AIGC技术分享
AIGC概述
- AIGC的概念、应用场景和发展历程
机器学习基础
- 机器学习的基本概念、分类和常用算法,如线性回归、决策树、支持向量机、神经网络等。
深度学习基础
- 深度学习的基本概念、分类和常用算法,如卷积神经网络、循环神经网络、自编码器等。
Golang在AIGC中的应用
- Golang在AIGC中的应用场景和优势,如高并发、内存管理、跨平台等。
Golang常用的AIGC库
- Golang常用的AIGC库,如GoLearn、Gorgonia、Gonum等。
Golang与Python在AIGC中的比较
- 对比Golang和Python在AIGC中的优缺点,如性能、易用性、生态系统等。
AIGC应用案例
- AIGC在各个领域的应用案例,如智能客服、智能家居、智能医疗、智能金融等。
AIGC发展趋势
- AIGC未来的发展趋势和前景,如自动化、智能化、数字化等。
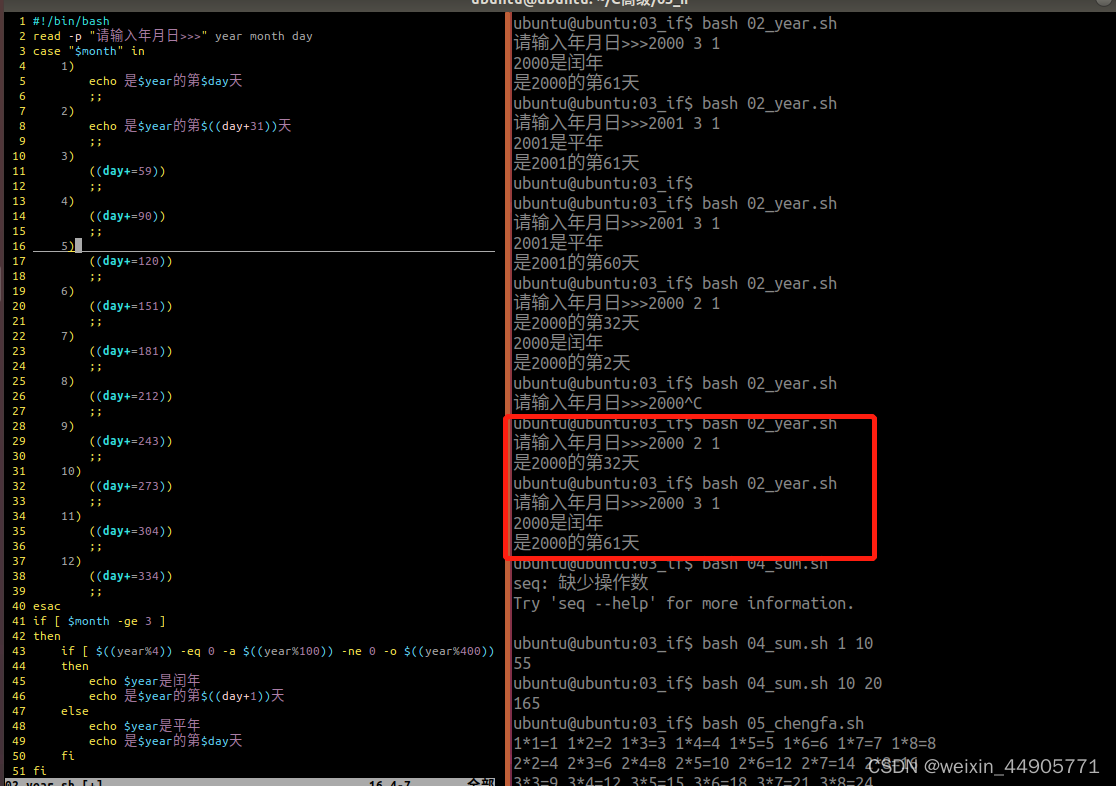
wget --no-check-certificate http://www.openssl.org/source/openssl-1.1.1.tar.gz
tar -zxvf openssl-1.1.1.tar.gz
cd openssl-1.1.1
1943年,麦卡洛克和皮特斯提出了最早的人工神经网络模型:麦卡洛克-皮特斯神经元(McCulloch-Pitts Neuron)模型[1]。该模型旨在用二进制开关的“开”与“关”的机制来模拟神经元的工作原理。该模型的主要组成部分为:接收信号的输入节点,通过预设阈值处理输入信号的中间节点,以及生成输出信号的输出节点。在论文中,麦卡洛克与皮特斯证明了该简化模型可以用于实现基础逻辑(如“与”、“或”、“非”)运算。除此以外,该模型还可以用于解决简单问题,如模式识别与图像处理。
1949年,加拿大心理学家唐纳德·赫布(Donald Hebb)出版了一本题为《行为的组织(The Organization of Behavior)》,并在书中提出了著名的赫布式学习(Hebbian Learning)理论[2]。该理论认为“共同激活的神经元往往是相互连接的(Cells that fire together, wire together)”,也就是神经元具有突触可塑性(synaptic plasticity, 突触是神经元之间相互连接进行信息传递的关键部位),并认为突触可塑性是大脑学习与记忆功能的基础。
