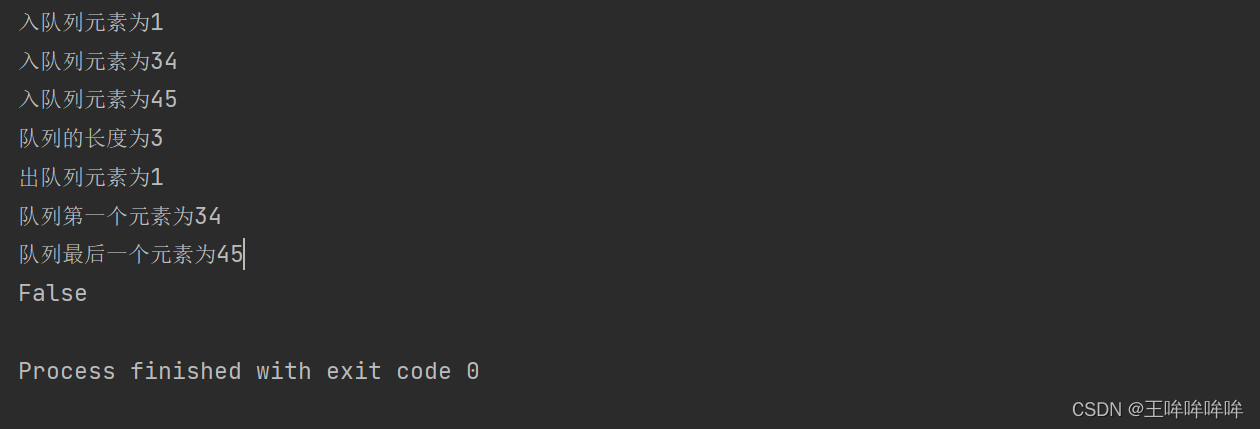
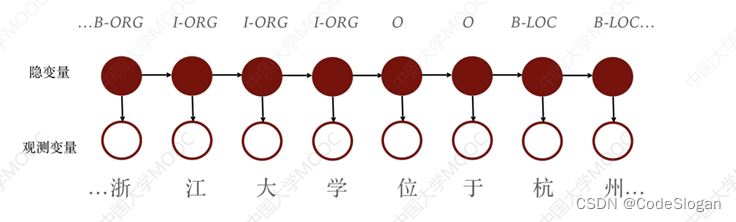
目录
摘要
一、引言
二、方法
2.1 图像表示
2.1.1 图像 patch
2.1.2 视觉 token
2.2 主干网络:图像 Transformer
2.3 预训练 BEiT:掩码图像建模
2.4 从变分自动编码器的角度来看
2.5 预训练设置
2.6 在下游视觉任务微调 BEiT
三、实验
3.1 图像分类
3.2 语义分割
3.3 消融实验
四、相关工作
五、总结
- GitHub: unilm/beit at master · microsoft/unilm · GitHub
摘要
我们引入了一个自监督视觉表示模型 BEIT,它表示 Bidirectional Encoder representation from Image Transformers。在 NLP 领域开发的BERT 之后,我们提出了一个掩码图像建模 (MIM) 任务来预训练视觉 Transformer。具体来说,在我们的预训练中,每幅图像都有两个视图 (views),即图像 patches (如 16×16 pixels) 和视觉 tokens (即离散 tokens)。我们首先将原始图像 “tokenize” 为视觉 token。然后,随机 mask 一些图像 patches,并将它们输入主干 Transformer。预训练的优化目标 (objective) 是基于损坏的图像 patches 恢复原始的视觉 tokens。在对 BEIT 进行预训练后,我们通过在经预训练的编码器上附加任务层,直接微调下游任务上的模型参数。对图像分类和语义分割的实验结果表明,我们的模型相比以往的预训练方法取得了具有竞争力的结果 (competitive results)。
一、引言
Transformer 在 CV 领域取得了良好的性能。然而,实证研究表明,视觉 Transformer 比 CNN 需要更多的训练数据。为了解决渴求数据 (data-hungry) 的问题,自监督预训练 是利用大规模图像数据的一个很有前途的解决方案。人们已经为视觉 Transformer 的探索了几种方法,如对比学习 和 自蒸馏。
与此同时,BERT 在 NLP 取得了巨大成功。其 掩码语言建模 (MLM) 任务首先随机 mask 文本中的部分 tokens,再根据已损坏 (corrupted) 文本的 Transformer 编码结果恢复 masked tokens。在 BERT 的激励下,我们转向 auto-encoding 的思想来预训练视觉 Transformer,这尚未被视觉社区很好地研究。对图像数据直接应用 BERT 风格的预训练具有挑战性。首先,没有现存的词表 (vocabulary) 可以用于视觉 Transformer 的输入单元,即图像 patches。因此,不能简单地使用一个 softmax 分类器来预测所有可能的候选 masked patches。相比之下,语言词表 (vocabulary),如 words 和 BPE,都有良好地定义了 (well-defined),缓解了 auto-encoding 预测。一个直接的替代方法是将任务视为一个回归问题,它预测 masked patches 的 raw pixels。然而,这种像素级恢复任务往往会浪费 对预训练的 短距离依赖关系和高频细节的建模能力。我们的目标是克服视觉 Transformer 预训练的上述问题。

