数据准备
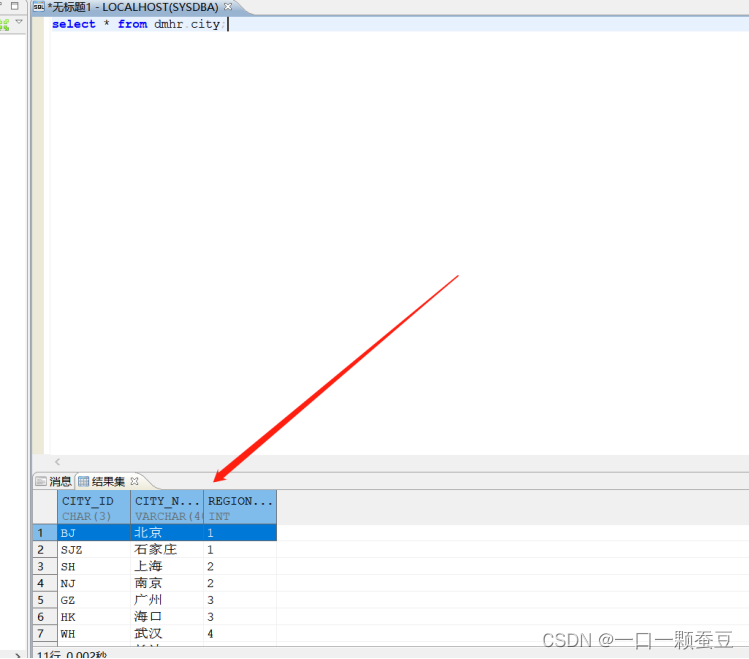
建立一张表
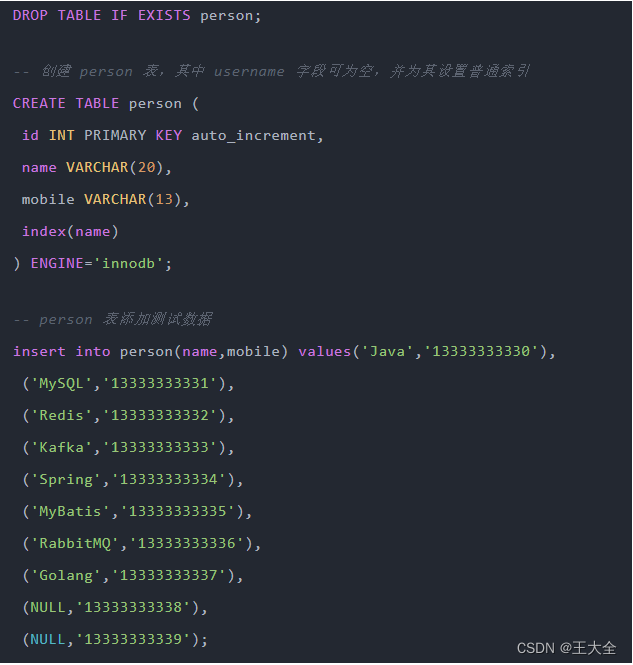
数据如下:
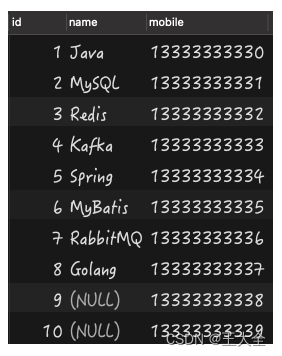
1.count 数据丢失
count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
select count(*),count(name) from person;
-----------------------
count(*) | count(name)
10 | 8
-------------------------
从结果可以看出,count(*)和count(name)的值不一样,即当使用的是 count(name) 查询时,就丢失了两条值为 NULL 的数据。
2.distinct 数据丢失
当使用语句count(distinct column1,column2)时,如果有一个字段值为空,即使另一列有不同的值,那么查询的结果也会将数据丢失, SQL如下所示:
select count(distinct name,mobile) from person;
-----------------------
count(distinct name,mobile)
8
-------------------------
3.select 数据丢失
如果某列存在 NULL 值时,如果执行非等于查询(<>或者!=)会导致为 NULL 值的结果丢失,比如下面的这些数据:
select * from person where name <> 'Java' order by id
-------------------------------------
id | name | mobile
2 | MySQL | 13333333333331
3 | Redis | 13333333333332
4 | Kafka | 13333333333333
5 | Spring | 13333333333334
6 | MyBatis | 13333333333335
7 | RabbitMQ| 13333333333336
8 | Golang | 13333333333337
------------------------------------
可以看出id=9和id=10的name为 NULL 的两条数据没有查询出来,这个结果并不符合我们的正常预期。
要全部查出可以用以下sql:
select * from person where name != 'Java' or isnull(name) order by id
4.导致空指针异常
表数据如下:

select sum(num) from goods where id>4;
-----------------------
sum(num)
NULL
-------------------------
解决方法:可以使用ifnull()对空值进行处理来避免空指针异常:
select ifnull(sum(num),0) from goods where id>4;
5.增加了查询难度
当字段中有了空值,对于null值或者非null值的查询难度就增加了,必须使用与null匹配的查询方法,比如IS NULL或者IS NOT NULL又或者是IFNULL(cloumn)这样的表达式进行查询,传统的 =、!=、<>…这些表达式就不能使用了,这就增加了查询的难度。
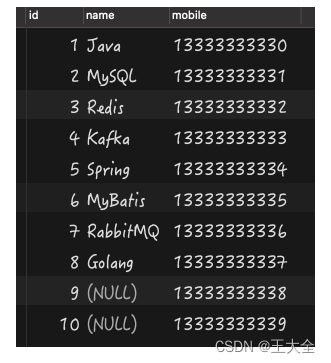
select * from person where name !=null;
//没有任何数据
-------------------------------------
id | name | mobile
------------------------------------
select * from person where name is not null
//这种就有数据
-------------------------------------
id | name | mobile
2 | MySQL | 13333333333331
3 | Redis | 13333333333332
4 | Kafka | 13333333333333
5 | Spring | 13333333333334
6 | MyBatis | 13333333333335
7 | RabbitMQ| 13333333333336
8 | Golang | 13333333333337
------------------------------------


![[强网杯 2019]随便注 1【SQL注入】解析过程](https://img-blog.csdnimg.cn/1a25f83b23634ddc93b182dd6e0bde6d.png)