分类目录:《自然语言处理从入门到应用》总目录
自然语言通常指的是人类语言,是人类思维的载体和交流的基本工具,也是人类区别于动物的根本标志,更是人类智能发展的外在体现形式之一。自然语言处理(Natural Language Processing,NLP)主要研究用计算机理解和生成自然语言的各种理论和方法,属于人工智能领域的一个重要甚至核心分支,是计算机科学与语言学的交叉学科,又常被称为计算语言学(Computational Linguistics,CL)。随着互联网的快速发展,网络文本呈爆炸性增长,为自然语言处理提出了巨大的应用需求。同时,自然语言处理研究也为人们更深刻地理解语言的机理和社会的机制提供了一条重要的途径,因此具有重要的科学意义。目前,人们普遍认为人工智能的发展经历了从运算智能到感知智能,再到认知智能三个发展阶段。运算智能关注的是机器的基础运算和存储能力,在这方面,机器已经完胜人类。感知智能则强调机器的模式识别能力,如语音的识别以及图像的识别,目前机器在感知智能上的水平基本达到甚至超过了人类的水平。然而,在涉及自然语言处理以及常识建模和推理等研究的认知智能上,机器与人类还有很大的差距。自然语言具有高度的抽象性、近乎无穷变化的语义组合性、无处不在的歧义性和进化性,以及理解语言通常需要背景知识和推理能力等,下面分别进行具体的介绍:
- 抽象性:语言是由抽象符号构成的,每个符号背后都对应着现实世界或人们头脑中的复杂概念,如“车”表示各种交通工具——汽车、火车、自行车等,它们都具有共同的属性,有轮子、能载人或物等。
- 组合性:每种语言的基本符号单元都是有限的,如英文仅有26个字母,中国国家标准GB 2312《信息交换用汉字编码字符集·基本集》共收录6763个汉字,即便是常用的单词,英文和中文也不过各几十万个。然而,这些有限的符号却可以组合成无限的语义,即使是相同的词汇,由于顺序不同,组合的语义也是不相同的,因此无法使用穷举的方法实现对自然语言的理解。
- 歧义性:歧义性主要是由于语言的形式和语义之间存在多对多的对应关系导致的,如:“苹果”一词,既可以指水果,也可以指一家公司或手机、电脑等电子设备,这就是典型的一词多义现象。另外,对于两个句子,如“曹雪芹写了红楼梦”和“红楼梦的作者是曹雪芹”,虽然它们的形式不同,但是语义是相同的。
- 进化性:任何一种“活着”的语言都是在不断发展变化的,即语言具有明显的进化性,也称创造性。这主要体现在两方面:一方面是新词汇层出不穷,如“超女”“非典”“新冠”等;另一方面则体现在旧词汇被赋予新的含义,如“腐败”“杯具”等。除了词汇,语言的语法等也在不断变化,新的用法层出不穷。
- 非规范性:在互联网上,尤其是在用户产生的内容中,经常有一些有意或无意造成的非规范文本,为自然语言处理带来了不小的挑战,如音近词(“为什么”写为“为森么”,“怎么了”写为“肿么了”)、单词的简写或变形(“please”写为“pls”、“cool”写为“coooooooool”)、新造词(“喜大普奔”、“不明觉厉”)和错别字等。