机器学习理论中的关键步骤是如何使用不同的更新算法(update rule)来更新模型。使用神经网络模型进行机器学习时,需设定初始模型的架构与参数。在模型训练过程中,每一个来自训练数据集中的输入数据都会导致模型更新各项参数。这个过程,就需要使用到更新算法。赫布式学习理论为机器学习提供了最初更新算法:Δw = η x xpre x xpost。Δw为突触模型的参数的变化大小, η为学习速率,xpre 为突触前神经元活动值大小,xpost为突触后神经元活动值大小。
赫布更新算法为利用人工神经网络来模仿大脑神经网络的行为提供了理论基础。赫布式学习模型是一种无监督学习模型——该模型通过调节其感知到的输入数据之间联系程度的强弱来实现学习目的。也正因为如此,赫布式学习模型在对输入数据中的子类别聚类分析尤其擅长。随着神经网络的研究逐渐加深,赫布式学习模型后来也被发现适用于强化学习等其他多个细分领域。
感知机
(Perceptron)
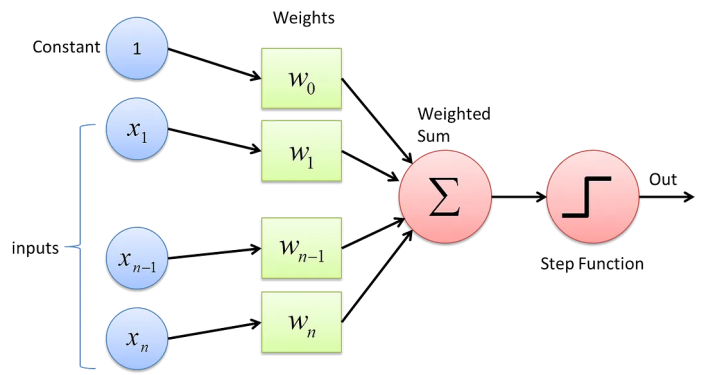
1957年,美国心理学家弗兰克·罗森布拉特(Frank Rosenblatt)首次提出感知机(Perceptron)模型,并且首次使用了感知机更新算法[3]。感知机更新算法延伸了赫布更新算法的基础,通过利用迭代、试错过程来进行模型训练。在模型训练时,感知机模型对于每一个新的数据,计算出模型预测的该数据输出值与实际测得的该数据输出值的差值,然后使用该差值更新模型中的系数。具体方程如下:Δw = η x (t - y) x x。在提出最初的感知机模型后,罗森布拉特继续深入探讨、发展感知机相关理论。1959年,罗森布拉特成功研发出一台使用感知机模型识别英文字母的神经计算机Mark1。
感知机模型与麦卡洛克-皮特斯神经元类似,也是基于神经元的生物学模型,以接收输入信号,处理输入信号,生成输出信号为基本运作机理。感知机模型与麦卡洛克-皮特斯神经元模型的区别在于后者的输出信号只能为0或1——超过预设阈值为1,否则为零——而感知机模型则使用了线性激活函数,使得模型的输出值可以与输入信号一样为连续变化值。另外,感知机对每一条输入信号都设置了系数,该系数能影响每条输入信号对于输出信号的作用程度。最后,感知机是学习算法,因为其各输入信号的系数可以根据所看到的数据进行调整;而麦卡洛克-皮特斯神经元模型因没有设置系数,所以其行为无法根据数据反馈进行动态更新。
1962年,罗森布拉特将多年关于感知机模型的研究集结成《神经动力学原理:感知机与大脑原理(Principles of Neurodynamics: Perceptrons and the theory of brain mechanisms)》一书。感知机模型在人工智能领域是一项重大的进步,因为它是第一种具有学习能力的算法模型,能自主学习接收到的数据中的规律与特点。并且,它具有模式分类的能力,可以将数据根据其特点自动分为不同的类别。另外,感知机模型相对简单,所需计算资源也较少。
