RFNet: Unsupervised Network for Mutually Reinforcing Multi-modal Image Registration and Fusion
(RFNet:一种互增强的多模态图像配准与融合的无监督网络)
本文提出了一种在相互增强的框架RFNet中实现多模态图像配准与融合的新方法。我们以由*coarse-to-fine(粗到精)*的方式处理配准。本文首次将图像融合的反馈信息作为配准精度的提高因素,而不是将二者作为两个独立的问题来处理。精细配准的结果也提高了融合性能。具体地,对于图像配准,我们解决了定义适用于多模态图像的配准度量和促进网络收敛的瓶颈。在coarse、fine两个阶段分别基于图像平移和图像融合定义度量。通过设计的度量和基于可变形卷积的网络来促进收敛。在图像融合方面,我们着重于纹理的保持,这不仅增加了融合结果的信息量和质量,而且改善了融合结果的反馈。通过对全局视差较大的多模态图像、局部失准图像和对准图像的配准和融合实验,验证了该方法的配准和融合性能。
介绍
多模态图像融合的目的是将不同成像模态的信息融合在一起,生成一幅信息丰富、质量高的图像。由于融合后的图像能够通过融合互补信息来全面描述场景,因此图像融合在安防、遥感、临床治疗等领域具有广泛的应用前景。由于多模态图像来自不同的设备/传感器,不可避免地会由于位置、角度等的偏差而产生视差,然而几乎所有的融合方法都没有考虑视差。在融合发生之前,它们需要精确的配准,如图1(a)所示。

不幸的是,不同模态之间的多样性对提高配准精度提出了巨大的挑战,仍然导致预配准图像中的减轻的未对准。当配准和融合是分开的问题时,现有的融合方法必须"tolerate"而不是"fight"预配准未对准。因此,多模态图像配准与融合成为图像融合实际应用中迫切需要解决的问题。
同时,在现有的独立分支中,图像融合是配准的下游任务,不能提供反馈以提高配准精度。然而,考虑到融合图像的特性,图像融合可以反向消除未对准。首先,融合图像整合来自两种模态的信息。当融合图像与任一源图像配准时,减轻的模态多样性降低了配准的难度。第二,融合图像中的未对准无疑导致更多但重复的显著结构,即,密集梯度。通过比较,精确配准鼓励梯度的稀疏。因此,融合结果的梯度稀疏性可以作为一个标准,以反馈的方式提高配准精度,而不丢失源图像中的场景信息。第三,融合后的图像保留了单幅图像中明显的显著结构,并在融合过程中丢弃了一些多余和无用的信息。减少了冗余信息对图像配准的负面影响。当图像融合有助于消除未对准时,更精确对准的数据进一步促进融合结果。结果,这两个任务可以以这种方式相互加强,如图1(b)所示。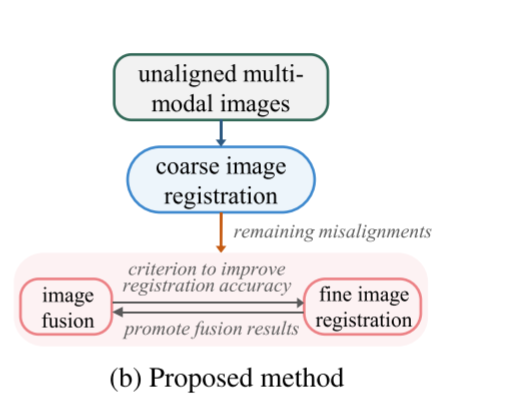
