=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 创建消息
prompt = "你好,好久不见,请介绍下你自己!"
messages = [{"role":"system","content":"孙悟空是谁的儿子。"},
{"role":"user","content":prompt}
]
# 分词
text = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 创建回复
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
end_time = time.time() # 获取结束时间
runtime = end_time - start_time # 计算运行时间
print("代码运行时间为:", runtime, "秒")
代码中为下面全精度,所以安装我们前面的配置
-
全精度训练
# 实例化预训练模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
# torch_dtype=torch.float16, #半精度
torch_dtype="auto", #全精度
device_map="auto",
low_cpu_mem_usage=True
)
(base) root@VM-0-80-ubuntu:/workspace# nvidia-smi
Thu Apr 3 13:17:51 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | Off |
| N/A 39C P0 26W / 70W | 12867MiB / 16384MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
(R1) root@VM-0-80-ubuntu:/workspace/R1-Distill# python runDeepSeek.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████| 4/4 [01:29<00:00, 22.39s/it]
Some parameters are on the meta device because they were offloaded to the cpu.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
嗯,用户问“孙悟空是谁的儿子。”,我得先回忆一下相关的故事。孙悟空是中国四大名著之一《西游记》里的角色,他通常被认为是石猴出生的,没有父母,所以严格来说他没有父亲或母亲。不过,有些民间传说或地方戏曲可能会提到他有父母,但这些不是官方的正统说法。接着,用户又问“你好,好久不见,请介绍下你自己!”,这看起来像是用户想和我互动,可能是在测试我或者只是闲聊。我应该礼貌地回应,同时保持专业,提供必要的帮助。
所以,我需要先回答第一个问题,说明孙悟空没有父母,然后回应用户的问候,介绍自己。要确保语气友好,信息准确。
</think>孙悟空是中国古典小说《西游记》中的主要角色之一,他通常被描述为从一块仙石中诞生的石猴,没有父母。因此,严格来说,孙悟空并没有父亲或母亲。然而,在一些民间传说或地方戏曲中,有时会提到孙悟空有父母,但这并不是《西游记》正统故事中的内容。
至于你提到的“你好,好久不见,请介绍下你自己!”,我是一个人工智能助手,由中国的深度求索(DeepSeek)公司开发,旨在帮助用户解答问题、提供信息和进行各种对话。有什么我可以帮助你的吗?
代码运行时间为: 1394.4433524608612 秒
-
半精度训练
# 实例化预训练模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, #半精度
#torch_dtype="auto", #全精度
device_map="auto",
low_cpu_mem_usage=True
)
(base) root@VM-0-80-ubuntu:/workspace# nvidia-smi
Thu Apr 3 13:52:31 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | Off |
| N/A 46C P0 34W / 70W | 14229MiB / 16384MiB | 39% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
用的显存比全精度还大一些 ,只能说明auto 自动选择的不是全精度,后面又变为下图,所以估计自动选择也是半精度
(base) root@VM-0-80-ubuntu:/workspace# nvidia-smi
Thu Apr 3 14:10:16 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | Off |
| N/A 49C P0 37W / 70W | 12849MiB / 16384MiB | 39% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
(R1) root@VM-0-80-ubuntu:/workspace/R1-Distill# python runDeepSeek.py
Loading checkpoint shards: 25%|██████████████████████ | 1/4 [00:55<02Loading checkpoint shards: 50%|████████████████████████████████████████████ | 2/4 [01:50<01Loading checkpoint shards: 75%|██████████████████████████████████████████████████████████████████ | 3/4 [02:54<00Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████| 4/4 [03:21<00Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████| 4/4 [03:21<00:00, 50.34s/it]
Some parameters are on the meta device because they were offloaded to the cpu.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
嗯,用户问我孙悟空是谁的儿子,我得好好想想怎么回答这个问题。首先,孙悟空是中国神话里的著名人物,来自《西游记》。他通常被认为是石猴出生,没有父母,所以严格来说,他没有父亲或母亲。不过,有时候民间传说会给他加上一些父母,比如石头里的仙人或者天地父母,但这些都不是官方的说法。接下来,我需要确认用户的问题背景。用户之前提到“你好,好久不见,请介绍下你自己!”,看起来可能是在闲聊或者测试我的知识。所以,我应该用简单明了的语言回答,同时保持友好和乐于助人的态度。
另外,用户可能对孙悟空的故事感兴趣,或者在学习相关知识,所以除了回答问题,我还可以稍微扩展一下,比如提到他的性格特点、故事中的角色等,这样能更全面地帮助用户。
最后,确保回答准确,同时避免使用过于正式的语言,保持自然流畅。这样用户会觉得亲切,也更容易理解信息。
</think>孙悟空是中国古典小说《西游记》中的主要角色之一,通常被认为是石猴出生,没有父母,因此严格来说他没有父亲或母亲。不过,根据一些民间传说和神话故事,有时会提到他是从石头中诞生的,因此有些人会说他是“石头的儿子”或“天地的子女”。这些说法更多是象征性的,表示他非凡的来历和强大的能力。
代码运行时间为: 1415.5809762477875 秒
四、保存历史进行多轮对话
1、编写代码
参考上一章节进行
/workspace/R1-Distill/runDeepSeek-history.py
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
# 输入模型下载地址
model_name = "/workspace/R1-Distill/DeepSeek-R1-14B"
# 实例化预训练模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, #半精度
# torch_dtype="auto", #全精度
device_map="auto",
low_cpu_mem_usage=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
messages = [{"role":"system","content":"You are a helpful assistant."}
# {"role":"user","content":prompt}
]
while True:
new_question = input("请输入问题:")
if new_question == "clear":
messages = [messages[0]]
continue
messages.append({"role":"user","content":new_question})
text = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 创建回复
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
messages.append({"role": "system", "content": response})
在这里执行这个函数之后,会在命令行里输出
请输入你的问题:,然后我们可以输入我们的问题,之后可以连续多轮输出,后台会记住我们之前的对话,从而实现多轮对话的功能
1) root@VM-0-80-ubuntu:/workspace/R1-Distill# python runDeepSeek-history.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████| 4/4 [03:21<00:00, 50.28s/it]
Some parameters are on the meta device because they were offloaded to the cpu.
