torch会自动被requirement.txt替换
在对yolov5_5.0进行pip install requirement.txt后,yolo5_5.0会将虚拟环境中中的torch替换为2.0.1版本的,但要注意查看该torch是否为gpu版本,查看方式如下:打开Anaconda Prompt,激活相应环境,输入python,输入import torch 及 torch.cuda.is_available(),就可查看cuda是否可用。事实证明,被更换后的torch版本是cpu版本。
安装gpu版本的torch并卸载cpu版本的torch
安装gpu版本的torch见这篇博文,注意使用清华镜像下载:-i https://pypi.tuna.tsinghua.edu.cn/simple(9条消息) PyTorch1.9.1 GPU版本安装(python3.8+pyTorch1.9.1, torch1.9.1/cu111 + torchvision0.10.1/cu111)_python3.8对应的pytorch_weixin_39450145的博客-CSDN博客![]() https://blog.csdn.net/weixin_39450145/article/details/126454261卸载原有的torch注意在conda的命令窗口中无法执行,需要使用pip才能顺利卸载。
https://blog.csdn.net/weixin_39450145/article/details/126454261卸载原有的torch注意在conda的命令窗口中无法执行,需要使用pip才能顺利卸载。
显卡驱动太高
安装torch2.0.1gpu版本之后,在运行train时报错ddl,原因是显卡驱动版本太高了,torch不兼容,例如我的显卡驱动为12.4(当下最新的驱动,事实证明,最新的技术要承担不兼容的风险),所以在控制面板的程序中删除对应的显卡,安装12.0以下版本的显卡驱动,安装10.2版本的驱动,如果安装11.7版本的显卡驱动,会出现问题:训练时box obj total都为nan。
先用小样本调试
一开始不要用很大的样本训练,先用一个小样本的数据集训练,比如coco128,方便排查各种问题。
colab训练
colab模型的传输
直接将项目的zip文件拖到content目录之下 解压命令:
!unzip file.zip -d /path/to/destination
//file.zip:要解压的ZIP文件的名称。
///path/to/destination:要将文件解压到的目标目录路径。colab数据集的传输
先将数据集的zip文件上传到谷歌硬盘上面,如下: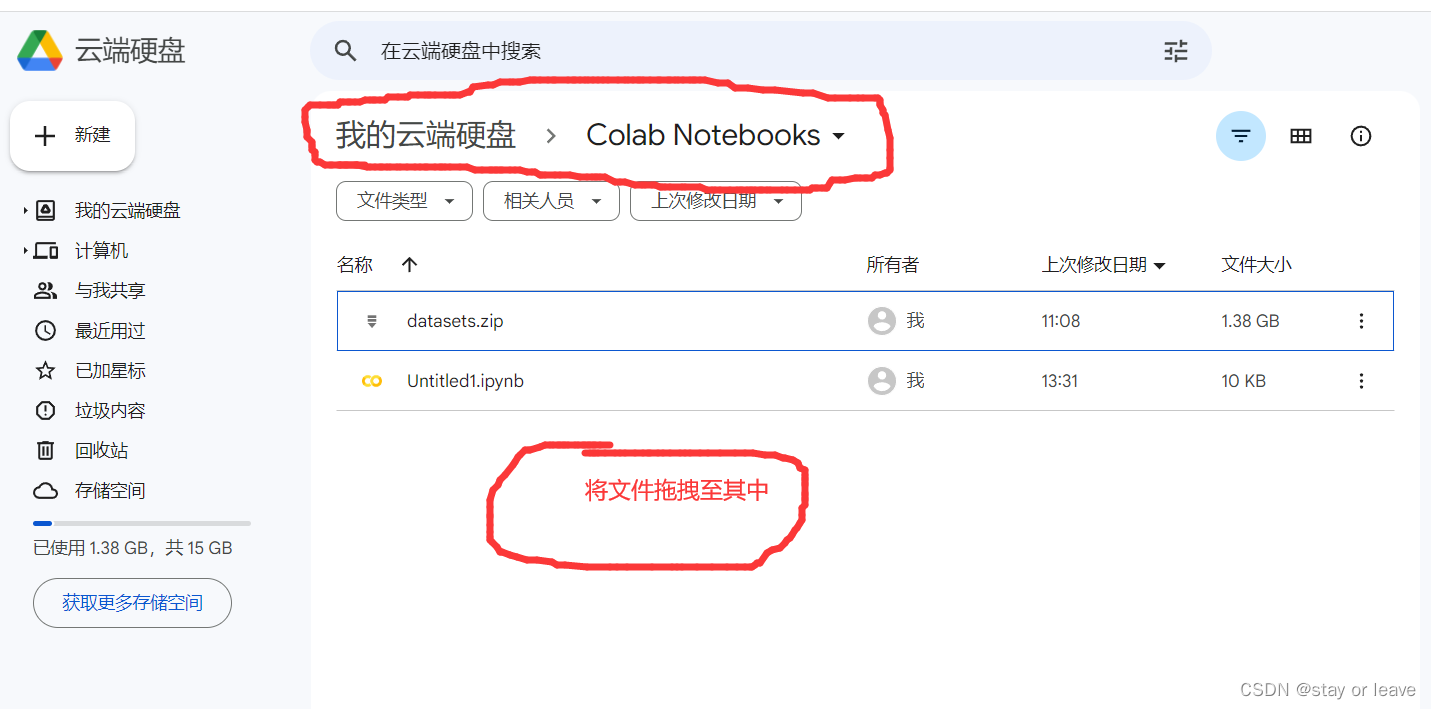
进入ipynb,点击装载云盘: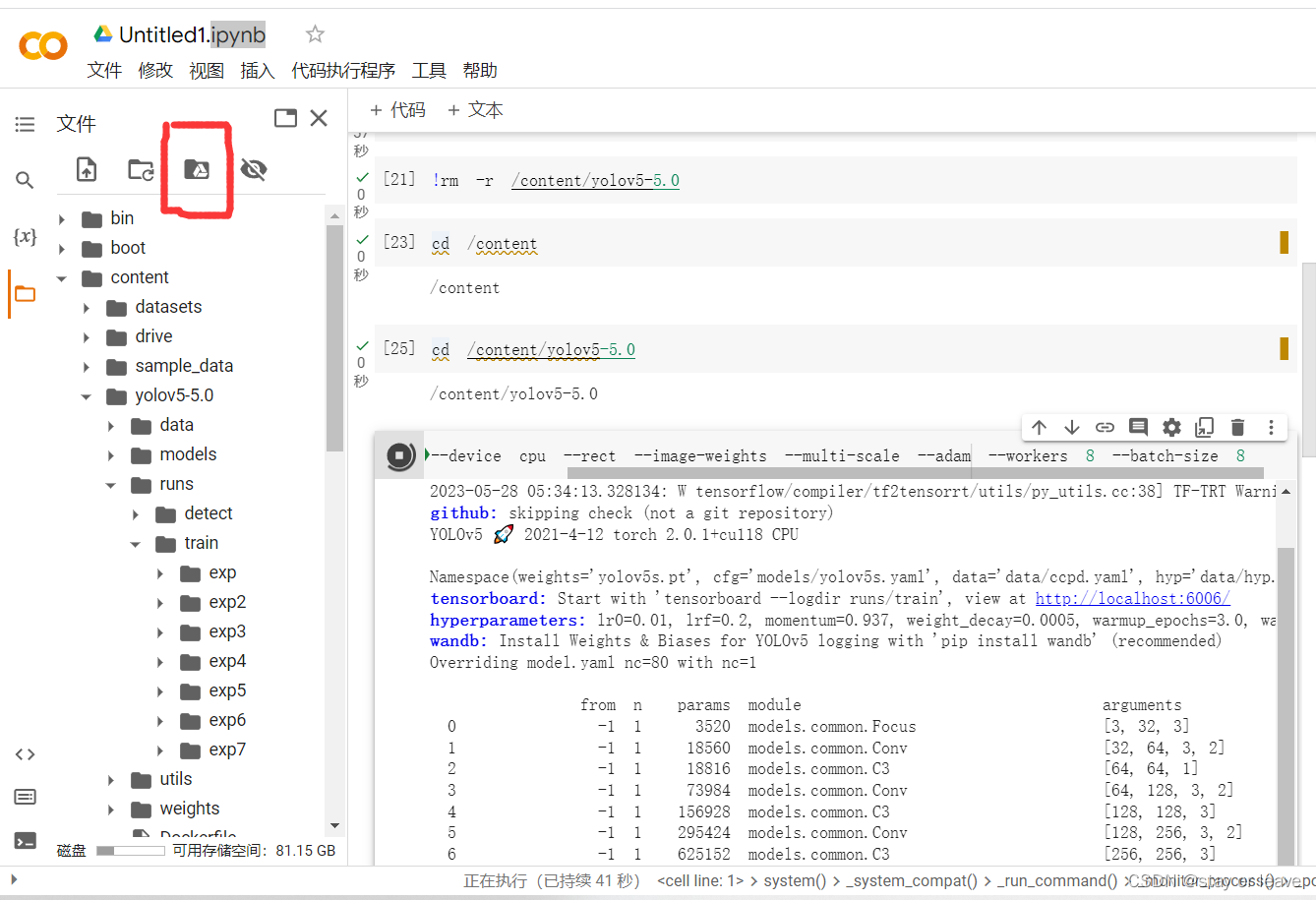
装在云盘完成之后,进入路径 /content/drive/MyDrive/Colab Notebooks,就能看到自己上传的压缩文件。
解压上传的数据集
# 解压缩文件
import zipfile
file_dir = '/content/drive/MyDrive/Colab Notebooks/datasets.zip' # 压缩包路径
zipFile = zipfile.ZipFile(file_dir)
for file in zipFile.namelist():
zipFile.extract(file, '/content') # 解压路径
zipFile.close()box obj total都为nan
