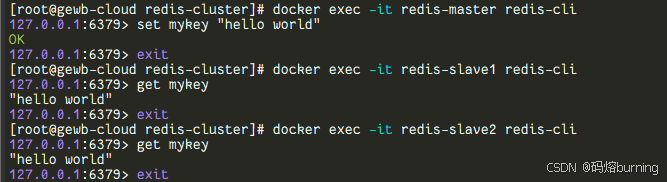
大家好,不少关注 DeepSeek 最新动态的朋友,想必都遇到过 “Distillation”(蒸馏)这一术语。本文将介绍模型蒸馏技术的原理,同时借助 TensorFlow 框架中的实例进行详细演示。通过本文,对模型蒸馏有更深的认识,解锁深度学习优化的新视角。
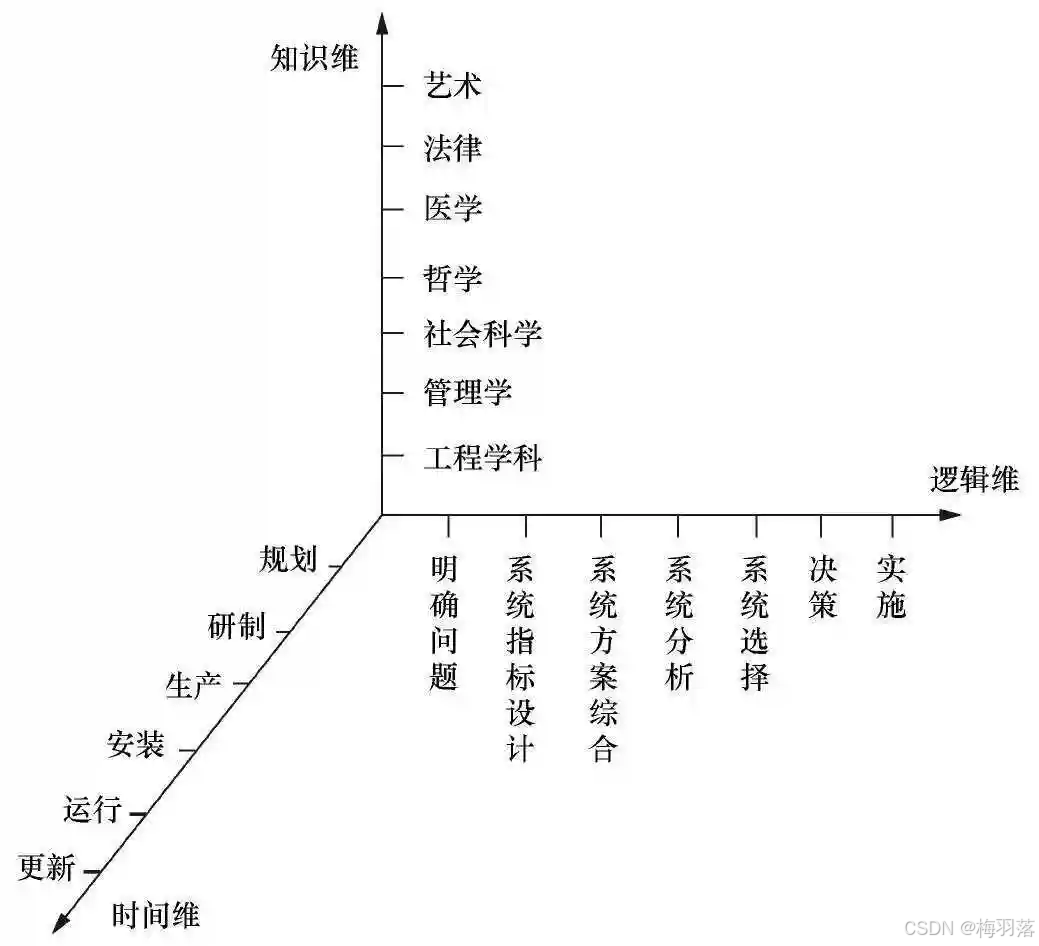
1.模型蒸馏原理
在深度学习领域,模型蒸馏是优化模型的关键技术。它让小的学生模型不再单纯依赖原始标签,而是基于大的教师模型软化后的概率输出进行训练。
以图像分类为例,普通模型只是简单判断图像内容,而运用模型蒸馏技术的学生模型,能从教师模型的置信度分数(如80%是狗,15%是猫,5%是狐狸)中获取更丰富信息,从而保留更细致知识。
这样一来,学生模型能用更少参数实现与教师模型相近的性能,在保持高精度的同时,减小模型规模、降低计算需求,为深度学习模型优化开辟了新路径。下面通过一个例子来看看具体是如何操作的,以使用MNIST数据集训练卷积神经网络(CNN)为例。
MNIST (Modified National Institute of Standards and Technology database)数据集在机器学习和计算机视觉里常用,有 70,000 张 28x28 像素的手写数字(0 - 9)灰度图,60,000 张训练图、10,000 张测试图。
模型蒸馏要先建教师模型,是用 MNIST 数据集训练的 CNN,参数多、结构复杂。
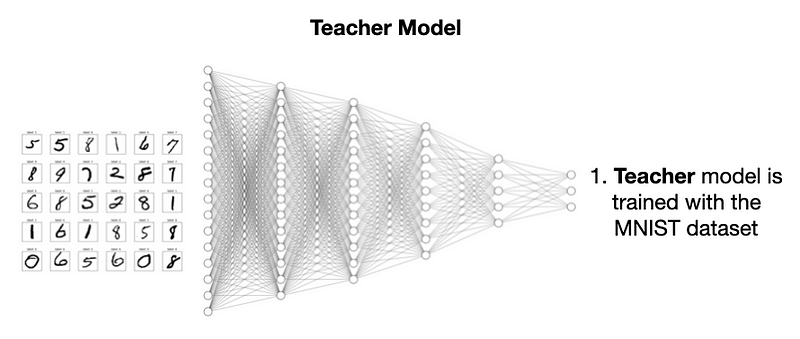
再建个更简单、规模更小的学生模型:
目的是让学生模型模仿教师模型性能,还能减少计算量和训练时间。
训练时,两个模型都用 MNIST 数据集预测,接着算它们输出的 Kullback-Leibler(KL)散度。这个值能确定梯度,指导调整学生模型。
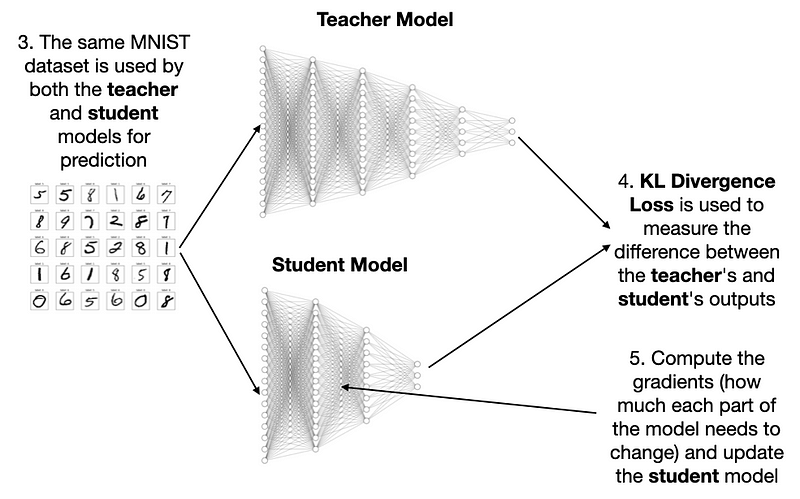
一番操作后,学生模型就能达到和教师模型差不多的准确率,成功 “出师”。
2.TensorFlow 和 MNIST 构建模型
接下来,借助 TensorFlow 和 MNIST 数据集,搭建一个模型蒸馏示例项目。
先训练一个教师模型,再通过模型蒸馏技术,训练出一个更小的学生模型。这个学生模型能模仿教师模型的性能,而且所需资源更少。
2.1 使用MNIST数据集
确保已经安装了TensorFlow:
!pip install tensorflow
然后加载MNIST数据集:
from tensorflow import keras
import matplotlib.pyplot as plt
# 加载数据集(MNIST)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
fig = plt.figure()
# 可视化部分数字
for i in range(9):
plt.subplot(3,3,i+1)
plt.tight_layout()
plt.imshow(x_train[i], interpolation='none')
plt.title("Digit: {}".format(y_train[i]))
# 不显示x轴和y轴刻度
plt.xticks([])
plt.yticks([])
以下是MNIST数据集中的前9个样本数字及其标签:

还需要对图像数据进行归一化处理,并扩展数据集的维度,为训练做准备:
import tensorflow as tf
import numpy as np
# 归一化图像
x_train, x_test = x_train / 255.0, x_test / 255.0