- 主观性:和感知智能问题不同,属于认知智能的自然语言处理问题往往具有一定的主观性,这不但提高了数据标注的难度,还为准确评价系统的表现带来了一定的困难。如在分词这一最基本的中文自然语言处理任务中,关于什么是“词”的定义都尚不明确,比如“打篮球”是一个词还是两个词呢?所以,在标注自然语言处理任务的数据时,往往需要对标注人员进行一定的培训,使得很难通过众包的方式招募大量的标注人员,导致自然语言处理任务的标注数据规模往往比图像识别、语音识别的标注数据规模要小得多。此外,由于不同的分词系统往往标准都不尽相同,所以通过准确率等客观指标对比不同的分词系统本身就是不客观的。难以评价的问题在人机对话等任务中体现得更为明显,由于对话回复的主观性,很难有一个所谓的标准回复,所以如何自动评价人机对话系统仍然是一个开放的问题。
- 知识性:理解语言通常需要背景知识以及基于这些知识的推理能力。例如,针对句子“张三打了李四,然后他倒了”,问其中的“他”指代的是“张三”还是“李四”?只有具备了“被打的人更容易倒”这一知识,才能推出“他”很可能指代的是“李四”。而如果将“倒”替换为“笑”,则“他”很可能指代的是“张三”,因为“被打的人不太容易笑”。但是,如何表示、获取并利用这些知识呢?目前的自然语言处理技术并没有提供很好的答案。
- 难移植性:由于自然语言处理涉及的任务和领域众多,并且它们之间的差异较大,造成了难移植性的问题。如后文将要介绍的,自然语言处理任务根据层级可以分为分词、词性标注、句法分析和语义分析等基础任务,以及信息抽取、问答系统和对话系统等应用任务,由于这些任务的目标和数据各不相同,很难使用统一的技术或模型加以解决,因此不得不针对不同的任务设计不同的算法或训练不同的模型。另外,由于不同领域的用词以及表达方式不尽相同,因此在一个领域上学习的模型也很难应用于其他领域,这也给提高自然语言处理系统的可移植性带来了极大的困难。综上所述,由于自然语言处理面临的众多问题,使其成为目前制约人工智能取得更大突破和更广泛应用的瓶颈之一。因此自然语言处理又被誉为“人工智能皇冠上的明珠”,并吸引了越来越多的人工智能研究者加入。
任务层级
自然语言处理的一大特点是涉及的任务众多。按照从低层到高层的方式,可以划分为资源建设、基础任务、应用任务和应用系统四大类。其中,资源建设主要包括两大类任务,即语言学知识库建设和语料库资源建设。所谓语言学知识库,一般包括词典、规则库等。词典(Dictionary)也称辞典(Thesaurus),除了可以为词语提供音韵、句法或者语义解释以及示例等信息,还可以提供词语之间的关系信息,如上下位、同义反义关系等。语料库资源指的是面向某一自然语言处理任务所标注的数据。无论是语言学资源,还是语料库资源的建设,都是上层各种自然语言处理技术的基础,需要花费大量的人力和物力构建。基础任务包括分词、词性标注、句法分析和语义分析等,这些任务往往不直接面向终端用户,除了语言学上的研究价值,它们主要为上层应用任务提供所需的特征。应用任务包括信息抽取、情感分析、问答系统、机器翻译和对话系统等,它们往往可以作为产品直接被终端用户使用。
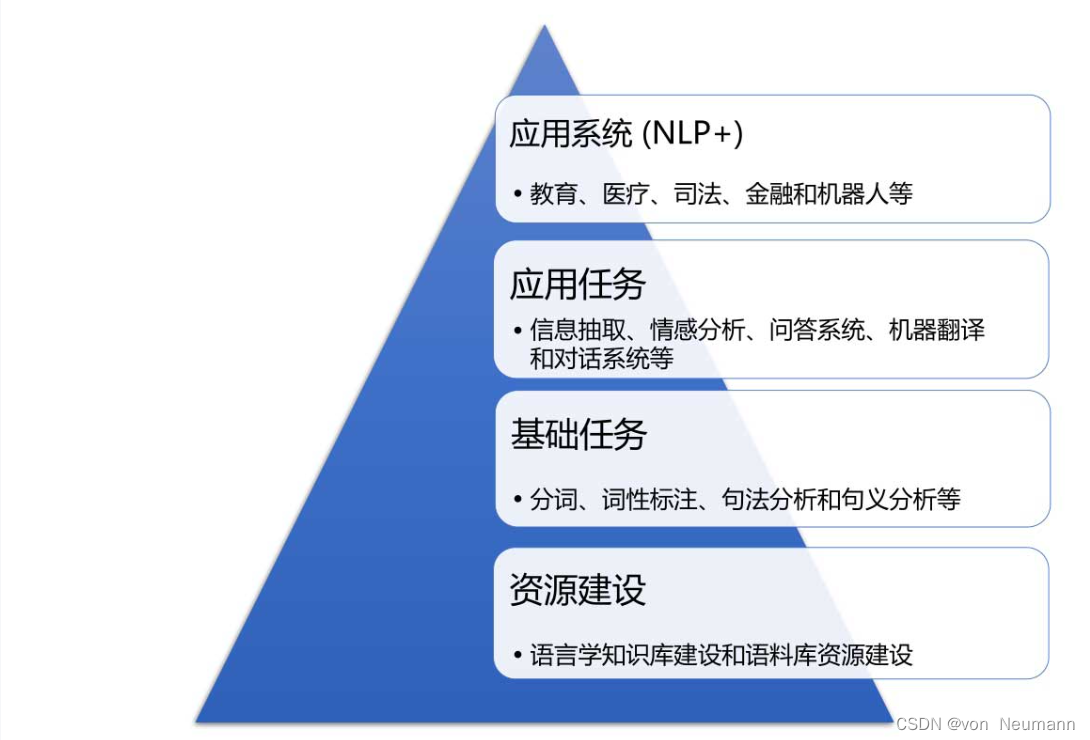