在预训练前,通过 autoencoding 风格的重建学习 “图像 tokenizer”,根据已学习的词表 (vocabulary),图像被 tokenized 成离散的视觉 tokens (id)。在预训练时,每幅图像都有两个 views,即图像 patches 和视觉 tokens。我们随机 mask 一定比例的图像 patches (图中灰色 patches),并替换为特殊的 mask 嵌入 [M]。然后这些 patches 被输入到一个主干视觉 Transformer。该预训练任务旨在基于被损坏图像的编码向量来预测原始图像的视觉 tokens。
在这项工作中,我们引入了一个自监督的视觉表示模型 BEiT,它代表 Bidirectional Encoder representation from Image Transformers (有别于后来同时具有编码器-解码器且 masked tokens 放在解码器的 MAE)。受BERT 的启发,我们提出了一个预训练任务,即 掩码图像建模 (MIM)。如图 1 所示,MIM 对每个图像使用两个视图 (views),即图像 patches 和视觉 tokens。我们将图像分割成一个 patches grid 作为主干 Transformer 的输入表示。此外,我们 将图像 “tokenize” 为离散的视觉 tokens,这获取自离散的 VAE 的潜在代码 (latent codes)。在预训练过程中,我们随机 mask 一定比例的图像 patches,并将已损坏的输入提供给 Transformer。该模型学习恢复原始图像的视觉 tokens,而非 masked patches 的 raw pixels (BEiT 恢复 tokens (图 1 中的 index),MAE 恢复 pixels)。
我们实施自监督学习,然后微调图像分类和语义分割这两个下游任务。实验结果表明,BEiT 的性能优于 从头开始的训练 和 以往的强自监督模型。此外,BEiT 是对有监督的预训练的补充。通过 使用 ImageNet 标签的中间 (intermediate) 微调,可以进一步提高 BEiT 的性能。消融研究表明,我们提出的技术对 BERT 式的图像数据预训练的有效性至关重要。除 性能 外,收敛速度 和 微调稳定性 的改善也降低了最终任务的训练成本。此外,我们还证明了 自监督 BEiT 可以通过预训练学习合理的语义区域,释放 (unleashing) 图像中丰富的监督信号。
我们的贡献总结如下:
- 我们提出了一个掩码图像建模 (MIM) 任务,以自监督的方式预训练视觉 Transformer。我们还从变分自编码器的角度提供了一个理论解释。
- 我们对 BEiT 预训练,并对下游任务进行广泛的微调实验,如图像分类和语义分割。
- 我们提出自监督 BEiT 的自注意机制来学习区分语义区域和对象边界 (semantic regions & object boundaries),尽管无需任何人类注释。
二、方法
给定一个输入图像 ,BEiT 将其编码为 经上下文化 (contextualized) 的向量表示。如图 1 所示,BEiT 通过自监督学习方式的掩码图像建模 (MIM) 任务进行预训练。MIM 旨在恢复基于编码向量的 masked image patches。对于下游任务 (如图像分类和语义分割),我们在经预训练的 BEiT 上添加任务层,并对特定数据集上的参数进行微调。
2.1 图像表示
在我们的方法中,图像有两个表示的 views,即图像 patch 和视觉 token,二者分别在预训练中作为输入和输出表示。
2.1.1 图像 patch
2D 图像被 splited 为一个序列的 patches,以便于标准 Transformer 能够接受图像数据。形式上 (formally),将图像 reshape 为