用的显卡版本为cuda11.7,将其改为10.2就好了,具体方法为,在Index of /anaconda/cloud/pytorch/win-64/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror![]() https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/这个网站找对应的torch版本并下载,然后在conda prompt中安装(安装命令为 conda install 下载文件路径),在官网(Previous PyTorch Versions | PyTorch)中找到对应版本的torchvision,torchaudio,cudatoolkit并下载。
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/这个网站找对应的torch版本并下载,然后在conda prompt中安装(安装命令为 conda install 下载文件路径),在官网(Previous PyTorch Versions | PyTorch)中找到对应版本的torchvision,torchaudio,cudatoolkit并下载。
清华源的使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
//conda prompt中也能运行“OSError: [WinError 1455]页面文件太小,无法完成操作。”解决方案
(9条消息) “OSError: [WinError 1455]页面文件太小,无法完成操作。”解决方案_页面文件太小,无法完成操作_indigo love的博客-CSDN博客https://blog.csdn.net/weixin_46133643/article/details/125042903?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168525951116782427453854%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168525951116782427453854&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-125042903-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=OSError%3A%20%5BWinError%201455%5D%20%E9%A1%B5%E9%9D%A2%E6%96%87%E4%BB%B6%E5%A4%AA%E5%B0%8F%EF%BC%8C%E6%97%A0%E6%B3%95%E5%AE%8C%E6%88%90%E6%93%8D%E4%BD%9C%E3%80%82%20Error%20loading%20D%3A%5Csoftware_deep_learning%5Canaconda%5Cenvs%5Cpytorch_2.0.1%5Clib%5Csite-packages%5Ctorch%5Clib%5Ccaffe2_detectron_ops_gpu.dll%20or%20one%20of%20its%20dependencies.&spm=1018.2226.3001.4187![]() https://blog.csdn.net/weixin_46133643/article/details/125042903?