具体每个任务的单个解决方案,图像配准和融合有自己的瓶颈。图像配准,难点在于开发适当的配准指标或综合评价方法自适应数据,以及确保设计配准限制应通过梯度下降对深度网络优化是实用的。图像融合的一般目的是使融合图像呈现最多的信息,部分由梯度表示。此外,如上所述,融合图像的梯度在消除未对准中起关键作用。结合这两个方面,融合方法应致力于纹理信息的保留,这既符合融合目标,也符合图像融合对图像配准的反馈作用。
为了解决先前工作的局限性和未探索的问题,我们在一个相互加强的框架中探索多模态图像配准和融合。我们提出了一个无监督网络来实现它,称为RFNet。图1(b)总结了拟定的框架。配准以从coarse-to-fine 的方法进行处理。粗略阶段通过基于图像平移的评估度量来校正全局视差。coarse-registered的结果帮助生成有意义但粗糙的融合图像。图像融合和细登记集成在一个单一的网络。然后,利用融合图像的特征对网络中与变形相关的部分进行优化,以校正局部错位。最后,网络生成fine-registered和融合的图像。
贡献
1)在我们的工作中,多模态图像配准和融合问题是相互加强的。本文首次将图像融合技术应用到多模态图像配准中,通过深度神经网络来提高配准精度。
2)我们着重于设计约束以优化多模态配准性能。在coarse stage,我们应用图像平移来建立图像级评估度量。提出了一种改进的网络体系结构,以帮助网络收敛。在fine stage,基于融合结果设计度量。
3)考虑到图像融合中的纹理保留问题,采用梯度通道注意机制自适应地调整特征的通道贡献。此外,我们还设计了一个带偏置的梯度损耗。网络结构和损失函数均基于纹理丰富度。
相关工作
Multi-modal Image Registration.
传统的配准方法包括基于变换的配准方法和基于测量的配准方法。基于变换的方法将图像变换到一个公共空间,以表现出更好的一致性。他们手动分析多模态特性和设计约束以实现一致性。然而,这些方法中的优化是棘手的。基于测量的相似性度量方法旨在度量对模态变化敏感性较低的相似性。代表性方法利用互信息(mutual information (MI))、区域MI 等,其在计算上是难处理的并且不适合于梯度下降。最近,已经提出了基于深度学习的方法。例如,Wang等人使用网络来创建模态独立特征,而稀疏性的缺点仍然存在。与我们的工作最接近的是,Arar等人学习了跨模态翻译。但是翻译网络和配准网络的协同训练增加了配准网络优化的难度。在我们的工作中,我们发现将同一域中的平移图像馈入网络可以同时提高配准精度和加快收敛速度。此外,与已有的配准网络相比,由于变形卷积是指未配准图像中的变形,因此我们在网络中使用了变形卷积,以获得更高的配准精度和更强的鲁棒性。与我们的工作最相关的是,SIRF证实,如果正确组合,联合配准和融合肯定可以改善结果。然而,这项工作是在传统的矢量全变分模型中实现的,并且是针对具有限制性局部失调的遥感图像而设计的。