尽管感知机具有种种优点与潜力,但它毕竟是一个相对简化的模型,存在许多局限性。1969年,计算机科学家马文·明斯基(Marvin Minsky)与西摩尔·派普特(Seymour Papert)合作出版了《感知机(Perceptron)》一书[5]。在书中,两位作者对感知机模型进行了深入的批判,分析了以感知机为代表的单层神经网络的局限,包括但不限于“异或”逻辑的实现以及线性不可分问题。但是,二位作者与罗森布拉特都已经意识到,多层神经网络可以解决这些单层神经网络不能解决的问题。可惜的是,《感知机》一书对感知机模型的负面评价影响巨大,使得公众与政府机构对于感知机研究一下子失去了兴趣。1971年,感知机理论的提出者兼头号支持者罗森布拉特不幸在一次出海航行中遇难,享年43岁。在《感知机》一书与罗森布拉特之死的双重打击下,与感知机相关的论文发表数目逐年迅速减少。人工神经网络的发展进入了“寒冬”。
反向传播算法
多层神经网络能够解决单层神经网络无法解决的问题,但它带来了新的问题:更新多层神经网络模型的每一层神经元的权重涉及到大量精确计算,而普通的计算方法费时费力,使得神经网络学习过程变得非常缓慢,实用性很差。
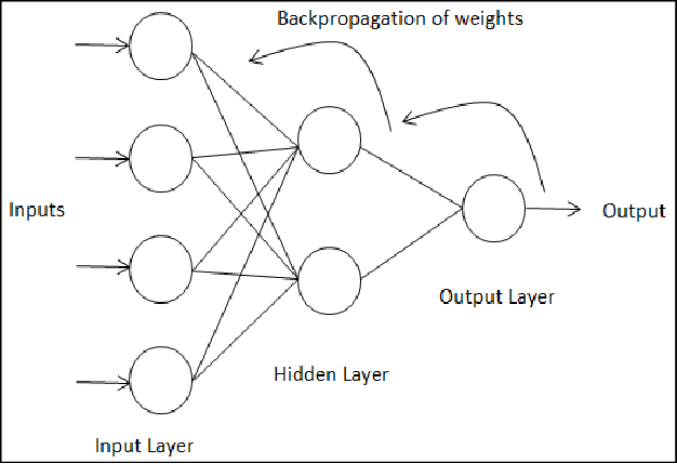
为了解决这个问题,美国社会学家、机器学习工程师保罗·韦伯(Paul Werbos)在1974年的哈佛大学的博士论文《Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences》中提出了反向传播算法(backpropagation)[6]。该算法的基本思想是通过将预测到的输出值与实际输出值之间的误差从输出层反向传播,从而调整神经网络各个神经元的权重。这个算法的本质是根据微积分中常用的链式法则从输出层到输入层反向(沿着负梯度方向)实现对由多层感知机组成的神经网络的训练。
令人感到遗憾的是,韦伯的论文在发表后很长一段时间内都没有得到足够的关注。直到1985年,加州大学圣地亚哥分校的心理学家大卫·鲁梅尔哈特(David Rumelhart)、认知心理学家与计算机学家杰弗里·辛顿(Geoffrey Hinton),以及计算机学家罗纳德·威廉姆斯(Ronald Williams)合作发表了一篇关于反向传播算法在神经网络中的应用的论文[7]。这篇论文在人工智能领域获得了很大的反响。鲁梅尔哈特等人的想法与韦伯的想法本质上是相似的,但鲁梅尔哈特他们没有引用韦伯的论文,这一点近来常常为人诟病。
反向传播算法在人工神经网络的发展中起着关键作用,并使得深度学习模型的训练成为可能。自从反向传播算法于八十年代重新受到人们的重视以来,它被广泛应用于训练多种神经网络网络。除了最初的多层感知机神经网络以外,反向传播算法还适用于卷积神经网络、循环神经网络等。由于反向传播算法的重要地位,韦伯与鲁梅尔哈特等人被认为是神经网络领域的先驱之一。
