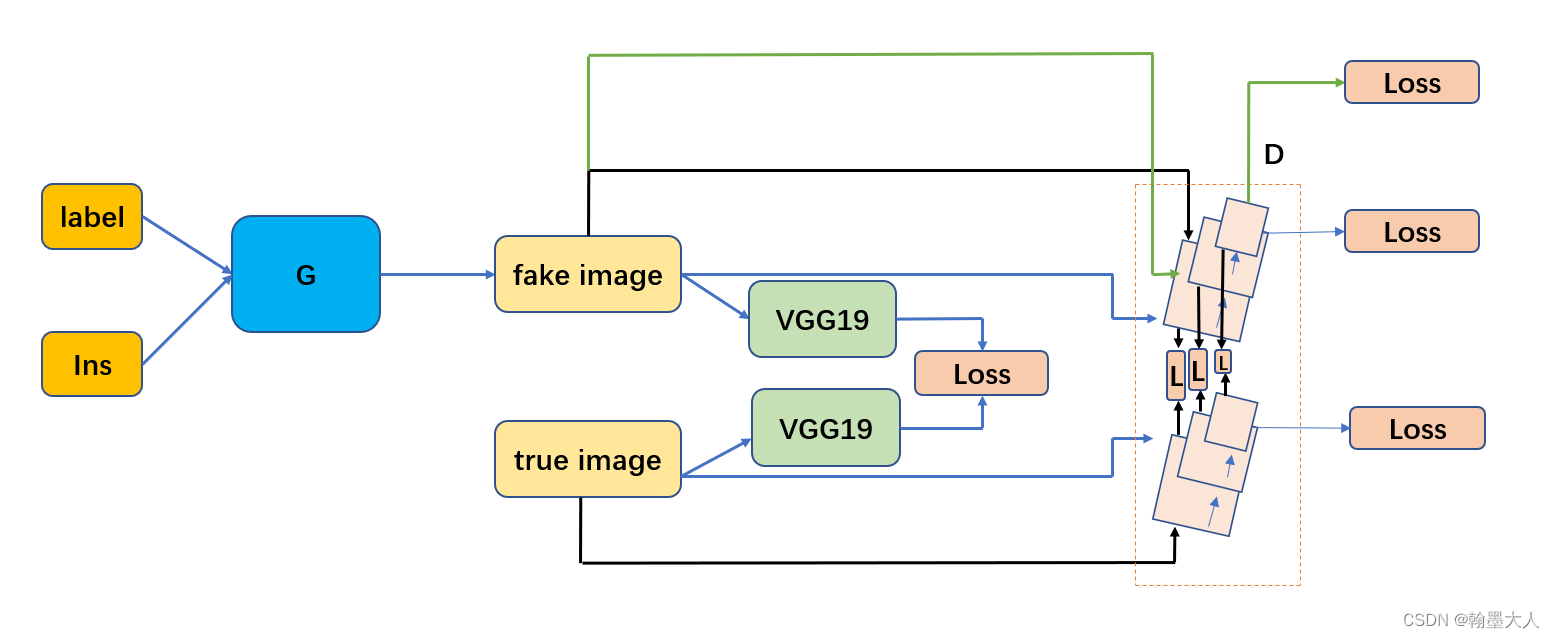
概 述
在服务端系统服务开发中,缓存是一种常用的技术,它可以提高系统对请求的处理效率,而redis又是缓存技术栈中的一个佼佼者,广泛的应用于各种服务系统中。在大型互联网服务中,每天需要处理的请求和存储的缓存数据都是海量的,在这些大型系统中,使用单实例的redis,很难满足系统超高的并发请求以及海量数据缓存需求。大型的互联网服务中对于redis的使用,往往采用集群架构,通过横向扩展redis实例规模的方式,以较低的成本,来提升缓存系统对数据请求的处理效率和数据存储容量。
redis集群架构虽然有众多优点,但是事物往往都是有双面性的,在解决某些场景下的问题后,又会在另外的场景下有带来问题。当然redis集群模式,也是符合这个规律的。redis集群模式下,会增加运维的复杂度,限制了redis中某些命令的使用(范围查询,事务操作的使用等),除了这些常见的问题外,数据倾斜问题,是redis集群模式下一个比较隐蔽的问题,只有在一些特殊的场景下才会出现,但是该问题带来的影响确实巨大的。
示 例
2019年春节抽奖服务,业务评估峰值qps是2w,转化到redis集群为10w qps和5GB内存存储,部署5个分片每个分片1GB+2W qps的redis集群(包含预留容量)。结果活动开始时,才发现服务存在”热点key",请求严重倾斜, 峰值时的6w qps都集中到其中一个分片,导致这分片过载,整个抽奖服务雪崩。
什么是数据倾斜
在redis集群模式下,数据会按照一定的分布规则分散到不同的实例上。如果由于业务数据特殊性,按照指定的分布规则,可能导致不同的实例上数据分布不均匀,如以下场景:有些切片实例上数据分布量较大,有些实例上数据分布量较少;有些实例上保存了热点数据,数据访问量较大,有些实例上保存数据相对较"冷",几乎没有访问量。那么存储数据量大的实例,或者保存热点数据的实例,资源利用率会比较高,负载压力较大,导致其对数据请求响应变慢。此时就产生了数据倾斜。

有哪几种数据倾斜
redis分布式集群倾斜问题,主要分为两类:
1、数据存储容量倾斜,数据存储总是落到集群中少数节点;
2、qps请求倾斜,qps总是落到少数节点。
redis集群出现倾斜的影响
倾斜问题对于redis这类纯内存和单线程服务影响较大,存在以下痛点:
-
qps集中到少数redis节点,引起少数节点过载,会拖垮整个服务,同时集群处理qps能力不具备可扩展性;
-
数据容量倾斜,导致少数节点内存爆增,出现OOM Killer和集群存储容量不具备可扩展性;
-
运维管理变复杂,类似监控告警内存使用量、QPS、连接数、redis cpu busy等值不便统一;
-
因集群内其他节点资源不能被充分利用,导致redis服务器/容器资源利率低;
-
增大自动化配置管理难度;单集群节点尽量统一参数配置;
分析完影响,那我们再看生产环境中,导致Redis集群严重“倾斜”的常见原因。
导致Redis集群倾斜的常见原因
一般是系统设计时,键空间(keyspace)设计不合理:
-
系统设计时,redis键空间(keyspace)设计不合理,出现”热点key",导致这类key所在节点qps过载,集群出现qps倾斜;
-