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168525951116782427453854%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168525951116782427453854&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-125042903-null-null.142%5Ev88%5Econtrol_2,239%5Ev2%5Einsert_chatgpt&utm_term=OSError%3A%20%5BWinError%201455%5D%20%E9%A1%B5%E9%9D%A2%E6%96%87%E4%BB%B6%E5%A4%AA%E5%B0%8F%EF%BC%8C%E6%97%A0%E6%B3%95%E5%AE%8C%E6%88%90%E6%93%8D%E4%BD%9C%E3%80%82%20Error%20loading%20D%3A%5Csoftware_deep_learning%5Canaconda%5Cenvs%5Cpytorch_2.0.1%5Clib%5Csite-packages%5Ctorch%5Clib%5Ccaffe2_detectron_ops_gpu.dll%20or%20one%20of%20its%20dependencies.&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_46133643/article/details/125042903?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168525951116782427453854%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168525951116782427453854&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-125042903-null-null.142%5Ev88%5Econtrol_2,239%5Ev2%5Einsert_chatgpt&utm_term=OSError%3A%20%5BWinError%201455%5D%20%E9%A1%B5%E9%9D%A2%E6%96%87%E4%BB%B6%E5%A4%AA%E5%B0%8F%EF%BC%8C%E6%97%A0%E6%B3%95%E5%AE%8C%E6%88%90%E6%93%8D%E4%BD%9C%E3%80%82%20Error%20loading%20D%3A%5Csoftware_deep_learning%5Canaconda%5Cenvs%5Cpytorch_2.0.1%5Clib%5Csite-packages%5Ctorch%5Clib%5Ccaffe2_detectron_ops_gpu.dll%20or%20one%20of%20its%20dependencies.&spm=1018.2226.3001.4187
KeyError:momentum
这是因为用adam训练出来的权重,不能用于训练sdg的模型。
训练出来的权值在评估数据集上的精度非常低
1、检查数据集的标签是否有问题
具体操作为,使用一张图片为例,对转yolo格式的程序进行debug,检查过程中是否出错。
2、检查模型是否有问题
对已有的数据集coco128,进行训练及测试,发现模型正常工作。
3、检查预训练权重是否合适
从ultralytics上下载的yolov5s.pt预训练权重,是从coco数据集上训练得到的,coco数据集的识别的80类别里面,并没有直接包含车牌的类别,所以我认为这是训练后测试的精度非常低的主要原因。针对以上的分析,我对模型进行从头开始训练,问题得到有效解决。结论就是,当识别的目标完全不同时,直接套用预训练权重可能会出现精度很低的问题。



![[深度学习]yolov7 pytorch模型转onnx,转ncnn模型和mnn模型使用细节](https://img-blog.csdnimg.cn/fd2628d6ecbf45eca14ed7c0d096c7e3.png#pic_center)