Multi-modal Image Fusion.
现有的融合方法是针对对准图像而定制的,而不考虑视差。传统方法关注融合本身,包括六类:基于多尺度变换、稀疏表示、子空间、显著性、混合方法等的方法。他们致力于手工设计分解方式和融合策略,而细致多样的设计使其变得越来越复杂。为了解决这个问题,提出了一些基于深度学习的方法。它们中的一些不注意纹理保持,并且一些基于生成式对抗网络的方法遭受生成虚假和模糊细节的困扰。即使一些方法涉及纹理,它们也根据图像模态而不是特定区域的实际纹理来保留纹理。在此工作中,我们采用了一种基于梯度的注意机制和一种带偏置的梯度丢失来增强纹理保持。此外,网络混合变形,这使得能够基于保留的纹理进行未对准校正。
方法
我们设计了一个无监督的网络,用于相互加强的多模态图像配准和融合,术语为RFNet。整个过程如图2所示,包括两个主要部分。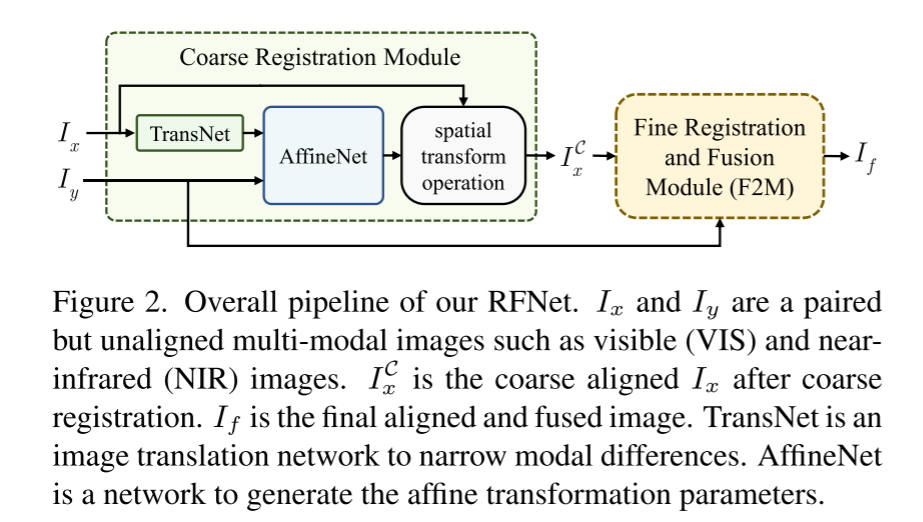
首先,粗配准模块基于仿射变换模型(affine model)执行全局校正。然后,除了一些局部视差之外,多模态图像被粗略地对准,其中仿射模型不适用。第二,在统一的模块/网络中实现精细配准和融合,称为精细配准和融合模块(F2 M)。
Coarse Registration Module
所提出的粗配准模块的流水线如图3所示。TransNet首先将多模态图像转换到同一域(即,将Ix转化为Ix→y)。AffineNet 以Ix→y和Iy为输入,输出仿射参数,生成Ix的形变场。

Image Translation Network
TransNet旨在学习图像平移函数
T
y
T^y
Tyx,其表示通过保留内容信息将域x中的图像Ix平移到域y。因此,我们使用编码器将Ix嵌入到内容空间中,如cx = Ex(Ix),同时去除域信息。为了确保cx包含内容信息,我们通过解码器Dx和Dy将其映射回域,如图4所示。
期望将cx映射回域x的结果重构Ix,即,
I
r
e
c
o
n
I^{recon}
Ireconx =
T
x
T^x
Tx x(Ix)= Dx(Ex(Ix))。并且到域y的映射结果应该是翻译后的Ix,即,X →Y =
T
y
T^y
TyX(X)= Dy(Ex(Ix))。类似地,对于定义域y中的Iy,重建和平移的结果是
I
r
e
c
o
n
I^{recon}
Irecony =
T
y
T^y
Ty y(Iy)和Iy→x =
T
x
T^x
Txy(Iy)。
为了鼓励编码器提取内容信息和解码器恢复域相关信息,将重构损失和转换损失定义为:

TransNet的最终损失函数总结为Eq.(2)其中超参数η控制权衡: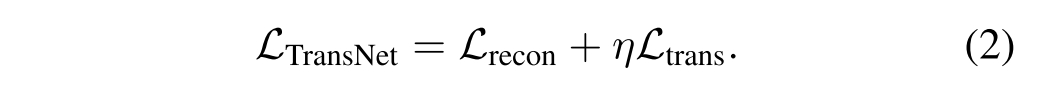
Network Architecture.