系统存在大的集合key(hash,set,list等),导致大key所在节点的容量和QPS过载,集群出现qps和容量倾斜;
-
DBA在规划集群或扩容不当,导致数据槽(slot)数分配不均匀,导致容量和请求qps倾斜;
-
系统大量使用Keys hash tags, 可能导致某些数据槽位的key数量多,集群集群出现qps和容量倾斜;
-
工程师执行monitor这类命令,导致当前节点client输出缓冲区增大;used_memory_rss被撑大;导致节点内存容量增大,出现容量倾斜;
接下来,当集群出现内存容量、键数量或QPS请求量严重倾斜时,我们应该排查定位问题呢?
Redis集群倾斜问题的排查方式
排查节点热点key,确定top commands.
当集群因热点key导致集群qps倾斜,需快速定位热点key和top commands。可使用开源工具redis-faina,或有实时redis分析平台更好。
以下是使用redis-faina工具分析,可见两个前缀key的QPS占比基本各为50%, 明显热点key;也能看到auth命令的异常(top commands)。
Overall Stats
========================================
Lines Processed 100000
Commands/Sec 7276.82
Top Prefixes
========================================
ar_xxx 49849 (49.85%)
Top Keys
========================================
c8a87fxxxxx 49943 (49.94%)
a_r:xxxx 49849 (49.85%)
Top Commands
========================================
GET 49964 (49.96%)
AUTH 49943 (49.94%)
SELECT 88 (0.09%)
系统是否使用较大的集合键
系统使用大key导致集群节点容量或qps倾斜,比如一个5kw字段的hash key, 内存占用在近10GB,这个key所在slot的节点的内存容量或qps都很有可能倾斜。
这类集合key每次操作几个字段,很难从proxy或sdk发现key的大小。
可使用redis-cli --bigkeys 分析节点存在的大键。如果需全量分析,可使用redis-rdb-tools(https://github.com/sripathikrishnan/redis-rdb-tools) 对节点的RDB文件全量分析,通过结果size_in_bytes列得到大key的占用内存字节数。
示例使用redis-cli 进行抽样分析:
redis-cli --bigkeys -p 7000
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far 'key:000000019996' with 1024 bytes
[48.57%] Biggest list found so far 'mylist' with 534196 items
-------- summary -------
Sampled 8265 keys in the keyspace!
