如果对内存寻址熟悉的话, 或者认真看过上一节的内容: 内存管理之内存寻址: https://blog.csdn.net/qq_40482358/article/details/130868188. 那么对linux系统中的进程管理应该已经有一个初步的认识了: cr3作为一个控制寄存器, 描述当前进程的页目录的物理内存基地址, 当进程切换时, 将cr3中的值置为当前进程中的基地址, 即可完成一次进程切换.(这是我们在内存寻址中初步分析的).
接下来,我们从进程控制块(PCB)的视角来重新看一下进程管理。
1. 进程概述
1.1 从程序到进程
一个程序经过gcc编译器将其编译成汇编程序,经过汇编器gas将其会变成目标代码,经过连接器Id形成可执行文件a.out,最后交给操作系统来执行。
一个操作系统中可执行的程序千变万化,操作系统如何管理这些程序呢?
一个程序一旦被执行, 该程序就变成了进程. 在OS看来, 每个进程是没有多大差异性的, 都被封装在一个可执行文件格式中, 通过top命令可以感知系统中个进程的动态变化
1.2 进程的家族关系
进程是一个动态的实体, 具有生命周期, 系统中进程的生生死死随时发生, 就像个人相对于人类社会这个系统一样.
一个进程不会平白无故的诞生, 它总有自己的父母, 在Linux中, 一个进程通过调用fork系统调用来创建一个新的进程, 新的进程同样能执行fork, 所以, 可以形成一颗完整的进程树. 通过ps -e jH命令可以查看自己机器上的进程树.
1.3 进程控制块(process control blaock)
Linux内核中把对进程的描述结构叫做task_struct, 该描述可以在sched.h中看到(在代码段中定义一个struct task_struct结构体, 点进去就能跳转到定义了)
该结构是内核中最为复杂的结构之一了(甚至可以说是没有之一), 该结构体的内容实在是太多了(光引用的头文件都有50多个, 每个还都是linux的核心头文件), 所以我们很难在一节中就将它解释清楚(仅仅结构体中声明的方法和变量, 不做实现, 就有500多行的), 这里只先对它们粗略的了解, 至于细节, 之后用到了再谈吧.
只看重点的话, 它描述了
- 状态信息, 用于描述进程的状态(就绪, 等待, 执行, 睡眠)
- 链接信息, 用于描述简称的父子关系
- 各种标识符, 通过简单数字对进程进行标识
- 进程通信信息, 描述多个进程在同一个任务上的协作工作
- 时间和定时器信息, 描述进程的生命周期, CPU时间统计等信息
- 调度信息, 用于描述进程的优先级, 调度策略等信息
- 文件系统信息, 用于描述进程使用文件情况的信息
- 虚拟内存信息, 用于描述每个进程拥有的虚拟地址空间
- 处理器环境信息, 用于描述进程的执行环境(寄存器, 堆栈等信息)
- …
2. 进程的重要内容
我们都知道这样一句话:进程是系统资源分配的基本单位,线程是独立运行的最小单位。
但真的对其涵义了解吗?进程有那些资源?如何体现?线程如何独立运行?这些在内核中是如何表示的?
2.1 线程的创建
实际上,linux内核对进程和线程一视同仁。他们的都是通过do_fork()函数创建的,参数的不同导致其功能的不同。
Linux下创建新进程是由父进程来完成的,创建完的新进程就是子进程。Linux用户态创建进程主要有两种:
- 通过<unistd.h>库下的fork()函数:子进程复制父进程的PCB,二者之间代码共享,数据独有,拥有各自的进程虚拟空间
- 通过<unistd.h>库下的vfork()函数:子进程和父进程共享地址空间,修改变量会同时影响。
linux内核中自带的源码只有定义文件,没有实现细节,因此可以去官网上下载对应版本的源码包来查看(下载和查看的方法本文不细讲了,大概思路就是从这里下载3.10.0的源码,然后解压用vscode打开,通过文件和函数查找ctrl+shift+f查找对应的函数或者文件,或者结合一下chatgpt搜索)。
稍微花了点时间:在kernel/fork.c中定义了对应系统调用的宏和真正的实现方法do_fork()
共提供了两个系统调用的接口fork和vfork执行的do_fork区别就是参数的不同。
/*
* Create a kernel thread.