应用系统特指自然语言处理技术在某一领域的综合应用,又被称为NLP+,即自然语言处理技术加上特定的应用领域。如在智能教育领域,可以使用文本分类、回归等技术,实现主观试题的智能评阅,帮助教师减轻工作量,提高工作效率;在智慧医疗领域,自然语言处理技术可以帮助医生跟踪最新的医疗文献,帮助患者进行简单的自我诊断等;在智能司法领域,可以使用阅读理解、文本匹配等技术,实现自动量刑、类案检索和法条推荐等。总之,凡是涉及文本理解和生成的领域,自然语言处理技术都可以发挥巨大的作用。
任务类别
虽然自然语言处理任务多种多样,刚涉足该领域的人可能会觉得眼花缭乱、无从下手,但是这些复杂的任务基本上都可以归纳为回归、分类、匹配、解析或生成五类问题中的一种。下面分别加以介绍:
- 回归问题:即将输入文本映射为一个连续的数值,如对作文的打分,对案件刑期或罚款金额的预测等。
- 分类问题:又称为文本分类,即判断一个输入的文本所属的类别,如:在垃圾邮件识别任务中,可以将一封邮件分为正常和垃圾两类;在情感分析中,可以将用户的情感分为褒义、贬义或中性三类。
- 匹配问题:判断两个输入文本之间的关系,如:它们之间是复述或非复述两类关系;或者蕴含、矛盾和无关三类关系。另外,识别两个输入文本之间的相似性(0到1的数值)也属于匹配问题。
- 解析问题:特指对文本中的词语进行标注或识别词语之间的关系,典型的解析问题包括词性标注、句法分析等,另外还有很多问题,如分词、命名实体识别等也可以转化为解析问题。
- 生成问题:特指根据输入(可以是文本,也可以是图片、表格等其他类型数据)生成一段自然语言,如机器翻译、文本摘要、图像描述生成等都是典型的文本生成类任务。
研究对象与层次
此外,也可以通过对研究对象的区分,将自然语言处理研究分成多个层次的任务。自然语言处理主要涉及“名”“实”“知”“境”之间的关系,如下图所示。其中“名”指的是语言符号;“实”表示客观世界中存在的事实或人的主观世界中的概念;“知”是指知识,包括常识知识、世界知识和领域知识等;“境”则是指语言所处的环境。
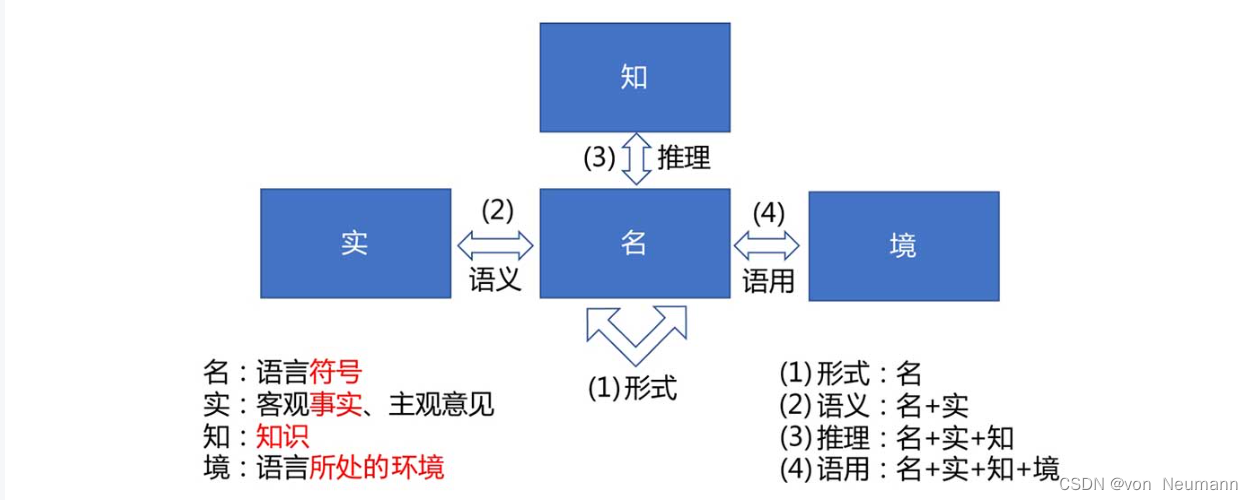
随着涉及的研究对象越来越多,自然语言处理的研究由浅入深,可以分为形式、语义、推理和语用四个层次。形式方面主要研究语言符号层面的处理,研究的是“名”与“名”之间的关系,如通过编辑距离等计算文本之间的相似度。语义方面主要研究语言符号和其背后所要表达的含义之间的关系,即“名”和“实”之间的关系,如“手机余额不足”和“电话欠费了”两个句子的表达方式完全不同,但是背后阐述的事实是相同的。语义问题也是自然语言处理领域目前主要关注的问题。推理是在语义研究的基础之上,进一步引入知识的运用,因此涉及“名”“实”和“知”之间关系,这一点正体现了自然语言的知识性。而语用则最为复杂,由于引入了语言所处的环境因素,通常表达的是“言外之意”和“弦外之音”,同时涉及了“名”“实”“知”“境”四个方面。例如,同样的一句话“你真讨厌”,从字面意义上明显是贬义,而如果是情侣之间的对话,则含义可能就不一样了。另外,语气、语调以及说话人的表情和动作也会影响其要表达的含义。
自然语言处理技术发展历史