事实上,反向传播算法是人工智能领域的“文艺复兴”时代(20世纪80年代和90年代期间)的重要成果。并行分布式处理(Parallel Distributed Processing)是这段时间的主要方法论。该方法论关注多层神经网络,并推崇通过并行处理计算来加速神经网络的训练过程与应用。这与先前的人工智能领域的主流思想背道而驰,因而具有划时代的意义。另外,该方法论受到了计算机科学以外,包括心理学、认知科学,以及神经科学等不同领域的学者的欢迎。因此,这段历史常常被后人认为是人工智能领域的文艺复兴。
卷积神经网络
(Convolutional Neural Network, CNN)
如果把麦卡洛克·皮特斯神经元作为人工智能诞生的标志,那么美国可以说是人工神经网络的发源地。人工神经网络诞生后的三十年里,美国在人工智能领域一直扮演着主角,孕育了感知机、反向传播算法等关键技术。但在第一个人工智能的"寒冬"中,包括政府、学术界在内的美国各方人士对人工神经网络的潜能失去了信心,大大放缓了对神经网络技术迭代的支持与投入。也因为如此,在这个席卷美国的”寒冬“中,其他国家的人工神经网络的研究走到了历史发展的聚光灯之下。卷积神经网络与递归神经网络就是在这样的背景下出场的。
卷积神经网络是一种包含了卷积层,池化层,以及全连接层等多种独特结构的多层神经网络模型。该模型利用卷积层提取出输入信号的局部特征,然后通过池化层降低数据的维度与复杂性,最后通过全连接层将数据转化为一维的特征向量并生成输出信号(一般为预测或分类结果)。卷积神经网络的独特结构使得它在处理具有网格结构属性的数据(图像,时间序列等)时尤有优势。
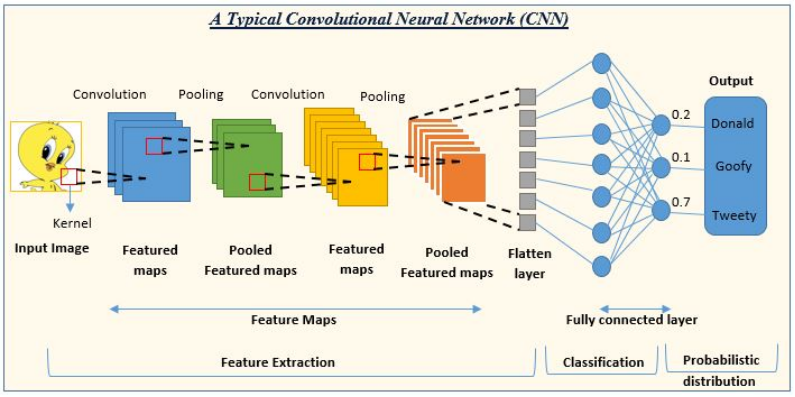
最早的卷积神经网络是日本计算机科学家福岛邦彦(Kunihiko Fukushima)于1980年提出[8]。福岛所提出的模型包含卷积层与下采样层,是当今主流卷积神经网络结构仍然一直沿用的结构。福岛的模型与今日的卷积神经网络唯一不同之处在于前者没有使用反向传播算法——如前文所叙,反向传播算法要等到1986年才受到关注。由于福岛的卷积神经网络模型没有该算法的助力,该模型与当时的其他多层神经网络一样存在训练时间长、计算复杂的问题。
1989年,任职于美国贝尔实验室法国计算机科学家杨·立昆(Yann LeCun)及其团队提出了名为LeNet-5的卷积神经网络模型,并在该模型中使用了反向传播算法进行训练[9]。立昆证明了该神经网络可以用于识别手写数字与字符。这标志着卷积神经网络在图像识别中的广泛应用的开始。
递归神经网络
(Recursive Neural Network, RNN)