TransNet的网络架构如补充材料所示。我们使用实例规范化而不是批规范化,因为它执行一种样式规范化。为了将不同的域映射到同一个内容空间,除了设计的损失函数之外,编码器中的最后一层和解码器中的第一层的权重是共享的。
Affine Network
仿射网络学习生成相应的仿射变换函数C。当馈入一对未对准的图像Ix→y和Iy时,它输出仿射参数paff = C(Ix→y,Iy)。根据paff,我们在一个规则的采样网格上应用paff,生成一个H × W × 2的变形场Φ。Φ表示Ix→y中所有像素的变形。数学上,变形的Ix→y表示为:

其中i和j表示像素的位置。Φ的两个通道分别表示垂直和水平方向的偏差。考虑到由于不同的坐标类型而可能存在一些丢失的像素值,应用重采样器S来改进此步骤。
作为描述,综合图像配准的问题被转化为变形翻译之间的相似图像
I
C
I^C
ICx→y和源图像Iy。因此AffineNet损失函数的定义限制他们的相似之处。为便于计算温顺和弱感性照明振幅线性变化,我们使用归一化互相关(NCC)作为相似性度量。登记损失因此定义为: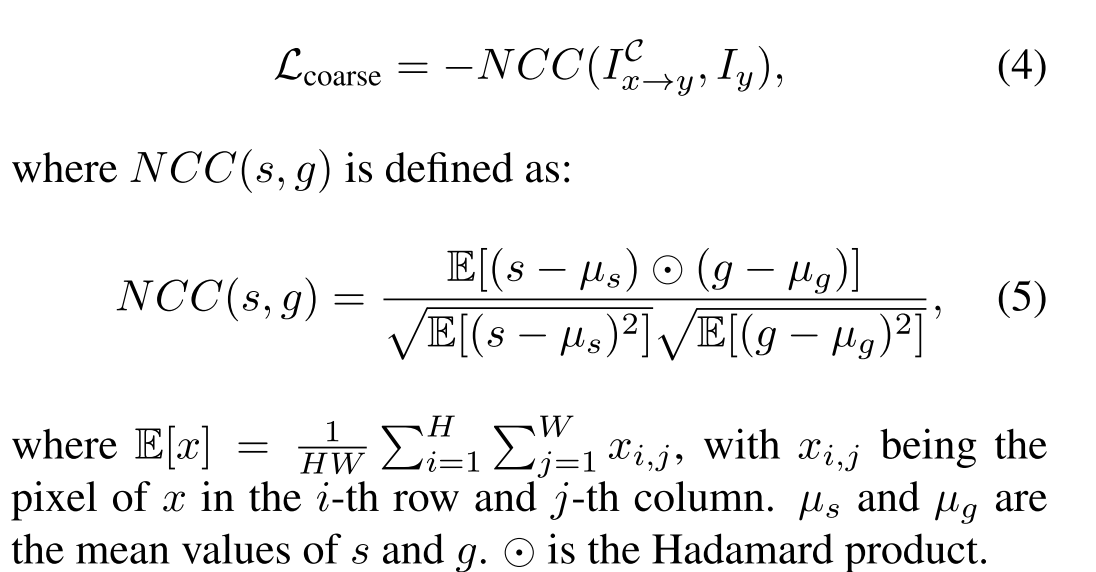
当获得最佳变形场Φ时,我们对Ix执行相同的空间变换,以根据Eq.(3)中的方式生成粗对准图像
I
C
I^C
ICx。
网络架构。AffineNet的网络架构在补充材料中报告。对于图像配准,在两个未配准的图像中,对应对象的区域可能显著移位。考虑到长距离视差,大的核尺寸和深的网络层是宽感受野所必需的以减轻该问题。因此,卷积可变形层应用于取代定期接受领域传统的卷积层。卷积可变形层增加接受字段偏移量,另外从卷积层从之前的特征图谱。因此,它是指在未配准的图像变形更高登记精度和更强的鲁棒性。
Mutually Reinforcing Fine Registration and Fusion Module (F2M)