# 为卷积神经网络扩展维度
x_train = np.expand_dims(x_train, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)
# 将标签转换为分类(独热编码)
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
2.2 定义教师模型
在基于模型蒸馏的示例项目构建中,定义并训练教师模型是关键的环节。这里,构建一个多层卷积神经网络(CNN)作为教师模型。代码如下:
# 教师模型
teacher_model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10) # 不使用softmax,输出原始logits用于蒸馏
])
需要注意的是,模型最后一层设置了 10 个单元,对应 0 - 9 这 10 个数字,但未采用 softmax 激活函数,而是输出原始的 logits。这一设计对于模型蒸馏很重要,因为在后续的蒸馏过程里,会借助 softmax 函数来计算教师模型与学生模型之间的 Kullback-Leibler(KL)散度,以此衡量二者差异,为学生模型的优化提供方向。
完成模型定义后,要使用compile()方法对其进行配置,设置优化器、损失函数以及评估指标:
teacher_model.compile(
optimizer = 'adam',
loss = tf.keras.losses.CategoricalCrossentropy(from_logits = True),
metrics = ['accuracy']
)
配置完成,就可以使用fit()方法启动模型训练:
# 训练教师模型
teacher_model.fit(x_train, y_train,
epochs = 5,
batch_size = 64,
validation_data = (x_test, y_test))
本次训练设定了 5 个训练周期,训练过程中的详细信息如下:
Epoch 1/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 8s 8ms/step - accuracy: 0.8849 - loss: 0.3798 - val_accuracy: 0.9844 - val_loss: 0.0504
Epoch 2/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 9s 9ms/step - accuracy: 0.9847 - loss: 0.0494 - val_accuracy: 0.9878 - val_loss: 0.0361
Epoch 3/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 9s 10ms/step - accuracy: 0.9907 - loss: 0.0302 - val_accuracy: 0.9898 - val_loss: 0.0316
Epoch 4/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 10s 10ms/step - accuracy: 0.9928 - loss: 0.0223 - val_accuracy: 0.9895 - val_loss: 0.0303
Epoch 5/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9935 - loss: 0.0197 - val_accuracy: 0.9919 - val_loss: 0.0230
从这些数据中,可以直观地看到模型在训练过程中的准确率和损失变化,了解模型的学习效果,为后续的模型优化和评估提供依据。
2.3 定义学生模型
教师模型训练完成后,定义学生模型。与教师模型相比,学生模型的架构更简单,层数更少:
# 学生模型
student_model = keras.Sequential([
keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10) # 不使用softmax,输出原始logits用于蒸馏
])
2.4 定义蒸馏损失函数
在模型蒸馏的实现过程中,distillation_loss() 函数发挥着核心作用,它借助 Kullback-Leibler(KL)散度来精准计算蒸馏损失,从而推动学生模型向教师模型 “看齐”。下面,我们就来详细解读这个函数的代码实现。
蒸馏损失函数的计算,依赖于教师模型和学生模型的预测结果,具体步骤如下:
-
使用教师模型为输入批次生成软目标(概率)。
-
使用学生模型的预测计算其软概率。
-
计算教师模型和学生模型软概率之间的Kullback-Leibler(KL)散度。
-
返回蒸馏损失。
软概率和常见的硬标签不同。硬标签是明确分类,像判断邮件是否为垃圾邮件,结果只有 “是”(1)或 “否”(0)。而软概率会给出多种结果的概率,比如某邮件是垃圾邮件的概率为 0.85,不是的概率为 0.15,能更全面反映模型判断。
计算软概率要用到 softmax 函数,且受温度参数影响。在知识蒸馏里,教师模型的软概率包含类间丰富信息,学生模型学习后,能提升泛化能力和性能,更好地模仿教师模型。
以下是distillation_loss()函数的定义:
def distillation_loss(y_true, y_pred, x_batch, teacher_model, temperature=5):
"""
使用KL散度计算蒸馏损失。
"""
# 计算当前批次的教师模型logits
teacher_logits = teacher_model(x_batch, training=False)
# 将logits转换为软概率
teacher_probs = tf.nn.softmax(teacher_logits / temperature)
student_probs = tf.nn.softmax(y_pred / temperature)
# KL散度损失(教师模型和学生模型分布之间的差异)
return tf.reduce_mean(tf.keras.losses.KLDivergence()(teacher_probs, student_probs))
Kullback-Leibler(KL)散度,也称为相对熵,用于衡量一个概率分布与另一个参考概率分布之间的差异。
2.5 使用知识蒸馏训练学生模型
现在准备好使用知识蒸馏来训练学生模型,首先,定义train_step()函数:
optimizer = tf.keras.optimizers.Adam()
@tf.function
def train_step(x_batch, y_batch, student_model, teacher_model):
with tf.GradientTape() as tape:
# 获取学生模型的预测
student_preds = student_model(x_batch, training=True)
# 计算蒸馏损失(显式传入教师模型)
loss = distillation_loss(y_batch, student_preds, x_batch, teacher_model, temperature=5)
# 计算梯度
gradients = tape.gradient(loss, student_model.trainable_variables)
# 应用梯度 - 训练学生模型
optimizer.apply_gradients(zip(gradients, student_model.trainable_variables))
return loss
这个函数执行单个训练步骤:
-
计算学生模型的预测。
-
使用教师模型的预测计算蒸馏损失。
-