自然语言处理自诞生之日起经历了两大研究范式的转换,即理性主义和经验主义,如下图所示。受到语料规模以及计算能力的限制,早期的自然语言处理主要采用基于理性主义的规则方法,通过专家总结的符号逻辑知识处理通用的自然语言现象。然而,由于自然语言的复杂性,基于理性主义的规则方法在面对实际应用场景中的问题时显得力不从心。
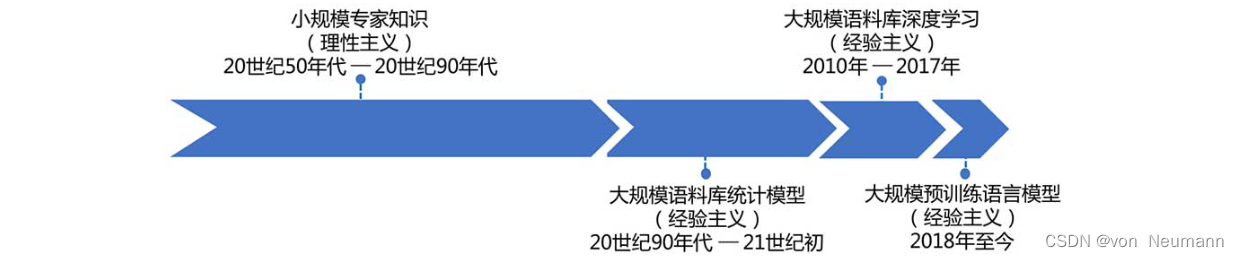
从20世纪90年代开始,随着计算机运算速度和存储容量的快速增加,以及统计学习方法的愈发成熟,使得以语料库为核心的统计学习方法在自然语言处理领域得以大规模应用。由于大规模的语料库中包含了大量关于语言的知识,使得基于语料库的统计自然语言处理方法能够更加客观、准确和细致地捕获语言规律。在这一时期,词法分析、句法分析、信息抽取、机器翻译和自动问答等领域的研究均取得了一定程度的成功。尽管基于统计学习的自然语言处理取得了一定程度的成功,但它也有明显的局限性,也就是需要事先利用经验性规则将原始的自然语言输入转化为机器能够处理的向量形式。这一转化过程(也称为特征提取)需要细致的人工操作和一定的专业知识,因此也被称为特征工程。
2010年之后,随着基于深度神经网络的表示学习方法(深度学习)的兴起,该方法直接端到端地学习各种自然语言处理任务,不再依赖人工设计的特征。所谓表示学习,是指机器能根据输入自动地发现可以用于识别或分类等任务的表示。具体地,深度学习模型在结构上通常包含多层的处理层。底层的处理层接收原始输入,然后对其进行抽象处理,其后的每一层都在前一层的结果上进行更深层次的抽象,最后一层的抽象结果即为输入的一个表示,用于最终的目标任务。其中的抽象处理,是由模型内部的参数进行控制的,而参数的更新值则是根据训练数据上模型的表现,使用反向传播算法学习得到的。由此可以看出,深度学习可以有效地避免统计学习方法中的人工特征提取操作,自动地发现对于目标任务有效的表示。在语音识别、计算机视觉等领域,深度学习已经取得了目前最好的效果,在自然语言处理领域,深度学习同样引发了一系列的变革。
除了可以自动地发现有效特征,表示学习方法的另一个好处是打通了不同任务之间的壁垒。传统统计学习方法需要针对不同的任务设计不同的特征,这些特征往往是无法通用的。而表示学习能够将不同任务在相同的向量空间内进行表示,从而具备跨任务迁移的能力。除了可以跨任务,还可以实现跨语言甚至跨模态的迁移。综合利用多项任务、多种语言和多个模态的数据,使得人工智能向更通用的方向迈进了一步。同样,得益于深度学习技术的快速发展,自然语言处理的另一个主要研究方向——自然语言生成也取得了长足进步。长期以来,自然语言生成的研究几乎处于停滞状态,除了使用模板生成一些简单的语句,并没有什么太有效的解决办法。随着基于深度学习的序列到序列生成框架的提出,这种逐词的文本生成方法全面提升了生成技术的灵活性和实用性,完全革新了机器翻译、文本摘要和人机对话等任务的技术范式。