与卷积神经网络一样,递归神经网络也是一类具有独特结构特征的神经网络。该类神经网络的主要结构特征在于各层级间具有递归关系,而不是顺序关系。由于以上这些特殊结构特征,递归神经网络特别适于处理自然语言以及其他文本类的数据。
1990年,美国认知科学家、心理语言学家杰弗里·艾尔曼(Jeffrey Elman)提出了艾尔曼网络模型(又称为简化递归网络)[10]。艾尔曼网络模型是首个递归神经网络。艾尔曼利用该模型证明了递归神经网络能够在训练时维持数据本身的先后顺序性质,为日后该类模型在自然语言处理领域的应用奠定了基础。
递归神经网络存在梯度消失现象。在使用反向传播算法训练神经网络时,离输入近的层级的权重更新梯度逐渐变得近似于零,使得这些权重变化很慢,导致训练效果变差。为了解决这个问题,1997年,德国计算机科学家瑟普·霍克赖特(Sepp Hochreiter)及其博士导师于尔根·施密德胡伯(Jürgen Schmidhuber)提出了长短期记忆网络[11]。该模型为一种特殊的递归神经网络模型。它引入了记忆节点,使得模型具有更好的长期记忆存留的能力,从而化解了梯度消失现象。该模型目前仍是使用最普遍的递归神经网络模型之一。
生成式神经网络与大型语言模型
**
**
递归神经网络可以逐字连续生成文本序列,因此常常被认为是早期的生成式神经网络模型。然而,尽管递归神经网络善于处理、生成自然语言数据,但它对于长序列数据一直无法有效捕捉全局信息(对于距离较远的信息无法进行有效联系)。
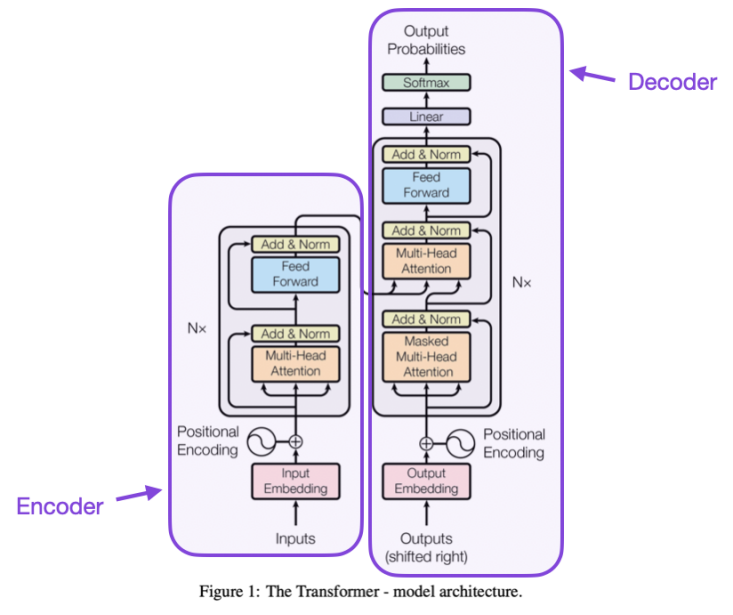
2017年,美国谷歌公司的研究员阿希瑟·瓦斯瓦尼(Ashish Vaswani)等人提出了变压器模型(Transformer)[14]。该大型神经网络分为编码器与解码器两个主要部分。编码器对输入序列进行编码处理,通过自注意力层等来进一步处理编码后的信息。此后,信息传至解码器,并经过解码器部分的自注意力层等网络结构来生成输出序列。该模型的重要创新在于自注意力层(self-attention)。自注意力层使得神经网络模型能摆脱顺序处理文本的局限性,而是直接去文本中的不同位置抓取信息并捕捉各处信息之间的依赖关系,并且并行化计算不同位置之间在语义上的相关性。变压器模型的横空出世对自然语言处理领域乃至整个人工智能领域产生了巨大影响。在短短的几年里,变压器模型已经被广泛用在各类人工智能大模型中。
在层出不穷基于变压器结构的大型语言模型中,OpenAI公司推出的聊天机器人ChatGPT最为出名。ChatGPT所基于的语言模型为GPT-3.5(生成式预训练变压器模型-3.5)。OpenAI公司在训练该模型时用了大量的语料库数据,使其最终具备了广泛的语言理解能力与生成能力,包括提供信息、交流,文本创作、完成软件代码写作、以及轻松胜任各类涉及语言理解相关的考试。