在第一阶段,F2M实现了以纹理为中心的图像融合,这也是精配准的基础。管道如图5所示。对F2M算法中除变形块外的参数进行了优化。变形块依赖于初始化的参数来生成变形场,变形场自动趋于一致。在这种情况下,If组合
I
C
I^C
ICx和Iy的场景信息,并且在单个图像中渲染它们的视差。损失函数定义为:
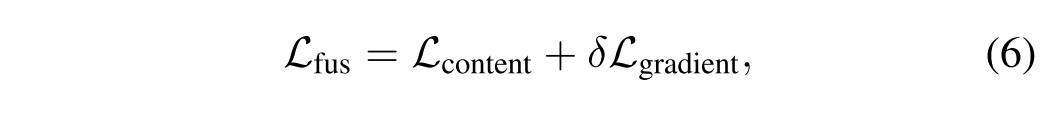
其中δ控制这两项之间的折衷。Lcontent约束图像级相似度以合并场景内容,其定义为:
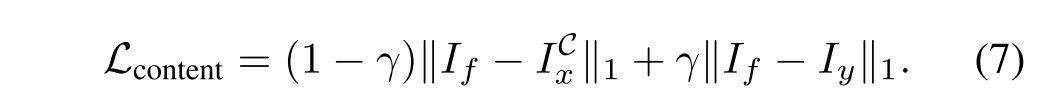
由于NIR图像通常比RGB图像包含更多的纹理细节,因此γ被设置为0.5和1之间的值。
由于显著结构通常以较大梯度出现,梯度损失Lgradient定义为:
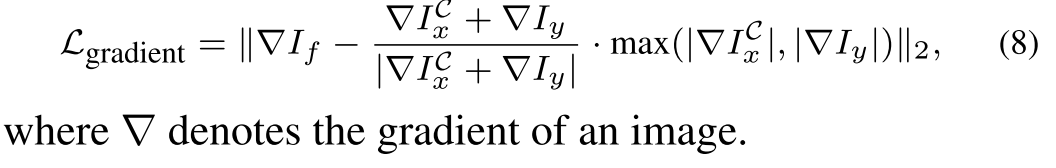
在第二个阶段,F2M实现精细配准根据融合图像的特点。在这个阶段,在这一阶段,我们固定在第一阶段优化的融合相关参数,并训练变形块。损失函数考虑以下三个方面。 1)Iy是提供参考纹理信息的固定图像。If保留
I
C
I^C
ICx的变形梯度。正确的变形后,∇Iy和∇lf应该展示高一致性。因此,第一项限制参考信息的一致性。2)容易观察到If中的任何未对准将增加梯度的稀疏性。我们使用第二项来鼓励If的稀疏性,并惩罚应该校正的显著梯度。3)相邻像素应该具有相似的变形,这由变形场的平滑度直观地表示。否则,场景结构将被扭曲。通过引入正则化项,避免变形块产生非光滑的变形场.因此,损失函数包含以下三项:

特别是对于Lsmooth,将变形表示为Φf,Φf的一阶梯度反映了变形的突变。此外,为了避免过度平滑,使用双边滤波器来将可变权重分配给不同的一阶变化,定义为:
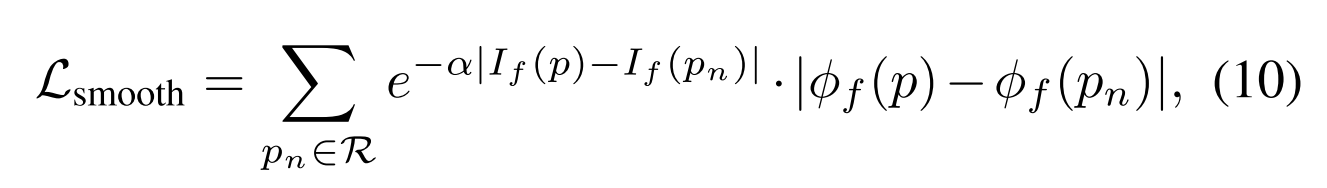