虽然深度学习技术大幅提高了自然语言处理系统的准确率,但是基于深度学习的算法有一个致命的缺点,就是过度依赖于大规模有标注数据。对于语音识别、图像处理等感知类任务,标注数据相对容易获得,如:在图像处理领域,人们已经为上百万幅的图像标注了相应的类别(如ImageNet数据集);用于语音识别的“语音–文本”平行语料库也有几十万小时。然而,由于自然语言处理这一认知类任务所具有的“主观性”特点,以及其所面对的任务和领域众多,使得标注大规模语料库的时间过长,人力成本过于高昂,因此自然语言处理的标注数据往往不够充足,很难满足深度学习模型训练的需要。早期的静态词向量预训练模型,以及后来的动态词向量预训练模型,特别是2018年以来,以BERT、GPT为代表的超大规模预训练语言模型恰好弥补了自然语言处理标注数据不足的缺点,帮助自然语言处理取得了一系列的突破,使得包括阅读理解在内的所有自然语言处理任务的性能都得到了大幅提高,在有些数据集上达到或甚至超过了人类水平。所谓模型预训练(Pre-train),即首先在一个原任务上预先训练一个初始模型,然后在下游任务(也称目标任务)上继续对该模型进行精调(Fine-tune),从而达到提高下游任务准确率的目的。在本质上,这也是迁移学习(Transfer Learning)思想的一种应用。然而,由于同样需要人工标注,导致原任务标注数据的规模往往也非常有限。那么,如何获得更大规模的标注数据呢?其实,文本自身的顺序性就是一种天然的标注数据,通过若干连续出现的词语预测下一个词语(又称语言模型)就可以构成一项原任务。由于图书、网页等文本数据规模近乎无限,所以,可以非常容易地获得超大规模的预训练数据。有人将这种不需要人工标注数据的预训练学习方法称为无监督学习(Unsupervised Learning),其实这并不准确,因为学习的过程仍然是有监督的(Supervised),更准确的叫法应该是自监督学习(Self-supervised Learning)。
为了能够刻画大规模数据中复杂的语言现象,还要求所使用的深度学习模型容量足够大。基于自注意力的Transformer模型显著地提升了对于自然语言的建模能力,是近年来具有里程碑意义的进展之一。要想在可容忍的时间内,在如此大规模的数据上训练一个超大规模的Transformer模型,也离不开以GPU、TPU为代表的现代并行计算硬件。可以说,超大规模预训练语言模型完全依赖“蛮力”,在大数据、大模型和大算力的加持下,使自然语言处理取得了长足的进步。如OpenAI推出的GPT-3,是一个具有1750亿个参数的巨大规模,无须接受任何特定任务的训练,便可以通过小样本学习完成十余种文本生成任务,如问答、风格迁移、网页生成和自动编曲等。目前,预训练模型已经成为自然语言处理的新范式。
参考文献:
[1] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[2] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[3] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[4] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023

![[深度学习]yolov7 pytorch模型转onnx,转ncnn模型和mnn模型使用细节](https://img-blog.csdnimg.cn/fd2628d6ecbf45eca14ed7c0d096c7e3.png#pic_center)