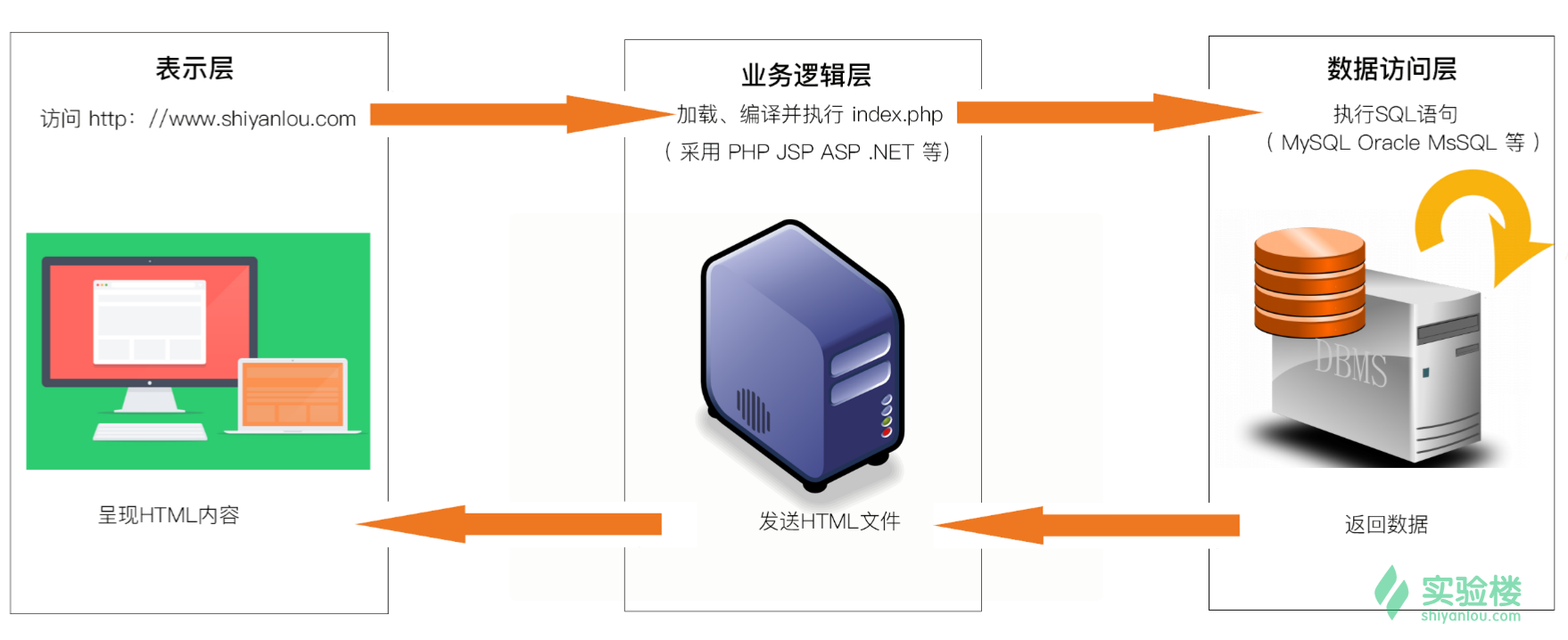
Pandas库专为数据分析而设计,它是使Python成为强大而高效的数据分析环境的重要因素。它提供了多种数据结构和方法来处理和分析数据。下面是一些Pandas常用方法的使用总结。
1. 创建数据框
使用read_csv()或read_excel()方法读取数据文件,也可以使用DataFrame()方法从列表或字典创建数据帧。例如,通过以下方式创建数据框:
import pandas as pd
df = pd.read_csv('example.csv')
# or
df = pd.read_excel('example.xlsx')
# or
df = pd.DataFrame({'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 32, 18]})
2. 查看数据
使用head()和tail()方法查看前几行或后几行数据。可以使用describe()方法获取数据的描述性统计信息,例如最大值、最小值、平均值和标准差等。
# 查看前5行数据
print(df.head())
# 查看后5行数据
print(df.tail())
# 查看数据的描述性统计信息
print(df.describe())
3. 索引和选择数据
可以使用loc[]和iloc[]方法对数据进行索引和选择。loc[]方法基于标签选择数据,而iloc[]方法基于行和列的位置选择数据,例如:
# 选择行和列:
df.loc[0, 'name']
df.iloc[0, 1]
# 选择行:
df.loc[0]
df.iloc[0]
# 选择列:
df['name']
4. 操作数据
Pandas提供了很多数据操作方法,例如,可以使用mean()方法计算列的平均值,使用corr()方法计算列之间相关性并使用drop()方法删除某些列或行。
# 计算列的平均值
df['age'].mean()
# 计算列之间的相关性
df.corr()
# 删除某些列或行
df.drop('age', axis=1)
df.drop(0)
5. 处理缺失值
Pandas提供了方法来处理缺失值,例如可以使用isnull()检查失值并使用fillna()方法填充缺失值。
# 检查缺失值
df.isnull()
# 填充缺失值
df.fillna(0)
6. 分组和聚合
可以使用groupby()方法将数据按照某些列进行分组,然后使用聚合函数计算列的值。
# 分组和聚合
df.groupby('name').mean()
7. 绘制图表
Pandas提供了很多绘制图表的函数,例如plot()方法可以绘制线图、散点图和条形图等。
# 绘制线图
df.plot(x='name', y='age')
# 绘制散点图
df.plot.scatter(x='name', y='age')
# 绘制条形图
df.plot.bar(x='name', y='age')
8. 排序和排名
使用sort_values()方法对数据进行排序,可以按照某一列的值进行升序或降序排列。使用rank()方法进行排名,将所有的数据按照某一列的值进行排名,例如:
# 按age列进行升序排列
df.sort_values('age', ascending=True)
# 按age列进行降序排列
df.sort_values('age', ascending=False)
# 对age进行排名
df['rank'] = df['age'].rank(method='dense')
9. 数据重塑
使用pivot()和melt()方法进行数据重塑。pivot()方法可以将长格式的数据框转化为宽格式,而melt()方法可以将宽格式的数据框转化为长格式,例如:
# 将长格式的数据框转化为宽格式
df.pivot(index='name', columns='subject', values='score')
# 将宽格式的数据框转化为长格式
df.melt(id_vars=['name', 'age'], var_name='subject', value_name='score')
10. 时间序列数据处理
Pandas提供了多种方法来处理时间序列数据,例如可以使用to_datetime()方法将字符串转化为日期格式,使用resample()方法对时间序列进行重采样,例如:
# 将字符串转化为日期格式
df['date'] = pd.to_datetime(df['date'], formatYmd')
# 对时间序列进行重采样
df.resample('D').sum()

11. 缩减内存占用
Pandas中如果数据集很大,占用的内存可能也会很大,可以使用astype()方法将一些整型或浮点型的列转化为较小的数据类型来减少内存占用,例如:
# 将age列从int64转化为int32
df['age'] =['age'].astype('int32')
# 将score列从float64转化为float32
df['score'] = df['score'].astype('float32')
12. 数据分析和统计
Pandas提供了多种方法来进行数据析和统计,例如可以使用value_counts()方法计算某一列中数值出现的次数,使用cut()方法对一维的连续数据进行离散化,例如:
# 计算name列中每个值出现的次数
df['name'].value_counts()
# 对age列进行等距离分割
df['age_cut'] = pd.cut(df['age'], 3)
13. 文本数据处理
Pandas提供了多种方法来处理文本数据,例如可以使用str()方法来访问字符串中的子串或使用正则表达式来匹配字符串,例如:
# 访问name列中的子串
df['name'].str[0:3]
# 查找name列中包含字母'c'的行
df[df[''].str.contains('c')]
14. 数据透视表
在数据分析中,有时需要统计汇总数据,并按照某些列进行分组统计汇总,Pandas中提供了数据透视表功能来实现上述需求。例如:
pivot_df = df.pivot_table(values='score', index='gender', columnssubject', aggfunc=np.mean)
在这个例子中,我们用pivot_table()方法将原始数据框df按照subject列和gender列进行分组,并求出每个分组的平均值,最后返回一个新的数据框pivot_df。
15. 数据读写
可以使用to_csv()方法数据框写入CSV文件,使用to_excel()方法将数据框写入Excel文件,使用read_sql()方法从数据库中读取数据,例如:
# 将数据框写入CSV文件
df.to_csv('example.csv', index=False)
# 将数据框写入Excel文件
df.to_excel('example.xlsx', index=False)
# 从数据库中读取数据
import sqlite3
conn = sqlite3.connect('example.db')
df = pd.read_sql('select * from table1', conn)
16. 编码和解码数据
Pandas提供了多种方法来进行编码和解码数据,例如可以使用get_dummies()方法对某一列进行独热编码,使用factorize()方法将一个类别列编码为数值列,例如:
# 对gender列进行独热编
df = pd.get_dummies(df, columns=['gender'])
# 将gender列编码为数值列
df['gender_code'] = pd.factorize(df['gender'])[0]
17. 数据采样
当数据量很大时,可以对数据进行采样进行快速处理。Pandas中提供了sample()方法,可以从数据框中随机抽取指定数量的行或占总行数的百分比进行采样,例如:
# 从df中随机抽取10行进行采样
sample_df = df.sample(n=10)
# 从df中随机抽取10的行进行采样
sample_df = df.sample(frac=0.1)
18. 数据重塑
在进行数据分析和处理时,有时需要对数据进行重塑,以便于进行后续的操作。Pandas提供了一些方法来进行数据重塑,例如:
- 将长格式数据重塑为宽格式数据:使用
pivot()方法 - 将宽格式数据重塑为长格式数据:使用
melt()方法
例子:
# 将长格式数据重塑为宽格式数据
df.pivot(index='date', columns='gender', values='score')
# 将宽格式数据重塑为长格式数据
df.melt(id_vars='date', value_vars=['math_score', 'biology_score', 'english_score'])
19. 多级索引
多级索引可以帮助我们处理多维数据,常见的多级索引实现方式为层次化索引。Pandas中使用MultiIndex()方法创建多级索引,例如:
# 创建一个拥有两层索引的数据框
df = pd.DataFrame(np.random.randint(10, size=(6,2)), index=[['A', 'A', 'B', 'B', 'C', 'C'], ['X', 'Y', 'X', 'Y', 'X', 'Y']], columns=['col_1', 'col_2'])
# 将数据框按照第一层索引进行排序
df = df.sort_index(level=0)
20. 时间序列数据重采样
Pandas中提供了一些方法用来对时间序列数据进行重采样,例如:
- 将高频率数据降采样到低频率:使用
resample()方法 - 将低频率数据升采样到高频率:使用
asfreq()方法
例子:
# 将按月的数据框重采样到按季度
df.resample('Q').sum()
# 将按年的数据框升采样到按半年
df.asfreq('6M')
同时,Pandas中也提供了各种方便的时间序列函数,例如计算均值、最大值、最小值、求和等,例如:
# 计算按周采样的均值
df.resample('W').mean()
# 计算按季度采样的最大值
df.resample('Q').max()
# 计算按年采样的最小值
df.resample('Y').min()
21. 用apply函数实现对数据的自定义处理
Pandas中,我们可以使用apply()方法将一个函数作用于数据框中所有的行或者列上,实现对数据的自定义处理。例如,我们定义一个函数对每一行进行处理:
def process_data(row):
# 处理数据的逻辑
return processed_row
# 对每一行进行
df.apply(process_data, axis=1)
在apply()方法中,axis参数可以设置为0表示对每一列进行处理,设置为1表示对每一行进行处理。同时,我们还可以用map()方法和applymap()方法对数据框中每一个元素进行处理:
# 对某一列进行映射处理
df['type'] = df['type'].map({'A': 0, 'B': 1, 'C': 2})