个 patches
,其中
为通道数,
为输入图像分辨率,
为每个 patch 的分辨率。图像 patches
被 flattened 成向量并被线性投影,类似 BERT 的词嵌入。图像 patches 保留 raw pixels,并在 BEiT 中用作输入特征。
实验中,每幅 224×224 图像被 splited 成 14×14 的图像 patches grid (),每个 grid 表示的 patch 尺寸为 16×16 (
)。
2.1.2 视觉 token
类似于自然语言,图像被表示为基于 “image tokenizer” 获取的离散 token 序列,而非 raw pixels。具体来说,图像 被 tokenized 为
,其中 词表 (vocabulary)
包含离散的 token indices。
按照 (Zero-shot text-to-image generation),我们使用 通过离散变分自编码器 (dVAE) 学习到的图像 tokenizer。在视觉 token 的学习过程中,有 tokenizer 和 decoder 这两个模块。tokenizer 根据据 视觉代码本 (codebook) / 词表 (vocabulary) 将图像像素
映射为离散的 tokens
。decoder
学习基于视觉 token
重建输入图像
。重建的优化目标 (objective) 可以写成
。由于潜在的视觉tokens 是离散的,模型训练是不可微的。因此,Gumbel-softmax 被用于训练模型。此外,在 dVAE 训练过程中,一个 uniform 先验 被加到
上。
每幅图像被 tokenize 成 14×14 的视觉 tokens grid。注意,一幅图像的视觉 tokens 数和图像 patches 数相同。词表 (vocabulary) 大小设置为 。本工作中,直接用 (Zero-shot text-to-image generation) 中的公开可用的图像 tokenizer (https://github.com/openai/DALL-E),还将它与附录 C 中重新实现的 tokenizer 进行了比较。
2.2 主干网络:图像 Transformer
按照 ViT,我们将标准 Transformer 用作主干网络,以便于结果能够直接和以往工作在网络架构方面进行比较。
Transformer 的输入是一个图像 patches 序列。然后,patches 经线性投影得到 patch 嵌入
,其中投影矩阵
。此外,我们不但预先往输入序列加入 (prepend) 一个 特殊的 token
,而且加入了 标准的可学习 1D 位置嵌入
。从而,输入向量
被馈入 Transformer。编码器包含了
层 Transformer blocks
,
。最后一层编码器输出
即为 经编码的图像 patches 表示 (共
个向量),其中
是 第
个图像 patch 的向量。
2.3 预训练 BEiT:掩码图像建模
我们提出了一个 掩码图像建模 (MIM) 任务:随机 mask 一定百分比的图像 patches,然后预测与 masked patches 对应的视觉 tokens。
在预训练前,通过 autoencoding 风格的重建学习 “图像 tokenizer”,根据已学习的词表 (vocabulary),图像被 tokenized 成离散的视觉 tokens (id)。在预训练时,每幅图像都有两个 views,即图像 patches 和视觉 tokens。我们随机 mask 一定比例的图像 patches (图中灰色 patches),并替换为特殊的 mask 嵌入 [M]。然后这些 patches 被输入到一个主干视觉 Transformer。该预训练任务旨在基于被损坏图像的编码向量来预测原始图像的视觉 tokens。
