Part1:使用 TensorFlow 和 Keras 的 NeRF计算机图形学和深度学习
- 1. 效果图
- 2. 原理
- 2.0 前向成像模型
- 2.1 世界坐标系
- 2.2 相机坐标系
- 2.3 坐标变换
- 2.4 投影转换
- 2.5 数据
- 3. 源码
- 参考
是否有一种方法可以仅从一个场景多张不同视角的照片中捕获整个3D场景?
有。 NeRF:将场景表示为用于视图合成的神经辐射场中(NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis),Mildenhall等人(2020)的论文解答了这个问题。NeRF的更简单实现赢得了 TensorFlow社区聚光灯奖 。
这篇博客将介绍计算机图像学的基础主题,包括:
- 前向成像模型(拍照)
- 世界到相机(3D到3D)转换
- 相机到图像(3D到2D)转换
- 所需的数据集,涵盖了所有先决条件。
后边的博客将研究各种基本概念:NeRF:将场景表示为视图合成的神经辐射场。我们还将学习如何使用TensorFlow和Python实现这些概念。
1. 效果图
如下图:从不同视角(顶部)给算法一些热狗盘的图片可以 top精确地生成整个3D风景( 底部 )


2. 原理
神经辐射场(Neural Radiance Fields NeRF) 将 深度学习 和 计算机图形学(Computer Graphics)结合在一起。计算机图形学一直是现代技术的奇迹之一。渲染逼真的 3D 场景(rendering realistic 3D scenes) 的应用范围从电影、太空导航到医学。
本课是关于使用 TensorFlow 和 Keras 使用 NeRF 进行计算机图形学和深度学习的 3 部分系列的第 1 部分:
- 使用 TensorFlow 和 Keras 的 NeRF 计算机图形学和深度学习:第 1 部分(本文)
- 使用 TensorFlow 和 Keras 的 NeRF 计算机图形学和深度学习:第 2 部分
- 使用 TensorFlow 和 Keras 的 NeRF 计算机图形学和深度学习:第 3 部分
这篇博客将介绍相机在计算机图形学世界中的工作原理及使用的数据集。
1. 世界坐标系(World Coordinate Frame): 表示物理 3D 世界
2. 相机坐标系(Camera Coordinate Frame): 代表虚拟3D相机世界
3. 坐标变换(Coordinate Transformation): 从一个坐标系映射到另一个坐标系
4. 投影变换(Projection Transformation): 在 2D 平面上形成图像(相机传感器)
5. 数据集: 了解 NeRF 的数据集
2.0 前向成像模型
想象一下你带着相机出去,发现了一朵美丽的花。你考虑你想要捕捉它的方式,定位相机,校准设置,然后拍照。
将世界场景转换为图像的整个过程被封装在一个通常称为 前向成像模型 中可视化模型 的数学模型中。
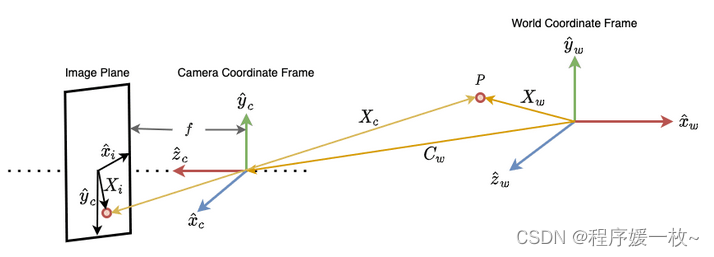
前向成像模型从世界坐标系中的一个点开始。然后使用坐标变换将其变换为相机坐标系。然后使用投影变换将相机坐标变换到图像平面上。
2.1 世界坐标系
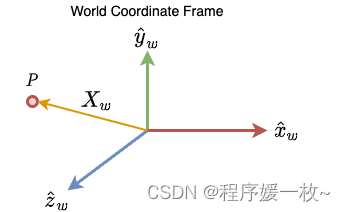
在现实世界中看到的所有形状和物体都存在于三维参考系中。我们把这个参照系称为世界坐标系。 使用这个坐标系可以很容易地定位三维空间中的任何点或对象。
让我们取三维空间中的点P,如下图
这里,
x
ˆ
w
,
y
ˆ
w
,
z
ˆ
w
\^{x}_w,\^{y}_w,\^{z}_w
xˆw,yˆw,zˆw表示世界坐标系中的三个轴。点P的位置通过向量
X
w
X_w
Xw来表示:
X
w
=
{
x
w
y
w
z
w
}