# 对整个数据框进行元素级别的处理
df.applymap(lambda x: x**2)
22. 用groupby和apply函数实现分组自定义处理
除了可以用groupby()方法按照某些列进行分组之外,apply()方法也可以和groupby()方法组合使用,实现对每个分组进行自定义处理。例如:
# 对每个分组进行自定义处理
def process_group(group):
# 处理分组的逻辑
return processed_group
df.groupby('gender').apply(process_group)
在这个例子中,我们定义了process_group()函数来处理每个分组,在groupby()方法中设置按gender列进行分组,然后将每个分组别传递到process_group()函数中进行处理。处理结果将组合在一起成为一个新的数据框。
23. 用pd.merge函数实现数据合并
在数据分析中,有时我们需要将多个数据源的数据合并到一个数据框中进行处理,Pandas中提供了pd.merge()函数来实现数据合并。例如,我们可以通过下列代码将两数据框按照一些列的共同特征进行合并:
merged_df = pd.merge(df1, df2, on='id')
在这个例子中,我们将df1和df2通过共同列id进行合并,并将合并结果存储在merged_df数据框中。
24. 用pd.concat函数实现数据拼接
除了用pd.merge()函数合并数据框之外,Pandas中还提供了pd.concat()函数来实现数据拼接的功能。pd.concat()函数可以将多个数据框沿着某个轴进行连接,例如:
concatenated_df = pd.concat([df1, df2], axis=0)
在这个例子中,我们将df1和df2沿着横轴连接,并将连接结果存储在concatenated_df中,其中axis的取值为0表示沿着纵轴进行连接,取值为1表示沿着横轴连接。
25. 获取唯一值
unique是Pandas中的一个方法,用于返回一个数组中唯一值的集合,并按照出现的顺序排序。该方法可用于Series和DataFram中的列。
例如,对于以下的Series:
import pandas as pd
s = pd.Series([2, 1, 3, 3, 2, 1, 4])
使用unique方法可以返回Series中的唯一值:
s.unique()
输出结果为:
array([2, 1, 3, 4])
26. 对表中的所有数据执行相同函数运算
applymap是Pandas中DataFrame对象的方法之一,它类似于apply方法,都可以用于对数据进行函数映射操作,但是applymap方法是作用于DataFrame中的所有元素,而不是apply方法作用于一列或一行。
例如,我们有一个包含几个人的信息的DataFrame:
import pandas as pd
df =.DataFrame({'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'height': [1.62, 1.78, 1.72]})
我们可以使用applymap方法将所有元素乘以2:
df.applymap(lambda x: x * 2)
输出结果为:
name age height
0 AliceAlice 50 3.24
1 BobBob 60 3.56
2 CharlieCharlie 70 3.44
注意到,因为name这一列的元素是字符串,所以applymap将函数应用到了每个字符上,而不是对整个字符串进行乘法操作。
applymap方法也可以传入自定义函数:
def format_age(age):