图 1 展示了我们的方法的概览。如 2.1 节所示,给定一个输入图像 ,将其 split 为
个图像 patches (
),并一一 tokenize 为
个视觉 tokens (
)。然后,随机 mask 约 40% (掩码率为 0.4) 的图像 patches,其中 masked 的位置表示为
(如图 1
)。接着,用一个可学习的嵌入
来替换 masked patches (用于训练)。然后如 2.2 节所述,将已损坏 (被 masked) 的图像 patches
馈入 L 层 Transformer 中,得到的最后隐层向量
被视为输入 patch 的编码表示 (如图 1 中的 5 个 BEiT Encoder 灰色输出)。对于每个 mask 位置
,使用 softmax 分类器 (其实是 FC+Softmax 构成的 MIM Head) 来预测相应的视觉 tokens
,其中
是已损坏 (被 masked) 的图像 patches,
且
。预训练的 objectives 是最大化 已损坏图像中 正确的视觉 tokens
的对数似然 (log-likelihood)。

其中, 为训练语料库 (corpus),
代表随机 masked 的位置 (如图 1 中的
),
为根据
来 masked 的已损坏图像 (如图 1 左下角的图)。

本工作中 使用 blockwise masking,而非随机为 masked 位置 选择 patches。如算法 1 所示,每次都会 mask 一个 block 的图像 patches。每个 block 的 patch 数最小设为 16。然后,随机选择 masking block 的高宽比 (aspect ratio)。重复上述 2 个步骤,直到获得足够的 masked patches,即
(
为图像 patches 总数,
为掩码率)。
MIM 主要受到 MLM 的启发,MLM 是 NLP 中最成功的预训练 objective 之一。此外,blockwise (或 n-gram) masking 也被广泛应用于 BERT-like 模型。然而,直接使用像素级 auto-encoding (即恢复 masked patches 的像素) 进行视觉预训练,会 pushes 模型聚焦于短程依赖和高频细节。BEiT 通过预测离散视觉 tokens 来克服上述问题,并将细节 summarizes 高级抽象。第 3.3 节的消融研究表明,BEiT 明显优于像素级 auto-encoding。
2.4 从变分自动编码器的角度来看
BEiT 预训练 可视为 变分自动编码器 (variational autoencoder) 训练。设 为原始图像,
为 masked 图像,
为视觉 tokens。考虑到对数似然
的证据下界 (ELBO),即从其损坏的版本中恢复原始图像:

表示使用图像 tokenizer 基于 输入图像 获取 视觉 tokens
表示 基于 输入视觉 tokens 解码 原始图像
表示 基于 masked 图像 恢复 视觉 tokens,此即 MIM 的预训练任务
我们遵循二阶段过程来学习模型。在第一阶段,获取图像 tokenizer 作为离散变分自动编码器。特别地,第一阶段使用一个 uniform 先验来最小化 Visual Token Reconstruction 损失,如公式 (2) 所示。在第二阶段,学习先验 ,同时保持
和
固定。将