请输入问题:孙悟空是谁的儿子
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
嗯,用户问的是“孙悟空是谁的儿子”,这让我有点困惑。因为通常我们说孙悟空是齐天大圣,是中国神话里的角色,不是人类的儿子。可能用户想问的是孙悟空的父母是谁,或者他有什么样的家庭背景。首先,我需要回忆一下《西游记》中的相关内容。孙悟空的父母是谁呢?根据小说,孙悟空是从一块石头里蹦出来的,没有父母。这块石头吸收天地灵气,日月精华,最终孕育了他。所以严格来说,孙悟空没有生物学上的父母。
不过,有时候人们会提到他的“养父”或者“义父”。比如,有些民间传说中,孙悟空可能被山中的神仙或者动物收养过,但这些说法并不正式,更多是民间的演绎。
另外,考虑到用户可能对孙悟空的家庭关系有误解,可能需要解释清楚他是从石头里出生的,而不是传统意义上的儿子。这样用户就能更好地理解孙悟空的起源。
总的来说,用户的问题可能源于对孙悟空身世的好奇,或者对“儿子”一词的理解有偏差。所以,回答时要明确说明孙悟空没有父母,而是从石头中诞生的,同时可以提及相关的神话背景,以满足用户的好奇心。
</think>孙悟空是中国神话《西游记》中的重要角色,他通常被描述为从一块仙石中孕育而出,而不是传统意义上的“儿子”。因此,严格来说,孙悟空并没有生物学上的父母。然而,有些民间传说或解读可能会提到他有“养父”或“义父”,但这些并不是官方正统的说法。
在《西游记》中,孙悟空是从一块名为“仙石”的石头中诞生的,这块石头吸收了天地灵气和日月精华,最终孕育了他。因此,孙悟空的身世可以被视为一种神话象征,而不是有血缘关系的儿子。
如果你有其他关于孙悟空的问题,欢迎继续提问!
请输入问题: 难道真的能从石头里出来
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.嗯,用户问的是“孙悟空是谁的儿子”,这让我有点困惑。因为通常我们说孙悟空是齐天大圣,是中国神话里的角色,不是人类的儿子。可能用户想问的是孙悟空的父母是谁,或者他有什么样的家庭背景。
首先,我需要回忆一下《西游记》中的相关内容。孙悟空的父母是谁呢?根据小说,孙悟空是从一块石头里蹦出来的,没有父母。这块石头吸收天地灵气,日月精华,最终孕育了他。所以严格来说,孙悟空没有生物学上的父母。
不过,有时候人们会提到他的“养父”或者“义父”。比如,有些民间传说中,孙悟空可能被山中的神仙或者动物收养过,但这些说法并不正式,更多是民间的演绎。
另外,考虑到用户可能对孙悟空的家庭关系有误解,可能需要解释清楚他是从石头里出生的,而不是传统意义上的儿子。这样用户就能更好地理解孙悟空的起源。
总的来说,用户的问题可能源于对孙悟空身世的好奇,或者对“儿子”一词的理解有偏差。所以,回答时要明确说明孙悟空没有父母,而是从石头中诞生的,同时可以提及相关的神话背景,以满足用户的好奇心。
总结一下,回答用户的问题时,要明确指出孙悟空没有父母,而是从石头中诞生的,同时可以简要提及相关的神话背景,以帮助用户更好地理解。
</think>孙悟空是中国神话《西游记》中的重要角色,他通常被描述为从一块仙石中孕育而出,而不是传统意义上的“儿子”。因此,严格来说,孙悟空并没有生物学上的父母。然而,有些民间传说或解读可能会提到他有“养父”或“义父”,但这些并不是官方正统的说法。
在《西游记》中,孙悟空是从一块名为“仙石”的石头中诞生的,这块石头吸收了天地灵气和日月精华,最终孕育了他。因此,孙悟空的身世可以被视为一种神话象征,而不是有血缘关系的儿子。
如果你有其他关于孙悟空的问题,欢迎继续提问!
关于ollama 调用deepseek 蒸馏版,看下一篇