*/
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL);
}
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
#else
/* can not support in nommu mode */
return(-EINVAL);
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL);
}
#endif
do_fork函数就在这几个宏上面,
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr){
...
struct task_struct *p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace); // 复制父进程的PCB
...
struct pid *pid = get_task_pid(p, PIDTYPE_PID); // 获得子进程的pid
...
wake_up_new_task(p); // 通过唤醒函数将子进程的状态设置为就绪,并将子进程加入就绪队列
...
}
- fork()调用do_fork(): 除了SIGCHLD参数以外,没有其他参数了,不共享父进程的任何资源,要全部资源的复制(独立了),但也不是直接就复制所有资源,而是用时复制,在这里只是给了一个资源指针(代码struct task_struct *p = copy_process())。
- vfork()调用do_fork(): 多传了两个标志CLONE_VFORF和CLONE_VM。子进程优先,父进程睡眠,子进程结束之后才执行父进程,并且子进程共享父进程的内存地址空间。
- 内核线程直接通过kernel_thread()接口创建线程,不过它也是通过do_fork()创建的,区别就是flags不同。
task_struct结构将所有的进程,线程都整合到了一起,进一步的copy_process内容将内核中的各个子系统都整合到了一起,因此这里就不过多的探究了,等到我们有一个整体的了解之后,再回过头来看进程,应该会有更多的理解。
2.2 进程状态信息
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
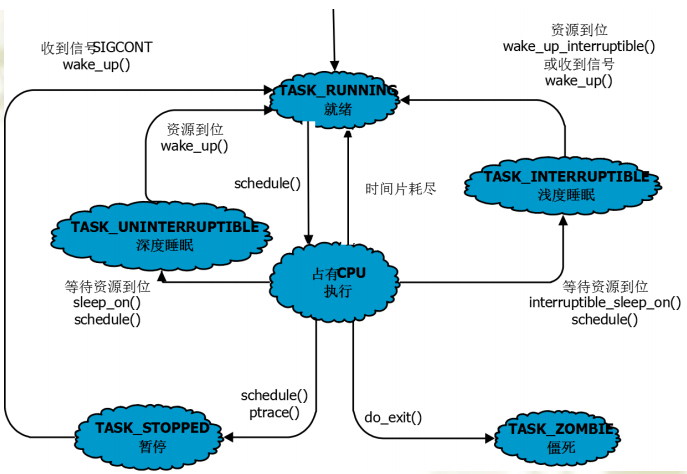
#define TASK_RUNNING 0 // 就绪
#define TASK_INTERRUPTIBLE 1 // 浅睡眠
#define TASK_UNINTERRUPTIBLE 2 // 深睡眠
#define __TASK_STOPPED 4 // 暂停
#define __TASK_TRACED 8 // 由调试程序暂停进程的执行
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16 // 僵死
#define EXIT_DEAD 32 // 最终状态,进程将被彻底删除,但需要父进程来回收
/* in tsk->state again */
#define TASK_DEAD 64 // 与EXIT_DEAD类似,但不需要父进程回收
#define TASK_WAKEKILL 128 // 深度睡眠,接受到致命信号时唤醒进程
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_STATE_MAX 1024
基础的进程状态及转换方式如图所示:
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack; // 内核栈
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace; // 断点调试
}
2.3 进程之间的亲属关系
系统创建的一个进程能创建数个子进程,因此进程有父子关系和有兄弟关系。
进程1(init)是所有进程的祖先,系统中的进程形成一颗进程数,
为了描述进程之间的关系,在PCB中定义了几个域来描述进程之间的关系
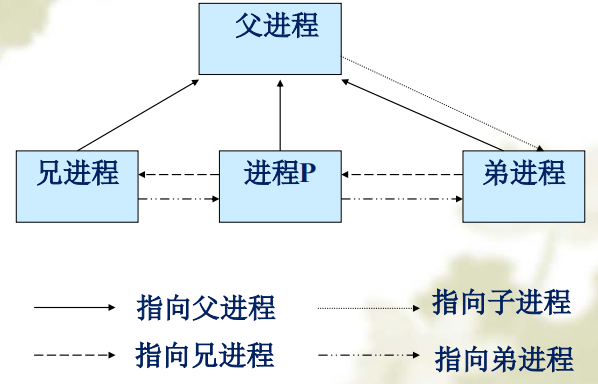
struct task_struct {
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct __rcu *real_parent; /* 生父 real parent process */
struct task_struct __rcu *parent; /* 养父 recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
}
就像我们之前了解到的Linux内核中的基础数据结构–链表:https://blog.csdn.net/qq_40482358/article/details/130864920
进程是通过链表的形式存储在内核中的
链表的头和尾都是init_task,这是0号进程的PCB,0号进程永远不会被撤销,它的PCB被静态的分配在内核数据段中,在运行时保持不变。其他的PCB都是在运行时分配的,撤销时再归还给系统。
当前程序的进程可以通过currenr来表示,它是定义在<current.h>中的一个宏,如上节中代码实例所使用的那样(current->mm),是一个全局变量,描述当前进程,可以直接使用。
2.4 进程之间的调度模型