其中p是像素在If或Φf中的位置索引。R表示p的邻居的集合。pn表示该集合中的位置索引。α为系数,设为0.5。
当变形块已经被优化时,我们再次完全执行F2M的前向过程,以生成最终的对准和融合图像If。
Network Architecture. 如图5所示,我们共享前三层的权重,以确保来自不同模态的特征类型的强度一致性。它避免了一个源图像中的信息相对于另一个源图像的衰减和扩散。否则,衰减和扩散会造成伪梯度稀疏,影响配准性能的提高。
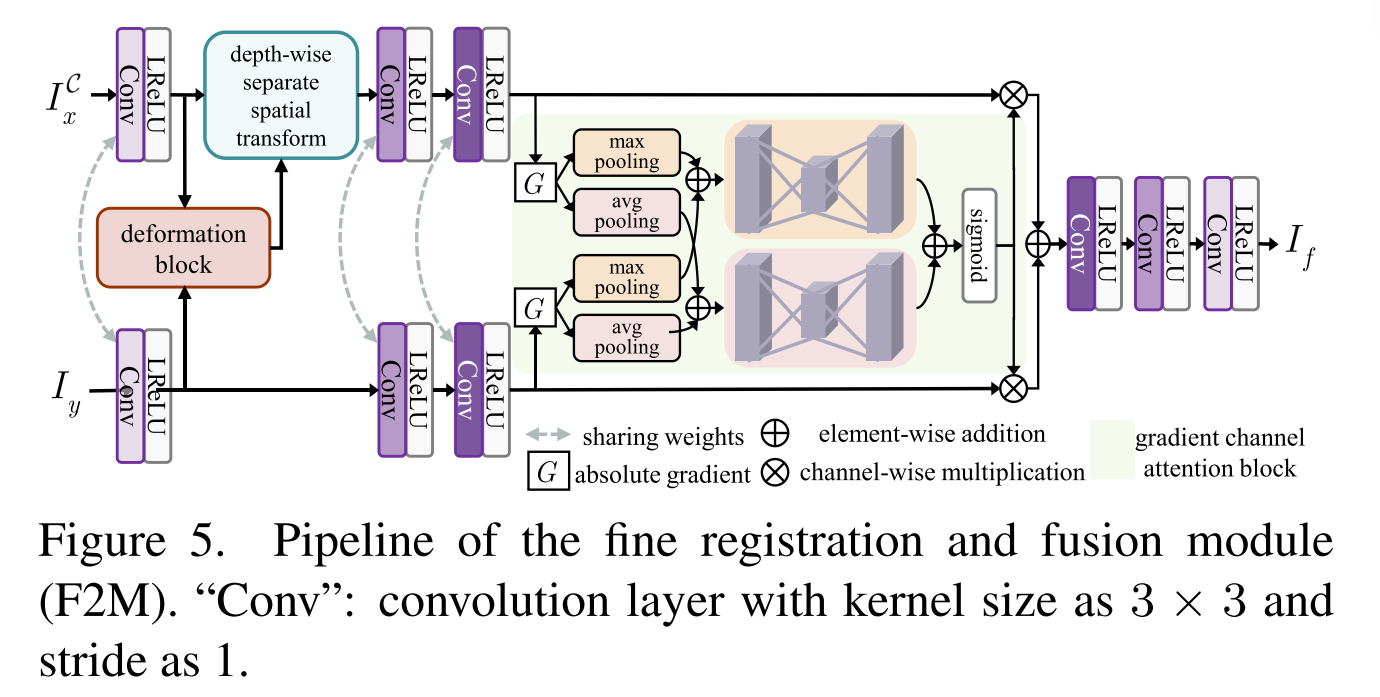
由于感受野随深度的增加而增大,较深特征图中的像素对应图像中较大的区域,这不利于提高配准精度。因此,我们使用浅层特征来探测和生成空间变形。第一卷积层的非线性映射消除了
I
C
I^C
ICx和Iy之间的像素强度差。变形块生成变形场。重采样、批量归一化和残差块用于应用于不同的变形。为了保持纹理,我们引入如图5所示的梯度通道注意块。我们聚合绝对梯度,因为它们是特征地图中信息丰富度的更好表示。通过联合使用最大池和平均池操作来聚合信息。然后,将两个分支的结果相加并馈送到两个单独的多层感知器,以生成共享的通道式注意力权重。然后,几个卷积层将特征映射回以生成If。





![[附源码]计算机毕业设计校园商铺Springboot程序](https://img-blog.csdnimg.cn/a96cc7f6162f4e62afba2b91e285deb2.png)
![[附源码]计算机毕业设计药品仓库及预警管理系统Springboot程序](https://img-blog.csdnimg.cn/279c030adc8048ec89d525c19cc87ba2.png)


![[附源码]计算机毕业设计基于springboot的4s店车辆管理系统](https://img-blog.csdnimg.cn/7081d948d11a4d1abc9458869f39c941.png)