X_w= \begin{Bmatrix} x_w \\ y_w \\ z_w \end{Bmatrix}
Xw=⎩
⎨
⎧xwywzw⎭
⎬
⎫
2.2 相机坐标系
与世界坐标系一样,有另一个参考系,称为相机坐标系
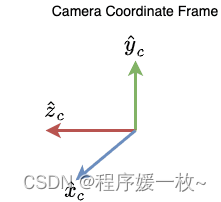
这个画框位于相机的中心。与世界坐标系不同,这不是一个静态的参照系可以在移动相机拍照时移动这个坐标系。
图4中的同一点P现在可以用两个参考系定位,如图世界到相机的坐标变换:

而在世界坐标系中,点由 X w X_{w} Xw向量定位,在相机坐标系中由 X c X_{c} Xc向量定位。如图6所示。
X
c
=
{
x
c
y
c
z
c
}
X_c= \begin{Bmatrix} x_c \\ y_c \\ z_c \end{Bmatrix}
Xc=⎩
⎨
⎧xcyczc⎭
⎬
⎫
注:点P的位置不变。只有观察点的方式会随着参照系的变化而变化。
2.3 坐标变换
建立了两个坐标系:世界和相机,目标是在相机坐标
X
c
X_c
Xc 和世界坐标
X
w
X_w
Xw 之间建立一座桥梁。
X
c
=
R
×
(
X
w
−
C
w
)
X_c = R \times (X_w - C_w)
Xc=R×(Xw−Cw)
R = [ r 11 r 12 r 13 r 21 r 22 r 23 r 31 r 32 r 33 ] R= \begin{bmatrix} r11 & r12 & r13\\ r21 & r22 & r23 \\ r31 & r32& r33 \end{bmatrix} R= r11r21r31r12r22r32r13r23r33
X c = R × ( X w − C w ) ⇒ X c = R × X w − R × C w ⇒ X c = R × X w + t X_c = R \times (X_w - C_w) \\ \rArr X_c = R \times X_w - R \times C_w \\ \rArr X_c = R \times X_w + t Xc=R×(Xw−Cw)⇒Xc=R×Xw−R×Cw⇒Xc=R×Xw+t
R表示相机坐标系相对于世界坐标系的方向,由矩阵表示。
其中 t 表示平移矩阵。在上面的等式中有一个矩阵乘法和一个矩阵加法。如果可以的话,将事物压缩为单个矩阵乘法总是更可取的。为此,我们将使用一个称为齐次坐标(homogeneous coordinates)的概念。
齐次坐标系允许我们在N+1维空间中用虚拟变量表示N维点。利用齐次坐标系,我们可以将
X
w
(
3
D
)
X_ w(3D)
Xw(3D)变换为
X
w
(
4
D
)
{X}_w(4D)
Xw(4D)。
有了齐次坐标,可以把方程压缩成矩阵乘法。

其中
C
e
x
C_{ex}
Cex是保持相机坐标系的方向和位置的矩阵。我们可以将此矩阵称为相机外部矩阵,因为它表示旋转和平移等值,这两个值都是相机的外参(Camera Extrinsic)。**
C
e
x
=
[
r
11
r
12
r
13
t
x
r
21
r
22
r
23
t
y
r
31
r
32
r
33
t
z
0
0
0
1
]
C_{ex}= \begin{bmatrix} r11 & r12 & r13 & t_x\\ r21 & r22 & r23 & t_y \\ r31 & r32& r33 & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix}
Cex=
r11r21r310r12r22r320r13r23r330txtytz1
2.4 投影转换
从一个点开始 P 及其(同质)世界坐标 X w X_w Xw 借助相机外在矩阵 C e x C_{ex} Cex, X w {X}_w Xw 已转换为其(均匀)相机坐标 X c X_c Xc.