Total key length in bytes is 132234 (avg len 16.00)
Biggest string found 'key:000000019996' has 1024 bytes
Biggest list found 'mylist' has 534196 items
8264 strings with 8460296 bytes (99.99% of keys, avg size 1023.75)
1 lists with 534196 items (00.01% of keys, avg size 534196.00)
检查集群每个分片的数据槽分配是否均匀
下面以Redis Cluster集群为例确认集群中,每个节点负责的数据槽位(slots)和key个数。下面demo的部分实例存在不轻度“倾斜”但不严重,可考虑进行reblance.
redis-trib.rb info redis_ip:port
nodeip:port (5e59101a...) -> 44357924 keys | 617 slots | 1 slaves.
nodeip:port (72f686aa...) -> 52257829 keys | 726 slots | 1 slaves.
nodeip:port (d1e4ac02...) -> 45137046 keys | 627 slots | 1 slaves.
---------------------省略------------------------
nodeip:port (f87076c1...) -> 44433892 keys | 617 slots | 1 slaves.
nodeip:port (a7801b06...) -> 44418216 keys | 619 slots | 1 slaves.
nodeip:port (400bbd47...) -> 45318509 keys | 614 slots | 1 slaves.
nodeip:port (c90a36c9...) -> 44417794 keys | 617 slots | 1 slaves.
[OK] 1186817927 keys in 25 masters.
72437.62 keys per slot on average.
系统是否大量使用keys hash tags
在redis集群中,有些业务为达到多键的操作,会使用hash tags把某类key分配同一个分片,可能导致数据、qps都不均匀的问题。可使用scan扫描keyspace是否有使用hash tags的,或使用monitor,vc-redis-sniffer工具分析倾斜节点,是否大理包含有hash tag的key。
是否因为client output buffer异常,导致内存容量倾斜
确认是否有client出现output buffer使用量异常,引起内存过大的问题;比如执行monitor、keys命令或slave同步full sync时出现客户端输入缓冲区占用过大。
这类情况基本redis实例内存会快速增长,很快会出现回落。通过监测client输出缓冲区使用情况;分析见下面示例:
# 通过监控client_longest_output_list输出列表的长度,是否有client使用大量的输出缓冲区.
redis-cli -p 7000 info clients
# Clients
connected_clients:52
client_longest_output_list:9179
client_biggest_input_buf:0
blocked_clients:0
# 查看输出缓冲区列表长度不为0的client。 可见monitor占用输出缓冲区370MB
redis-cli -p 7000 client list | grep -v "oll=0"
id=1840 addr=xx64598 age=75 idle=0 flags=O obl=0 oll=15234 omem=374930608 cmd=monitor
如何有效避免Redis集群倾斜问题
-
系统设计redis集群键空间和query pattern时,应避免出现热点key, 如果有热点key逻辑,尽量打散分布不同的节点或添加程序本地缓存;
-
系统设计redis集群键空间时,应避免使用大key,把key设计拆分打散;大key除了倾斜问题,对集群稳定性有严重影响;
-
redis集群部署和扩缩容处理,保证数据槽位分配平均;
-
系统设计角度应避免使用keys hash tag;
-
日常运维和系统中应避免直接使用keys,monitor等命令,导致输出缓冲区堆积;这类命令建议作rename处理;
-
合量配置normal的client output buffer, 建议设置10mb,slave限制为1GB按需要临时调整(警示:和业务确认调整再修改,避免业务出错)
在实际生产业务场景中,大规模集群很难做到集群的完全均衡,只是尽量保证不出现严重倾斜问题。