简化为具有最有可能的视觉 token 的单点 (one-point) 分布
,则公式 (2) 可重写为:

其中,第二项是 BEiT 的预训练 objectives。
2.5 预训练设置
BEiT 的架构遵循 ViT-Base,以进行公平比较。我们使用 12 层 Transformer,隐层大小为 768,注意力头数为 12。FFN 的中间尺寸 (intermediate size) 为 3072。默认输入 patch size 为 16×16。直接用已训练好的图像 tokenizer。视觉 token 词表大小 (vocabulary) 为 8192。
我们在 ImageNet-1K 训练集上预训练,IN1K 包含约 120 万张图像。数据增广策略 包括:随机调整尺寸的裁剪、水平翻转、颜色抖动 (color jittering)。注意,我们 并未使用这些标签用于自监督学习。实验中使用了 224×224 的分辨率。因此,输入被 split 成 14×14 个图像 patches,以及相同数量的视觉 tokens。最多随机 mask 75 个 patches (掩码率约 40%,masked patches 数:14×14×0.4 = 78.4 ≈ 75)。
预训练约 500k steps (即 800 个 epochs),batch size 为 2k。采用 β1 = 0.9, β2 = 0.999 的 Adam 优化。学习率为 1.5e-3,预热 10 个 epochs,使用余弦学习率衰减策略,权重衰减为 0.05。采用 rate = 0.1 的 stochastic depth (Deep networks with stochastic depth:训练时每个 batch 随机 dropout 网络的一些 layers,测试时用完整网络),并禁用 dropout。使用 16 张 Nvidia Telsa V100 32GB GPU,500k steps 的训练约需 5 天。
我们发现 适当的初始化对于稳定 Transformer 很重要,特别是对于大规模预训练。我们首先在一个小范围内随机初始化所有参数,如[−0.02, 0.02]。然后,对于第 层 Transformer,我们用
rescale 自注意力模块和 FFN 的输出矩阵 (即每个子层内的最后一个线性投影)。
2.6 在下游视觉任务微调 BEiT
预训练 BEiT 后,我们在 Transformer 末尾追加了一个任务层,并微调下游任务的参数,就像 BERT。以图像分类和语义分割为例。在 BEiT 的其他视觉任务上利用 预训练然后微调 的范式是很简单的。
图像分类。对于图像分类,直接使用一个简单的线性分类器作为任务层。具体地,使用平均池化来聚合表示,并将全局提供给 softmax 分类器。类别概率计算为 ,其中
是第
个图像 patch 的最终编码向量,
是一个参数矩阵,
是类别/标签数。通过更新 BEiT 和 softmax 分类器的参数,来最大化有标签 (labeled) 数据的似然 (likehood)。
语义分割。对于语义分割,遵循 SETRPUP 中使用的任务层。具体地,使用经预训练的 BEiT 作为主干编码器,然后合并几个反卷积层 (deconv) 作为解码器来产生分割。该模型也类似于图像分类被端到端微调。
中间微调。经过自监督的预训练,我们可以在数据丰富的中间数据集 (即本工作中的 ImageNet-1K) 上进一步训练 BEiT,然后在目标下游任务上微调模型 (可以理解为三阶段:自监督预训练 → 中间数据集微调 → 下游任务微调)。这种中间微调 (intermediate fine-tuning) 是 NLP 中 BERT 微调的常见做法。我们直接遵循 BEIT 的方法。