return f"Age: {age}"
df.applymap(format_age)
输出结果为:
name age height
0 Age: Alice Age: 25 Age: 1.621 Age: Bob Age: 30 Age: 1.78
2 Age: Charlie Age: 35 Age: 1.72
在上面的例子中,我们将函数应用到了每一个单元格,将age的数值与字符串"Age: "连接成新的字符串。
27. 查看某列中是否包含某些值
isin是Pandas中的一个方法,用于检查DataFrame或Series对象中的值是否存在于给定的列表中。返回结果为一个布尔型Series或DataFrame,其中包含所查询元素是否在目标表中的信息。
例如,对于以下DataFrame:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': ['a', 'b', 'c', 'd']})
我们可以使用isin方法判断列B中的元素是否在指定的列表中:
df['B'].isin(['a', 'c', 'e'])
输出结果为:
0 True
1 False
2 True
3 False
Name: B, dtype: bool
我们也可以使用isin方法结合布尔索引技巧,过滤出符合条件的行:
df[df['B'].isin(['a', 'c', 'e'])]
输出结果为:
A B
0 1 a
2 3 c
注意到,我们使用isin方法返回的布尔型Series作为筛选行的条件。
除了可以传入列表进行查询,isin方法还可以接受其他的类型作为参数,包括标量值,Series,以及同长度的布尔型Series,用来检查DataFrame或Series中是否包含相应的元素
28. 替换
replace是Pandas中的一个方法,用于将DataFrame或Series对象中的值替换为另外的值。replace方法支持多种不同形式的替换规则,可以通过字典、列表、标量等不同方式进行替换。
例如,对于以下Series:
import pandas as pd
s = pd.Series([1, 2, 3, -1, 5])
我们可以使用replace方法将所有-1的元素替换为NaN(缺失值):
s.replace(-1, pd.NaT)
输出结果为:
0 1.0
1 2.0
2 3.0
3 NaT
4 5.0
dtype: float64
注意到,我们使用了pd.NaT来表示缺失值。
replace方法还支持使用字典进行多种不同值的替换,例如:
s.replace({1: 'one', 2: 'two', 3: 'three', -1: pd.NaT, 5: 'five'})
输出结果为:
0 one
1 two
2 three
3 NaT
4 five
dtype: object
其中,我们通过传入一个字典,指定了不同值的替换规则。
除了Series,replace方法也可以用于DataFrame对象中的数值或字符串的替换。只需要指定要替换的列名,并使用字典或其他方式指定替换规则即可。
以上是对于Pandas的28种基本用法的概述,Pandas是数据分析领域一个很重要的工具,它提供了处理、分和可视化大型数据集的简单易用的方法和API,我们可以通过不断实践和探索来更好地掌握Pandas的使用。




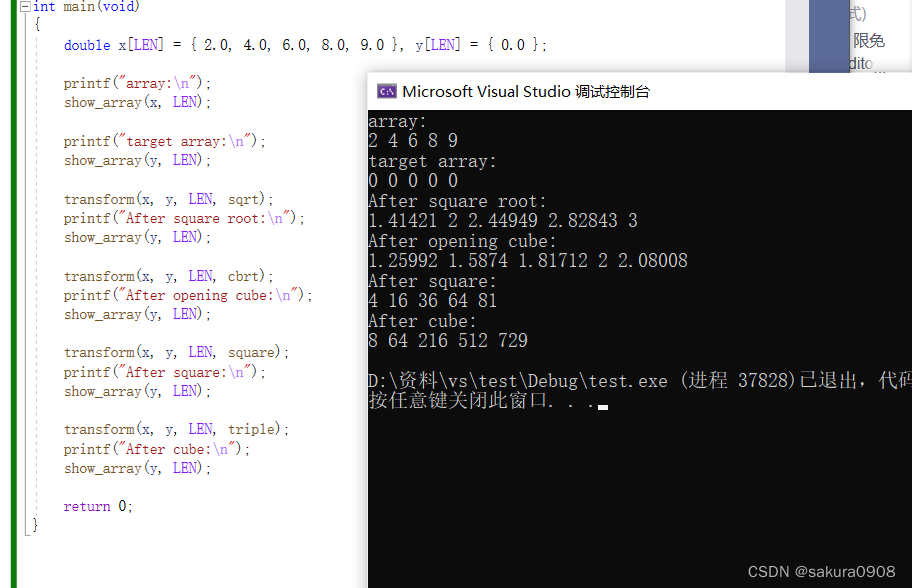

![[深度学习]yolov7 pytorch模型转onnx,转ncnn模型和mnn模型使用细节](https://img-blog.csdnimg.cn/fd2628d6ecbf45eca14ed7c0d096c7e3.png#pic_center)