要理解投影变换,唯一需要的是类似的三角形。
实际的图像平面不是虚拟平面,而是图像传感器阵列。3D场景落在这个传感器上,导致图像的形成。因此 x_i 和 y_i x_i 在图像平面中可以用像素值替换 u,v。
最后得到:
[
u
˜
v
˜
w
˜
]
=
[
f
0
o
x
0
0
f
o
y
0
0
0
1
0
]
[
x
c
y
c
z
c
1
]
\begin{bmatrix} \~u \\ \~v \\ \~w \end{bmatrix} = \begin{bmatrix} f & 0 & o_x & 0\\ 0 & f & o_y& 0\\ 0 & 0 & 1& 0 \end{bmatrix} \begin{bmatrix} x_c \\ y_c \\ z_c \\ 1 \end{bmatrix}
u˜v˜w˜
=
f000f0oxoy1000
xcyczc1
可以简单地表示为
u
˜
=
C
i
n
×
x
˜
c
\~{u}=C_{in} \times \~{x}_c
u˜=Cin×x˜c
其中 x ~ c \tilde{x}_c x~c 是包含点在相机坐标空间中的位置的向量集 是包含点在相机坐标空间中的位置的一组向量, u ^ \hat{u} u^ 是包含图像平面上点位置的值集。分别 C i n C_{in} Cin 表示将点从 3D 照相机空间映射到 2D 空间所需的值集。
C i n = [ f 0 o x 0 0 f o y 0 0 0 1 0 ] C_{in} = \begin{bmatrix} f & 0 & o_x & 0\\ 0 & f & o_y& 0\\ 0 & 0 & 1& 0 \end{bmatrix} Cin= f000f0oxoy1000
可以称 C i n C_{in} Cin为相机固有(camera intrinsic)属性,表示焦距和图像平面中心等值 和 x 和 轴,两者都是相机内参。
2.5 数据
将讨论要使用的数据。作者已经开源了数据集,数据集的链接发布在 NeRF 的官方存储库中。数据集的结构如图 11 所示。
有两个文件夹,nerf_synthetic和nerf_lilf_data。接下来将在本系列中使用合成数据集,选择了“船舶”数据集,但请随时下载其中任何一个。
解压缩数据集后发现三个包含图像的文件夹: train、val、test 和 transforms_train.json、transforms_val.json、 transforms_test.json其中包含相机的方向和位置。
3. 源码
解析tranfomrs_train.json
# 解析转换文件
# python transform_json_read.py
# 导入包
import json
import numpy as np
# 定义json训练文件路径
jsonTrainFile = "transforms_train.json"
# 打开并读取文件内容
with open(jsonTrainFile, "r") as fp:
jsonTrainData = json.load(fp)
# 打印json文件内容
print(f"[INFO] Focal length train: {jsonTrainData['camera_angle_x']}")
print(f"[INFO] Number of frames train: {len(jsonTrainData['frames'])}")
# json文件有俩个key: camera_angle_x(摄像机的角度) 和 frames(每个图像帧的元信息)
firstFrame = jsonTrainData["frames"][0]
# 获取转换矩阵和文件名 获取第一帧:每一帧都是一个字典,包含transform_matrix和file_path两个关键点,
# file_path是到所考虑的图像(帧)的路径,transform_matrix是该图像的相机到世界的矩阵。
tMat = np.array(firstFrame["transform_matrix"])
fName = firstFrame["file_path"]
# 打印数据
print(tMat)
print(fName)
参考
- https://pyimagesearch.com/2021/11/10/computer-graphics-and-deep-learning-with-nerf-using-tensorflow-and-keras-part-1/



![[强网杯 2019]随便注 1【SQL注入】解析过程](https://img-blog.csdnimg.cn/1a25f83b23634ddc93b182dd6e0bde6d.png)