计算梯度并更新学生模型的权重。
为了训练学生模型,需要创建一个训练循环,遍历数据集,在每一步更新学生模型的权重,并在每个训练周期结束时打印损失,以监控训练进度:
# 训练循环
epochs = 5
batch_size = 32
# 准备数据集批次
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)
for epoch in range(epochs):
total_loss = 0
num_batches = 0
for x_batch, y_batch in train_dataset:
loss = train_step(x_batch, y_batch, student_model, teacher_model)
total_loss += loss.numpy()
num_batches += 1
avg_loss = total_loss / num_batches
print(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}")
print("Student Model Training Complete!")
训练后,应该会看到类似以下的输出:
Epoch 1, Loss: 0.1991
Epoch 2, Loss: 0.0588
Epoch 3, Loss: 0.0391
Epoch 4, Loss: 0.0274
Epoch 5, Loss: 0.0236
Student Model Training Complete!
2.6 评估学生模型
学生模型已经训练完成,可以使用测试集(x_test和y_test)对其进行评估,观察其性能:
student_model.compile(
optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
student_acc = student_model.evaluate(x_test, y_test, verbose=0)[1]
print(f"Student Model Accuracy: {student_acc:.4f}")
如预期,学生模型达到了相当不错的准确率:
Student Model Accuracy: 0.9863
2.7 使用教师模型和学生模型进行预测
现在可以使用教师模型和学生模型进行一些预测,看看是否都能准确预测MNIST测试数据集中的数字:
import numpy as np
_, (x_test, y_test) = keras.datasets.mnist.load_data()
for index in range(5):
plt.figure(figsize=(2, 2))
plt.imshow(x_test[index], interpolation='none')
plt.title("Digit: {}".format(y_test[index]))
# 不显示x轴和y轴刻度
plt.xticks([])
plt.yticks([])
plt.show()
# 现在可以进行预测
x = x_test[index].reshape(1,28,28,1)
predictions = teacher_model.predict(x)
print(predictions)
print("Predicted value by teacher model: ", np.argmax(predictions, axis=-1))
predictions = student_model.predict(x)
print(predictions)
print("Predicted value by student model: ", np.argmax(predictions, axis=-1))
以下是前两个结果:

如果测试更多的数字,会发现学生模型的表现与教师模型一样好。