进程调度,就是从就绪队列中选择一个进程投入CPU运行,调度的核心就是就绪队列调度算法,实质性的动作就是进程切换,对于以时间片调整为主的调度,时钟中断是驱动力。用户可以通过系统调用nice调整优先级等操作。
再task_struct结构体中,就绪状态的进程组成了一个双向循环链表,在优先级部分可以看到优先级和调度策略等信息。
struct task_struct {
// 优先级信息
int prio, static_prio, normal_prio;
unsigned int rt_priority; // 实时优先级
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
// 进程调度策略
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct sched_info sched_info; // 调度信息
struct list_head tasks; // tasks双向链表,链接所有的进程,可以用来遍历其他进程
// 上下文切换和缺页统计
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
}
2.5 虚拟内存信息
正如我们上一节中了解的内存寻址,所用到的mm结构,就是保存在PCB中。
mm和active_mm就是保存了线性地址的所有信息。其中active_mm就是最后访问的地址空间指针
struct task_struct {
struct mm_struct *mm, *active_mm;
}
2.6 文件系统
struct task_struct {
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
}
3. 代码实践: 读取进程描述符中的字段
#include<linux/module.h>
#include<linux/init.h>
#include<linux/kernel.h>
#include<linux/sched.h>
#include<linux/init_task.h>
#include<linux/fdtable.h>
#include<linux/mm_types.h>
#include<linux/list.h>
#include<linux/fs_struct.h>
static void print_pid(void){
struct task_struct *task, *p;
struct list_head *pos;
int count = 0;
printk("Printf process message begin:\n");
// task = &INIT_TASK;
task = &init_task; // 获取0号进程
list_for_each(pos, &task->tasks){
p = list_entry(pos, struct task_struct, tasks);
count++;
printk("\n\n");
printk("pid: %d, state: %lx, prio: %d, static_prio: %d, parent_pid: %d, count: %d, umask: %d\n", \
p->pid, p->state, p->prio, p->static_prio, (p->parent)->pid, atomic_read((&(p->files)->count)), (p->fs)->umask);
if((p->mm) != NULL){
printk("total_vm: %ld\n", (p->mm)->total_vm);
}
}printk("进程的个数: %d\n", count);
}
static int __init mod_init(void){
printk("task_struct init...");
print_pid();
return 0;
}
static void __exit mod_exit(void){
printk("task_struct exit...");
}
module_init(mod_init);
module_exit(mod_exit);
MODULE_LICENSE("GPL");
Makefile文件:
obj-m:= task_struct.o
current_path:= $(shell pwd)
linux_kernel_path:= /usr/src/kernels/$(shell uname -r)/
all:
make -C $(linux_kernel_path) M=$(current_path) modules
clean:
make -C $(linux_kernel_path) M=$(current_path) clean
测试老一套: make编译, insmod task_struct.ko装载, remod task_struct卸载, dmesg查看日志.
参考资料
- 学堂在线-Linux内核分析与应用:https://next.xuetangx.com/course/XIYOU08091001441/14767915
- 蜗窝科技-进程管理: http://www.wowotech.net/sort/process_management
- 这里面有很多的好文章: 看了好几篇, 就不一一列举了, 放了个目录在这里
- 进程调度与管理:https://blog.csdn.net/gatieme/article/details/51383272