三、实验
我们对图像分类和语义分割进行了完全微调实验。此外,我们提出了预训练的各种消融研究,并分析了由 BEiT 学习到的表示。我们还在附录D 中报告了 ImageNet 上的 linear probes。
3.1 图像分类

图像分类任务将输入图像分为不同的类别。我们在 ILSVRC-2012 ImageNet 数据集上评估 BEiT,使用 1k 个类别和 130 万张图像。在微调实验中,我们直接遵循 DeiT 的大多数超参数来进行公平比较。与从头开始的训练相比,我们 减少了微调 epochs,因为 BEiT 已经被预训练过了。因此,我们使用了一个 较大的学习率与 layer-wise decay。详细的超参数总结在附录 H 中。
表 1 报告了图像分类的 top-1 准确率。我们将 BEiT 与通过 随机初始化、有监督预训练 和以前的 自监督学习 方法训练的视觉 Transformer 进行了比较。除 iGPT 有 1.36B 的参数外,所有的比较模型都是 base-size。预训练在 ImiageNet 上进行,除了 ViT-JFT300M 是在谷歌内部的300M 图像上预训练的。
与随机初始化训练的模型相比,我们发现预训练 BEiT 显著提高了在两个数据集上的性能。BEiT 提高了在 ImageNet 上的性能,显示了在丰富资源设置下的有效性。
此外,我们还将 BEiT 与之前用于 Transformer 的 SOTA 自监督方法进行了比较,如 DINO 和 MoCo v3。BEiT 在 ImageNet 微调上优于以前的模型。其中,iGPT-1.36B 使用了更多的参数 (即 1.36B vs 86M),而 ViT-JFT300M 在更大的语料库上预训练 (即 300M vs 1.3M),而 其他模型在 ImageNet-1K 上对 ViT-Base 进行预训练。iGPT-1.36B 和 ViT-JFT300M 是最具可比性 (most comparable) 的方法,它们也遵循了视觉 Transformer 的自动编码预训练。具体来说,iGPT 使用聚类图像 tokens 作为图像 GPT 或图像 BERT 的输入和输出。相比之下,BEiT 使用图像 patches 作为输入来保留原始像素,并使用离散的视觉 tokens 作为预测 bottleneck (中间表示的意思?)。ViT-JFT300 预测每个 masked patch 的平均 3-bit 颜色,而不是通过离散的 VAE 学习到的视觉 tokens。我们还以多任务学习的方式对 BEiT 和 DINO 的自监督任务进行了预训练,详见附录 E。
此外,我们还使用 中间微调 评估了 BEiT。换言之,首先以自监督的方式预训练 BEiT,然后基于 ImageNet 的有标签数据微调预训练模型 (最后有需要再微调下游任务)。结果表明,BEiT 是对有监督预训练的补充,在 ImageNet 上进行中间微调后获得了额外的增益。
微调到 384×384 的分辨率。在对 224×224 的分辨率微调后,我们用 384×384 的图像额外微调了 10 个 epochs。我们遵循 DeiT 的标准的高分辨率设置,除了使用更少的 epochs。注意,224×224 和 384×384 图像 保持相同的 patch size。因此,对于更高的分辨率,Transformer 的输入序列长度会更长。表 1 显示,更高的分辨率使 ImageNet 上的 BEiT 结果提高了1+ 个点。更重要的是,在 ImageNet-1K 上进行预训练的BEiT-384 在使用相同的输入分辨率时,甚至优于使用 ImageNet-22K 的有监督预训练 ViT-384。
