在Pix2PixHDModel代码中首先定义损失:
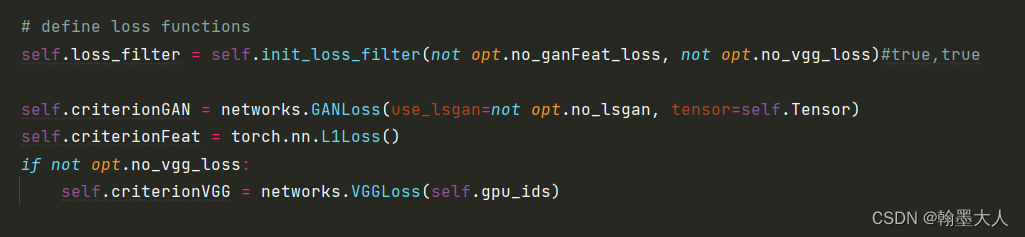
首先看第一个:输入的两个参数use_gan_feat_loss, use_vgg_loss默认为false,则前缀有not,所以两个参数都是True。
def init_loss_filter(self, use_gan_feat_loss, use_vgg_loss):
flags = (True, use_gan_feat_loss, use_vgg_loss, True, True)
def loss_filter(g_gan, g_gan_feat, g_vgg, d_real, d_fake):
return [l for (l,f) in zip((g_gan,g_gan_feat,g_vgg,d_real,d_fake),flags) if f]
return loss_filter
则flag里面有五个True,zip函数将每一个值和True组合为一个元组。一共有五个。
接着看第二个:

class GANLoss(nn.Module):
def __init__(self, use_lsgan=True, target_real_label=1.0, target_fake_label=0.0,
tensor=torch.FloatTensor):
super(GANLoss, self).__init__()
self.real_label = target_real_label
self.fake_label = target_fake_label
self.real_label_var = None
self.fake_label_var = None
self.Tensor = tensor
if use_lsgan:
self.loss = nn.MSELoss()
else:
self.loss = nn.BCELoss()
def get_target_tensor(self, input, target_is_real):
target_tensor = None
if target_is_real:
create_label = ((self.real_label_var is None) or
(self.real_label_var.numel() != input.numel()))
if create_label:
real_tensor = self.Tensor(input.size()).fill_(self.real_label)
self.real_label_var = Variable(real_tensor, requires_grad=False)
target_tensor = self.real_label_var
else:
create_label = ((self.fake_label_var is None) or
(self.fake_label_var.numel() != input.numel()))
if create_label:
fake_tensor = self.Tensor(input.size()).fill_(self.fake_label)
self.fake_label_var = Variable(fake_tensor, requires_grad=False)
target_tensor = self.fake_label_var
return target_tensor
def __call__(self, input, target_is_real):
if isinstance(input[0], list):
loss = 0
for input_i in input:
pred = input_i[-1]
target_tensor = self.get_target_tensor(pred, target_is_real)
loss += self.loss(pred, target_tensor)
return loss
else:
target_tensor = self.get_target_tensor(input[-1], target_is_real)
return self.loss(input[-1], target_tensor)
通过call函数调用,有两个输入,这里用了一个for循环,因为在辨别器中我们的输出列表里面有五个值。将pred值和target值输入到get_target_tensor得到target_tensor 。
def get_target_tensor(self, input, target_is_real):
target_tensor = None
if target_is_real:
create_label = ((self.real_label_var is None) or
(self.real_label_var.numel() != input.numel()))
if create_label:
real_tensor = self.Tensor(input.size()).fill_(self.real_label)
self.real_label_var = Variable(real_tensor, requires_grad=False)
target_tensor = self.real_label_var
else:
create_label = ((self.fake_label_var is None) or
(self.fake_label_var.numel() != input.numel()))
if create_label:
fake_tensor = self.Tensor(input.size()).fill_(self.fake_label)
self.fake_label_var = Variable(fake_tensor, requires_grad=False)
target_tensor = self.fake_label_var
return target_tensor
这个地方就是获得一个和input大小一样的矩阵,矩阵的值由1或者0组成。
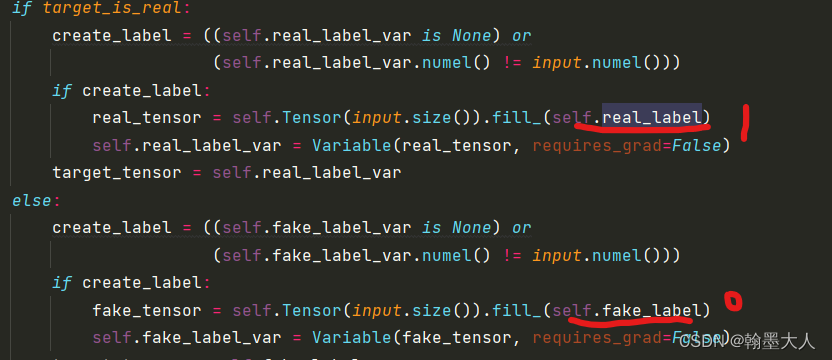
最后将pred和target进行损失计算,计算的结果进行累加:损失函数采用的MSELoss.