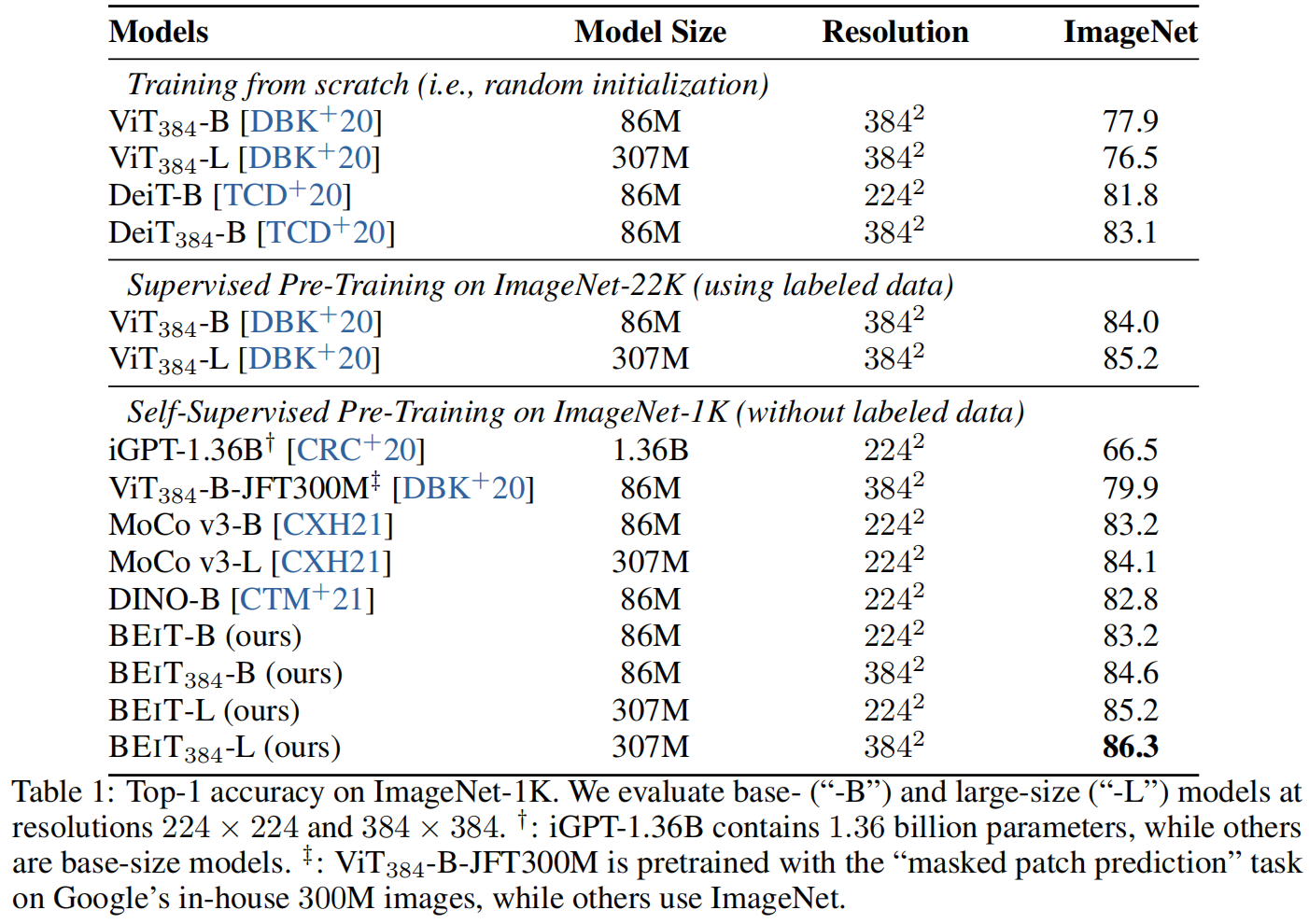
可扩展到更大的尺寸。我们进一步将 BEiT 扩展到大尺寸 (与 ViT-L 相同)。如表 1 所示,在从头开始训练时,在 ImageNet 上的 ViT384-L 比 ViT-384 更差。该结果验证了 视觉 Transformer 的 data-hungry 问题。在 ImageNet-22K 上进行有监督的预训练则部分缓解了这个问题,其中 ViT384-L 最终比 ViT-384 高出 1.2。相比之下,BEIT-L 比 BEIT 好 2.0,BEIT384-L 比 BEIT384 好 1.7。换句话说,将 BEiT 从 base 扩展到 large 的收益比使用 ImageNet-22K 进行有监督预训练的收益更大。更重要的是,比较 BEiT-384 和在 ImageNet-22K 上进行有监督预训练的ViT-384,随着从 base (即 0.6) 到 large (即 1.1),BEiT 的改进变得更大。结果表明,对于非常大的模型 (如 1B 或 10B),BEiT 倾向于更有用,特别是当有标签数据不足以对如此大的模型进行有监督预训练时。

收敛曲线。图 2 比较了 从头开始训练 和 预训练然后微调 范式的收敛曲线。我们发现,微调 BEiT 不仅获得 更好的性能,而且比从头训练DeiT 收敛得快得多。此外,微调 BEiT 可以在极少的 epochs 内达到合理的数字。
3.2 语义分割
略
3.3 消融实验
我们进行了消融研究来分析 BEiT 中各组件的贡献。通过图像分类 (ImageNet) 和语义分割 (ADE20K) 对这些模型进行了评估。我们将消融研究的默认预训练 steps 设为 300 个 epochs,占之前实验中使用的总 steps 的 37.5%。

表 4 报告了各种模型变体的结果。
首先,通过随机采样 masked 位置来消融 blockwise masking,发现 blockwise masking 对两种任务都是有益的,特别是语义分割。
其次,我们 通过预测 masked patches 的 raw pixels 来减少视觉 tokens 的使用,即,预训练任务成为恢复 masked patches 的像素回归问题。我们提出的 掩码图像建模 (MIM) 任务显著优于朴素像素级自动编码。与表 1 的结果相比,两个任务的消融结果比从头训练视觉 Transformer 差。结果表明,视觉 tokens 的预测是 BEiT 的关键组件。
第三,我们 减少了视觉 tokens 和 blockwise masking 的使用。我们发现,blockwise masking 对像素级自动编码更有帮助,从而缓解了短距离依赖的痛苦。
第四,恢复所有的视觉 tokens 会损害下游任务的性能。
第五,我们比较了不同训练 steps 下的 BEiT。对模型进行更长时间的预训练可以进一步提高下游任务的性能。
四、相关工作
略
五、总结
我们为视觉 Transformer 引入了一个自监督的预训练框架,在下游任务上实现了强大的微调结果,如图像分类和语义分割。我们表明,所提出的方法对于图像 Transformer 的 BERT-like 预训练 (即具有 masked 输入的自动编码) 的良好工作至关重要。我们还提出了自动获得关于语义区域的知识的有趣属性,而不使用任何人类标注的数据。在未来,我们希望在数据大小和模型大小方面扩大 BEiT 预训练。此外,我们将以更统一的方式进行多模态预训练,对文本和图像使用相似的 objectives 和共享的架构。