除了GANloss之外还有一个L1loss和VGGloss。

如果使用VGGloss即feature matching loss的话:
class VGGLoss(nn.Module):
def __init__(self, gpu_ids):
super(VGGLoss, self).__init__()
self.vgg = Vgg19().cuda()
self.criterion = nn.L1Loss()
self.weights = [1.0/32, 1.0/16, 1.0/8, 1.0/4, 1.0]
def forward(self, x, y):
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
loss = 0
for i in range(len(x_vgg)):
loss += self.weights[i] * self.criterion(x_vgg[i], y_vgg[i].detach())
return loss
将真实图片和生成图片输入到VGG19中,得到的值进行L1损失计算,每一个值赋予一个权重。

在model中使用损失进行计算:
pred_fake_pool = self.discriminate(input_label, fake_image, use_pool=True)
loss_D_fake = self.criterionGAN(pred_fake_pool, False)
# Real Detection and Loss
pred_real = self.discriminate(input_label, real_image)
loss_D_real = self.criterionGAN(pred_real, True)
# GAN loss (Fake Posibility Loss)
pred_fake = self.netD.forward(torch.cat((input_label, fake_image), dim=1))
loss_G_GAN = self.criterionGAN(pred_fake, True)
对于辨别器来说,当输入的是假图片即生成的图片时,我们希望他输出为0,当输入的是真实图片时,我们希望辨别器输出为1.对于生成器来说,我们希望辨别器不能预测出来,即生成的都为1.这是三个GANLoss。
然后将真实图片输入到辨别器的输出和假图片输入到辨别器的输出进行一个l1损失计算。
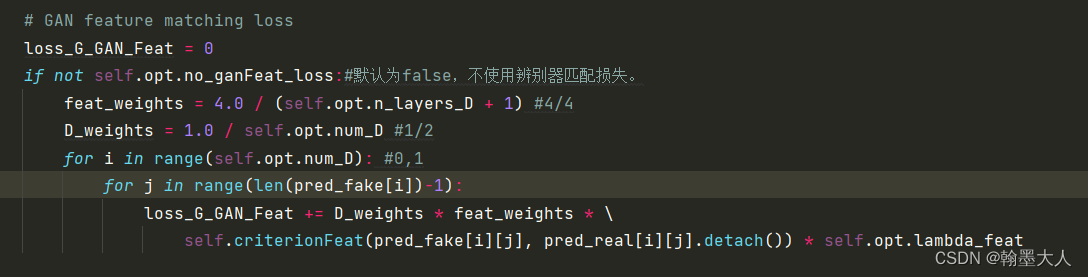
最后将生成器生成的加图片和真实图片输入到VGG中得到的结果进行一个VGGloss计算。画了一下损失计算流程。
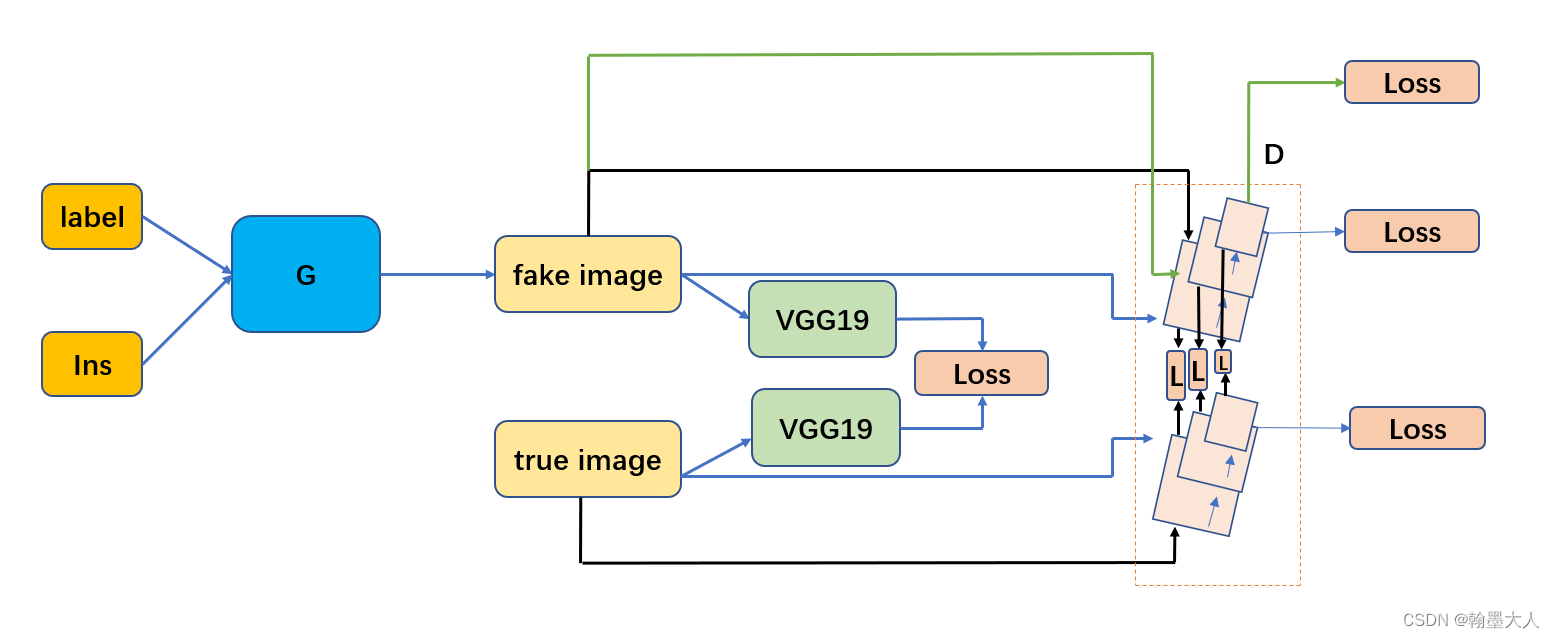
最后将所有损失输入到loss_filter,每一个和true组成一个元组,返回一个大列表,同时model在训练时候还输出另一个输出None,在infer时候输出假的图。
返回train中,整个model就搭建完毕。